Link to this tool (its sources)
What is this tool about?
Its goal is to give a better sense on how much computations are going on in Mozilla automation. Current TreeHerder UI surfaces job durations, but only per job. To get a sense on how much we stress our automation, we have to click on each individual job and do the sum manually. This tool is doing this sum for you. Well, it also tries to rank the jobs by their durations. I would like to open minds about the possible impact on the environment we may have here. For that, I am translating these durations into something fun that doesn’t necessarily make any sense.
What is that car’s GIF?
The car is a Trabant. This car is often seen as symbolic of the former East Germany and the collapse of the Eastern Bloc in general. This part of the tool is just a joke. You may only consider looking at durations, which are meant to be trustable data. Translating a worker duration into CO2 emission is almost impossible to get right. And that’s what I do here: Translate worker duration into a potential energy consumption, which I translate into a potential CO2 emission, before finally translating that CO2 emission into the equivalent emission of a trabant over a given distance in kilometers.
Power consumption of an AWS worker per hour
Here is a really weak computation of Amazon AWS CO2 emissions for a t4.large worker. The power usage of the machines these workers are running on could be 0.6 kW. Such worker uses 25% of these machines. Then let’s say that Amazon Power Usage Effectiveness is 1.1. It means that one hour of a worker consumes 0.165 kWh (0.6 * 0.25 * 1.1).
CO2 emission of electricity per kWh
Based on US Environmental Protection Agency (source), the average CO2 emission per MWh is 998.4 lb/MWh. So 998.4 * 453.59237(g/lb) = 452866 g/MWh, and, 452866 / 1000 = 452 g of CO2/kWh. Unfortunately, the data is already old. It comes from a 2018 report, which seems to be about 2017 data.
CO2 emission of a Trabant per km
A Trabant emits 170 g of CO2 / km (source). (Another [source] reports 140g, but let’s say it emits a lot.)
Final computation
Trabant’s kilometers = "Hours of computation" * "Power consumption of a worker per hour"
* "CO2 emission of electribity per kWh"
/ "CO2 emission of a trabant per km"
Trabant’s kilometers = "Hours of computation" * 0.165 * 452 / 170
=> Trabant’s kilometers = "Hours of computation" * 0.4387058823529412 **
All of this must be wrong
Except the durations! Everything else is highly subject to debate.
Sources are here, and contributions or feedback are welcomed.
Mozilla is announcing its eight latest Creative Media Awards. These art and advocacy projects highlight how AI intersects with online media and truth — and impacts our everyday lives
Today, one of the biggest issues facing the internet — and society — is misinformation.
It’s a complicated issue, but this much is certain: The artificial intelligence (AI) powering the internet is complicit. Platforms like YouTube and Facebook recommend and amplify content that will keep us clicking, even if it’s radical or flat out wrong.
Earlier this year, Mozilla called for art and advocacy projects that illuminate the role AI plays in spreading misinformation. And today, we’re announcing the winners: Eight projects that highlight how AI like machine learning impacts our understanding of the truth.
These eight projects will receive Mozilla Creative Media Awards totalling $200,000, and will launch to the public by May 2020. They include a Turing Test app; a YouTube recommendation simulator; educational deepfakes; and more. Awardees hail from Japan, the Netherlands, Uganda, and the U.S. Learn more about each awardee below.
Mozilla’s Creative Media Awards fuel the people and projects on the front lines of the internet health movement. Past Creative Media Award winners have built mock dating apps that highlight algorithmic discrimination; they’ve created games that simulate the inherent bias of automated hiring; and they’ve published clever tutorials that mix cosmetic advice with cybersecurity best practices.
These eight awards align with Mozilla’s focus on fostering more trustworthy AI.
The winners
 [1] Truth-or-Dare Turing Test | by Foreign Objects in the U.S.
[1] Truth-or-Dare Turing Test | by Foreign Objects in the U.S.
This project explores deceptive AI that mimic real humans. Users play truth-or-dare with another entity, and at the conclusion of the game, must guess if they were playing with a fellow human or an AI. (“Truths” are played out using text, and “dares” are played out using an online sketchpad.) The project also includes a website outlining the state of mimicry technology, its uses, and its dangers.
[2] Swap the Curators in the Tube | by Tomo Kihara in Japan
This project explores how recommendation engines present different realities to different people. Users will peruse the YouTube recommendations of five wildly different personas — including a conspiracist and a racist persona — to experience how their recommendations differ.

[3] An Interview with ALEX | by Carrie Wang in the U.S.
The project is a browser-based experience that simulates a job interview with an AI in a future of gamified work and total surveillance. As the interview progresses, users learn that this automated HR manager is covering up the truth of this job, and using facial and speech recognition to make assumptions and decisions about them.
[4] The Future of Memory | by Xiaowei Wang, Jasmine Wang, and Yang Yuting in the U.S.
This project explores algorithmic censorship, and the ways language can be made illegible to such algorithms. It reverse-engineers how automated censors work, to provide a toolkit of tactics using a new “machine resistant” language, composed of emoji, memes, steganography and homophones. The project will also archive censored materials on a distributed, physical network of offline modules.
 [5] Choose Your Own Fake News | by Pollicy in Uganda
[5] Choose Your Own Fake News | by Pollicy in Uganda
This project uses comics and audio to explore how misinformation
The recording of my Rust Conf talk on algorithmic art and pen plotters is up on YouTube!
Here is the abstract:
Sometimes programming Rust can feel like serious business. Let’s reject the absurdity of the real world and slip into solipsism with generative art. How does Rust hold up as a paint brush? And what can we learn when our fantasy worlds bleed back into reality?
I really enjoyed giving this talk, and I think it went well. I want more creative coding, joy, surprise, and silliness in the Rust community. This talk is a small attempt at contributing to that, and I hope folks left inspired.
Without further ado, here is the video:
And here are the slides. You can view them below, or open them in a new window. Navigate between slides with the arrow keys or space bar.
Enjoy!
http://fitzgeraldnick.com/2019/09/17/flatulence-crystals-and-happy-little-accidents.html
On Friday, Mozilla filed comments in a case brought by Privacy International in the European Court of Human Rights involving government “computer network exploitation” (“CNE”)—or, as it is more colloquially known, government hacking.
