The Rust team has published a new point release of Rust, 1.41.1. Rust is a programming language that is empowering everyone to build reliable and efficient software.
If you have a previous version of Rust installed via rustup, getting Rust 1.41.1 is as easy as:
rustup update stable
If you don't have it already, you can get rustup from the appropriate page on our website.
What's in 1.41.1 stable
Rust 1.41.1 addresses two critical regressions introduced in Rust 1.41.0:
a soundness hole related to static lifetimes, and a miscompilation causing segfaults.
These regressions do not affect earlier releases of Rust,
and we recommend users of Rust 1.41.0 to upgrade as soon as possible.
Another issue related to interactions between 'static and Copy implementations,
dating back to Rust 1.0, was also addressed by this release.
A soundness hole in checking static items
In Rust 1.41.0, due to some changes in the internal representation of static values,
the borrow checker accidentally allowed some unsound programs.
Specifically, the borrow checker would not check that static items had the correct type.
This in turn would allow the assignment of a temporary,
with a lifetime less than 'static, to a static variable:
static mut MY_STATIC: &'static u8 = &0;
fn main() {
let my_temporary = 42;
unsafe {
// Erroneously allowed in 1.41.0:
MY_STATIC = &my_temporary;
}
}
This was addressed in 1.41.1, with the program failing to compile:
error[E0597]: `my_temporary` does not live long enough
--> src/main.rs:6:21
|
6 | MY_STATIC = &my_temporary;
| ------------^^^^^^^^^^^^^
| | |
| | borrowed value does not live long enough
| assignment requires that `my_temporary` is borrowed for `'static`
7 | }
8 | }
| - `my_temporary` dropped here while still borrowed
You can learn more about this bug in issue #69114 and the PR that fixed it.
Respecting a 'static lifetime in a Copy implementation
Ever since Rust 1.0, the following erroneous program has been compiling:
#[derive(Clone)]
struct Foo<'a>(&'a u32);
impl Copy for Foo<'static> {}
fn main() {
let temporary = 2;
let foo = (Foo(&temporary),);
drop(foo.0); // Accessing a part of `foo` is necessary.
drop(foo.0); // Indexing an array would also work.
}
In Rust 1.41.1, this issue was fixed by the same PR as the one above. Compiling the program now produces the following error:
error[E0597]: `temporary` does not live long enough
--> src/main.rs:7:20
|
7 | let foo = (Foo(&temporary),);
| ^^^^^^^^^^ borrowed value does not live long enough
8 | drop(foo.0);
| ----- copying this value requires that
| `temporary` is borrowed for `'static`
9 | drop(foo.0);
10 | }
| - `temporary` dropped here while still borrowed
This error occurs because Foo<'a>, for some 'a, only implements Copy when 'a: 'static.
However, the temporary variable,
with some lifetime '0 does not outlive 'static and hence Foo<'0> is not Copy,
so using drop the second time around should be an error.
Miscompiled bound checks leading to segfaults
In a few cases, programs compiled with Rust 1.41.0 were omitting bound checks in the memory allocation code. This caused segfaults if out of bound values were provided. The root cause of the miscompilation was a change in a LLVM optimization pass, introduced in LLVM 9 and reverted in LLVM 10.
Rust 1.41.0 uses a snapshot of LLVM 9, so
(previous options of the week)
--ftp-pasv has no short version of the option.
This option was added in curl 7.11.0, January 2004.
FTP uses dual connections
FTP is a really old protocol with traces back to the early 1970s, actually from before we even had TCP. It truly comes from a different Internet era.
When a client speaks FTP, it first sets up a control connection to the server, issues commands to it that instructs it what to do and then when it wants to transfer data, in either direction, a separate data connection is required; a second TCP connection in addition to the initial one.
