Last week the Reps program celebrated its 10 years anniversary. To honor the event, a week of celebrations took place, with meetings in Zoom rooms and virtual hangouts in specially decorated Hubs rooms. During that week, current Reps and Reps alumni shared memories of the past years, talked about their current work, and discussed future plans and aspirations.
The Reps program was created with a simple narrative in the mind of its founders (William Quiviger and Pierros Papadeas), to bring structure to the regional communities and help them grow. Throughout the last years, the Reps have served their communities, by growing them and mentoring them, supporting all Mozilla’s big projects and launches, and pivoting to be able to help where the organization needed them the most. From the 1 million Mozillians initiative to the Firefox OS days, and from the Quantum launch to the recent foxfoooding campaign, Reps have always stepped up for the challenge, giving a helping hand, organizing thousands of events, and amplifying Mozilla’s work and mission. And is that spirit that we wanted to celebrate during the last week. A spirit of giving and helping.
The event
Due to the pandemic, an event with physical attendance was not possible. However, that didn’t discourage the Reps. A full-week virtual event was organized instead (special kudos to Francesca Minelli for all the work on planning and coordinating it) that included virtual talks in Zoom rooms and hanging out time to two Hubs rooms. There was a dedicated Reps room and a room for communities. The first day we kicked off with a trip down memory lane. Reps alumni and longtime Reps were invited to talk about their experiences during the first days of the program. The day closed with a talk and Q&A with Mitchell Baker about the significance of the Reps program and how Reps can contribute to the future of Mozilla. The second day was dedicated to the current state of the program, where Reps had a chance to chat with the Reps council and its current work. The last 2 days were dedicated to the current work of Reps and how it is affecting the rest of the organization with talks from both staff and also volunteers presenting their communities. During the last days, we also focused on how Reps can improve, gathered feedback and suggestions for the future of the program.

And what about the future?
For the future we are focusing on 2 main pillars: 1) improving the mentorship program, so Reps can feel more supported and be able to do more 2) work more on how we can bring volunteers to product work. The last part is already happening via the campaigns. We want to work more on how we can bring volunteers earlier on product experience and ideation and nevertheless, spreading the word. A busy future is ahead for the Reps but we are ready for it. Reps onwards!
https://blog.mozilla.org/mozillareps/2021/06/22/celebrating-10-years-of-reps/
Eight years ago, I have started working at Mozilla.

Hiring, a long process
In my employment history, I have never tried to spread a large net to try to land a job, except probably for my first real job in 1995. I have always carefully chosen the company I wanted to work for. I probably applied ten times on the course of 10 years before landing a job at Mozilla.
When the Web Compatibility team was created, I applied to one of the positions available in 2013. In April 2013, from Montreal, I flew to Mountain View for a series of job interviews with different Mozilla employees. Most of the interviews were interesting but I remember one engineer was apparently not happy interviewing me and it didn't go very well. I don't remember who, but it left me with a bitter taste at the time. A couple of days later I was notified that I was not taken for the job. While disappointing, I was not surprised. I usually do not perform well during interviews, specifically when you have to demonstrate knowledge instead of articulating the way you work with knowledge. I find interviews a kind of theater.
But Mozilla came back to me and proposed me a 6 months contract, still in the Mozilla Web Compatibility team but for another role. It was not what I was initially interested by, but why not? It's when I met Lawrence Mandel, who would be my future manager if I landed the job. I liked the contact right away. I got an offer in June 2013. I signed.
Fast forward 8 years, I'm currently the manager of the Web Compatibility team.
Without people, no Web Compatibility!
The Web Compatibility team started with 3 persons: Mike Taylor, Hallvord R. M. Steen and myself and at its peak we were probably 10 persons, depending on how we count. We are currently 7 persons including myself. Talking about my 8 years anniversary doesn't make sense without mentioning the work of the team. My work is insignificant if we don't take the globability of what the team is achieving.

« Et par contre, si je communique `a mes hommes l’amour de la marche sur la mer, et que chacun d’eux soit ainsi en pente `a cause d’un poids dans le coeur, alors tu les verras bient^ot se diversifier selon leurs mille qualit'es particuli`eres. Celui-l`a tissera des toiles, l’autre dans la for^et par l’'eclair de sa hache couchera l’arbre. L’autre, encore, forgera des clous, et il en sera quelque part qui observeront les 'etoiles afin d’apprendre `a gouverner. Et tous cependant ne seront qu’un. Cr'eer le navire ce n’est point tisser les toiles, forger les clous, lire les astres, mais bien donner le go^ut de la mer qui est un, et `a la lumi`ere duquel il n’est plus rien qui soit contradictoire mais communaut'e dans l’amour. »
Antoine de Saint-Exup'ery. « Citadelle. »
Since the beginning of 2021,
Dennis has drastically reduced the number of old diagnosis that were on top (or at the bottom?) of our pile. He is also now the module owner for Site Interventions, which help Mozilla to hotfix websites. When a site is broken and the outreach is unlikely to be unsuccessful, this one of the ways we have to fix the website on the fly so the people can continue to enjoy using troubled websites.
James is the mind and the smooth operator behind Web Platform Tests at Mozilla. He is doing an amazing job at encouraging Mozilla engineers to develop more Web Platform tests. He makes sure that everything is synchronized with other vendors. Web Platform Tests are essential to be able to discover bugs in specifications and differences in implementations. He is also the core person for the work on BiDi at Mozilla. BiDi is another important part of the puzzle of Web Compatibility. Testing manually websites is costly. Webdriver comes here to make it possible for automating the tests of websites functionalities. If the cost is lower, web developers can test their websites in more than one browser and discover and fix their webcompatibility issues before we discover them.
Ksenia is the owner of
On the internet you are never alone, and because of that at Mozilla we know that we can’t work to build a better internet alone. We believe in and rely on our community — from our volunteers, to our staff, to our users and even the parent’s of our staff (who also happen to be some of our power users). For Father’s Day, Mozilla’s Natalie Linden sat down with her father, big wave surf legend and surfboard maker, Gary Linden to talk the ocean, the internet and where humanity goes from here.
We should probably start by telling people who we are. I am Natalie Linden, the Director of the Creative Studio in Mozilla marketing.
And I’m Gary Linden. I’m your father. That’s probably my best accomplishment.
