Hi there! Another gfx newsletter incoming.
Glenn and Sotaro’s work on integrating WebRender with DirectComposition on Windows is close to being ready. We hope to let it ride the trains for Firefox 75. This will lead to lower GPU usage and energy consumption. Once this is done we plan to follow up with enabling WebRender by default for Windows users with (some subset of) Intel integrated GPUs, which is both challenging (these integrated GPUs are usually slower than discrete GPUs and we have run into a number of driver bugs with them on Windows) and rewarding as it represents a very large part of the user base.
Edit: Thanks to Robert in the comments section of this post for mentioning the Linux/Wayland progress! I copy-pasted it here:
Some additional highlights for the Linux folks: Martin Str'ansk'y is making good progress on the Wayland front, especially concerning DMABUF. It will allow better performance for WebGL and hardware decoding for video (eventually). Quoting from https://bugzilla.mozilla.org/show_bug.cgi?id=1586696#c2:
> there’s a WIP dmabuf backend patch for WebGL, I see 100% performance boost with it for simple WebGL samples at GL compositor (it’s even faster than chrome/chromium on my box).
And there is active work on partial damage to reduce power consumption: https://bugzilla.mozilla.org/show_bug.cgi?id=1484812
What’s new in gfx
- Handyman fixed fixed a crash in the async plugin infrastructure.
- Botond fixed (2) various data races in the APZ code.
- Sean Feng fixed another race condition in APZ code.
- Andrew fixed a crash with OMTP and image decoding.
- Sotaro fixed a crash with the GL compositor on Wayland.
- Botond worked with Facebook developers to resolve a scrolling-related usability problem affecting Firefox users on messenger.com, primarily on MacOS.
- Botond fixed (2) divisions by zero various parts of the APZ.
- Sean Feng added some telemetry for touch input latency.
- Timothy made sure all uses of
APZCTreeManager::mGeckoFixedLayerMarginsare protected by the proper mutex. - Boris Chiou moved animations of transforms with preserve-3d off the main thread
- Jamie clamped some scale transforms at 32k to avoid excessively large rasterized areas.
- Jonathan Kew reduced the emboldening strength used for synthetic-bold faces with FreeType.
- Andrew implemented NEON accelerated methods for unpacking RGB to RGBA/BGRA.
- Alex Henrie fixed a bug in Moz2D’s Skia backend.
What’s new in WebRender
WebRender is a GPU based 2D rendering engine for the web written in Rust, currently powering Firefox‘s rendering engine as well as Mozilla’s research web browser servo.
- Miko avoided calculating snapped bounds twice for some display items.
- Kris fixed snapping and rounding errors causing picture caching invalidation when zoomed in.
- Glenn
I’m personally familiar with Backblaze as a fine backup solution I’ve helped my parents in law setup and use. I’ve found it reliable and easy to use. I would recommend it to others.
Over the Christmas holidays 2019 someone emailed me and mentioned that Backblaze have stated that they use libcurl but yet there’s no license or other information about this anywhere in the current version, nor on their web site. (I’m always looking for screenshotted curl credits or for data to use as input when trying to figure out how many curl installations there are or how many internet transfers per day that are done with curl…)
libcurl is MIT licensed (well, a slightly edited MIT license) so there’s really not a lot a company need to do to follow the license, nor does it leave me with a lot of “muscles” or remedies in case anyone would blatantly refuse to adhere. However, the impression I had was that this company was one that tried to do right and this omission could then simply be a mistake.
I sent an email. Brief and focused. Can’t hurt, right?
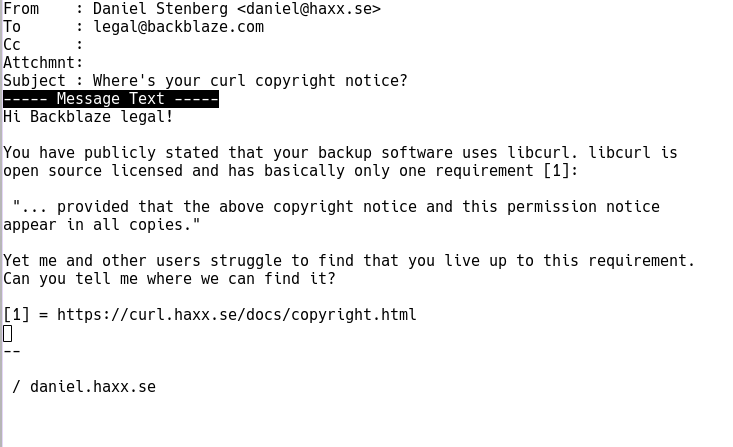
Immediate response
Brian Wilson, CTO of Backblaze, replied to my email within hours. He was very friendly and to the point. The omission was a mistake and Brian expressed his wish and intent to fix this. I couldn’t ask for a better or nicer response. The mentioned fixup was all that I could ask for.
Fixed it
Today Brian followed up and showed me the changes. Delivering on his promise. Just totally awesome.