While the case focuses on the direct privacy and freedom of expression implications of UK government hacking, Mozilla intervened in order to showcase the further, downstream risks to users and internet security inherent in state CNE. Our submission highlights the security and related privacy threats from government stockpiling and use of technology vulnerabilities and exploits.
Government CNE relies on the secret discovery or introduction of vulnerabilities—i.e., bugs in software, computers, networks, or other systems that create security weaknesses. “Exploits” are then built on top of the vulnerabilities. These exploits are essentially tools that take advantage of vulnerabilities in order to overcome the security of the software, hardware, or system for purposes of information gathering or disruption.
When such vulnerabilities are kept secret, they can’t be patched by companies, and the products containing the vulnerabilities continue to be distributed, leaving people at risk. The problem arises because no one—including government—can perfectly secure information about a vulnerability. Vulnerabilities can be and are independently discovered by third parties and inadvertently leaked or stolen from government. In these cases where companies haven’t had an opportunity to patch them before they get loose, vulnerabilities are ripe for exploitation by cybercriminals, other bad actors, and even other governments,1 putting users at immediate risk.
This isn’t a theoretical concern. For example, the findings of one study suggest that within a year, vulnerabilities undisclosed by a state intelligence agency may be rediscovered up to 15% of the time.2 Also, one of the worst cyber attacks in history was caused by a vulnerability and exploit stolen from NSA in 2017 that affected computers running Microsoft Windows.3 The devastation wreaked through use of that tool continues apace today.4
This example also shows how damaging it can be when vulnerabilities impact products that are in use by tens or hundreds of millions of people, even if the actual government exploit was only intended for use against one or a handful of targets.
As more and more of our lives are connected, governments and companies alike must commit to ensuring strong security. Yet state CNE significantly contributes to the prevalence of vulnerabilities that are ripe for exploitation by cybercriminals and other bad actors and can result in serious privacy and security risks and damage to citizens, enterprises, public services, and governments. Mozilla believes that governments can and should contribute to greater security and privacy for their citizens by minimizing their use of CNE and disclosing vulnerabilities to vendors as they find them.
————————
1https://www.wired.com/story/notpetya-cyberattack-ukraine-russia-code-crashed-the-world/
2https://www.belfercenter.org/sites/default/files/files/publication/Vulnerability Rediscovery (belfer-revision).pdf
3https://en.wikipedia.org/wiki/WannaCry_ransomware_attack
4https://www.nytimes.com/2019/05/25/us/nsa-hacking-tool-baltimore.html
The post Governments should work to strengthen online security, not undermine it appeared first on Open Policy & Advocacy.
For those who are still wondering, yup, I am still maintaining mozregression, though increasingly reluctantly. Given how important this project is to the development of Firefox (getting a regression window using mozregression is standard operating procedure whenever a new bug is reported in Firefox), it feels like this project is pretty vital, so I continue out of some sense of obligation — but really, someone more interested in Mozilla’a build, automation and testing systems would be better suited to this task: over the past few years, my interests/focus have shifted away from this area to building up Mozilla’s data storage and visualization platform.
This post will describe some of the things that have happened in the last year and where I see the project going. My hope is to attract some new blood to add some needed features to the project and maybe take on some of the maintainership duties.
python 3
The most important update is that, as of today, the command-line version of mozregression (v3.0.1) should work with python 3.5+. modernize did most of the work for us, though there were some unit tests that needed updating: special thanks to @gloomy-ghost for helping with that.
For now, we will continue to support python 2.7 in parallel, mainly because the GUI has not yet been ported to python 3 (more on that later) and we have CI to make sure it doesn’t break.
other updates
The last year has mostly been one of maintenance. Thanks in particular to Ian Moody (:kwan) for his work throughout the year — including patches to adapt mozregression support to our new updates policy and shippable builds (bug 1532412), and Kartikaya Gupta (:kats) for adding support for bisecting the GeckoView example app (bug 1507225).
future work
There are a bunch of things I see us wanting to add or change with mozregression over the next year or so. I might get to some of these if I have some spare cycles, but probably best not to count on it:
- Port the mozregression GUI to Python 3 (bug 1581633) As mentioned above, the command-line client works with python 3, but we have yet to port the GUI. We should do that. This probably also entails porting the GUI to use PyQT5 (which is pip-installable and thus much easier to integrate into a CI process), see bug 1426766.
- Make self-contained GUI builds available for MacOS X (bug 1425105) and Linux (bug 1581643).
- Improve our mechanism for producing a standalone version of the GUI in general. We’ve used cx_Freeze which mostly works ok, but has a number of problems (e.g. it pulls in a bunch of unnecessary dependencies, which bloats the size of the installer). Upgrading the GUI to use python 3 may alleviate some of these issues, but it might be worth considering other options in this space, like Gregory Szorc’s pyoxidizer.
- Add some kind of telemetry to mozregression to measure usage of this tool (bug 1581647). My anecdotal experience is that this tool is pretty invaluable for Firefox development and QA, but this is not immediately apparent to Mozilla’s leadership and it’s thus very difficult to convince people to spend their cycles on maintaining and improving this tool. Field data may help change that story.
- Supporting new Mozilla products which aren’t built (entirely) out of mozilla-central, most especially Fenix (bug 1556042) and Firefox Reality (bug 1568488). This is probably rather involved (mozregression has a big pile of assumptions about how the builds it pulls down are stored and organized) but that doesn’t mean that this work isn’t necessary.
If you’re interested in working on any of the above, please feel free to dive in on one of the above bugs. I can’t offer
I’ve been a bit bad about updating this blog over the past year or so, though this hasn’t meant there haven’t been things to talk about. For the next couple weeks, I’m going to try to give some updates on the projects I have been spending time on in the past year, both old and new. I’m going to begin with some of the less-loved things I’ve been working on, partially in an attempt to motivate some forward-motion on things that I believe are rather important to Mozilla.
More to come.
https://wlach.github.io/blog/2019/09/time-for-some-project-updates?utm_source=Mozilla&utm_medium=RSS
Back in July and August, I was looking into a performance issue in Treeherder . Treeherder is a Django app running on Heroku with a MySql database via RDS. This post will cover some knowledge gained while investigating the performance issue and the solutions for it.
NOTE: Some details have been skipped to help the readability of this post. It’s a long read as it is!