Awww Dad.
I make surfboards, run surfing events and surf. I’m semi-retired. Sort of.

I don’t think you’re giving yourself enough credit. When I tell people I’m Gary Linden’s daughter, they always say “Gary Linden?! He’s a legend!”
You know, if you’re involved in something for all your life, and you do a reasonably good job, you’ll get old and then you’ll be the oldest one around. So of course you’ll be the legend!
One of the things you’re the oldest guy doing is paddling into really, really big waves.
Yeah I’m a big wave surfer, that’s been my passion. I wasn’t afraid of the ocean or of big waves, and that set me apart from most other surfers. So I got admission to a club that was pretty exclusive. And that was pretty cool. Then I started the Big Wave World Tour so younger surfers could have a career path to becoming a big wave rider. Big wave surfing takes more time and resources: you have to have the means to travel, the boards are more expensive. We weren’t seeing the younger people really be able to surf the big waves so we weren’t seeing what could be done in the peak athletic performance years. I’m pretty proud of that tour.
One of the questions I was going to ask you is why you do what you do, and I think you’re starting to answer that. The way you’ve always described it to me is that from the first time you rode a wave on a surfboard, you knew that’s what you wanted to do, and you’ve oriented your whole life around being able to surf as much as possible.
Yes. Even before I rode a surfboard, my father took me to the ocean and taught me to play in the waves, and about the currents, and body surfing. The freedom of it was like nothing else. I had asthma and hay fever, and when I was in the ocean I didn’t feel any of that. Whereas on land the pollens and the dryness just made being on the land kind of miserable. Like a fish out of water in a lot of ways. It was always rewarding for me to go into the ocean. It goes beyond just feeling good. It’s a state of mind as well.

So you started making surfboards, too.
I started making surfboards because surfing went into a transitional period — we all had longboards and then in the 70s, some of the Australians started experimenting with boards that were a foot shorter. There was nobody in San Diego making them, so I got a blank and shaped a board. And then I started making them for my friends, and it just set me on a path. But I’ve always made surfboards so that I could have the boards I needed to surf. If somebody else wanted one, that was fine, but I wasn’t making it for them. I was making it for me. Because surfing — not surfboard making — was my primary focus.
How has the internet changed what you do?
Well first, the internet has made it incredibly easy to find out where the best waves of the day are. There are cameras all over the world now and you get surf reports. You don’t have to drive to the beach — you can live inland and plan ahead. And this year with the pandemic, live surfing competition was pretty much shut down. So a friend and I created a virtual surfing world tour called Surf Web Series, where we could
Real talk: this web stuff can get confusing. And it’s really important that we all understand how it works, so we can be as informed and empowered as possible. Let’s start by breaking down the differences between the internet, browsers, search engines and websites. Lots of us get these four things confused with each other and use them interchangeably, though they are different. In this case, the old “information superhighway” analogy comes in handy.

Let’s start by breaking down the differences between internet, search engine, and browser. Lots of us get these three things confused with each other.
In this case, the old “internet superhighway” analogy comes in handy.
The internet
The internet is the superhighway’s system of roads, bridges and tunnels. It is the technical network and infrastructure that connect all the computers and devices that are online together across the world. Being connected to the internet means devices, and whoever is using them, can communicate with each other and share information.
Browsers
The browser is the car that gets you everywhere. You type a destination into the address bar and zoooom: your browser takes you anywhere on the internet. Firefox is a browser — one built specifically for people, not profit.
Search engines
Search engines like Yahoo, Google, Bing and DuckDuckGo are the compass and the map. You tell a search engine an idea of where you want to go by typing your search terms, and it gives you some possible destinations. Search engines are websites, and they can also be apps. More on apps later.
Websites and the web
Effectively, you drive along the internet highway, stopping at whatever towns, stores and roadside attractions catch your fancy, aka websites. Websites are the specific destinations you visit throughout the internet. This is the content — the webpages, websites, documents, social media, news, videos, images and so on that you view and experience via the internet. The “web” (which is short for “world wide web”, hence “www”) is the collection of all these websites.
Apps
Any program that you download and install on your device is an app. Browsers are apps. Some websites — like Facebook, YouTube, Spotify and The New York Times, for example — double up as apps, so you get the same or similar content on the app as you would on the corresponding website.
The key thing to remember about apps, especially social media apps, is that while they are accessed via a connection to the internet (the infrastructure), content on them does not represent the full web. It’s just a slice. In addition, not everything published in an app is necessarily publicly accessible on the web.
The web is the largest software platform ever, a great equalizer that works on any device, anywhere. By design, the web is open for anyone to participate in. Read more about Mozilla’s mission to keep the internet open and accessible to all.
Know someone who gets these things mixed up? It’s easy to do!
Pass this article along to share the knowledge.
The post What is the difference between the internet, browsers, search engines and websites? appeared first on The Mozilla Blog.
https://blog.mozilla.org/en/internet-culture/mozilla-explains/internet-search-engine-browser/
Mozilla has always been about community and understanding that the internet is a better place when we work together. Ten years ago, Mozilla created the Reps program to add structure to our regional programs, further building off of our open source foundation. Over the last decade, the program has helped activate local communities in over 50 countries, tested Mozilla products and launches before they were released to the public, and collaborated on some of our biggest projects.
The last decade also has seen big shifts in technology, and it has only made us at Mozilla more thankful for our volunteers and more secure in our belief that community and collaboration are key to making a better internet.
“As the threats to a healthy internet persist, our network of collaborative communities and contributors continues to provide an essential role in helping us make it better,” said Mitchell Baker, CEO and Chairwoman of Mozilla. “These passionate Mozillians give up their time to educate, empower and mobilize others to support Mozilla’s mission and expand the impact of the open source ecosystem – a critical part of making the internet more accessible and better than how they found it.”
Ahead of our 10 year anniversary virtual celebration for the Reps Mozilla program, or ReMo for short, we connected with six of the 205 current reps to talk about their favorite parts of the internet, why community is so important, and where the Reps program can go from here.
Please introduce yourself! What community do you represent and how long have you been in the Mozilla Reps program?
