TenFourFox Feature Parity Release 16 final is now available for testing (downloads, hashes, release notes). This final version has a correctness fix to the VMX text fragment scanner found while upstreaming it to mainline Firefox for the Talos II, as well as minor outstanding security updates. Assuming no issues, it will become live on Monday afternoon-evening Pacific time (because I'm working on Labor Day).
http://tenfourfox.blogspot.com/2019/08/tenfourfox-fpr16-available.html
With the release of Firefox 69, we are pleased to welcome the 50 developers who contributed their first code change to Firefox in this release, 39 of whom were brand new volunteers! Please join us in thanking each of these diligent and enthusiastic individuals, and take a look at their contributions:
- danielvictoriadbugzilla: 1556025
- gweber: 1554881
- hgallagher: 1539115, 1560494
- ifeanyichukwunwabuokei: 1066323
- kelly.bell: 1523864
- rxu: 1547184
- u635498: 1538722
- violinmonkey42: 1532935
- Alex R.: 1561577
- Alexandru Irimovici: 1554696, 1557724, 1558625, 1559934, 1559935, 1559936, 1561889
- Alexandru Michis: 1557518
- Ali Abdoli: 1554609
- Alvina Waseem: 1533575
- AndreiH: 1527610
- Anthony Xie: 1543859
- Armando Ferreira: 1522104
- Arnold Iakab: 1512607, 1555370, 1558621, 1558764, 1559926, 1559927, 1559937, 1559939, 1559948, 1559952, 1559953
- Avneesh Singhal: 1556844
- Brad Arant: 1489458
- Bren Louis Surio: 1514372
- Bryan Kok: 1519314, 1519315
- Charlie Marlow: 1440014, 1552062, 1555150, 1555436, 1555863, 1556041,
Introduction
Modern web applications load and execute a lot more JavaScript code than they did just a few years ago. While JIT (just-in-time) compilers have been very successful in making JavaScript performant, we needed a better solution to deal with these new workloads.
To address this, we’ve added a new, generated JavaScript bytecode interpreter to the JavaScript engine in Firefox 70. The interpreter is available now in the Firefox Nightly channel, and will go to general release in October. Instead of writing or generating a new interpreter from scratch, we found a way to do this by sharing most code with our existing Baseline JIT.
The new Baseline Interpreter has resulted in performance improvements, memory usage reductions and code simplifications. Here’s how we got there:
Execution tiers
In modern JavaScript engines, each function is initially executed in a bytecode interpreter. Functions that are called a lot (or perform many loop iterations) are compiled to native machine code. (This is called JIT compilation.)
Firefox has an interpreter written in C++ and multiple JIT tiers:
- The Baseline JIT. Each bytecode instruction is compiled directly to a small piece of machine code. It uses Inline Caches (ICs) both as performance optimization and to collect type information for Ion.
- IonMonkey (or just Ion), the optimizing JIT. It uses advanced compiler optimizations to generate fast code for hot functions (at the expense of slower compile times).
Ion JIT code for a function can be ‘deoptimized’ and thrown away for various reasons, for example when the function is called with a new argument type. This is called a bailout. When a bailout happens, execution continues in the Baseline code until the next Ion compilation.
Until Firefox 70, the execution pipeline for a very hot function looked like this:

Problems
Although this works pretty well, we ran into the following problems with the first part of the pipeline (C++ Interpreter and Baseline JIT):
- Baseline JIT compilation is fast, but modern web applications like Google Docs or Gmail execute so much JavaScript code that we could spend quite some time in the Baseline compiler, compiling thousands of functions.
- Because the C++ interpreter is so slow and doesn’t collect type information, delaying Baseline compilation or moving it off-thread would have been a performance risk.
- As you can see in the diagram above, optimized Ion JIT code was only able to bail out to the Baseline JIT. To make this work, Baseline JIT code required extra metadata (the machine code offset corresponding to each bytecode instruction).
- The Baseline JIT had some complicated code for bailouts, debugger support, and exception handling. This was especially true where these features intersect!
Solution: generate a faster interpreter
We needed type information from the Baseline JIT to enable the more optimized tiers, and we wanted to use JIT compilation for runtime speed. However, the modern web has such large codebases that even the relatively fast Baseline JIT Compiler spent a lot of time compiling. To address this, Firefox 70 adds a new tier called the Baseline Interpreter to the pipeline:

The Baseline Interpreter sits between the C++ interpreter and the Baseline JIT and has elements from both. It executes all bytecode instructions with a fixed interpreter loop (like the C++ interpreter). In addition, it uses Inline Caches to improve performance and collect type information (like the Baseline JIT).