Starting with the Windows build 7.0.0.409, the Backblaze about window looks like this (see image below) and builds for other platforms will follow along.
15,600 US dollars
At the same time, Backblaze also becomes the new largest single-shot donor to curl when they donated no less than 15,600 USD to the project, making the recent Indeed.com donation fall down to a second place in this my favorite new game of 2020.
Why this particular sum you may ask?
Backblaze was started in my living room on Jan 15, 2007 (13 years ago tomorrow) and that represents $100/month for every month Backblaze has depended on libcurl back to the beginning.
/ Brian Wilson, CTO of Backblaze
I think it is safe to say we have another happy user here. Brian also shared this most awesome statement. I’m happy and proud to have contributed my little part in enabling Backblaze to make such cool products.
Finally, I just want to say thank you for building and maintaining libcurl for all these years. It’s been an amazing asset to Backblaze, it really really has.
Thank you Backblaze!
Mozilla has sent a CA Communication to inform Certificate Authorities (CAs) who have root certificates included in Mozilla’s program about current events relevant to their membership in our program and to remind them of upcoming deadlines. This CA Communication has been emailed to the Primary Point of Contact (POC) and an email alias for each CA in Mozilla’s program, and they have been asked to respond to the following 7 action items:
- Read and fully comply with version 2.7 of Mozilla’s Root Store Policy.
- Ensure that their CP and CPS complies with the updated policy section 3.3 requiring the proper use of “No Stipulation” and mapping of policy documents to CA certificates.
- Confirm their intent to comply with section 5.2 of Mozilla’s Root Store Policy requiring that new end-entity certificates include an EKU extension expressing their intended usage.
- Verify that their audit statements meet Mozilla’s formatting requirements that facilitate automated processing.
- Resolve issues with audits for intermediate CA certificates that have been identified by the automated audit report validation system.
- Confirm awareness of Mozilla’s Incident Reporting requirements and the intent to provide good incident reports.
- Confirm compliance with the current version of the CA/Browser Forum Baseline Requirements.
The full action items can be read here. Responses to the survey will be automatically and immediately published by the CCADB.
With this CA Communication, we reiterate that participation in Mozilla’s CA Certificate Program is at our sole discretion, and we will take whatever steps are necessary to keep our users safe. Nevertheless, we believe that the best approach to safeguard that security is to work with CAs as partners, to foster open and frank communication, and to be diligent in looking for ways to improve.
The post January 2020 CA Communication appeared first on Mozilla Security Blog.
https://blog.mozilla.org/security/2020/01/13/january-2020-ca-communication/
It’s hard to go anywhere on the internet without seeing an ad. That’s because advertising is the predominant business model of the internet today. Websites and apps you visit every … Read more
The post No judgment digital definitions: Online advertising strategies appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/online-advertising-strategies/
Today, Mozilla filed a friend of the court brief with the Supreme Court in Google v. Oracle, the decade-long case involving questions of copyright for functional elements of Oracle’s Java SE. This is the fourth amicus brief so far that Mozilla has filed in this case, and we are joined by Medium, Cloudera, Creative Commons, Shopify, Etsy, Reddit, Open Source Initiative, Mapbox, Patreon, Wikimedia Foundation, and Software Freedom Conservancy.
Arguing from the perspective of small, medium, and open source technology organizations, the brief urges the Supreme Court to reverse the Federal Circuit’s holdings first that the structure, sequence, and organization (“SSO”) of Oracle’s Java API package was copyrightable, and subsequently that Google’s use of that SSO was not a “fair use” under copyright law.
At bottom in the case is the issue of whether copyright law bars the commonplace practice of software reimplementation, “[t]he process of writing new software to perform certain functions of a legacy product.” (Google brief p.7) Here, Google had repurposed certain functional elements of Java SE (less that 0.5% of Java SE overall, according to Google’s brief, p. 8) in its Android operating system for the sake of interoperability—enabling Java apps to work with Android and Android apps to work with Java, and enabling Java developers to build apps for both platforms without needing to learn the new conventions and structure of an entirely new platform.
Mozilla believes that software reimplementation and the interoperability it facilitates are fundamental to the competition and innovation at the core of a flourishing software development ecosystem. However, the Federal Circuit’s rulings would upend this tradition of reimplementation not only by prohibiting it in the API context of this case but by calling into question enshrined tenets of the software industry that developers have long relied on to innovate without fear of liability. With the consequence that small software developers are disadvantaged and innovations are fewer, incumbents’ positions in the industry are reinforced with a decline in incentive to improve their products, and consumers lose out. We believe that a healthy internet depends on the Supreme Court reversing the Federal Circuit and reaffirming the current state of play for software development, in which copyright does not stand in the way of software developers reusing SSOs for API packages in socially, technologically, and economically beneficial ways.
The post Competition and Innovation in Software Development Depend on a Supreme Court Reversal in Google v. Oracle appeared first on Open Policy & Advocacy.