This second connection can be setup two different ways. The client instructs the server which way to use:
- the client connects again to the server (passive)
- the server connects back to the client (active)
Passive please
--ftp-pasv is the default behavior of curl and asks to do the FTP transfer in passive mode. As this is the default, you will rarely see this option used. You could for example use it in cases where you set active mode in your .curlrc file but want to override that decision for a single specific invocation.
The opposite behavior, active connection, is called for with the --ftp-port option. An active connection asks the server to do a TCP connection back to the client, an action that these days is rarely functional due to firewall and network setups etc.
FTP passive behavior detailed
FTP was created decades before IPv6 was even thought of, so the original FTP spec assumes and uses IPv4 addresses in several important places, including how to ask the server for setting up a passive data transfer.
EPSV is the “new” FTP command that was introduced to enable FTP over IPv6. I call it new because it wasn’t present in the original RFC 959 that otherwise dictates most of how FTP works. EPSV is an extension.
EPSV was for a long time only supported by a small fraction of FTP servers and it probably still exists such servers, so in case invoking this command is a problem, curl needs to fallback to the original command for this purpose: PASV.
curl first tries EPSV and if that fails, it sends PASV. The first of those commands that is accepted by the server will make the server wait for the client to connect to it (again) on fresh new TCP port number.
Problems with the dual connections
Your firewall needs to allow your client to connect to the new port number the server opened up for the data connection. This is particularly complicated if you enable FTPS (encrypted FTP) as then the new port number is invisible to middle-boxes such as firewalls.
Dual connections also often cause problems because the control connection will be idle during the transfer and that idle connection sometimes get killed by NATs or other middle-boxes due to that inactivity.
Enabling active mode is usually even worse than passive mode in modern network setups, as then the firewall needs to allow an outside TCP connection to come in and connect to the client on a given port number.
Example
Ask for a file using passive FTP mode:
curl --ftp-pasv ftp://ftp.example.com/cake-recipe.txt
Related options
--disable-epsv will prevent curl from using the EPSV command – which then also makes this transfer not work for IPv6. --ftp-port switches curl to active connection.
--ftp-skip-pasv-ip tells curl that the IP address in the server’s PASV response should be ignored and the IP address of the control connection should instead be used when the second connection is setup.
It seems as though Mozilla is never not in a period of transition. The distributed nature of the organization and community means that teams and offices and any informal or formal group is its own tiny experimental plot tended by gardeners with radically different tastes.
And if there’s one thing that unites gardeners and tech workers is that both have Feelings about their tools.
Tools are personal things: they’re the only thing that allows us to express ourselves in our craft. I can’t code without an editor. I can’t prune without shears. They’re the part of our work that we actually touch. The code lives Out There, the garden is Outside… but the tools are in our hands.
But tools can also be group things. A shed is a tool for everyone’s tools. A workshop is a tool that others share. An Issue Tracker is a tool that helps us all coordinate work.
And group things require cooperation, agreement, and compromise.
While I was on the Browser team at BlackBerry I used a variety of different Issue Trackers. We started with an outdated version of FogBugz, then we had a Bugzilla fork for the WebKit porting work and MKS Integrity for everything else across the entire company, and then we all standardized on Jira.
With minimal customization, Jira and MKS Integrity both seemed to be perfectly adequate Issue Tracking Software. They had id numbers, relationships, state, attachments, comments… all the things you need in an Issue Tracker. But they couldn’t just be “perfectly adequate”, they had to be better enough than what they were replacing to warrant the switch.
In other words, to make the switch the new thing needs to do something that the previous one couldn’t, wouldn’t, or just didn’t do (or you’ve forgotten that it did). And every time Jira or MKS is customized it seems to stop being Issue Tracking Software and start being Workflow Management Software.
Perhaps because the people in charge of the customization are interested more in workflows than in Issue Tracking?
Regardless of why, once they become Workflow Management Software they become incomparable with Issue Trackers. Apples and Oranges. You end up optimizing for similar but distinct use cases as it might become more important to report about issues than it is to file and fix and close them.