Generating an interpreter isn’t a new idea. However, we found a nice new way to do it by reusing most of the Baseline JIT Compiler code. The Baseline JIT is a template JIT, meaning each bytecode instruction is compiled to a mostly fixed sequence of
Thank you, Chris.
Chris Beard has been Mozilla Corporation’s CEO for 5 and a half years. Chris has announced 2019 will be his last year in this role. I want to thank Chris from the bottom of my heart for everything he has done for Mozilla. He has brought Mozilla enormous benefits — new ideas, new capabilities, new organizational approaches. As CEO Chris has put us on a new and better path. Chris’ tenure has seen the development of important organization capabilities and given us a much stronger foundation on which to build. This includes reinvigorating our flagship web browser Firefox to be once again a best-in-class product. It includes recharging our focus on meeting the online security and privacy needs facing people today. And it includes expanding our product offerings beyond the browser to include a suite of privacy and security-focused products and services from Facebook Container and Enhanced Tracking Protection to Firefox Monitor.
Chris will remain an advisor to the board. We recognize some people may think these words are a formula and have no deep meaning. We think differently. Chris is a true “Mozillian.” He has been devoted to Mozilla for the last 15 years, and has brought this dedication to many different roles at Mozilla. When Chris left Mozilla to join Greylock as an “executive-in-residence” in 2013, he remained an advisor to Mozilla Corporation. That was an important relationship, and Chris and I were in contact when it started to become clear that Chris could be the right CEO for MoCo. So over the coming years I expect to work with Chris on mission-related topics. And I’ll consider myself lucky to do so.
One of the accomplishments of Chris’ tenure is the strength and depth of Mozilla Corporation today. The team is strong. Our organization is strong, and our future full of opportunities. It is precisely the challenges of today’s world, and Mozilla’s opportunities to improve online life, that bring so many of us to Mozilla. I personally remain deeply focused on Mozilla. I’ll be here during Chris’ tenure, and I’ll be here after his tenure ends. I’m committed to Mozilla, and to making serious contributions to improving online life and developing new technical capabilities that are good for people.
Chris will remain as CEO during the transition. We will continue to develop the work on our new engagement model, our focus on privacy and user agency. To ensure continuity, I will increase my involvement in Mozilla Corporation’s internal activities. I will be ready to step in as interim CEO should the need arise.
The Board has retained Tuck Rickards of the recruiting firm Russell Reynolds for this search. We are confident that Tuck and team understand that Mozilla products and technology bring our mission to life, and that we are deeply different than other technology companies. We’ll say more about the search as we progress.
The internet stands at an inflection point today. Mozilla has the opportunity to make significant contributions to a better internet. This is why we exist, and it’s a key time to keep doing more. We offer heartfelt thanks to Chris for leading us to this spot, and for leading the rejuvenation of Mozilla Corporation so that we are fit for this purpose, and determined to address big issues.
Mozilla’s greatest strength is the people who respond to our mission and step forward to take on the challenge of building a better internet and online life. Chris is a shining example of this. I wish Chris the absolute best in all things.
I’ll close by stating a renewed determination to find ways for everyone who seeks safe, humane and exciting online experiences to help create this better world.
The post Thank you, Chris appeared first on The Mozilla Blog.
Earlier this morning I shared the news internally that – while I’ve been a Mozillian for 15 years so far, and plan to be for many more years – this will be my last year as CEO.
When I returned to Mozilla just over five years ago, it was during a particularly tumultuous time in our history. Looking back it’s amazing to reflect on how far we’ve come, and I am so incredibly proud of all that our teams have accomplished over the years.
Today our products, technology and policy efforts are stronger and more resonant in the market than ever, and we have built significant new organizational capabilities and financial strength to fuel our work. From our new privacy-forward product strategy to initiatives like the State of the Internet we’re ready to seize the tremendous opportunity and challenges ahead to ensure we’re doing even more to put people in control of their connected lives and shape the future of the internet for the public good.
In short, Mozilla is an exceptionally better place today, and we have all the fundamentals in place for continued positive momentum for years to come.
It’s with that backdrop that I made the decision that it’s time for me to take a step back and start my own next chapter. This is a good place to recruit our next CEO and for me to take a meaningful break and recharge before considering what’s next for me. It may be a clich'e — but I’ll embrace it — as I’m also looking forward to spending more time with my family after a particularly intense but gratifying tour of duty.