Background
Treeherder is a public site mainly used by Mozilla staff. It’s used to determine if engineers have introduced code regressions on Firefox and other products. The performance issue that I investigated would make the site unusable for a long period of time (a few minutes to 20 minutes) multiple times per week. An outage like this would require blocking engineers from pushing new code since it would be practially impossible to determine the health of the code tree during an outage. In other words, the outages would keep “the trees” closed for business. You can see the tracking bug for this work here.
The smoking gun
On June 18th during Mozilla’s All Hands conference, I received a performance alert and decided to investigate it. I decided to use New Relic which was my first time using it and it also was my first time investigating a performance issue of a complex web site. New Relic made it easy and intiutive to get to what I wanted to see.
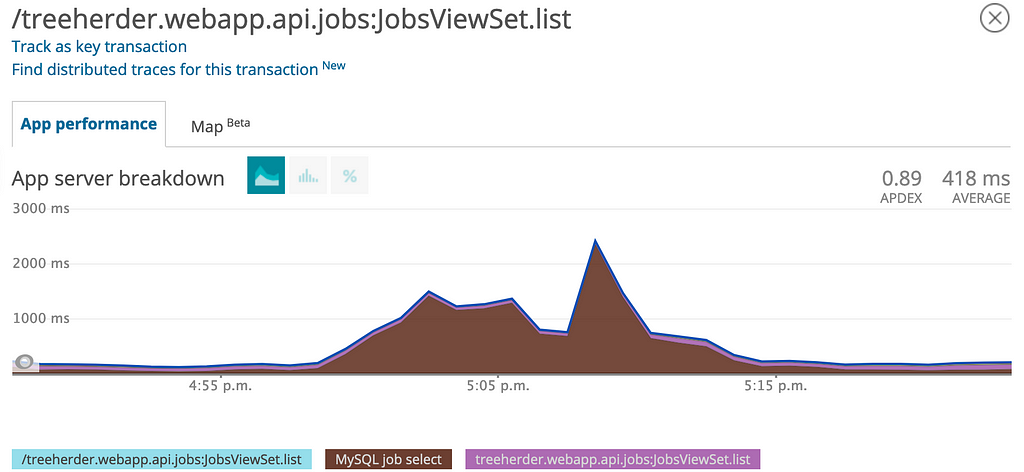
The UI slow downs came from API slow downs (and timeouts) due to database slow downs. The API that was most affected was JobsViewSet API which is heavily used by the front-end developers. The spike shown on the graph above was rather anomoulous. After some investigation I found that a developer unintentionally pushed code with a command that would trigger an absurd number of performance jobs. A developer normally would request one performance job per code push rather than ten. As these jobs finished (very close together in time) their performance data would be inserted into the database and make the DB crawl.

Since I was new to the team and the code-base, I tried to get input from the rest of my coworkers. We discussed using Django’s bulk_create to reduce the impact on the DB. I was not completely satisfied with the solution because we did not yet understand the root issue. From my Release Engineering years I remembered that you need to find the root issue or you’re just putting a band-aid on that will fall off sooner or later. Treeherder’s infrastructure had a limitation somewhere and a code change might only solve the problem temporarily. We would hit a different performance issue down the road. A fix at the root of the problem was required.
Gaining insight
I knew I needed proper insight as to what was happening plus an understanding of how each part of the data ingestion pipeline worked together. In order to know these things I needed metrics, and New Relic helped me to create a custom dashboard.
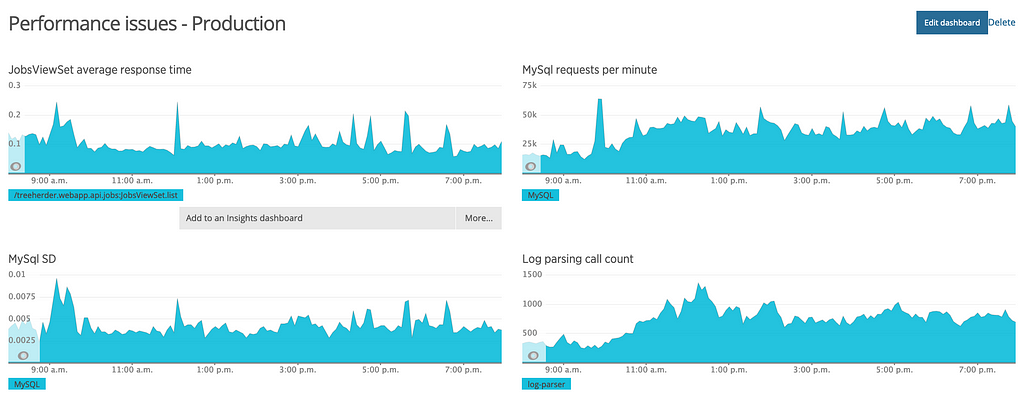
Similar set-up to test fixes
I made sure that the Heroku and RDS set-up between production and stage were as similar as possible. This is important if you want to try changes on stage first, measure it, and compare it with production.
For instance, I requested EC2 type instance changes plus upgrading to the current EC M5 instance types. I can’t find the exact Heroku changes that I produced, but I made the various ingestion workers to be similar in type and in number.
Consult others
I had a very primitive knowledge of MySql at scale and I knew that I would have to lean on others to understand the potential solution. I want to thank dividehex, coop and ckolos for all their time spent listening and all the knowledge they shared with me.
The cap you didn’t know you have
After reading a lot

We now live in a world with instantaneous communication unrestrained by geography. While a generation ago, we would be limited by the speed of the post, now we’re limited by the speed of information on the Internet. This has changed how we connect with other people.
As immersive devices become more affordable, social spaces in virtual reality (VR) will become more integrated into our daily lives and interactions with friends, family, and strangers. Social media has enabled rapid pseudonymous communication, which can be directed at both a single person and large groups. If social VR is the next evolution of this, what approaches will result in spaces that respect user identities, autonomy, and safety?
We need spaces that reflect how we interact with others on a daily basis.
Social spaces: IRL and IVR
Often, when people think about social VR, what tends to come to mind are visions from the worlds of science fiction stories: Snow Crash, Ready Player One, The Matrix - huge worlds that involve thousands of strangers interacting virtually on a day to day basis. In today’s social VR ecosystem, many applications take a similarly public approach: new users are often encouraged (or forced) by the system to interact with new people in the name of developing relationships with strangers who are also participating in the shared world. This can result in more dynamic and populated spaces, but in a way that isn’t inherently understood from our regular interactions.