And that’s the state Mozilla might be finding itself in right now as a few teams here and there try to find the best tools for their garden and settle upon Jira. Maybe they tried building workflows in Bugzilla and didn’t make it work. Maybe they were using Github Issues for a while and found it lacking. We already had multiple places to file issues, but now some of the places are Workflow Management Software.
And the rumbling has begun. And it’s no wonder, as even tools that are group things are still personal. They’re still what we touch when we craft.
The GNU-minded part of me thinks that workflow management should be built above and separate from issue tracking by the skillful use of open and performant interfaces. Bugzilla lets you query whatever you want, however you want, so why not build reporting Over There and leave me my issue tracking Here where I Like It.
The practical-minded part of me thinks that it doesn’t matter what we choose, so long as we do it deliberately and consistently.
The schedule-minded part of me notices that I should probably be filing and fixing issues rather than writing on them. And I think now’s the time to let that part win.
:chutten
https://chuttenblog.wordpress.com/2020/02/25/jira-bugzilla-and-tales-of-issue-trackers-past/
Protecting the security and privacy of individuals is a central tenet of Mozilla’s mission, and so we constantly endeavor to make our users safer online. With a complex and highly-optimized system like Firefox, memory safety is one of the biggest security challenges. Firefox is mostly written in C and C++. These languages are notoriously difficult to use safely, since any mistake can lead to complete compromise of the program. We work hard to find and eliminate memory hazards, but we’re also evolving the Firefox codebase to address these attack vectors at a deeper level. Thus far, we’ve focused primarily on two techniques:
- Breaking code into multiple sandboxed processes with reduced privileges
- Rewriting code in a safe language like Rust
A new approach
While we continue to make extensive use of both sandboxing and Rust in Firefox, each has its limitations. Process-level sandboxing works well for large, pre-existing components, but consumes substantial system resources and thus must be used sparingly. Rust is lightweight, but rewriting millions of lines of existing C++ code is a labor-intensive process.
Consider the Graphite font shaping library, which Firefox uses to correctly render certain complex fonts. It’s too small to put in its own process. And yet, if a memory hazard were uncovered, even a site-isolated process architecture wouldn’t prevent a malicious font from compromising the page that loaded it. At the same time, rewriting and maintaining this kind of domain-specialized code is not an ideal use of our limited engineering resources.
So today, we’re adding a third approach to our arsenal. RLBox, a new sandboxing technology developed by researchers at the University of California, San Diego, the University of Texas, Austin, and Stanford University, allows us to quickly and efficiently convert existing Firefox components to run inside a WebAssembly sandbox. Thanks to the tireless efforts of Shravan Narayan, Deian Stefan, Tal Garfinkel, and Hovav Shacham, we’ve successfully integrated this technology into our codebase and used it to sandbox Graphite.
This isolation will ship to Linux users in Firefox 74 and to Mac users in Firefox 75, with Windows support following soon after. You can read more about this work in the press releases from UCSD and UT Austin along with the joint research paper. Read on for a technical overview of how we integrated it into Firefox.
Building a wasm sandbox
The core implementation idea behind wasm sandboxing is that you can compile C/C++ into wasm code, and then you can compile that wasm code into native code for the machine your program actually runs on. These steps are similar to what you’d do to run C/C++ applications in the browser, but we’re performing the wasm to native code translation ahead of time, when Firefox itself is built. Each of these two steps rely on significant pieces of software in their own right, and we add a third step to make the sandboxing conversion more straightforward and less error prone.
First, you need to be able to compile C/C++ into wasm code. As part of the WebAssembly effort, a wasm backend was added to Clang and LLVM. Having a compiler is not enough, though; you also need a standard library for C/C++. This component is provided via wasi-sdk. With those pieces, we have enough to translate C/C++ into wasm code.