However, I’m not wrapping up today or tomorrow, but at year’s end. I’m absolutely committed to ensuring that we sustain the positive momentum we have built. Mitchell Baker and I are working closely together with our Board of Directors to ensure leadership continuity and a smooth transition. We are conducting a search for my successor and I will continue to serve as CEO through that transition. If the search goes beyond the end of the year, Mitchell will step in as interim CEO if necessary, to ensure we don’t miss a beat. And I will stay engaged for the long-term as advisor to both Mitchell and the Board, as I’ve done before.
I am grateful to have had this opportunity to serve Mozilla again, and to Mitchell for her trust and partnership in building this foundation for the future.
Over the coming months I’m excited to share with you the new products, technology and policy work that’s in development now. I am more confident than ever that Mozilla’s brightest days are yet to come.
The post My Next Chapter appeared first on The Mozilla Blog.
Our newest release, Thunderbird version 68 is now available! Users on version 60, the last major release, will not be immediately updated – but will receive the update in the coming weeks. In this blog post, we’ll take a look at the features that are most noteworthy in the newest version. If you’d like to see all the changes in version 68, you can check out the release notes.
Thunderbird 68 focuses on polish and setting the stage for future releases. There was a lot of work that we had to do below the surface that has made Thunderbird more future-proof and has made it a solid base to continue to build upon. But we also managed to create some great features you can touch today.
New App Menu
Thunderbird 68 features a big update to the App Menu. The new menu is single pane with icons and separators that make it easier to navigate and reduce clutter. Animation when cycling through menu items produces a more engaging experience and results in the menu feeling more responsive and modern.

Thunderbird’s New App Menu
Options/Preferences in a Tab
Thunderbird’s Options/Preferences have been converted from a dialog window to its own dedicated tab. The new Preferences tab provides more space which allows for better organized content and is more consistent with the look and feel of the rest of Thunderbird. The new Preferences tab also makes it easier to multitask without the problem of losing track of where your preferences are when switching between windows.

Preferences in a Tab
Full Color Support
Thunderbird now features full color support across the app. This means changing the color of the text of your email to any color you want or setting tags to any shade your heart desires.

Full Color Support
Better Dark Theme
The dark theme available in Thunderbird has been enhanced with a dark message thread pane as well as many other small improvements.

Thunderbird Dark Theme
Attachment Management
There are now more options available for managing attachments. You can “detach” an attachment to store it in a different folder while maintaining a link from the email to the new location. You can also open the folder containing a detached file via the “Open Containing Folder” option.

Attachment options for detached files.
Filelink Improved
Filelink attachments that have already been uploaded can now be linked to again instead of having to re-upload them. Also, an account is no longer required to use the default Filelink provider – WeTransfer.
Other Filelink providers like Box and Dropbox are not included by default but can be added by grabbing the Dropbox and Box add-ons.
Other Notable Changes
There are many other smaller changes that make Thunderbird 68 feel polished and powerful including an updated To/CC/BCC
It is now easier than ever to customize avatars for Hubs! Choosing the way that you represent yourself in a 3D space is an important part of interacting in a virtual world, and we want to make it possible for anyone to have creative control over how they choose to show up in their communities. With the new avatar remixing update, members of the Hubs community can publish avatars that they create under a remixable, Creative Commons license, and grant others the ability to derive new works from those avatars. We’ve also added more options for creating custom avatars.
When you change your avatar in Hubs, you will now have the opportunity to browse through 'Featured' avatars and ‘Newest’ avatars. Avatars that are remixable will have an icon on them that allows you to save a version of that avatar to your own ‘My Avatars’ library, where you can customize the textures on the avatar to create your own spin on the original work. The ‘Red Panda’ avatar below is a remix of the original Panda Bot.
In addition to remixing avatars, you can create avatars by uploading a binary glTF file (or selecting one of the base bots that Hubs provides) and uploading up to four texture maps to the model. We have a number of resources available on GitHub for creating custom textures, as well as sets to get you started. You can also make your own designs with a 2D image editor or a 3D texture painting program.
The Hubs base avatar is a glTF model that has four texture maps and supports physically-based rendering (PBR) materials. This allows a great deal of flexibility in what kind of avatars can be created while still providing a quick way to create custom base color maps. For users who are familiar with 3D modeling, you can also create your own new avatar style from scratch, or by using the provided .blend files in the avatar-pipelines GitHub repo.