Lately the data engineering team has been looking into productionizing (i.e. running in Airflow) a bunch of models that the data science team has been producing. This often involves languages and environments that are a bit outside of our comfort zone — for example, the next version of Mission Control relies on the R-stan library to produce a model of expected crash behaviour as Firefox is released.
To make things as simple and deterministic as possible, we’ve been building up Docker containers to run/execute this code along with their dependencies, which makes things nice and reproducible. My initial thought was to use just the language-native toolchains to build up my container for the above project, but quickly found a number of problems:
- For local testing, Docker on Mac is slow: when doing a large number of statistical calculations (as above), you can count on your testing iterations taking 3 to 4 (or more) times longer.
- On initial setup, the default R packaging strategy is to have the user of a package like R-stan recompile from source. This can take forever if you have a long list of dependencies with C-compiled extensions (pretty much a given if you’re working in the data space): rebuilding my initial docker environment for missioncontrol-v2 took almost an hour. This isn’t just a problem for local development: it also makes continuous integration using a service like Circle or Travis expensive and painful.
I had been vaguely aware of Conda for a few years, but didn’t really understand its value proposition until I started working on the above project: why bother with a heavyweight package manager when you already have Docker to virtualize things? The answer is that it solves both of the above problems: for local development, you can get something more-or-less identical to what you’re running inside Docker with no performance penalty whatsoever. And for building the docker container itself, Conda’s package repository contains pre-compiled versions of all the dependencies you’d want to use for something like this (even somewhat esoteric libraries like R-stan are available on conda-forge), which brought my build cycle times down to less than 5 minutes.
tl;dr: If you have a bunch of R / python code you want to run in a reproducible manner, consider Conda.
https://wlach.github.io/blog/2020/01/conda-is-pretty-great/?utm_source=Mozilla&utm_medium=RSS
(ootw is short for “option of the week“!)
--raw
Introduced back in April of 2007 in curl 7.16.2, the man page details for this option is very brief:
(HTTP) When used, it disables all internal HTTP decoding of content or transfer encodings and instead makes them passed on unaltered, raw.
This option is for HTTP(S) and it was brought to curl when someone wanted to use curl in a proxy solution. In that setup the user parsed the incoming headers and acted on them and in the case where for example chunked encoded data is received, which curl then automatically “decodes” so that it can deliver the pure clean data, the user would find that there were headers in the received response that says “chunked” but since libcurl had already decoded the body, it wasn’t actually still chunked when it landed!
In the libcurl side, an application can explicitly switch off this, by disabling transfer and content encoding with CURLOPT_HTTP_TRANSFER_DECODING and CURLOPT_HTTP_CONTENT_DECODING.
The --raw option is the command line version that disable both of those at once.
With --raw, no transfer or content decoding is done and the “raw” stream is instead delivered or saved. You really only do this if you for some reason want to handle those things yourself instead.
Content decoding includes automatice gzip compression, so --raw will also disable that, even if you use --compressed.
It should be noted that chunked encoding is a HTTP/1.1 thing. We don’t do that anymore in HTTP/2 and later – and curl will default to HTTP/2 over HTTPS if possible since a while back. Users can also often avoid chunked encoded responses by insisting on HTTP/1.0, like with the --http1.0 option (since chunked wasn’t included in 1.0).
Example command line
curl --raw https://example.com/dyn-content.cgi
Related options
--compressed asks the server to provide the response compressed and curl will then decompress it automatically. Thus reduce the amount of data that gets sent over the wire.
Avast took an interesting approach when integrating their antivirus product with web browsers. Users are often hard to convince that Avast browser extensions are good for them and should be activated in their browser of choice. So Avast decided to bring out their own browser with the humble name Avast Secure Browser. Their products send a clear message: ditch your current browser and use Avast Secure Browser (or AVG Secure Browser as AVG users know it) which is better in all respects.
Avast Secure Browser is based on Chromium and its most noticeable difference are the numerous built-in browser extensions, usually not even visible in the list of installed extensions (meaning that they cannot be disabled by regular means). Avast Secure Browser has eleven custom extensions, AVG Secure Browser has eight. Now putting eleven extensions of questionable quality into your “secure” browser might not be the best idea. Today we’ll look at the remarkable Video Downloader extension which essentially allowed any website to take over the browser completely (CVE-2019-18893). An additional vulnerability then allowed it to take over your system as well (CVE-2019-18894). The first issue was resolved in Video Downloader 1.5, released at some point in October 2019. The second issue remains unresolved at the time of writing. Update (2020-01-13): Avast notified me that the second issue has been resolved in an update yesterday, I can confirm the application version not being vulnerable any more after an update.

Note: I did not finish my investigation of the other extensions which are part of the Avast Secure Browser. Given how deeply this product is compromised on another level, I did not feel that there was a point in making it more secure. In fact, I’m not going to write about the Avast Passwords issues I reported to Avast – nothing special here, yet another password manager that made several of the usual mistakes and put your data at risk.