Second, you need to be able to convert the wasm code into native object files. When we first started implementing wasm sandboxing, we were often asked, “why
The current insecure DNS system leaves billions of people around the world vulnerable because the data about where they go on the internet is unencrypted. We’ve set out to change that. In 2017, Mozilla began working on the DNS-over-HTTPS (DoH) protocol to close this privacy gap within the web’s infrastructure. Today, Firefox is enabling encrypted DNS over HTTPS by default in the US giving our users more privacy protection wherever and whenever they’re online.
DoH will encrypt DNS traffic from clients (browsers) to resolvers through HTTPS so that users’ web browsing can’t be intercepted or tampered with by someone spying on the network. The resolvers we’ve chosen to work with so far – Cloudflare and NextDNS – have agreed to be part of our Trusted Recursive Resolver program. The program places strong policy requirements on the resolvers and how they handle data. This includes placing strict limits on data retention so providers- including internet service providers – can no longer tap into an unprotected stream of a user’s browsing history to build a profile that can be sold, or otherwise used in ways that people have not meaningfully consented to. We hope to bring more partners into the TRR program.
Like most new technologies on the web, there has been a healthy conversation about this new protocol. We’ve seen non-partisan input, privacy experts, and other organizations all weigh in. And because we value transparency and open dialogue this conversation has helped inform our plans for DoH. We are confident that the research and testing we’ve done over the last two years has ensured our roll-out of DoH respects user privacy and makes the web safer for everyone. Through DoH and our trusted recursive resolver program we can begin to close the data leaks that have been part of the domain name system since it was created 35 years ago.
Here are a few things we think are important to know about our deployment of DNS over HTTPs.

The post The Facts: Mozilla’s DNS over HTTPs (DoH) appeared first on Open Policy & Advocacy.
https://blog.mozilla.org/netpolicy/2020/02/25/the-facts-mozillas-dns-over-https-doh/
Today, Firefox began the rollout of encrypted DNS over HTTPS (DoH) by default for US-based users. The rollout will continue over the next few weeks to confirm no major issues are discovered as this new protocol is enabled for Firefox’s US-based users.
A little over two years ago, we began work to help update and secure one of the oldest parts of the internet, the Domain Name System (DNS). To put this change into context, we need to briefly describe how the system worked before DoH. DNS is a database that links a human-friendly name, such as www.mozilla.org, to a computer-friendly series of numbers, called an IP address (e.g. 192.0.2.1). By performing a “lookup” in this database, your web browser is able to find websites on your behalf. Because of how DNS was originally designed decades ago, browsers doing DNS lookups for websites — even encrypted https:// sites — had to perform these lookups without encryption. We described the impact of insecure DNS on our privacy:
Because there is no encryption, other devices along the way might collect (or even block or change) this data too. DNS lookups are sent to servers that can spy on your website browsing history without either informing you or publishing a policy about what they do with that information.
At the creation of the internet, these kinds of threats to people’s privacy and security were known, but not being exploited yet. Today, we know that unencrypted DNS is not only vulnerable to spying but is being exploited, and so we are helping the internet to make the shift to more secure alternatives. We do this by performing DNS lookups in an encrypted HTTPS connection. This helps hide your browsing history from attackers on the network, helps prevent data collection by third parties on the network that ties your computer to websites you visit.
Since our work on DoH began, many browsers have joined in announcing their plans to support DoH, and we’ve even seen major websites like Facebook move to support a more secure DNS.
If you’re interested in exactly how DoH protects your browsing history, here’s an in-depth explainer by Lin Clark.
We’re enabling DoH by default only in the US. If you’re outside of the US and would like to enable DoH, you’re welcome to do so by going to Settings, then General, then scroll down to Networking Settings and click the Settings button on the right. Here you can enable DNS over HTTPS by clicking, and a checkbox will appear. By default, this change will send your encrypted DNS requests to Cloudflare.
Users have the option to choose between two providers — Cloudflare and NextDNS — both of which are trusted resolvers. Go to Settings, then General, then scroll down to Network Settings and click the Settings button on the right. From there, go to Enable DNS over HTTPS, then use the pull down menu to select the provider as your resolver.