![]()
We’ve also made it easier to share avatars with one another inside a Hubs room. A tab for ‘Avatars’ now appears in the Create menu, and you can place thumbnails for avatars in the room you’re in to quickly swap between them. This will also allow others in the room to easily change to a specific avatar, which is a fun way to share avatars with a group.

These improvements to our avatar tools are just the start of what we’re working on to increase opportunities that Hubs users have available to express themselves on the platform. Making it easy to change your avatar - over and over again - allows users to have flexibility over how much personal information they want their avatar to reveal, and easily change from one digital body to another depending on how they’re using Hubs at a given time. While, at Mozilla, we find Panda Robots to be perfectly suited to company meetings, other communities and groups will have their own established social norms for professional activities. We want to support a rich, creative ecosystem for our users, and we can't wait to see what you create!
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
News & Blog Posts
- Should small Rust structs be passed by-copy or by-borrow?
- Thoughts on Rust bloat.
- Rust GUI ecosystem overview.
- Introduction to C2Rust.
- Async stack traces in Rust.
- Polsim - a case study for small-scale scientific computing in Rust.
- Managing memory in Rust: Entity-component systems.
- Actually using Crev, or, the problem of trusting software dependencies.
- Review of “Everything in Rust” of COSCUP 2019.
Crate of the Week
This week's crate is include_flate, a variant of include_bytes!/include_str with compile-time DEFLATE compression and runtime lazy decompression.
Thanks to Willi Kappler for the suggestion!
Submit your suggestions and votes for next week!
Call for Participation
Always wanted to contribute to open-source projects but didn't know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
No issues were proposed for CfP.
If you are a Rust project owner and are looking for contributors, please submit tasks here.
Updates from Rust Core
221 pull requests were merged in the last week
- Stabilize
async_awaitin Rust 1.39.0 - When declaring a declarative macro in an item it's only accessible inside it
- Improve diagnostics: break/continue in wrong context
- Audit uses of
apply_markin built-in macros + Remove default macro transparencies - Ensure miri can do bit ops on pointer values
- Use more optimal
Ordimplementation for integers - Fix bug in
iter::Chain::size_hint - Implement
nth_backforChunksExactMut - Avoid unnecessary reservations in
std::io::Take::read_to_end
The word “regulation" gets tossed around a lot. And it’s often aimed at the internet’s Big Tech companies. Some worry that the size of these companies and the influence they wield is too much. On the other side, there’s the argument that any regulation is overreach — leave it to the market, and everything will sort itself out. But over the last year, in the midst of this regulation debate, a funny thing happened. Tech companies got regulated. And our right to privacy got a little easier to exercise.
Gabriela Zanfir-Fortuna gives us the highlights of Europe’s sweeping GDPR privacy law, and explains how the law netted a huge fine against Spain’s National Football League. Twitter’s Data Protection Officer, Damien Kieran explains how regulation has shaped his new job and is changing how Twitter works with our personal data. Julie Brill at Microsoft says the company wants legislators to go further, and bring a federal privacy law to the U.S. And Manoush chats with Alastair MacTaggart, the California resident whose work led to the passing of the California Consumer Privacy Act.
IRL is an original podcast from Firefox. For more on the series go to irlpodcast.org
Learn more about consumer rights under the GDPR, and for a top-level look at what the GDPR does for you, check out our GDPR summary.
Here’s more about the California Consumer Privacy Act and Alastair MacTaggart.
And, get commentary and analysis on data privacy from Julie Brill, Gabriela Zanfir-Fortuna, and Damien Kieran.
Firefox has a department dedicated to open policy and advocacy. We believe that privacy is a right, not a privilege. Follow our blog for more.
TenFourFox Feature Parity Release 16 beta 1 is now available (downloads, hashes, release notes). In addition, the official FAQ has been updated, along with the tech notes.
FPR16 got delayed because I really tried very hard to make some progress on our two biggest JavaScript deficiencies, the infamous issues 521 (async and await) and 533 (this is undefined). Unfortunately, not only did I make little progress on either, but the speculative fix I tried for issue 533 turned out to be the patch that unsettled the optimized build and had to be backed out. There is some partial work on issue 521, though, including a fully working parser patch. The problem is plumbing this into the browser runtime which is ripe for all kinds of regressions and is not currently implemented (instead, for compatibility, async functions get turned into a bytecode of null throw null return, essentially making any call to an async function throw an exception because it wouldn't have worked in the first place).