This approach doesn’t mirror our usual day-to-day experiences—instead of spending time with strangers, we mostly interact with people we know. Whether we’re in a private, semi-public, or public space, we tend to stick to familiarity. We can define the privacy of space by thinking about who has access to a location, and the degree to which there is established trust among other people you encounter there.
Private: a controlled space where all individuals are known to each other. In the physical world, your home is an example of a private space—you know anyone invited into your home, whether they’re a close associate, or a passing acquaintance (like a plumber)
Semi-public: a semi-controlled space where all individuals are associated with each other. For example, you might not know everyone in your workplace, but you’re all connected via your employer
Public: a public space made up of a lot of different, separate groups of people who might not have established relationships or connections. In a restaurant, while you know the group you’re dining with, you likely don’t know anyone else

While we might encounter strangers in public or semi-public spaces, most of our interactions are still with people we know. This should extend to the virtual world. However, VR devices haven’t been widely available until recently, so most companies building virtual worlds have designed their spaces in a way that prioritizes getting people in the same space, regardless of whether or not those users already know each other.
For many social VR systems, the platform hosting spaces often networks different environments and worlds together and provides a centralized directory of user-created content to go explore. While this type of discovery has benefits and values, in the physical world, we largely spend time with the same people from day to day. Why don’t we design a social platform around this?
Mozilla Hubs is a social VR platform created to provide spaces that more accurately emulate our IRL interactions. Instead of hosting a connected, open ecosystem, users create their own independent, private-by-default rooms. This creates a world where instead of wandering into others’ spaces, you intentionally invite people you know into your space.
Private by default
Communities and societies often establish their own cultural norms, signals, inside jokes, and unspoken (or written) rules — these carry over to online spaces. It can be difficult for people to be thrown into brand-new groups of users without this understanding, and there are often no guarantees that the people you’ll be interacting with in these public spaces will be receptive to other users who are joining. In contrast to these public-first platforms, we’ve designed our social VR platform, Hubs, to be private by default. This means that instead of being in an environment with strangers from the outset, Hubs

The WebGL multiview extension is already available in several browsers and 3D web engines and it could easily help to improve the performance on your WebXR application
What is multiview?
When VR first arrived, many engines supported stereo rendering by running all the render stages twice, one for each camera/eye. While it works it is highly inefficient.
for (eye in eyes)
renderScene(eye)
Where renderScene will setup the viewport, shaders, and states every time is being called. This will double the cost of rendering every frame.
Later on, some optimizations started to appear in order to improve the performance and minimize the state changes.
for (object in scene)
for (eye in eyes)
renderObject(object, eye)
Even if we reduce the number of state changes, by switching programs and grouping objects, the number of draw calls remains the same: two times the number of objects.
In order to minimize this bottleneck, the multiview extension was created. The TL;DR of this extension is: Using just one drawcall you can draw on multiple targets, reducing the overhead per view.
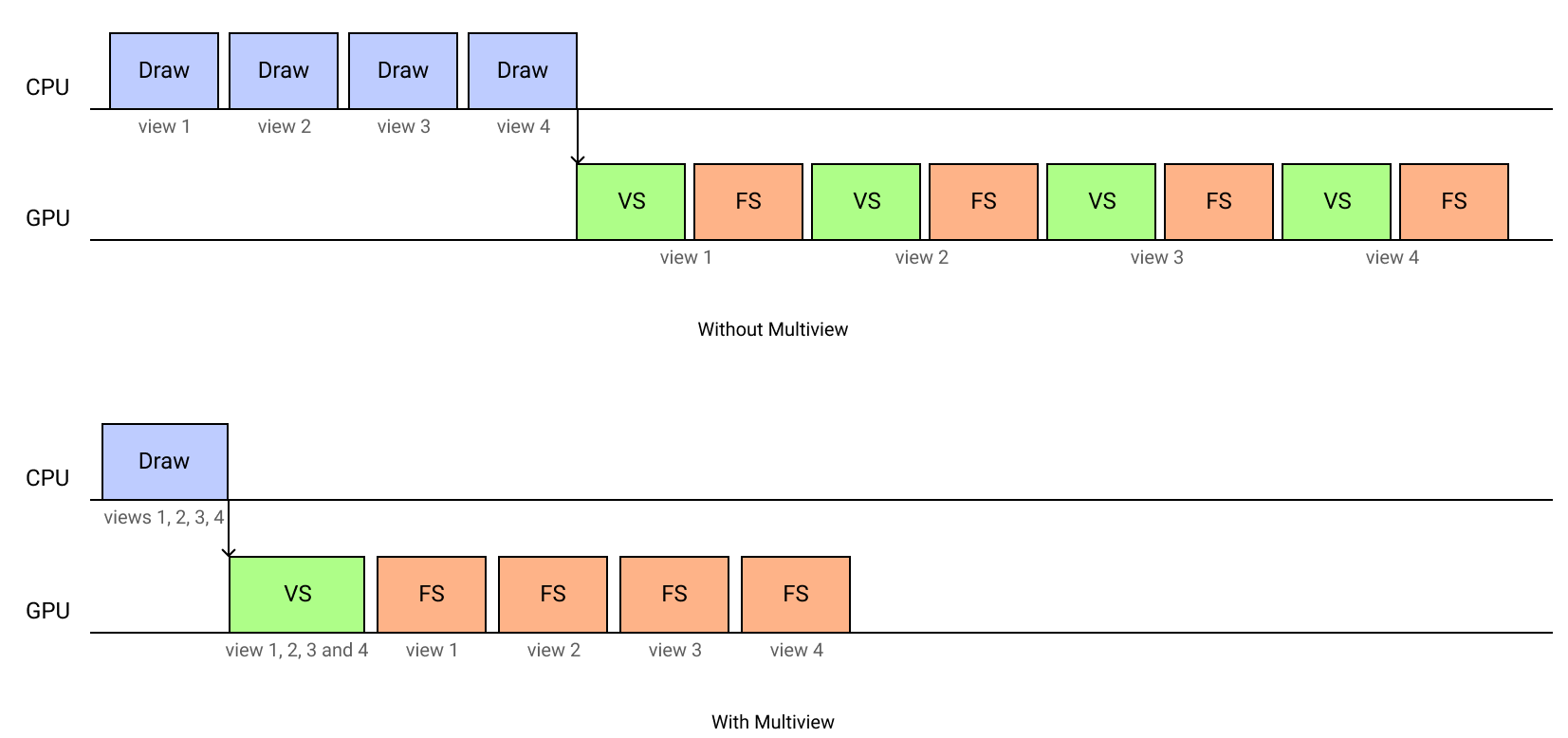
This is done by modifying your shader uniforms with the information for each view and accessing them with the gl_ViewID_OVR, similar to how the Instancing API works.