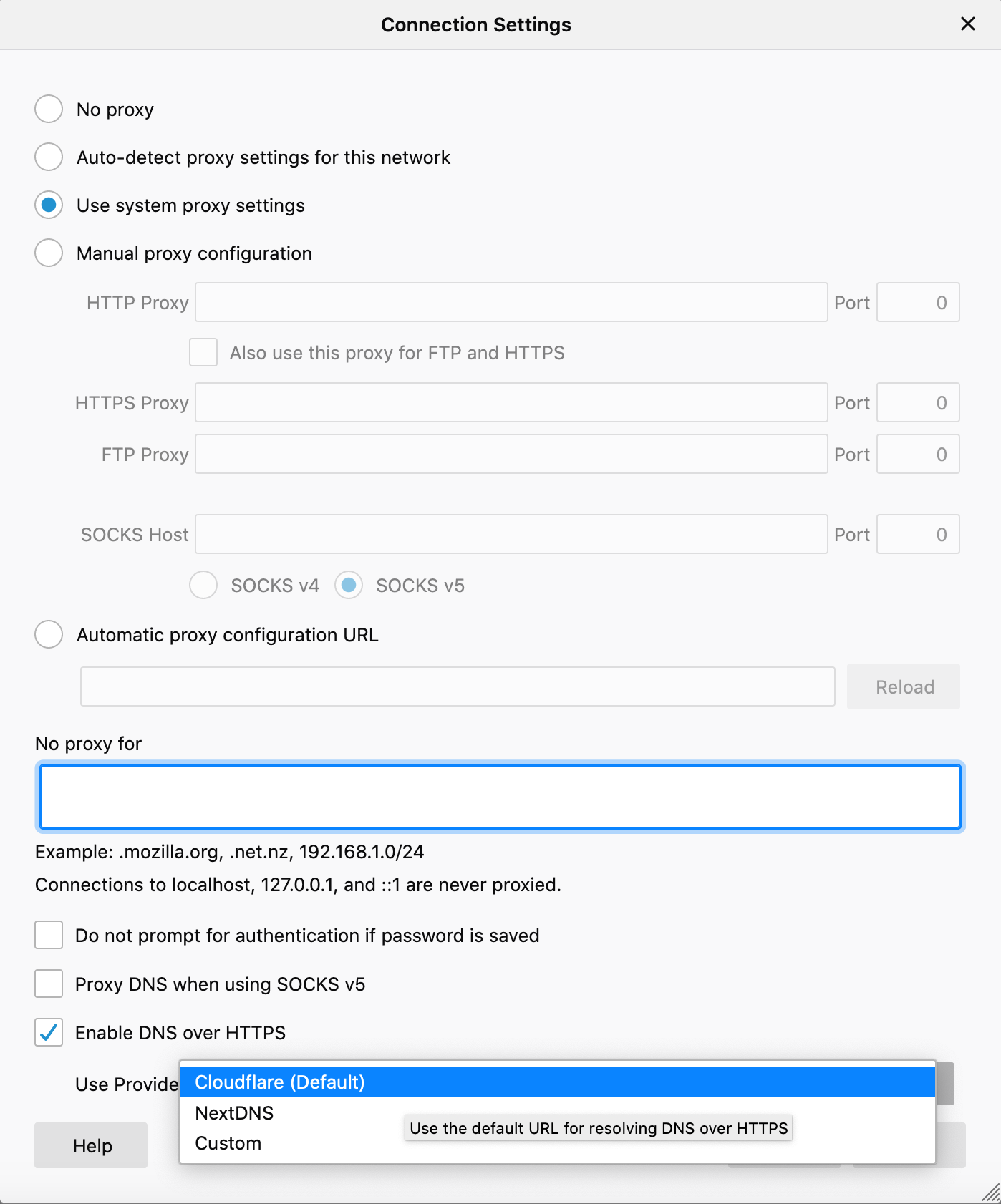
Users can choose between two providers
We continue to explore enabling DoH in other regions, and are working to add more providers as trusted resolvers to our program. DoH is just one of the many privacy protections you can expect to see from us in 2020.