This wouldn't seem very useful except that effectively what the whole shebang does is convert a compile-time error into a runtime warning, such that other functions that previously might not have been able to load because of the error can now be parsed and hopefully run. With luck this should improve the functionality of sites using these functions even if everything still doesn't fully work, as a down payment hopefully on a future implementation. It may not be technically possible but it's a start.
Which reminds me, and since this blog is syndicated on Planet Mozilla: hey, front end devs, if you don't have to minify your source, how about you don't? Issue 533, in fact, is entirely caused because uglify took some fast and loose shortcuts that barf on older parsers, and it is nearly impossible to unwind errors that occur in minified code (this is now changing as sites slowly update, so perhaps this will be self-limited in the end, but in the meantime it's as annoying as Andy Samberg on crack). This is particularly acute given that the only thing fixing it in the regression range is a 2.5 megabyte patch that I'm only a small amount of the way through reading. On the flip side, I was able to find and fix several parser edge cases because Bugzilla itself was triggering them and the source file that was involved was not minified. That means I could actually read it and get error reports that made sense! Help support us lonely independent browser makers by keeping our lives a little less complicated. Thank you for your consideration!
Meanwhile, I have the parser changes on by default to see if it induces any regressions. Sites may or may not work any differently, but they should not work worse. If you find a site that seems to be behaving adversely in the beta, please toggle javascript.options.asyncfuncs to false and restart the browser, which will turn the warning back into an error. If even that doesn't fix it, make sure nothing on the site changed (like, I dunno, checking it in FPR15) before reporting it in the comments.
This version also "repairs" Firefox Sync support by connecting the browser back up to the right endpoints. You are reminded, however, that like add-on support Firefox Sync is only supported at a "best effort" level because I have no control over the backend server. I'll make reasonable attempts to keep it working, but things can break at any time, and it is possible that it will stay broken for good (and be removed from the UI) if data structures or the protocol change in a way I can't control for. There's a new FAQ entry for this I suggest you read.
Finally, there are performance improvements for HTML5 and URL parsing from later versions of Firefox as well as a minor update to same-site cookie support, plus a fix for a stupid bug with SVG backgrounds that I caused and Olga found, updates to basic adblock with new bad hosts, updates to the font blacklist with new bad fonts, and the usual security and stability updates from the ESRs.
I realize the delay means there won't be a great deal of time to test this, so let me know deficiencies as quickly as possible so they can be
Whenever a patch is landed on autoland, it will run many builds and tests to make sure there are no regressions. Unfortunately many times we find a regression and 99% of the time backout the changes so they can be fixed. This work is done by the Sheriff team at Mozilla- they monitor the trees and when something is wrong, they work to fix it (sometimes by a quick fix, usually by a backout). A quick fact, there were 1228 regressions in H1 (January-June) 2019.
My goal in writing is not to recommend change, but instead to start conversations and figure out what data we should be collecting in order to have data driven discussions. Only then would I expect that recommendations for changes would come forth.
What got me started in looking at regressions was trying to answer a question: “How many regressions did X catch?” This alone is a tough question, instead I think the question should be “If we were not running X, how many regressions would our end users see?” This is a much different question and has two distinct parts:
- Unique Regressions: Only look at regressions found that only X found, not found on both X and Y
- Product Fixes: did the regression result in changing code that we ship to users? (i.e. not editing the test)
- Final Fix: many times a patch [set] lands and is backed out multiple times, in this case do we look at each time it was backed out, or only the change from initial landing to final landing?
These can be more difficult to answer. For example, Product Fixes- maybe by editing the test case we are preventing a regression in the future because the test is more accurate.
In addition we need to understand how accurate the data we are using is. As the sheriffs do a great job, they are human and humans make judgement calls. In this case once a job is marked as “fixed_by_commit”, then we cannot go back in and edit it, so a typo or bad data will result in incorrect data. To add to it, often times multiple patches are backed out at the same time, so is it correct to say that changes from bug A and bug B should be considered?
This year I have looked at this data many times to answer:
- how many unique regressions did linux32 catch?
- how many unique regressions did opt tests catch vs pgo?
- how many regressions did web-platform-tests catch?
- In H1 – 90 regressions, 17 product changes
This data is important to harvest because if we were to turn off a set of jobs or run them as tier-2 we would end up missing regressions. But if all we miss is editing manifests to disable failing tests, then we are getting no value from the test jobs- so it is important to look at what the regression outcome was.