in vec4 inPos;
uniform mat4 u_viewMatrices[2];
void main() {
gl_Position = u_viewMatrices[gl_ViewID_OVR] * inPos;
}
The resulting render loop with the multiview extension will look like:
for (object in scene)
setUniformsForBothEyes() // Left/Right camera matrices
renderObject(object)
This extension can be used to improve multiple tasks as cascaded shadow maps, rendering cubemaps, rendering multiple viewports as in CAD software, although the most common use case is stereo rendering.
Stereo rendering is also our main target as this will improve the VR rendering path performance with just a few modifications in a 3D engine. Currently, most of the headsets have two views, but there are prototypes of headset with ultra-wide FOV using 4 views which is currently the maximum number of views supported by multiview.
Multiview in WebGL
Once the OpenGL OVR_multiview2 specification was created, the WebGL working group started to make a WebGL version of this API.
It’s been a while since our first experiment supporting multiview on servo and three.js. Back then it was quite a challenge to support WEBGL_multiview: it was based on opaque framebuffers and it was possible to use it with WebGL1 but the shaders need to be compiled with GLSL 3.0 support, which was only available on WebGL2, so some hacks on the servo side were needed in order to get it running.
At that time the WebVR spec had a proposal to support multiview but it was not approved.
Thanks to the work of the WebGL WG, the multiview situation has improved a lot in the last few months. The specification is already in the Community Approved status, which means that browsers could ship it enabled by default (As we do on Firefox desktop 70 and Firefox Reality 1.4)
Some important restrictions of the final specification to notice:
- It only supports
WebGL2contexts, as it needsGLSL 3.00andtexture arrays. - Currently there is no way to use multiview to render to a multisampled backbuffer, so you should create contexts with
antialias: false. (The WebGL WG is working on a solution for this)
Web engines with multiview support
We have been working for a while on adding multiview support to three.js (PR). Currently it is possible to get the benefits of multiview automatically as long as the extension is available and you define a WebGL2 context without antialias:
var context = canvas.getContext( 'webgl2', { antialias: false } );
renderer = new THREE.WebGLRenderer( { canvas: canvas, context: context } );
You can see a three.js example using multiview here (

Firefox Reality 1.4 is now available for users in the Viveport and Oculus stores.
With this release, we’re excited to announce that users can enjoy browsing in multiple windows side-by-side. Each window can be set to the size and position of your choice, for a super customizable experience.
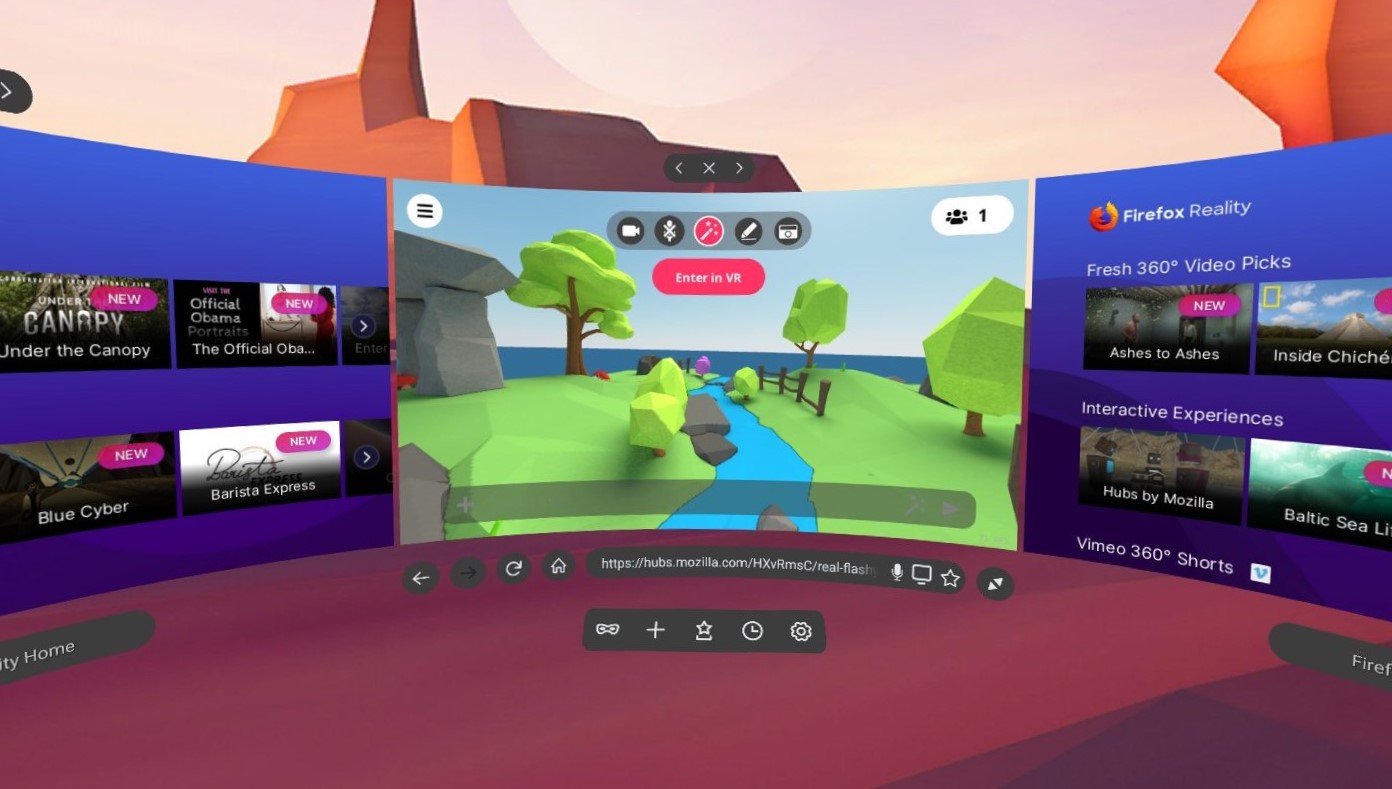
And, by popular demand, we’ve enabled local browsing history, so you can get back to sites you've visited before without typing. Sites in your history will also appear as you type in the search bar, so you can complete the address quickly and easily. You can clear your history or turn it off anytime from within Settings.