Ioana Chiorean: I am the Reps Module Owner at this time. I am part of Mozilla Romania, but have always been involved in technical communities directly, like QA, Firefox OS and support. My latest roles have been more on the advocacy side as Tech Speaker and building the Reps community. I’ve been in the Reps program since 2011.
Irvin Chen: I’m a Mozilla Rep from Taipei, Taiwan. I’m representing the Mozilla Taiwan Community, one of the oldest Mozilla communities.
Lidya Christina: I’m a Mozilla Reps from Jakarta, Indonesia. I’ve been involved in the Reps program for more than two years now. I am also part of the review and resources team, provide operational support for the Mozilla community space in Jakarta, and a translator for the Mozilla localization project.
Michael Kohler: I have been part of the Reps program since 2012, and I am currently a Reps Peer helping out with strategy-related topics within the Reps program. After organizing events and building the community in Switzerland, I moved to Berlin in 2018 and started to help there. In the past 13 years I have worked on different Mozilla products such as Firefox, Firefox OS and Common Voice.
Pranshu Khanna: I’m Pranshu Khanna, a Reps Council Member for the current term and a Rep from Mozilla Gujarat. I started my journey as a Firefox Student Ambassador from an event in January 2016, where my first contribution was to introduce the world of Open Source to over 150 college students. Since then, I’ve spoken to thousands of people about privacy, open web and open source to people across the world and have been a part of hundreds of events, programs and initiatives.
Robert Sayles: Currently, I reside in Dallas, Texas, and I represent the North American community. I first joined the Mozilla Reps program in 2012, focusing mainly on my volunteer contribution to the Mozilla Festival Volunteer Coordinator 2013.

What part of the internet do you get the most joy from?
Irvin: For me, the most exciting thing about the internet is that no matter who you are or where you are located, you can always find and make some friends on the internet. For example, apart from each other, we could still collaborate online and successfully host the release party of Firefox in early 2000. Mozilla gives us, the local community contributors, the opportunity to participate, contribute and learn from each other on a global scale.
Michael: Nyan Cat is probably the part of the internet that I get most joy from. Kidding aside, for me the best part of the internet is probably the possibility to learn new astonishing facts about things I otherwise would never have looked up. All the knowledge is a

curl is a command line tool and library for doing Internet data transfers. It has been around for a loooong time (over 23 years) but there is still a flood of new things being added to it and development being made, to take it further and to keep it relevant today and in the future.
I’m the lead developer and head maintainer of the curl project.
How do we decide what goes into curl? And perhaps more importantly, what does not get accepted into curl?
Let’s look how this works in the curl factory.
Stick to our principles
curl has come this far by being reliable, trusted and familiar. We don’t rock the boat: curl does Internet transfers specified as URLs and it doesn’t parse or understand the content it transfers. That goes for libcurl too.
Whatever we add should stick to these constraints and core principles, at least. Then of course there are more things to consider.
A shortlist of things I personally want to see
I personally usually have a shortlist of a few features I personally want to work on in the coming months and maybe half year. Items I can grab when other things are slow or if I need a change or fun thing to work on a rainy day. These items are laid out in the ROADMAP document – which also tends to be updated a little too infrequently…
There’s also the TODO document that lists things we consider could be good to do and KNOWN_BUGS that lists known shortcomings we want to address.
Sponsored works have priority
I’m the lead developer of the curl project but I also offer commercial support and curl services to allow me to work on curl full-time. This means that paying customers can get a “priority lane” into landing new features or bug-fixes in future releases of curl. They still need to suit the project though, we don’t abandon our principles even for money. (Contact me to learn how I can help you get your proposed changes done!)
Keep up with where the world goes
All changes and improvements that help curl keep up with and follow where the Internet protocol community is moving, are considered good and necessary changes. The curl project has always been on the front-lines of protocols and that is where we want to remain. It takes a serious effort.
Asking the community
Every year around the May time frame we do a “user survey” that we try to get as many users as possible to respond to. It asks about user patterns, what’s missing and how things are working.
The results from that work provide good feedback on areas to improve and help us identify features our community think curl lacks etc. (The 2020 survey analysis)
Even outside of the annual survey, discussions on the mailing list is a good way for getting direct feedback on questions and ideas and users very often bring up their ideas and suggestions using those channels.
Ideas are easy, code is harder
Actually implementing and providing a feature is a lot harder than just providing an idea. We almost drown among all the good ideas people propose we might or could do one day. What someone might think is a great idea may therefore still not be implemented very soon. Because of the complexity of implementing it or because of lack of time or energy etc.
But at the same time: oftentimes, someone needs to bring the idea or crack the suggestion for it to happen.
It needs to exist to be considered
Related to the previous section. Code and changes that exist, that are provided are of course much more likely to actually end up in curl than abstract ideas. If a pull-request comes to curl and the change adheres to our standards and meet the requirements mentioned in this post, then the chances are very good that it will be accepted and merged.
As I am currently the only one working on curl professionally (ie I get paid to do it). I can rarely count on or assume work submissions from other team members. They usually show up more or less by surprise, which of course is awesome in itself but also makes such work and features very hard to plan for ahead of time. Sometimes people bring new features. Then we deal with them!
Half-baked is not good enough
A decent amount of all pull requests submitted to the project never get
In a letter sent to the White House on Friday, June 11, 2021, Mozilla joined over 50 advocacy groups and unions asking President Biden and Vice President Harris to appoint the fifth FCC Commissioner. Without a full team of appointed Commissioners, the Federal Communications Commission (FCC) is limited in its ability to move forward on crucial tech agenda items such as net neutrality and on addressing the country’s digital divide.
“Net neutrality preserves the environment that creates room for new businesses and new ideas to emerge and flourish, and where internet users can choose freely the companies, products, and services that they want to interact with and use. In a marketplace where consumers frequently do not have access to more than one internet service provider (ISP), these rules ensure that data is treated equally across the network by gatekeepers. We are committed to restoring the protections people deserve and will continue to fight for net neutrality,” said Amy Keating, Mozilla’s Chief Legal Officer.
In March 2021, we sent a joint letter to the FCC asking for the Commission to reinstate net neutrality as soon as it is in working order. Mozilla has been one of the leading voices in the fight for net neutrality for almost a decade, together with other advocacy groups. Mozilla has defended user access to the internet, in the US and around the world. Our work to preserve net neutrality has been a critical part of that effort, including our lawsuit against the FCC to keep these protections in place for users in the US.