In fact every time I did this I would run an active-data-recipe (fbc recipe in my repo) and have a large pile of data I needed to sort through and manually check. I spent some time every day for a few weeks looking at regressions and now I have looked at 700 (bugs/changesets). I found that in manually checking regressions, the end results fell into buckets:
| test | 196 | 28.00% |
| product | 272 | 38.86% |
| manifest | 134 | 19.14% |
| unknown | 48 | 6.86% |
| backout | 27 | 3.86% |
| infra | 23 | 3.29% |
Keep in mind that many of the changes which end up in mozilla-central are not only product bugs, but infrastructure bugs, test editing, etc.
After looking at many of these bugs, I found that ~80% of the time things are straightforward (single patch [set] landed, backed out once, relanded with clear comments). Data I would like to have easily available via a query:
- Files that are changed between backout and relanding (even if it is a new patch).
- A reason as part of phabricator that when we reland, it is required to have a few pre canned
On 10 September, Mozilla will host the next installment of our EU Mozilla Mornings series – regular breakfast meetings where we bring together policy experts, policymakers and practitioners for insight and discussion on the latest EU digital policy developments.
The next installment will focus on the future of EU content regulation. We’re bringing together a high-level panel to discuss how the European Commission should approach the mooted Digital Services Act, and to lay out a vision for a sustainable and rights-protective content regulation framework in Europe.
Featuring
Werner Stengg
Head of Unit, E-Commerce & Platforms, European Commission DG CNECT
Alan Davidson
Vice President of Global Policy, Trust & Security, Mozilla
Liz Carolan
Executive Director, Digital Action
Eliska Pirkova
Europe Policy Analyst, Access Now
Moderated by Brian Maguire, EURACTIV
Logistical information
10 September 2019
08:30-10:30
L42 Business Centre, rue de la Loi 42, Brussels 1040
Register your attendance here
The post Mozilla Mornings on the future of EU content regulation appeared first on Open Policy & Advocacy.
https://blog.mozilla.org/netpolicy/2019/08/22/mozilla-mornings_content-regulation/
Outreachy is a program that provides paid internships working on FOSS (Free and Open Source Software) to applicants from around the world. Internships are three months long and involve deep, technical work on a mentor-selected project, guided by mentors and other developers working on the FOSS application. At Mozilla, projects include work on Firefox itself, development of associated services and sites like Taskcluster and Treeherder, and analysis of Firefox telemetry data from a data-science perspective.
The program has an explicit focus on diversity: “Anyone who faces under-representation, systemic bias, or discrimination in the technology industry of their country is invited to apply.” It’s a small but very effective step in achieving better representation in this field. One of the interesting side-effects is that the program sees a number of career-changing participants. These people bring a wealth of interesting and valuable perspectives, but face challenges in a field where many have been programming since they were young.
Round 20 will involve full-time, remote work from mid-December 2019 to mid-March 2020. Initial applications for this round are now open.
New this year, applicants will need to make an “initial application” to determine eligibility before September 24. During this time, applicants can only see the titles of potential internship projects – not the details. On October 1, all applicants who have been deemed eligible will be able to see the full project descriptions. At that time, they’ll start communicating with project mentors and making small open-source contributions, and eventually prepare applications to one or more projects.
So, here’s the call to action:
- If you are or know people who might benefit from this program, encourage them to apply or to talk to one of the Mozilla coordinators (Kelsey Witthauer and myself) at
outreachy-coordinators@mozilla.com. - If you would like to mentor for the program, there’s still time! Get in touch with us and we’ll figure it out.
http://code.v.igoro.us/posts/2019/08/outreachy-round-20.html
Frontend security — thoughts on Snyk
I can’t remember why but few months ago I started looking into keeping my various React projects secure. Here’s some of what I discovered (more to come). I hope some will be valuable to you.