The Content Feed also has a new and improved menu of hand-curated “Best of WebVR” content for you to explore. You can look forward to monthly updates featuring a selection of new content across different categories including Animation, Extreme (sports/adrenaline/adventure), Music, Art & Experimental and our personal favorite way to wind down a day, 360 Chill.
Additional highlights
- Movable keyboard, so you can place it where it’s most comfortable to type.
- Tooltips on buttons and actions throughout the app.
- Updated look and feel for the Bookmarks and History views so you can see and interact better at all window sizes.
- An easy way to request the desktop version of a site that doesn’t display well in VR, right from the search bar.
- Updated and reorganized settings to be easier to find and understand.
- Added the ability to set a preferred website language order.
Full release notes can be found in our GitHub repo here.
Stay tuned as we keep improving Firefox Reality! We’re currently working on integrating your Firefox Account so you’ll be able to easily send tabs to and from VR from other devices. New languages and copy/paste are also coming soon, in addition to continued improvements in performance and stability.
Firefox Reality is available right now. Go and get it!
Download for Oculus Go
Download for Oculus Quest
Download for Viveport (Search for Firefox Reality in Viveport store)
A colleague asked me what I thought of this Medium article by Owen Bennett on the application of the UK’s Duty of Care laws to software. I’d had… quite a bit of coffee at that point, and this (lightly edited) was my answer:
I think the point Bennett makes early about the shortcomings of analogy is an important one, that however critical analogy is as a conceptual bridge it is not a valuable endpoint. To some extent analogies are all we have when something is new; this is true ever since the first person who saw fire had to explain to somebody else, it warms like the sun but it is not the sun, it stings like a spear but it is not a spear, it eats like an animal but it is not an animal. But after we have seen fire, once we know fire we can say, we can cage it like an animal, like so, we can warm ourselves by it like the sun like so. “Analogy” moves from conceptual, where it is only temporarily useful, to functional and structural where the utility endures.
I keep coming back to something Bryan Cantrill said in the beginning of an old DTrace talk – https://www.youtube.com/watch?v=TgmA48fILq8 – (even before he gets into the dtrace implementation details, the first 10 minutes or so of this talk are amazing) – that analogies between software and literally everything else eventually breaks down. Is software an idea, or is it a machine? It’s both. Unlike almost everything else.
(Great line from that talk – “Does it bother you that none of this actually exists?”)
But: The UK has some concepts that really do have critical roles as functional- and structural-analogy endpoints for this transition. What is your duty of care here as a developer, and an organization? Is this software fit for purpose?
Given the enormous potential reach of software, those concepts absolutely do need to survive as analogies that are meaningful and enforceable in software-afflicted outcomes, even if the actual text of (the inevitable) regulation of software needs to recognize software as being its own, separate thing, that in the wrong context can be more dangerous than unconstrained fire.
With that in mind, and particularly bearing in mind that the other places the broad “duty of care” analogy extends go well beyond beyond immediate action, and covers stuff like industrial standards, food safety, water quality and the million other things that make modern society work at all, I think Bennett’s argument that “Unlike the situation for ‘offline’ spaces subject to a duty of care, it is rarely the case that the operator’s act or omission is the direct cause of harm accruing to a user — harm is almost always grounded in another user’s actions” is incorrectly omitting an enormous swath of industrial standards and societal norms that have already made the functional analogy leap so effectively as to be presently invisible.
Put differently, when Toyota recalls hundreds of thousands of cars for potential defects in which exactly zero people were harmed, we consider that responsible stewardship of their product. And when the people working at Uber straight up murder a person with an autonomous vehicle, they’re allowed to say “but software”. Because much of software as an industry, I think, has been pushing relentlessly against the notion that the industry and people in it can or should be held accountable for the consequences of their actions, which is another way of saying that we don’t have and desperately need a clear sense of what a “duty of care” means in the software context.
I think that the concluding paragraph – “To do so would twist the law of negligence in a wholly new direction; an extremely risky endeavour given the context and precedent-dependent nature of negligence and the fact that the ‘harms’ under consideration are so qualitatively different than those subject to ‘traditional’ duties.” – reflects a deep genuflection to present day conceptual structures, and their specific manifestations as text-on-the-page-today, that is (I suppose inevitably, in the presence of this Very New Thing) profoundly at odds with the larger – and far more noble than this article admits – social and societal goals of those structures.
But maybe that’s just a superficial reading; I’ll read it over a few times and give it some more thought.
Please join us in congratulating Bhuvana Meenakshi Koteeswaran, Rep of the Month for July 2019!
Bhuvana is from Salem, India. She joined the Reps program at the end of 2017 and since then she has been involved with Virtual and Augmented Reality projects.

Bhuvana has recently held talks about WebXR at FOSSCon India and BangPypers. In October she will be a Space Wrangler at the Mozilla Festival in London.
Congratulations and keep rocking the open web! 
https://blog.mozilla.org/mozillareps/2019/09/11/rep-of-the-month-july-2019/
I personally have not done this many commits to curl in a single month (August 2019) for over three years. This increased activity is of course primarily due to the merge of and work with the HTTP/3 code. And yet, that is still only in its infancy…
Download curl here.
Numbers
the 185th release
6 changes
54 days (total: 7,845)
81 bug fixes (total: 5,347)
214 commits (total: 24,719)
1 new public libcurl function (total: 81)
1 new curl_easy_setopt() option (total: 269)
4 new curl command line option (total: 225)
46 contributors, 23 new (total: 2,014)
29 authors, 14 new (total: 718)
2 security fixes (total: 92)
450 USD paid in Bug Bounties
Two security advisories
TFTP small blocksize heap buffer overflow
(CVE-2019-5482) If you told curl to do TFTP transfers using a smaller than default “blocksize” (default being 512), curl could overflow a heap buffer used for the protocol exchange. Rewarded 250 USD from the curl bug bounty.