The post Mozilla joins call for fifth FCC Commissioner appointment appeared first on Open Policy & Advocacy.
In the afternoon of October 17, 2013 we merged the first config file ever that would use Travis CI for the curl project using the nifty integration at GitHub. This was the actual introduction of the entire concept of building and testing the project on every commit and pull request for the curl project. Before this merge happened, we only had our autobuilds. They are systems run by volunteers that update the code from git maybe once per day, build and run the tests and then upload all the logs.
Don’t take this wrong: the autobuilds are awesome and have helped us make curl what it is. But they rely on individuals to host and admin the machines and to setup the specific configs that are tested.
With the introduction of “proper” CI, the configs that are tested are now also hosted in git and allows the project members to better control and adjust the tests and configs, plus that we can run them on already on pull-requests so that we can verify code before merge instead of having to first merge the code to master before the changes can get verified.
Seriously. Always.
Travis provided a free service with a great promise.

In 2017 we surpassed 10 jobs per commit, all still on Travis.
In early 2019 we reached 30 jobs per commit, and at that time we started to use and spread out the work on more CI services. Travis would still remain as the one we’d lean on the heaviest. It was there and we had custom-written a bunch of jobs for it and it performed well.
Travis even turned some levers for us so that we got more parallel processing powers than on the regular open source tier, and we listed them as sponsors of the curl project for their gracious help. This may or may not be related to the fact that I met Josh Kalderimis (co-founder of travis) in 2019 and we talked about curl’s use of it and they possibly helping us more.
Transition to death
This year, 2021, the curl project runs around 100 CI jobs per commit and PR. 33 of them ran on Travis when we were finally pushed over from travis-ci.org to their new travis-ci.com domain. A transition they’d been advertising for a while but wasn’t very clearly explained or motivated in my eyes.
The new domain also implied new rules and new tiers, we quickly learned. Now we would have to apply to be recognized as an open source project (after 7.5 years of using their services as an open source project). But also, in order to get to take advantage of their free tier being an open source project was no longer enough. Among the new requirements on the project was this:
Project must not be sponsored by a commercial company or
organization (monetary or with employees paid to work on the project)
We’re a small independent open source project, but yes I work on curl full-time thanks to companies paying for curl support. I’m paid to work on curl and therefore we cannot meet that requirement.
Not eligible but still there
I’m not sure why, but apparently we still got free “credits” for running CI on Travis. The CI jobs kept working and I think maybe I sighed a little from relief – of course I did it prematurely as it only took us a few days into the month of June until we had run out of the free credits. There’s no automatic refill but we can apparently ask for more. We asked, but many days after having asked we still had no more credits and no CI jobs could run on Travis anymore. CI on Travis at the same level as before would cost more than 249 USD/month. Maybe not so much “it will always be free”.
The 33 jobs on Travis were there for a purpose. They’re prerequisites for us to develop and ship a quality product. Without the CI jobs running, we risk landing bad code. This was not a sustainable situation.
We looked for alternative services and we quickly got several offers of help and assistance.
New service
Friends from both Zuul CI and Circle CI stepped up and helped us started to get CI jobs transitioned over from Travis over to their new homes.
At June 14th 2021, we officially had no more jobs running on Travis.
Visualized as a graph, we can see the Travis jobs “falling off a cliff” with Zuul rising to the challenge:

 The second “Cross Team Collaboration Fun Times” (CTCFT) meeting will take place one week from today, on 2021-06-21 (in your time zone)! This post describes the main agenda items for the meeting; you’ll find the full details (along with a calendar event, zoom details, etc) on the CTCFT website.
The second “Cross Team Collaboration Fun Times” (CTCFT) meeting will take place one week from today, on 2021-06-21 (in your time zone)! This post describes the main agenda items for the meeting; you’ll find the full details (along with a calendar event, zoom details, etc) on the CTCFT website.
Afterwards: Social hour
After the CTCFT this week, we are going to try an experimental social hour. The hour will be coordinated in the #ctcft stream of the rust-lang Zulip. The idea is to create breakout rooms where people can gather to talk, hack together, or just chill.
Turbowish and Tokio console
Presented by: pnkfelix and Eliza (hawkw)
Rust programs are known for being performant and correct – but what about when that’s not true? Unfortunately, the state of the art for Rust tooling today can often be a bit difficult. This is particularly true for Async Rust, where users need insights into the state of the async runtime so that they can resolve deadlocks and tune performance. This talk discuss what top-notch debugging and tooling for Rust might look like. One particularly exciting project in this area is tokio-console, which lets users visualize the state of projects build on the tokio library.
Guiding principles for Rust
Presented by: nikomatsakis
As Rust grows, we need to ensure that it retains a coherent design. Establishing a set of “guiding principles” is one mechanism for doing that. Each principle captures a goal that Rust aims to achieve, such as ensuring correctness, or efficiency. The principles give us a shared vocabulary to use when discussing designs, and they are ordered so as to give guidance in resolving tradeoffs. This talk will walk through a draft set of guiding principles for Rust that nikomatsakis has been working on, along with examples of how they those principles are enacted through Rust’s language, library, and tooling.
http://smallcultfollowing.com/babysteps/blog/2021/06/14/ctcft-2021-06-21-agenda/
WebRTC is a standard real-time communication protocol built directly into modern web browsers. It enables the creation of video conferencing services which do not require participants to download additional software. Many services make use of it and it almost always works out of the box.
The reason it just works is that it uses a protocol called ICE to establish a connection regardless of the network environment. What that means however is that in some cases, your video/audio connection will need to be relayed (using end-to-end encryption) to the other person via third-party TURN server. In addition to adding extra network latency to your call that relay server might overloaded at some point and drop or delay packets coming through.
Here's how to tell whether or not your WebRTC calls are being relayed, and how to ensure you get a direct connection to the other host.
Testing basic WebRTC functionality
Before you place a real call, I suggest using the official test page which will test your camera, microphone and network connectivity.
Note that this test page makes use of a Google TURN server which is locked to particular HTTP referrers and so you'll need to disable privacy features that might interfere with this:
- Brave: Disable Shields entirely for that page (Simple view) or allow all cookies for that page (Advanced view).