Summary of the findings
Browser vendors put a significant effort into limiting the attack surface of browser extensions. The Video Downloader extension explicitly chose to disable the existing security mechanisms however. As a result, a vulnerability in this extension had far reaching consequences. Websites could inject their JavaScript code into the extension context (CVE-2019-18893). Once there, they could control pretty much all aspects of the browser, read out any data known to it, spy on the user as they surf the web and modify any websites.
This JavaScript code, like any browser extension with access to localhost, could also communicate with the Avast Antivirus application. This communication interface has a vulnerability in the command starting Banking Mode which allows injecting arbitrary command line flags (CVE-2019-18894). This can be used to gain full control of Avast Secure Browser in Banking Mode and even execute local applications with user’s privileges. End result: visiting any website with Avast Secure Browser could result in malware being installed on your system without any user interaction.
Selecting a
Automatically finding a program that implements a given specification is called program synthesis. The main difficulty is that the search space is huge: the number of programs of size \(n\) grows exponentially. Na"ively enumerating every program of size \(n\), checking whether each one satisfies the specification, and then moving on to programs of size \(n+1\) and so on doesn’t scale. However, the field has advanced by using smarter search techniques to prune the search space, leveraging performance improvements in SMT solvers, and at times limiting the scope of the problem.
In this post, I’ll explain one approach to modern program synthesis: counterexample-guided iterative synthesis of component-based, loop-free programs, as described in Synthesis of Loop-Free Programs by Gulwani et al. We’ll dissect exactly what each of those terms mean, and we’ll also walk through an implementation written in Rust that uses the Z3 solver.
My hopes for this post are two-fold:
-
I hope that people who are unfamiliar with program synthesis — just like I was not too long ago — get a little less unfamiliar and learn something new about the topic. I’ve tried to provide many examples, and break down the dense logic formulas from the paper into smaller, approachable pieces.
-
I hope that folks who are already familiar with this kind of program synthesis can help me diagnose some performance issues in the implementation, where I haven’t been able to reproduce the synthesis results reported in the literature. For some of the more difficult benchmark problems, the synthesizer fails to even find a solution before my patience runs out.
Table of Contents
- Motivation
- An Overview of Our Task
- Formalizing the Problem
- A Brief Introduction to SMT Solvers
- Counterexample-Guided Iterative Synthesis
- Implementation
- Results
Working at Mozilla has been a very educational experience over the past eight years. I have had the chance to work side-by-side with many engineers at a large non-profit whose business and ethics are guided by a broad vision to protect the health of the web ecosystem. How did I go from being on the front of a computer screen in 1995 to being behind the workings of the web now? Below is my story of how my path wended from being a Netscape user to working at Mozilla, the heir to the Netscape legacy. It's amazing to think that a product I used 24 years ago ended up altering the course of my life so dramatically thereafter. But the world and the web was much different back then. And it was the course of thousands of people with similar stories, coming together for a cause they believed in.
The Winding Way West
Like many people my age, I followed the emergence of the World Wide Web in the 1990’s with great fascination. My father was an engineer at International Business Machines when the Personal Computer movement was just getting started. His advice to me during college was to focus on the things you don't know or understand rather than the wagon-wheel ruts of the well trod path. He suggested I study many things, not just the things I felt most comfortable pursuing. He said, "You go to college so that you have interesting things to think about when you're waiting at the bus stop." He never made an effort to steer me in the direction of engineering. In 1989 he bought me a Macintosh personal computer and said, "Pay attention to this hypertext trend. Networked documents is becoming an important new innovation." This was long before the World Wide Web became popular in the societal zeitgeist. His advice was prophetic for me.
After graduation, I moved to Washington DC and worked for a financial news wire that covered international business, US economy, World Trade Organization, G7, US Trade Representative, the Federal Reserve and breaking news that happened in the US capital. This era stoked my interest in business, international trade and economics. During my research (at the time, via a Netscape browser, using AltaVista search engine) I found that I could locate much of what I needed on the web rather than in the paid LexisNexis database, which I also had access to at the National Press Club in Washington, DC.
When the Department of Justice initiated its anti-trust investigation into Microsoft, for what was called anti-competitive practices against Netscape, my interest was piqued. Philosophically, I didn’t particularly see what was wrong with Microsoft standing up a competing browser to Netscape. Isn’t it good for the economy for there to be many competing programs for people to use on their PCs? After all, from my perspective, it seemed that Netscape had been the monopoly of the browser space at the time.
Following this case was my first exposure to the ethical philosophy of the web developer community. During the testimony, I learned how Marc Andressen, and his team of software developer pioneers, had an idea that access to the internet (like the underlying TCP/IP protocol) should not be centralized, or controlled by one company, government or interest group. And the mission behind Mosaic and Netscape browsers had been to ensure that the web could be device and operating system agnostic as well. This meant that you didn’t need to have a Windows PC or Macintosh to access it.