FTP-KRB double-free
(CVE-2019-5481) If you used FTP-kerberos with curl and the server maliciously or mistakenly responded with a overly large encrypted block, curl could end up doing a double-free in that exit path. This would happen on applications where allocating a large 32 bit max value (up to 4GB) is a problem. Rewarded 200 USD from the curl bug bounty.
Changes
The new features in 7.66.0 are…
HTTP/3
This experimental feature is disabled by default but can be enabled and works (by some definition of “works”). Daniel went through “HTTP/3 in curl” in this video from a few weeks ago:
Parallel transfers
You can now do parallel transfers with the curl tool’s new -Z / –parallel option. This is a huge change that might change a lot of use cases going forward!
Retry-after
There’s a standard HTTP header that some servers return when they can’t or won’t respond right now, which indicates after how many seconds or at what point in the future the request might be fulfilled. libcurl can now return that number easily and curl’s –retry option makes use of it (if present).
curl_multi_poll
curl_multi_poll is a new function offered that is very similar to curl_multi_wait, but with one major benefit: it solves the problem for applications of what to do for the occasions when libcurl has no file descriptor at all to wait for. That has been a long-standing and perhaps far too little known issue.
SASL authzid
When using SASL authentication, curl and libcurl now can provide the authzid field as well!
Bug-fixes
Some interesting bug-fixes included in this release..
.netrc and .curlrc on Windows
Starting now, curl and libcurl will check for and use the dot-prefixed versions of these files even on Windows and only fall back and check for and use the underscore-prefixed versions for compatibility if the dotted one doesn’t exist. This unifies curl’s behavior across platforms.
asyn-thread: create a socketpair to wait on
With this perhaps innocuous-sounding change, libcurl on Linux and other Unix systems will now provide a file descriptor for the application to wait on while name resolving in a background thread. This lets applications know better when to call libcurl again and avoids having to just blindly wait and retry. A performance gain.
Credentials in URL when using HTTP proxy
We found and fixed a regression that made curl not use credentials properly from the URL when doing multi stage authentication (like HTTP Digest) with a proxy.
Move code into vssh for SSH backends
A mostly janitor-style fix that also now abstracted away more SSH-using code to not know what particular SSH backend that is being used while

We are happy to announce the release of our WebXR emulator browser extension which helps WebXR content creation.
We understand that developing and debugging WebXR experiences is hard for many reasons:
- You must own a physical XR device
- Lack of support of XR devices on some platforms, as macOS
- Putting on and taking off the headset all the time is an uncomfortable task
- In order to make your app responsive across form factors, you must own tons of devices: mobile, tethered, 3dof, 6dof, and so on
With this extension, we aim to soften most of these issues.
WebXR emulator extension emulates XR devices so that you can directly enter immersive(VR) mode from your desktop browser and test your WebXR application without the need of any XR devices. It emulates multiple XR devices, so you can select which one you want to test.
The extension is built on top of the WebExtensions API, so it works on Firefox, Chrome, and other browsers supporting the API.

How can I use it?
- Install the extension from the extension stores (Firefox, Chrome)
- Launch a WebXR application, for example the Three.js examples. You will notice that the application detects that you have a VR device (emulated) and it will let you enter the immersive (VR) mode.
- Open the “WebXR” tab in the browser’s developer tool (Firefox, Chrome) to control the emulated device. You can move the headset and controllers and trigger the controller buttons. You will see their transforms reflected in the WebXR application.

What’s next?
The development of this extension is still at an early stage. We have many awesome features planned, including:
- Recording and replaying of actions and movements of your XR devices so you don’t have to replicate them every time you want to test your app and can share them with others.
- Incorporate new XR devices
- Control the headset and controllers using a standard gamepad like the Xbox or PS4 controllers or use your mobile as 3dof device
- Something else?
We would love your feedback! What new features do you want next? Any problems with the extension on your WebXR application? Please join us on GitHub to discuss them.
Lastly, we would like to give a shout out to the WebVR API emulation Extension by Jaume Sanchez as it was a true inspiration for us when building this one.
Forget about those hackers in movies trying to crack the code on someone’s computer to get their top secret files. The hackers responsible for data breaches usually start by targeting … Read more
The post Understand how hackers work appeared first on The Firefox Frontier.
This week, the House Judiciary Committee is expected to mark up the Copyright Alternative in Small Claims Enforcement (CASE) Act of 2019 (H.R. 2426). While the bill is designed to streamline the litigation process, it will impose severe costs upon users and the broader internet ecosystem. More specifically, the legislation would create a new administrative tribunal for claims with limited legal recourse for users, incentivizing copyright trolling and violating constitutional principles. Mozilla has always worked for copyright reform that supports businesses and internet users, and we believe that the CASE Act will stunt innovation and chill free expression online. With this in mind, we urge members to oppose passage of H.R. 2426.
First, the tribunal created by the legislation conflicts with well-established separation of powers principles and limits due process for potential defendants. Under the CASE Act, a new administrative board would be created within the Copyright Office to review claims of infringement. However, as Professor Pamela Samuelson and Kathryn Hashimoto of Berkeley Law point out, it is not clear that Congress has the authority under Article I of the Constitution to create this tribunal. Although Congress can create tribunals that adjudicate “public rights” matters between the government and others, the creation of a board to decide infringement disputes between two private parties would represent an overextension of its authority into an area traditionally governed by independent Article III courts.
Moreover, defendants subject to claims under the CASE Act will be funneled into this process with strictly limited avenues for appeal. The legislation establishes the tribunal as a default legal process for infringement claims–defendants will be forced into the process unless they explicitly opt-out. This implicitly places the burden on the user, and creates a more coercive model that will disadvantage defendants who are unfamiliar with the nuances of this new legal system. And if users have objections to the decision issued by the tribunal, the legislation severely restricts access to justice by limiting substantive court appeals to cases in which the board exceeded its authority; failed to render a final determination; or issued a determination as a result of fraud, corruption, or other misconduct.
While the board is supposed to be reserved for small claims, the tribunal is authorized to award damages of up to $30,000 per proceeding. For many people, this supposedly “small” amount would be enough to completely wipe out their household savings. Since the forum allows for statutory damages to be imposed, the plaintiff does not even have to show any actual harm before imposing potentially ruinous costs on the defendant.