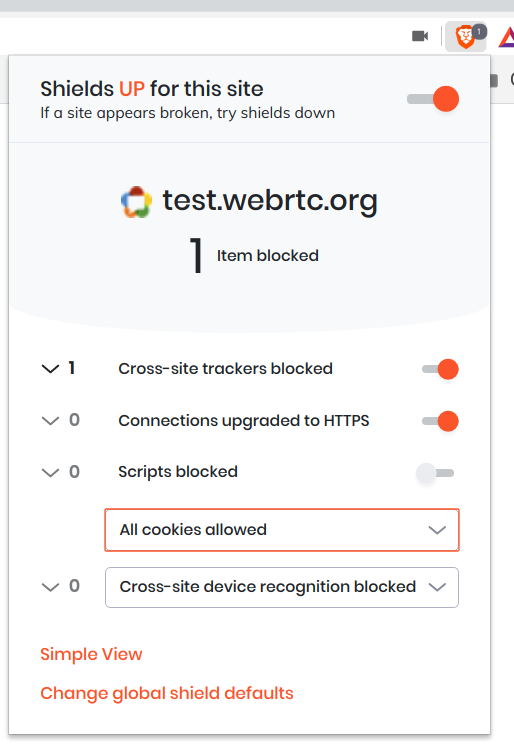
Firefox: Ensure that
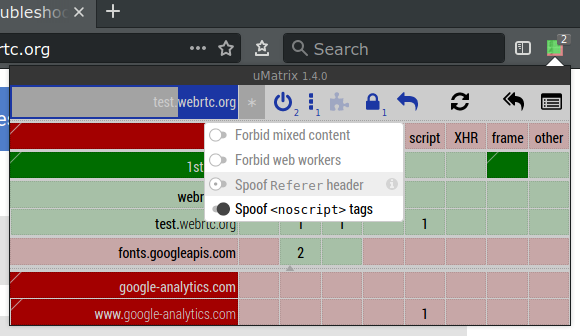
http.network.referer.spoofSourceis set tofalseinabout:config, which it is by default.uMatrix: The "Spoof
Refererheader" option needs to be turned off for that site.
Checking the type of peer connection you have
Once you know that WebRTC is working in your browser, it's time to establish a connection and look at the network configuration that the two peers agreed on.
My favorite service at the moment is Whereby (formerly Appear.in), so I'm going to use that to connect from two different computers:
canadais a laptop behind a regular home router without any port forwarding.siberiais a desktop computer in a remote location that is also behind a home router, but in this case its internal IP address (192.168.1.2) is set as the DMZ host.
Chromium
For all Chromium-based browsers, such as Brave, Chrome, Edge, Opera and
Vivaldi, the debugging page you'll need to open is called
chrome://webrtc-internals.
Look for RTCIceCandidatePair lines and expand them one at a time until you
find the one which says:
state: succeeded(orstate: in-progress)nominated: truewritable: true
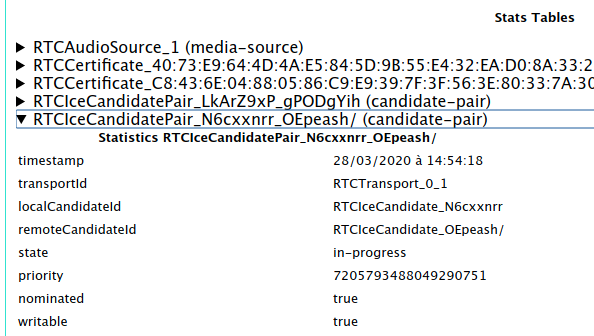
Then from the name of that pair (N6cxxnrr_OEpeash in the above example)
find the two matching RTCIceCandidate lines (one local-candidate and one
remote-candidate) and expand them.
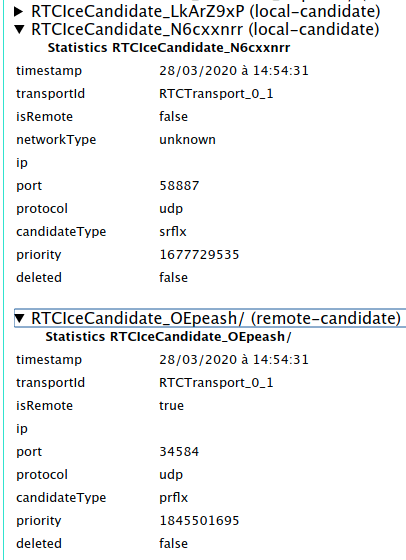
In the case of a direct connection, I saw the following on the
remote-candidate:
ipshows the external IP address ofsiberiaportshows a random number between 1024 and 65535candidateType: srflx
and the following on local-candidate:
ipshows the external IP address ofcanadaportshows a random number between 1024 and 65535candidateType: prflx
Almost a year ago we had a push at Element to convert the remaining instances of Twisted’s inlineCallbacks to use native async/await syntax from Python [1]. Eventually this work got covered by issue #7988 (which is the original basis for this blogpost).
Note that Twisted itself gained some …
https://patrick.cloke.us/posts/2021/06/11/converting-twisteds-inlinecallbacks-to-async/
Please note some of the information provided in this report may be subject to change as we are sometimes sharing information about projects that are still in early stages and are not final yet.
Welcome!
Are you a locale leader and want us to include new members in our upcoming reports? Contact us!
New content and projects
Firefox 89 (MR1)
On June 1st, Mozilla released Firefox 89. That was a major milestone for Firefox, and a lot of work went into this release (internally called MR1, which stands for Major Release 1). If this new update was well received — see for example this recent article from ZDNet — it’s also thanks to the amazing work done by our localization community.
For the first time in over a decade, we looked at Firefox holistically, making changes across the board to improve messages, establish a more consistent tone, and modernize some dialogs. This inevitably generated a lot of new content to localize.
Between November 2020 and May 2021, we added 1637 strings (6798 words). To get a point of reference, that’s almost 14% of the entire browser. What’s amazing is that the completion levels didn’t fall drastically:
- Nov 30, 2020: 89.03% translated across all shipping locales, 99.24% for the top 15 locales.
- May 24, 2021: 87.85% translated across all shipping locales, 99.39% for the top 15 locales.