It was fascinating to me that there were people acting like Jiminy Cricket, Pinocchio's conscience, overseeing the future openness of this nascent developer environment. Little did I know then that I myself was being drawn into this cause. The more I researched about it, the more I was drawn in. What I took away from the DOJ/Microsoft consent decree was the concept that our government wants to see our economy remain inefficient in the
I’m happy to announce that curl now supports a third SSH library option: wolfSSH. Using this, you can build curl and libcurl to do SFTP transfers in a really small footprint that’s perfectly suitable for embedded systems and others. This goes excellent together with the tiny-curl effort.
SFTP only
The initial merge of this functionality only provides SFTP ability and not SCP. There’s really no deeper thoughts behind this other than that the work has been staged and the code is smaller for SFTP-only and it might be that users on these smaller devices are happy with SFTP-only.
Work on adding SCP support for the wolfSSH backend can be done at a later time if we feel the need. Let me know if you’re one such user!
Build time selection
You select which SSH backend to use at build time. When you invoke the configure script, you decide if wolfSSH, libssh2 or libssh is the correct choice for you (and you need to have the correct dev version of the desired library installed).
The initial SFTP and SCP support was added to curl in November 2006, powered by libssh2 (the first release to ship it was 7.16.1). Support for getting those protocols handled by libssh instead (which is a separate library, they’re just named very similarly) was merged in October 2017.
WolfSSH uses WolfSSL functions
If you decide to use the wolfSSH backend for SFTP, it is also possibly a good idea to go with WolfSSL for the TLS backend to power HTTPS and others.
A plethora of third party libs
WolfSSH becomes the 32nd third party component that curl can currently be built to use. See the slide below and click on it to get the full resolution version.

Credits
I, Daniel, wrote the initial new wolfSSH backend code. Merged in this commit.
Wolf image by David Mark from Pixabay
https://daniel.haxx.se/blog/2020/01/12/curl-even-more-wolfed/
If you are using feature detection with SharedArrayBuffer objects today you are likely impacted by upcoming changes to shared memory. In particular, you can no longer assume that if you have access to a SharedArrayBuffer object you can also use it with postMessage(). Detecting if SharedArrayBuffer objects are exposed can be done through the following code:
if (self.SharedArrayBuffer) {
// SharedArrayBuffer objects are available.
}Detecting if shared memory is possible by using SharedArrayBuffer objects in combination with postMessage() and workers can be done through the following code:
if (self.crossOriginIsolated) {
// Passing SharedArrayBuffer objects to postMessage() will succeed.
}Please update your code accordingly!
(As indicated in the aforelinked changes document obtaining a cross-origin isolated environment (i.e., one wherein self.crossOriginIsolated returns true) requires setting two headers and a secure context. Simply put, the Cross-Origin-Opener-Policy header to isolate yourself from attackers and the Cross-Origin-Embedder-Policy header to isolate yourself from victims.)
https://annevankesteren.nl/2020/01/shared-memory-feature-detection
CRLite is a technology to efficiently compress revocation information for the whole Web PKI into a format easily delivered to Web users. It addresses the performance and privacy pitfalls of the Online Certificate Status Protocol (OCSP) while avoiding a need for some administrative decisions on the relative value of one revocation versus another. For details on the background of CRLite, see our first post, Introducing CRLite: All of the Web PKI’s revocations, compressed.
To discuss CRLite’s design, let’s first discuss the input data, and from that we can discuss how the system is made reliable.
Designing CRLite
When Firefox securely connects to a website, the browser validates that the website’s certificate has a chain of trust back to a Certificate Authority (CA) in the Mozilla Root CA Program, including whether any of the CAs in the chain of trust are themselves revoked. At this time Firefox knows the issuing certificate’s identity and public key, as well as the website’s certificate’s identity and public key.
To determine whether the website’s certificate is trusted, Firefox verifies that the chain of trust is unbroken, and then determines whether the website’s certificate is revoked. Normally that’s done via OCSP, but with CRLite Firefox simply has to answer the following questions:
- Is this website’s certificate older than my local CRLite Filter, e.g., is my filter fresh enough?
- Is the CA that issued this website’s certificate included in my local CRLite Filter, e.g. is that CA participating?
- If “yes” to the above, and Firefox queries the local CRLite Filter, does it indicate the website’s certificate is revoked?
That’s a lot of moving parts, but let’s inspect them one by one.
Freshness of CRLite Filter Data
Mozilla’s infrastructure continually monitors all of the known Certificate Transparency logs for new certificates using our CRLite tooling; the details of how that works will be in a later blog post about the infrastructure. Since multiple browsers now require that all website certificates are disclosed to Certificate Transparency logs to be trusted, in effect the tooling has total knowledge of the certificates in the public Web PKI.

Figure 1: CRLite Information Flow. More details on the infrastructure will be in Part 4 of this blog post series.
Four times per day, all website certificates that haven’t reached their expiration date are processed, drawing out lists of their Certificate Authorities, their serial numbers, and the web URLs where they might be mentioned in a Certificate Revocation List (CRL).