You can download the release here.
The post Firefox continues push to bring DNS over HTTPS by default for US users appeared first on The Mozilla Blog.
A while back I wrote about a bunch of vulnerabilities in McAfee WebAdvisor, a component of McAfee antivirus products which is also available as a stand-alone application. Part of the fix was adding a bunch of pages to the extension which were previously hosted on siteadvisor.com, generally a good move. However, when I looked closely I noticed a Cross-Site Scripting (XSS) vulnerability in one of these pages (CVE-2019-3670).
Now an XSS vulnerability in a browser extension is usually very hard to exploit thanks to security mechanisms like Content Security Policy and sandboxing. These mechanisms were intact for McAfee WebAdvisor and I didn’t manage to circumvent them. Yet I still ended up with a proof of concept that demonstrated how attackers could gain local administrator privileges through this vulnerability, something that came as a huge surprise to me as well.

Summary of the findings
Both the McAfee WebAdvisor browser extension and the HTML-based user interface of its UIHost.exe application use the jQuery library. This choice of technology proved quite fatal: not only did it contribute to both components being vulnerable to XSS, it also made the vulnerability exploitable in the browser extension where existing security mechanisms would normally make exploitation very difficult to say the least.
In the end, a potential attacker could go from a reflective XSS vulnerability in the extension to a persistent XSS vulnerability in the application to writing arbitrary Windows registry values. The latter can then be used to run any commands with privileges of the local system’s administrator. The attack could be performed by any website and the required user interaction would be two clicks anywhere on the page.
At the time of writing, McAfee closed the XSS vulnerability in the WebAdvisor browser extensions and users should update to version 8.0.0.37123 (Chrome) or 8.0.0.37627 (Firefox) ASAP. From the look of it, the XSS vulnerability in the WebAdvisor application remains unaddressed. The browser extensions no longer seem to have the capability to add whitelist entries here which gives it some protection for now. It should still be possible for malware running with user’s privileges to gain administrator access through it however.
The initial vulnerability
When McAfee WebAdvisor prevents you from accessing a malicious page, a placeholder page is displayed instead. It contains a “View site report” link which brings you to the detailed information about the site. Here is what this site report looks like for the test website malware.wicar.org:
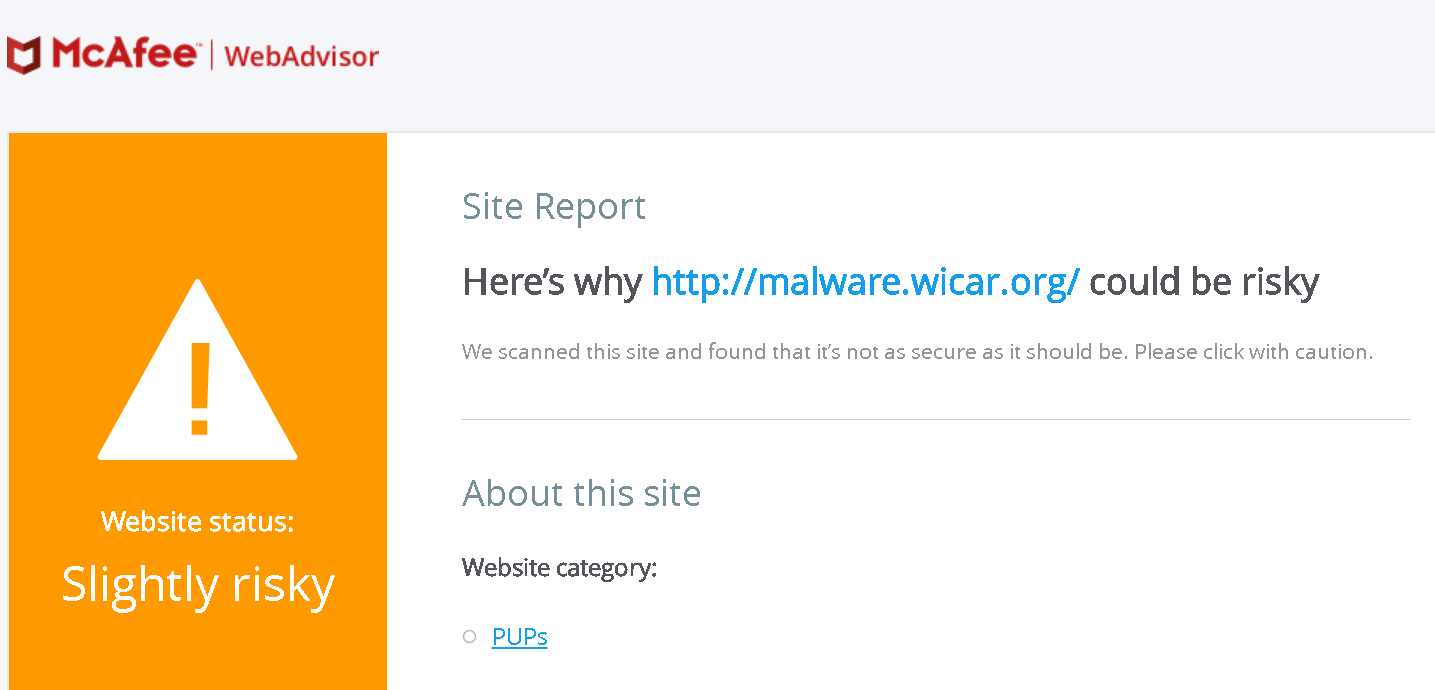
This page happens to be listed in the extensions web accessible resources, meaning that any website can open it with any parameters. And the way it handles the url query parameter is clearly problematic. The following code has been paraphrased to make it more