The completion level across all locales is lower, but that’s mostly due to locales that are completely unmaintained, and that we’ll likely need to drop from release later this year. If we exclude those 7 locales, overall completion increased by 0.10% (to 89.84%).
Once again, thanks to all the volunteers who contributed to this successful release of Firefox.
What’s new or coming up in Firefox desktop
These are the important deadlines for Firefox 90, currently in Beta:
- Firefox 90 will be released on July 13. It will be possible to update localizations until July 4.
- Firefox 91 will move to beta on July 12 and will be released on August 10.
Keep in mind that Firefox 91 is also going to be the next ESR version. Once that moves to release, it won’t generally be possible to update translations for that specific version.
Talking about Firefox 91, we’re planning to add a new locale: Scots. Congratulations to the team for making it so quickly to release!
On a final note, expect to see more updates to the Firefox L10n Newsletter, since this has proved to be an important tool to provide more context to localizers, and help them with testing.
What’s new or coming up in mobile
Next l10n deadlines for mobile projects:
- Firefox for Android v91: July 12
- Firefox for iOS v34.1: June 9
Once more, we want to thank all the localizers who worked hard for the MR1 (Proton) mobile release. We really appreciate the time and effort spent on helping ensure all these products are available globally (and of course, also on desktop). THANK YOU!
What’s new or coming up in web projects
AMO
There are a few strings exposed to Pontoon that do not require translation. Only Mozilla staff in the admin role to the product would be able to see them. The developer for the feature will add a comment of “no need to translate” or context to the string at a later time. We don’t know when this will be added. For the time being, please ignore them. Most of the strings with a source string ID of src/olympia/scanners/templates/admin/* can be ignored. However, there are still a handful of strings that fall out of the category.
MDN
The project continues to be on hold in Pontoon. The product repository doesn’t pick up any changes made in Pontoon, so fr, ja, zh-CN, and zh-TW are now read-only for now. The MDN site, however, is still maintaining the articles localized in these languages plus ko, pt-BR, and ru.
Mozilla.org
The websites in ar, hi-IN, id, ja, and ms languages are now fully localized through vendor service since our last report. Communities of these languages are encouraged to help promote the sites through various social media platforms to increase download, conversion and create new profiles.
What’s new or coming up
In a previous post, I wrote about a new set of technologies “Privacy Preserving Advertising”, which are intended to allow for advertising without compromising privacy. This post discusses one of those proposals–Federated Learning of Cohorts (FLoC)–which Chrome is currently testing. The idea behind FLoC is to make it possible to target ads based on the interests of users without revealing their browsing history to advertisers. We have conducted a detailed analysis of FLoC privacy. This post provides a summary of our findings.
In the current web, trackers (and hence advertisers) associate a cookie with each user. Whenever a user visits a website that has an embedded tracker, the tracker gets the cookie and can thus build up a list of the sites that a user visits. Advertisers can use the information gained from tracking browsing history to target ads that are potentially relevant to a given user’s interests. The obvious problem here is that it involves advertisers learning everywhere you go.
FLoC replaces this cookie with a new “cohort” identifier which represents not a single user but a group of users with similar interests. Advertisers can then build a list of the sites that all the users in a cohort visit, but not the history of any individual user. If the interests of users in a cohort are truly similar, this cohort identifier can be used for ad targeting. Google has run an experiment with FLoC; from that they’ve stated that FLoC provides 95% of the per-dollar conversion rate when compared to interest-based ad targeting using tracking cookies.
Our analysis shows several privacy issues that we believe need to be addressed:
Cohort IDs can be used for tracking
Although any given cohort is going to be relatively large (the exact size is still under discussion, but these groups will probably consist of thousands of users), that doesn’t mean that they cannot be used for tracking. Because only a few thousand people will share a given cohort ID, if trackers have any significant amount of additional information, they can narrow down the set of users very quickly. There are a number of possible ways this could happen:
Browser Fingerprinting
Not all browsers are the same. For instance, some people use Chrome and some use Firefox; some people are on Windows and others are on Mac; some people speak English and others speak French. Each piece of user-specific variation can be used to distinguish between users. When combined with a FLoC cohort that only has a few thousand users, a relatively small amount of information is required to identify an individual person or at least narrow the FLoC cohort down to a few people. Let’s give an example using some numbers that are plausible. Imagine you have a fingerprinting technique which divides people up into about 8000 groups (each group here is somewhat bigger than a ZIP code). This isn’t enough to identify people individually, but if it’s combined with FLoC using cohort sizes of about 10000, then the number of people in each fingerprinting group/FLoC cohort pair is going to be very small, potentially as small as one. Though there might be larger groups that can’t be identified this way, that is not the same as having a system that is free from individual targeting.
Multiple Visits
People’s interests aren’t constant and neither are their FLoC IDs. Currently, FLoC IDs seem to be recomputed every week or so. This means that if a tracker is able to use other information to link up user visits over time, they can use the combination of FLoC IDs in week 1, week 2, etc. to distinguish individual users. This is a particular concern because it works even with modern anti-tracking mechanisms such as Firefox’s Total Cookie Protection (TCP). TCP is intended to prevent trackers from correlating visits across sites but not multiple visits to one site. FLoC restores cross-site tracking even if users have TCP enabled.
FLoC leaks more information than you want
With cookie-based tracking, the amount of information a tracker gets is determined by the number of sites it is embedded on. Moreover, a site which wants to learn about user interests must itself participate in tracking the user across a large number of sites, work with some reasonably
In 2018, we started pioneering work on securing one of the oldest parts of the Internet, one that had till then remained largely untouched by efforts to make the web safer and more private: the Domain Name System (DNS). We passed a key milestone in that endeavor last year, when we rolled out DNS-over-HTTPS (DoH) technology by default in the United States, thus improving privacy and security for millions of people. Given the transformative nature of this technology and in line with our mission commitment to transparency and collaboration, we have consistently sought to implement DoH thoughtfully and inclusively. Today we’re sharing our latest update on that continued effort.
Between November 2020 and January 2021 we ran a public comment period, to give the broader community who care about the DNS – including human rights defenders; technologists; and DNS service providers – the opportunity to provide recommendations for our future DoH work. Specifically, we canvassed input on our Trusted Recursive Resolver (TRR) policies, the set of privacy, security, and integrity commitments that DNS recursive resolvers must adhere to in order to be considered as default partner resolvers for Mozilla’s DoH roll-out.