All of the referenced CRLs are downloaded, verified, processed, and correlated against the lists of unexpired website certificates.

Figure 2: CRLite Filter Generation Process
At the end, we have a set of all known issuers that publish CRLs we could use, the identification numbers of every certificate they issued that is still unexpired, and the identification numbers of every certificate they issued that hasn’t expired but was revoked.
With this knowledge, we can build a CRLite Filter.
Structure of A CRLite Filter
CRLite data comes in the form of a series of cascading Bloom filters, with each filter layer adding data to the one before it. Individual Bloom filters have a certain chance of false-positives, but using Certificate Transparency as an oracle, the whole Web PKI’s certificate corpus is verified through the filter. When a false-positive is discovered, the algorithm adds it to another filter layer to resolve the false positive.
CRLite is a technology proposed by a group of researchers at the IEEE Symposium on Security and Privacy 2017 that compresses revocation information so effectively that 300 megabytes of revocation data can become 1 megabyte. It accomplishes this by combining Certificate Transparency data and Internet scan results with cascading Bloom filters, building a data structure that is reliable, easy to verify, and easy to update.
Since December, Firefox Nightly has been shipping with with CRLite, collecting telemetry on its effectiveness and speed. As can be imagined, replacing a network round-trip with local lookups makes for a substantial performance improvement. Mozilla currently updates the CRLite dataset four times per day, although not all updates are currently delivered to clients.
Revocations on the Web PKI: Past and Present
The design of the Web’s Public Key Infrastructure (PKI) included the idea that website certificates would be revocable to indicate that they are no longer safe to trust: perhaps because the server they were used on was being decommissioned, or there had been a security incident. In practice, this has been more of an aspiration, as the imagined mechanisms showed their shortcomings:
- Certificate Revocation Lists (CRLs) quickly became large, and contained mostly irrelevant data, so web browsers didn’t download them;
- The Online Certificate Status Protocol (OCSP) was unreliable, and so web browsers had to assume if it didn’t work that the website was still valid.
Since revocation is still crucial for protecting users, browsers built administratively-managed, centralized revocation lists: Firefox’s OneCRL, combined with Safe Browsing’s URL-specific warnings, provide the tools needed to handle major security incidents, but opinions differ on what to do about finer-grained revocation needs and the role of OCSP.
The Unreliability of Online Status Checks
Much has been written on the subject of OCSP reliability, and while reliability has definitely improved in recent years (per Firefox telemetry; failure rate), it still suffers under less-than-perfect network conditions: even among our Beta population, which historically has above-average connectivity, over 7% of OCSP checks time out today.
Because of this, it’s impractical to require OCSP to succeed for a connection to be secure, and in turn, an adversarial monster-in-the-middle (MITM) can simply block OCSP to achieve their ends. For more on this, a couple of classic articles are:
Mozilla has been making improvements in this realm for some time, implementing OCSP Must-Staple, which was designed as a solution to this problem, while continuing to use online status checks whenever there’s no stapled response.
We’ve also made Firefox skip revocation information for short-lived certificates; however, despite improvements in automation, such short-lived certificates still make up a very small portion of the Web PKI, because the majority of certificates are long-lived.
Does Decentralized Revocation Bring Dangers?
The ideal in question is whether a Certificate Authority’s (CA) revocation should be directly relied upon by end-users.
There are legitimate concerns that respecting CA revocations could be a path to enabling CAs to censor websites. This would be particularly troubling in the event of increased consolidation in the CA market. However, at present, if one CA were to engage in censorship, the website operator could go to a different CA.
If censorship concerns do bear out, then Mozilla has the option to use its root store policy to
Gutenberg 7.2 has just been released as a plugin. The development cycle was longer than usual. As a result, this version contains a lot of changes. Several of them improve Gutenberg’s accessibility.
The tab order in the editor
When editing a block, the tab order has been adjusted. Rather than tabbing to the next block, for example from one paragraph to the next, pressing tab will now put focus into the side bar for the active block. Further tabbing will move through the controls of said side bar. Shift+Tab will go in the opposite direction.
Likewise, when in the main contents area of a block, Shift+Tab will now move focus to the toolbar consistently and through its controls. It will also skip the drag handle for a block, because this is not keyboard operable. Tab will stop on the items to move the block up or down within the current set of blocks.
This makes the keyboard focus much more consistent and alleviates the need to use the custom keyboard shortcuts for the side bar and toolbar. These do still work, so if you have memorized them, you can continue using them. But you do not need to, tab and shift+tab will now also take you to expected places consistently.
Improvements to the Welcome guide
The modal for the Welcome guide has been enhanced. The modal now always gets a proper title for screen readers, so it no longer speaks an empty dialog when focus moves into it. The current page is now indicated for screen readers so it is easy to know which of the steps in the current guide is showing. The main contents is now a document so screen readers which apply a special reading mode for content sections can provide this functionality inside the modal.