At Mozilla, we believe that privacy is a fundamental digital right. We’ve built these values into the Firefox browser itself, and we’ve pushed Congress to pass strong legal protections for consumer privacy in the US. This week, Congress will have another opportunity to consider meaningful reforms to protect user privacy when it debates the reauthorization of the USA FREEDOM Act. We believe that Congress should amend this surveillance law to remove ineffective programs, bolster resources for civil liberties advocates, and provide more transparency for the public. More specifically, Mozilla supports the following reforms:
- Elimination of the Call Detail Record program
- Greater access to information for amicus curiae
- Public access to all significant opinions from the Foreign Intelligence Surveillance Court
By taking these steps, we believe that Congress can ensure the continued preservation of civil liberties while allowing for appropriate government access to information when necessary.
Eliminate the Call Detail Record Program
First, Congress should revoke the authority for the Call Detail Record (CDR) program. The CDR program allows the federal government to obtain the metadata of phone calls and texts from telecom companies in the course of an international terrorism investigation, subject to specific statutory requirements. This program is simply no longer worthwhile. Over the last four years, the National Security Agency (NSA) scaled back its use of the program, and the agency has not used this specific authority since late 2018.
The decision to suspend the program is a result of challenges the agency encountered in effectively operating the program on three separate fronts. First, the NSA has had issues with the mass overcollection of phone records that it was not authorized to receive, intruding into the private lives of millions of Americans. This overcollection represents a mass breach of civil liberties–a systemic violation of our privacy. Without technical measures to maintain these protections, the program was no longer legally sustainable.
Second, the program may not provide sufficiently valuable insights in the current threat environment. In a recent Senate Judiciary Committee hearing, the government acknowledged that the intelligence value of the program was outweighed by the costs and technical challenges associated with its continued operation. This conclusion was supported by an independent analysis from the Privacy and Civil Liberties Oversight Board (PCLOB), which hopes to publicly release an unclassified version of its report in the near future. Additionally, the shift to other forms of communications may make it even less likely that law enforcement will obtain useful information through this specific authority in the future.