We received rich feedback from stakeholders across the world, and we continue to reflect on how it can inform our future DoH work and our TRR policies. As we continue that reflection, we’re today publishing the input we received during the comment period – acting on a commitment to transparency that we made at the outset of the process. You can read the comments here.
During the comment period and prior, we received substantial input on the blocklist publication requirement of our TRR policies. This requirement means that resolvers in our TRR programme must publicly release the list of domains that they block access to. This blocking could be the result of either legal requirements that the resolver is subject to, or because a user has explicitly consented to certain forms of DNS blocking. We are aware of the downsides associated with blocklist publication in certain contexts, and one of the primary reasons for undertaking our comment period was to solicit constructive feedback and suggestions on how to best ensure meaningful transparency when DNS blocking takes place. Therefore, while we reflect on the input regarding our TRR policies and solutions for blocking transparency, we will relax this blocklist publication requirement. As such, current or prospective TRR partners will not be required to mandatorily publish DNS blocklists from here on out.
DoH is a transformative technology. It is relatively new and, as such, is of interest to a variety of stakeholders around the world. As we bring the privacy and security benefits of DoH to more Firefox users, we will continue our proactive engagement with internet service providers, civil society organisations, and everyone who cares about privacy and security in the internet ecosystem.
We look forward to this collaborative work. Stay tuned for more updates in the coming months.
The post Working in the open: Enhancing privacy and security in the DNS appeared first on Open Policy & Advocacy.
How we collaborated on a major redesign to clean up debt and refresh the product.

Introducing the redesigned Firefox browser, featuring the Alpenglow them
We just launched a major redesign of the Firefox desktop browser to 240 million users. The effort was so large that we put our full content design team — all two of us — on the case. Over the course of the project, we updated nearly 1,000 strings, re-architected our menus, standardized content patterns, established new principles, and cleaned up content debt.
Creating and testing language to inform visual direction
The primary goal of the redesign was to make Firefox feel modern. We needed to concretize that term to guide the design and content decisions, as well as to make the measurement of visual aesthetics more objective and actionable.
To do this, we used the Microsoft Desirability Toolkit, which measures people’s attitudes towards a UI with a controlled vocabulary test. Content design worked with our UX director to identify adjectives that could embody what “modern” meant for our product. The UX team used those words for early visual explorations, which we then tested in a qualitative usertesting.com study.
Based on the results, we had an early idea of where the designs were meeting goals and where we could make adjustments.

Sampling of qualitative feedback from the visual appeal test with word cloud and participant comments.
Improving way-finding in menus
Over time, our application menu had grown unwieldy. Sub-menus proliferated like dandelions. It was difficult to scan, resulting in high cognitive load. Grouping of items were not intuitive. By re-organizing the items, prioritizing high-value actions, using clear language, and removing icons, the new menu better supports people’s ability to move quickly and efficiently in the Firefox browser.
To finalize the menu’s information architecture, we leveraged a variety of inputs. We studied usage data, reviewed past user research, and referenced external sources like the Nielsen Norman Group for menu design best practices. We also consulted with product managers to understand the historical context of prior decisions.
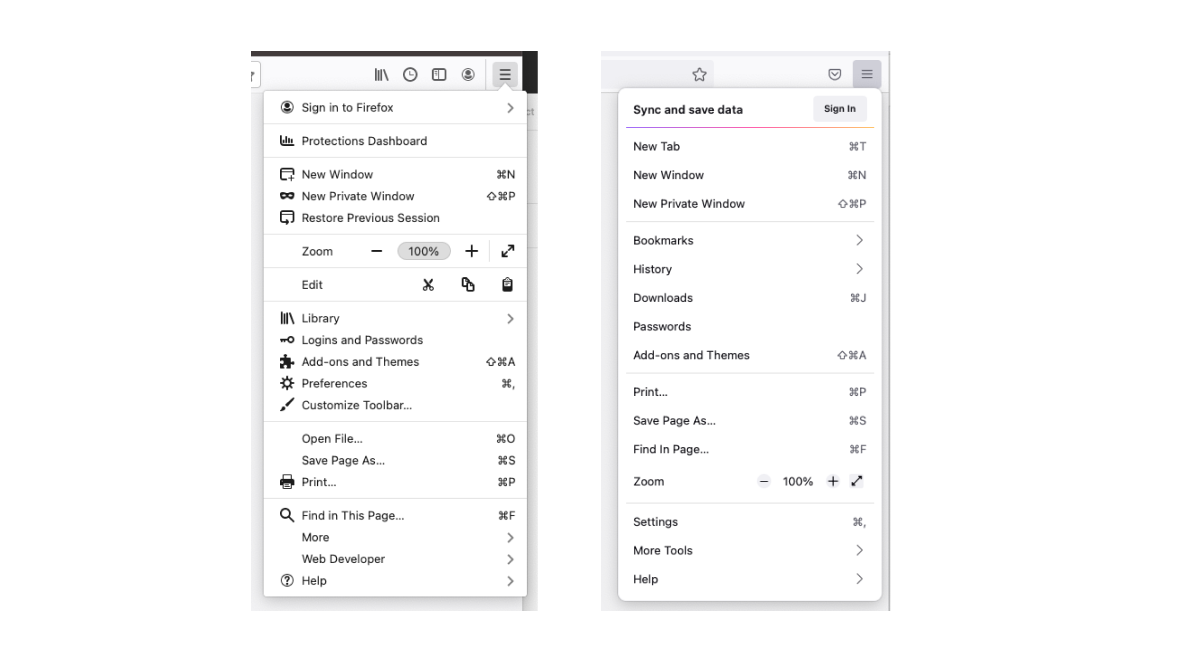
The Firefox application menu, before and after the information architecture redesign.