This was one of the first two code contributions to Gutenberg by yours truly.
More enhancements and fixes
The justification radio menu items in the formatting toolbar are now properly exposed as such. This was the other of the two code contributions I made to this Gutenberg version.
The Social block now has proper labels.
The block wrapper, which contains the current set of blocks, now properly identifies as a group rather than a section. This will make it easier when dealing with nested blocks or parallel groups of blocks when building pages.
In conclusion
Gutenberg continues to improve. And now that I am a team member as well, I’ll try to help as time and capacity permit. The changes especially to the keyboard focus and semi-modality of blocks is a big step in improving usability.
One other thing that will hopefully land soon once potential plugin compatibility issues are resolved, will be that toolbars conform to the WAI-ARIA design pattern. That will mean that every toolbar container will be one tab stop, and elements within will be navigable via arrow keys. That will reduce the amount of tab stops and thus improve efficiency and compliance.
https://marcozehe.de/2020/01/09/whats-new-for-accessibility-in-gutenberg-7-2/

I’m please to invite you to our live webinar, “Why everyone is using curl and you should too!”, hosted by wolfSSL. Daniel Stenberg (me!), founder and Chief Architect of curl, will be live and talking about why everyone is using curl and you should too!
This is planned to last roughly 20-30 minutes with a following 10 minutes Q&A.
Space is limited so please register early!
When: Jan 14, 2020 08:00 AM Pacific Time (US and Canada) (16:00 UTC)
Register in advance for this webinar!
After registering, you will receive a confirmation email containing information about joining the webinar.
Not able to attend? Register now and after the event you will receive an email with link to the recorded presentation.
https://daniel.haxx.se/blog/2020/01/09/webinar-why-everyone-is-using-curl-and-you-should-too/

The bug that mashed Firefox 71 (ultimately fallout from bug 1601707 and its many dupes) did not get fixed in time for Firefox 72 and turned out to be a compiler issue. The lifetime change that the code in question relies upon is in Clang 7 and up, but not yet in gcc, and unless you are using a pre-release build this fix is not (yet) in any official release of gcc 9 or 10. As Clang is currently unable to completely build the browser on ppc64le, if your extensions are affected (mine aren't) you may want to add this patch which was also landed on the beta release channel for Firefox 73.
The debug and opt configurations are, again, otherwise unchanged from Firefox 67.
In my #rust2020 blog post, I mentioned rather off-handedly that I think the time has come for us to talk about forming a Rust foundation. I wanted to come back to this topic and talk in more detail about what I think a Rust foundation might look like. And, since I don’t claim to have the final answer to that question by any means, I’d also like to talk about how I think we should have this conversation going forward.
Hat tip
Before going any further, I want to say that most of the ideas in this post arose from conversations with others. In particular, Florian Gilcher, Ryan Levick, Josh Triplett, Ashley Williams, and I have been chatting pretty reguarly, and this blog post generally reflects the consensus that we seemed to be arriving at (though perhaps they will correct me). Thanks also to Yehuda Katz and Till Schneidereit for lots of detailed discussions.
Why do we want a Rust foundation?
I think this is in many ways the most important question for us to answer: what is it that we hope to achieve by creating a Rust foundation, anyway?
To me, there are two key goals:
- to help clarify Rust’s status as an independent project, and thus encourage investment from more companies;
- to alleviate some practical problems caused by Rust not having a “legal entity” nor a dedicated bank account.
There are also some anti-goals. Most notably:
- the foundation should not replace the existing Rust teams as a decision-making apparatus.
The role of the foundation is to complement the teams and to help us in achieving our goals. It is not to set the goals themselves.
Start small and iterate
You’ll notice that I’ve outlined a fairly narrow role for the foundation. This is no accident. When designing a foundation, just as when designing many other things, I think it makes sense for us to move carefully, a step at a time.
We should try to address immediate problems that we are facing and then give those changes some time to “sink in”. We should also take time to experiment with some of the various funding possibilities that are out there (some of which I’ll discuss later on). Once we’ve had some more experience, it should be easier for us to see which next steps make sense.
Another reason to start small is being able to move more quickly. I’d like to see us setup a foundation like the one I am discussing as soon as this year.
Goal #1: Clarifying Rust’s status as an independent project
So let’s talk a bit more about the two goals that I set forth for a Rust foundation. The first was to clarify Rust’s status as an independent project. In some sense, this is nothing new. Mozilla has from the get-go attempted to create an independent governance structure and to solicit involvement from other companies, because we know this makes Rust a better language for everyone.
Unfortunately, there is sometimes a lingering perception that Mozilla “owns” Rust, which can discourage companies from getting invested, or create the perception that there is no need to support Rust since Mozilla is footing the bill. Establishing a foundation will make official what has been true in practice for a long time: that Rust is an independent project.
We have also heard a few times from companies, large and small, who would like to support Rust financially, but right now there is no clear way to do that. Creating a foundation creates a place where that support can be directed.