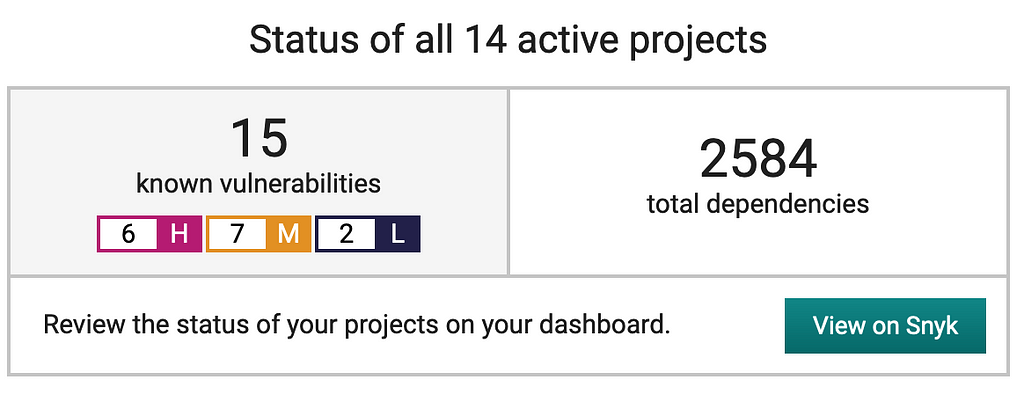
A while ago I discovered Snyk and I hooked it up my various projects with it. Snyk sends me a weekly security summary with the breakdown of various security issues across all of my projects.
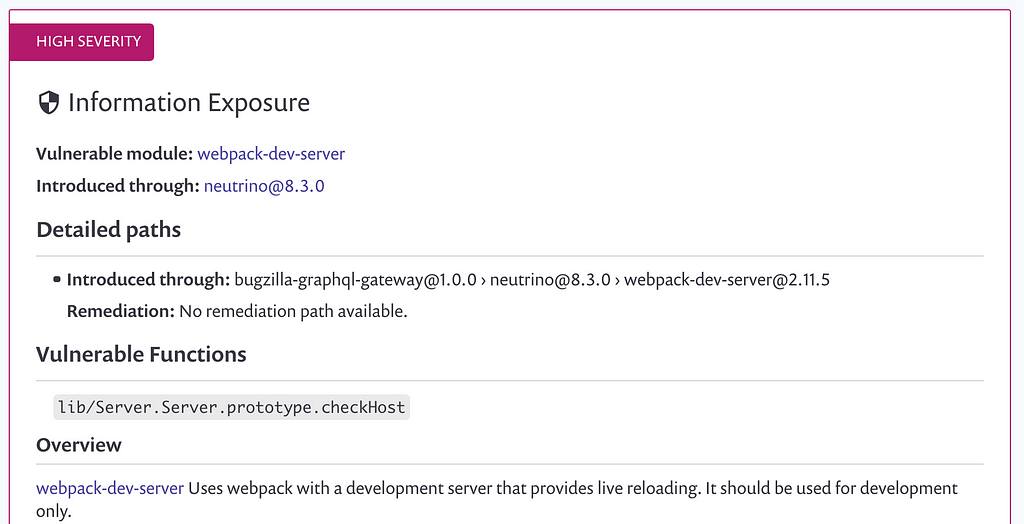
Snyk also gives me context about the particular security issues found:
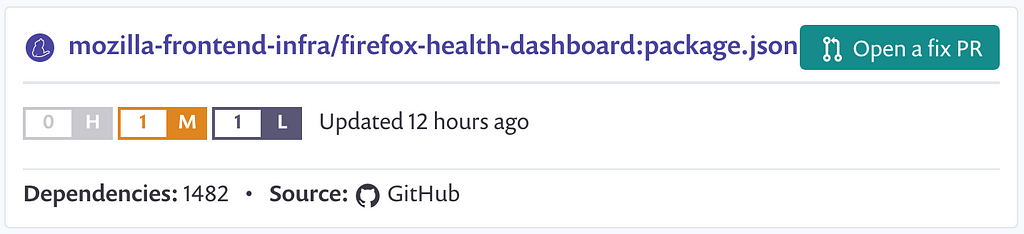
It also analyzes my dependencies on a per-PR level:

Other features that I’ve tried from Snyk:
- It sends you an email when there’s a vulnerable package (no need to wait for the weekly report)
- Open PRs upgrading vulnerable packages when possible
- Patch your code while there’s no published package with a fix
The above features I have tried and I decided not to use them for the following reasons (listed in the same order as above):
- As a developer I already get enough interruptions in a week. I don’t need to be notified for every single security issue in my dependency tree. My projects don’t deal with anything sensitive, thus, I’m OK with waiting to deal with them at the beginning of the week
- The PR opened by Snyk does not work well with Yarn since it does not update the yarn.lock file, thus, requirying me to fetch the PR, run yarn install and push it back (This wastes my time)
- The feature to patch your code (Runtime protection or snyk protect) adds a very high set up cost (1–2 minutes) everytime you need to run yarn install. This is because it analyzes all your dependencies and patches your code in-situ. This gets on the way of my development workflow.