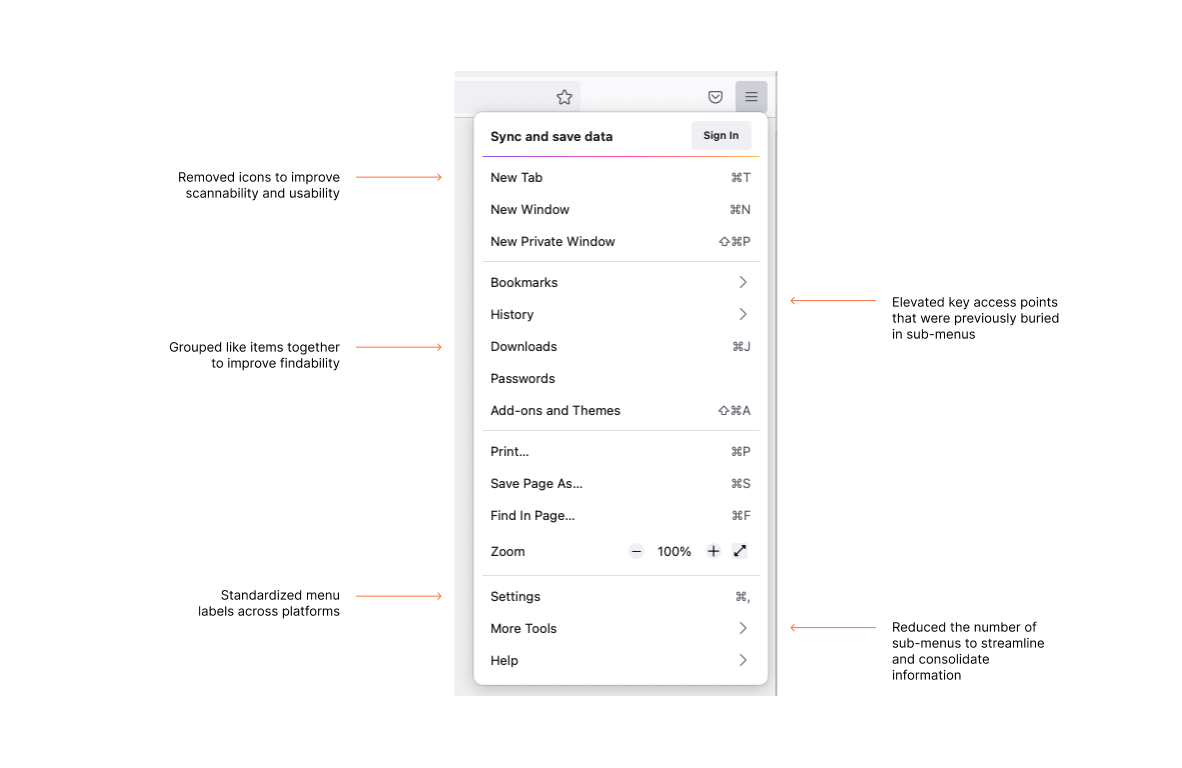
Changes made to the Firefox application menu include removing icons, grouping like items together, and reducing the number of sub-menus.
As a final step, we created principles to document the rationale behind the menu redesign so a consistent approach could be applied to other menu-related decisions across the product and platforms.

Content design developed these principles to help establish a consistent approach for other menus in the product.
Streamlining high-visibility messages
Firefox surfaces a number of messages to users while they use the product. Those messages had dated visuals, inconsistent presentation, and clunky copy.
We partnered with our UX and visual designers to redesign those message types using a content-first approach. By approaching the redesign this way, we better ensured the resulting components supported the message needs. Along the way, we were able to make some improvements to the existing copy and establish guidelines so future modals, infobars, and panels would be higher quality.
Cleaning up paper cuts in modal dialogues
A modal sits on top of the main
We successfully deployed ThreadSanitizer in the Firefox project to eliminate data races in our remaining C/C++ components. In the process, we found several impactful bugs and can safely say that data races are often underestimated in terms of their impact on program correctness. We recommend that all multithreaded C/C++ projects adopt the ThreadSanitizer tool to enhance code quality.
What is ThreadSanitizer?
ThreadSanitizer (TSan) is compile-time instrumentation to detect data races according to the C/C++ memory model on Linux. It is important to note that these data races are considered undefined behavior within the C/C++ specification. As such, the compiler is free to assume that data races do not happen and perform optimizations under that assumption. Detecting bugs resulting from such optimizations can be hard, and data races often have an intermittent nature due to thread scheduling.
Without a tool like ThreadSanitizer, even the most experienced developers can spend hours on locating such a bug. With ThreadSanitizer, you get a comprehensive data race report that often contains all of the information needed to fix the problem.
 ThreadSanitizer Output for this example program (shortened for article)
ThreadSanitizer Output for this example program (shortened for article)
One important property of TSan is that, when properly deployed, the data race detection does not produce false positives. This is incredibly important for tool adoption, as developers quickly lose faith in tools that produce uncertain results.
Like other sanitizers, TSan is built into Clang and can be used with any recent Clang/LLVM toolchain. If your C/C++ project already uses e.g. AddressSanitizer (which we also highly recommend), deploying ThreadSanitizer will be very straightforward from a toolchain perspective.
Challenges in Deployment
Benign vs. Impactful Bugs
Despite ThreadSanitizer being a very well designed tool, we had to overcome a variety of challenges at Mozilla during the deployment phase. The most significant issue we faced was that it is really difficult to prove that data races are actually harmful at all and that they impact the everyday use of Firefox. In particular, the term “benign” came up often. Benign data races acknowledge that a particular data race is actually a race, but assume that it does not have any negative side effects.
While benign data races do exist, we found (in agreement with previous work on this subject [1] [2]) that data races are very easily misclassified as benign. The reasons for this are clear: It is hard to reason about what compilers can and will optimize, and confirmation for certain “benign” data races requires you to look at the assembler code that the compiler finally produces.
Needless to say, this procedure is often much more time consuming than fixing the actual data race and also not future-proof. As a result, we decided that the ultimate goal should be a “no data races” policy that declares even benign data races as undesirable due to their risk of misclassification, the required time for investigation and the potential risk from future compilers (with better optimizations) or future platforms (e.g. ARM).
However, it was clear that establishing such a policy would require a lot of work, both on the technical side as well as in convincing developers and management. In particular, we could not expect a large amount of resources to be dedicated to fixing data races with no clear product impact. This is where TSan’s suppression list came in handy:
We knew we had to stop the influx of new data races but at the same time get the tool usable without fixing all legacy issues. The suppression list (in particular the version compiled into Firefox) allowed us to temporarily ignore data races once we had them on file and ultimately