Mozilla wants to support Rust… just not alone
Now, establishing a Rust foundation doesn’t mean that Mozilla plans to step back. After all, Mozilla has a lot riding on Rust, and Rust is playing an increasingly important role in how Mozilla builds our products. What we really want is a scenario where other companies join Mozilla in supporting Rust, letting us do much more.
In truth, this has already started to happen. For example, just this year Microsoft started sponsoring Rust’s CI costs and Amazon is paying Rust’s S3 bills. In fact, we recently added a corporate sponsors page to the Rust web site to acknowledge the many companies that are starting to support Rust.
Goal #2: Alleviating some practical difficulties
While the Rust
After doing some analysis late last night and today to determine if we need a chemspill build, I have concluded that TenFourFox is not vulnerable to CVE-2019-17026, or at least not to any of the PoCs or test cases available to me. This is the 0-day that was fixed in Firefox 72.0.1 and 68.4.1. Though a portion of the affected code exists in the TenFourFox code base, there doesn't seem to be a way to trigger the exploit due to various other missing optimizations and the oddities of our JIT. (Firefox 45-based browsers using our patches as upstream should bear in mind this may not be true for other architectures, however.) Absent evidence to the contrary it will be nevertheless patched as part of the standard security fixes in FPR19.
http://tenfourfox.blogspot.com/2020/01/tenfourfox-not-vulnerable-to-cve-2019.html
Mozilla is a global community that is building an open and healthy internet. We do so by building products that improve internet life, giving people more privacy, security and control over the experiences they have online. We are also helping to grow the movement of people and organizations around the world committed to making the digital world healthier.
As we grow our ambitions for this work, we are seeking new members for the Mozilla Foundation Board of Directors. The Foundation’s programs focus on the movement building side of our work and complement the products and technology developed by Mozilla Corporation.
What is the role of a Mozilla board member?
I’ve written in the past about the role of the Board of Directors at Mozilla.
At Mozilla, our board members join more than just a board, they join the greater team and the whole movement for internet health. We invite our board members to build relationships with management, employees and volunteers. The conventional thinking is that these types of relationships make it hard for the Executive Director to do his or her job. I wrote in my previous post that “We feel differently”. This is still true today. We have open flows of information in multiple channels. Part of building the world we want is to have built transparency and shared understandings.
It’s worth noting that Mozilla is an unusual organization. We’re a technology powerhouse with broad internet openness and empowerment at its core. We feel like a product organization to those from the nonprofit world; we feel like a non-profit organization to those from the technology industry.
It’s important that our board members understand the full breadth of Mozilla’s mission. It’s important that Mozilla Foundation Board members understand why we build consumer products, why it happens in the subsidiary and why they cannot micro-manage this work. It is equally important that Mozilla Corporation Board members understand why we engage in the open internet activities of the Mozilla Foundation and why we seek to develop complementary programs and shared goals.
What are we looking for?
Last time we opened our call for board members, we created a visual role description. Below is an updated version reflecting the current needs for our Mozilla Foundation Board.
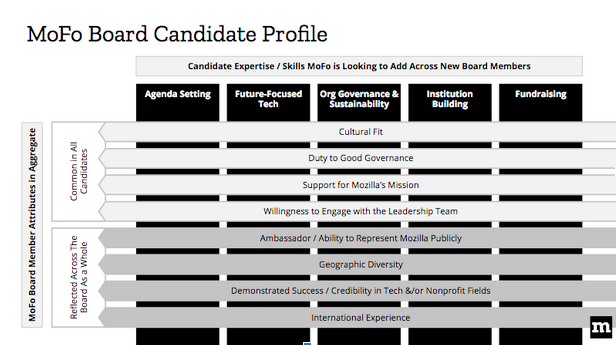
Here is the full job description: https://mzl.la/MoFoBoardJD
Here is a short explanation of how to read this visual:
- In the vertical columns, we have the particular skills and expertise that we are looking for right now. We expect new board members to have at least one of these skills.
- The horizontal lines speaks to things that every board member should have. For instance, to be a board member, you should have to have some cultural sense of Mozilla. They are a set of things that are important for every candidate. In addition, there is a set of things that are important for the board as a whole. For instance, international experience. The board makeup overall should cover these areas.
- The horizontal lines will not change too much over time, whereas the vertical lines will change, depending on who joins the Board and who leaves.
Finding the right people who match these criteria and who have the skills we need takes time. We hope to have extensive discussions with a wide range of people. Board candidates will meet the existing board members, members of the management team, individual contributors and volunteers. We see this as a good way to get to know how someone thinks and works within the framework of the Mozilla mission. It also helps us feel comfortable including someone at this senior level of stewardship.
We want your suggestions
We are hoping to add three new members to the Mozilla Foundation Board of Directors over the next 18 months. If you have candidates that you believe would be good board members, send them to msurman@mozillafoundation.org. We will use real discretion with the names you send us.
The post Expanding Mozilla’s Boards in 2020 appeared first on The Mozilla Blog.