These damages awards are completely out of place in what is being touted as a small claims tribunal. As Stan Adams of the Center for Democracy and Technology notes, awards as high as $30,000 exceed the maximum awards for small claims courts in 49 out of 50 states. In some cases, they would be ten times higher than the damages available in small claims court.
The bill also authorizes the Register of Copyrights to unilaterally establish a forum for claims of up to $5,000 to be decided by a singular Copyright Claims Officer, without any pre-established explicit due process protections for users. These amounts may seem negligible in the context of a copyright suit, where damages can reach up to $150,000, but nearly 40 percent of Americans cannot cover a $400 emergency today.
Finally, the CASE Act will give copyright trolls a
Like a cat, the Test Pilot program has had many lives. It originally started as an Add-on before we relaunched it three years ago. Then in January, we announced that we were evolving our culture of experimentation, and as a result we closed the Test Pilot program to give us time to further explore what was next.
We learned a lot from the Test Pilot program. First, we had a loyal group of users who provided us feedback on projects that weren’t polished or ready for general consumption. Based on that input we refined and revamped various features and services, and in some cases shelved projects altogether because they didn’t meet the needs of our users. The feedback we received helped us evaluate a variety of potential Firefox features, some of which are in the Firefox browser today.
If you haven’t heard, third time’s the charm. We’re turning to our loyal and faithful users, specifically the ones who signed up for a Firefox account and opted-in to be in the know about new products testing, and are giving them a first crack to test-drive new, privacy-centric products as part of the relaunched Test Pilot program. The difference with the newly relaunched Test Pilot program is that these products and services may be outside the Firefox browser, and will be far more polished, and just one step shy of general public release.
We’ve already earmarked a couple of new products that we plan to fine-tune before their official release as part of the relaunched Test Pilot program. Because of how much we learned from our users through the Test Pilot program, and our ongoing commitment to build our products and services to meet people’s online needs, we’re kicking off our relaunch of the Test Pilot program by beta testing our project code named Firefox Private Network.
Try our first beta – Firefox Private Network
One of the key learnings from recent events is that there is growing demand for privacy features. The Firefox Private Network is an extension which provides a secure, encrypted path to the web to protect your connection and your personal information anywhere and everywhere you use your Firefox browser.
There are many ways that your personal information and data are exposed: online threats are everywhere, whether it’s through phishing emails or data breaches. You may often find yourself taking advantage of the free WiFi at the doctor’s office, airport or a cafe. There can be dozens of people using the same network — casually checking the web and getting social media updates. This leaves your personal information vulnerable to those who may be lurking, waiting to take advantage of this situation to gain access to your personal info. Using the Firefox Private Network helps protect you from hackers lurking in plain sight on public connections.
Start testing the Firefox Private Network today, it’s currently available in the US on the Firefox desktop browser. A Firefox account allows you to be one of the first to test potential new products and services, you can sign up directly from the extension.
Key features of Firefox Private Network are:
- Protection when in public WiFi access points – Whether you are waiting at your doctor’s office, the airport or working from your favorite coffee shop, your connection to the internet is protected when you use the Firefox browser thanks to a secure tunnel to the web, protecting all your sensitive information like the web addresses you visit, personal and financial information.
- Internet Protocol (IP) addresses are hidden so it’s harder to track you – Your IP address is like a home address for your computer. One of the reasons why you may want to keep it hidden is to keep advertising networks from tracking your browsing history. Firefox Private Network will mask your IP address providing protection from third party trackers around the web.
- Toggle the switch on at any time. By clicking in the browser extension,
Web developers spend a good amount of time making web compatibility decisions. Deciding whether or not to use a web platform feature often depends on its availability in web browsers.
A brief history of compatibility data
More than 10 years ago, @fyrd created the caniuse project, to help developers check feature availability across browsers. Over time, caniuse has evolved into the go-to resource to answer the question that comes up day to day: “Can I use this?”
About 2 years ago, the MDN team started re-doing its browser compatibility tables. The team was on a mission to take the guesswork out of web compatibility. Since then, the BCD project has become a large dataset with more than 10,000 data points. It stays up to date with the help of over 500 contributors on GitHub.
MDN compatibility data is available as open data on npm and has been integrated in a variety of projects including VS Code and webhint.io auditing.
Two great data sources come together
Today we’re announcing the integration of MDN’s compat data into the caniuse website. Together, we’re bringing even more web compatibility information into the hands of web developers.

Before we began our collaboration, the caniuse website only displayed results for features available in the caniuse database. Now all search results can include support tables for MDN compat data. This includes data types already found on caniuse, specifically the HTML, CSS, JavaScript, Web API, SVG & and HTTP categories. By adding MDN data, the caniuse support table count expands from roughly 500 to 10,500 tables! Developers’ caniuse queries on what’s supported where will now have significantly more results.
The new feature tables will look a little different. Because the MDN compat data project and caniuse have compatible yet somewhat different goals, the implementation is a little different too. While the new MDN-based tables don’t have matching fields for all the available metadata (such as links to resources and a full feature description), support notes and details such as bug information, prefixes, feature flags, etc. will be included.
The MDN compatibility data itself is converted under the hood to the same format used in caniuse compat tables. Thus, users can filter and arrange MDN-based data tables in the same way as any other caniuse table. This includes access to browser usage information, either by region or imported through Google Analytics to help you decide when a feature has enough support for your users. And the different view modes available via both datasets help visualize support information.
Differences in the datasets
We’ve been asked why the datasets are treated differently. Why didn’t we merge them in the first place? We discussed and considered this option. However, due to the intrinsic differences between our two projects, we decided not to. Here’s why:
MDN’s support data is very broad and covers feature support at a very granular level. This allows MDN to provide as much detailed information as possible across all web technologies, supplementing the reference information provided by MDN Web Docs.
Caniuse, on the other hand, often looks at larger features as a whole (e.g. CSS Grid, WebGL, specific file format support). The caniuse approach provides developers with higher level at-a-glance information on whether the feature’s supported. Sometimes detail is missing. Each individual feature is added manually to caniuse, with a primary focus on browser support coverage rather than on feature coverage overall.
Because of these and other differences in implementation, we don’t plan on merging the source data repositories or matching the data