Overall I’m very satisfied with Snyk and I highly recommend using it.
In the following posts I’m thinking of speaking on:
- How Renovate can help reduce the burden of keeping your projects up-to-date (reducing security work later on)
- Differences between GitHub’s security tab (DependaBot) and Snyk
- npm audit, yarn audit & snyk test
NOTE: This post is not sponsored by Snyk. I love what they do, I root for them and I hope they soon fix the issues I mention above.
Hello SUMO Community,
I’m thrilled to share this update with you today. Bryce and Brady have joined us last week and will be able to help out on Support for some of the new efforts Mozilla are working on towards creating a connected and integrated Firefox experience.
They are going to be involved with new products, but also they won’t forget to put extra effort in providing support on forums and as well as serving as an escalation point for hard to solve issues.
Here is a short introduction to Brady and Bryce:
Hi! My name is Brady, and I am one of the new members of the SUMO team. I am originally from Boise, Idaho and am currently going to school for a Computer Science degree at Boise State. In my free time, I’m normally playing video games, writing, drawing, or enjoying the Sawtooths. I will be providing support for Mozilla products and for the SUMO team.
Hello! My name is Bryce, I was born and raised in San Diego and I reside in Boise, Idaho. Growing up I spent a good portion of my life trying to be the best sponger(boogie boarder) and longboarder in North County San Diego. While out in the ocean I had all sorts of run-ins with sea creatures; but nothing to scary. I am also an IN-N-Out fan, as you may find me sporting their merchandise with boardshorts and the such. I am truly excited to be part of this amazing group of fun loving folks and I am looking forward to getting to know everyone.
Please welcome them warmly!
https://blog.mozilla.org/sumo/2019/08/21/introducing-bryce-and-brady/
People are excited about running WebAssembly outside the browser.
That excitement isn’t just about WebAssembly running in its own standalone runtime. People are also excited about running WebAssembly from languages like Python, Ruby, and Rust.
Why would you want to do that? A few reasons:
- Make “native” modules less complicated
Runtimes like Node or Python’s CPython often allow you to write modules in low-level languages like C++, too. That’s because these low-level languages are often much faster. So you can use native modules in Node, or extension modules in Python. But these modules are often hard to use because they need to be compiled on the user’s device. With a WebAssembly “native” module, you can get most of the speed without the complication. - Make it easier to sandbox native code
On the other hand, low-level languages like Rust wouldn’t use WebAssembly for speed. But they could use it for security. As we talked about in the WASI announcement, WebAssembly gives you lightweight sandboxing by default. So a language like Rust could use WebAssembly to sandbox native code modules. - Share native code across platforms
Developers can save time and reduce maintainance costs if they can share the same codebase across different platforms (e.g. between the web and a desktop app). This is true for both scripting and low-level languages. And WebAssembly gives you a way to do that without making things slower on these platforms.

So WebAssembly could really help other languages with important problems.
But with today’s WebAssembly, you wouldn’t want to use it in this way. You can run WebAssembly in all of these places, but that’s not enough.
Right now, WebAssembly only talks in numbers. This means the two languages can call each other’s functions.
But if a function takes or returns anything besides numbers, things get complicated. You can either:
- Ship one module that has a really hard-to-use API that only speaks in numbers… making life hard for the module’s user.
- Add glue code for every single environment you want this module to run in… making life hard for the module’s developer.
But this doesn’t have to be the case.
It should be possible to ship a single WebAssembly module and have it run anywhere… without making life hard for either the module’s user or developer.

So the same WebAssembly module could use rich APIs, using complex types, to talk to:
- Modules running in their own native runtime (e.g. Python modules running in a Python runtime)
- Other WebAssembly modules written in different source languages (e.g. a Rust module and a Go module running together in the browser)
- The host system itself (e.g. a WASI module providing the system interface to an operating system or the browser’s APIs)

And with a new, early-stage proposal, we’re seeing how we can make this Just Work , as you can see in this demo.
, as you can see in this demo.
So let’s take a look at how this will work. But first, let’s look at where we are today and the problems that we’re trying to solve.
WebAssembly talking to JS
WebAssembly isn’t limited to the web. But up to now, most of WebAssembly’s development has focused on the Web.
That’s because you can make better designs when you focus on solving concrete use cases. The language was definitely going to have to run on the Web, so that was a good use