And finally, some technological shifts may have made the CDR program too complex to implement today. Citing to “technical irregularities” in some of the data obtained from telecom providers under the program, the NSA deleted three years’ worth of CDRs that it was not authorized to receive last June. While the agency has not released a specific explanation, Susan Landau and Asaf Lubin of Tufts University have posited that the problem stems from challenges associated with measures in place to facilitate interoperability between landlines and mobile phone networks.
The NSA has recommended shutting down the program, and Congress should follow suit by allowing it to expire.
Bolster Access for Advocates
The past four years have
 This is me about 25 years ago, dancing with a yoga ball. I was part of a theater company where I first learned Liz Lerman’s Critical Response Process. We used this extensively—it was an integral part of our company dynamic. We used it to develop company work, we used it in our education programs and we even used it to redesign our company structure. It was a formative part of my development as an artist, a teacher, and later, as a user-centered designer.
This is me about 25 years ago, dancing with a yoga ball. I was part of a theater company where I first learned Liz Lerman’s Critical Response Process. We used this extensively—it was an integral part of our company dynamic. We used it to develop company work, we used it in our education programs and we even used it to redesign our company structure. It was a formative part of my development as an artist, a teacher, and later, as a user-centered designer.
What I love about this process is that works by embedding all the things we strive for in a critique into a deceptively simple, step-by-step process. You don’t have to try to remember everything the next time you’re knee-deep in a critique session. It’s knowledge in the world for critique sessions.
So a while back I started thinking about how I could adapt this to critiquing design and I introduced the process to the Firefox UX team. We’ve been practicing and refining it since last summer and we’ve really found it helpful. Recently I’ve been getting requests to share our adapted version with other design teams so I’ve collected my notes and the cheat sheet we use to keep us on track over at critiquing.design. Please feel free to try it out. Let me know if you have questions or ideas to make it better. I’ve also started a GitHub repo for it so you can file an issue or make pull request if you want.
The other great part about this is that it changes critique from something like:
 To a time that I look forward to and that leaves me inspired by the smart, creative people I work with.
To a time that I look forward to and that leaves me inspired by the smart, creative people I work with.

TenFourFox Feature Parity Release 20 beta 1 is now available (downloads, hashes, release notes). Now here's an acid test: I watched the entire Democratic presidential debate live-streamed on the G5 with TenFourFox FPR20b1 and the MP4 Enabler, and my G5 did not burst into flames either from my code or their rhetoric. (*Note: Any politician of any party can set your G5 on fire. It's what they do.)
When using FPR20 you should notice ... absolutely nothing. Sites should just appear as they do; the only way you'd know anything changed in this version is if you pressed Command-I and looked at the Security tab to see that you're connected over TLS 1.3, the latest TLS security standard. In fact, the entirety of the debate was streamed over it, and to the best of my knowledge TenFourFox is the only browser that implements TLS 1.3 on Power Macs running Mac OS X. On regular Firefox your clue would be seeing occasional status messages about handshakes, but I've even disabled that for TenFourFox to avoid wholesale invalidating our langpacks which entirely lack those strings. Other than a couple trivial DOM updates I wrote up because they were easy, as before there are essentially no other changes other than the TLS enablement in this FPR to limit the regression range. If you find a site that does not work, verify first it does work in FPR19 or FPR18, because sites change more than we do, and see if setting security.tls.version.max to 3 (instead of 4) fixes it. You may need to restart the browser to make sure. If this does seem to reliably fix the problem, report it in the comments. A good test site is Google or Mozilla itself. The code we are using is largely the same as current Firefox's.
I have also chosen to enable Zero Round Trip Time (0-RTT) to get further speed. The idea with 0RTT is that the browser, having connected to a particular server before and knowing all the details, will not wait for a handshake and immediately starts sending encrypted data using a previous key modified in a predictable fashion. This saves a handshake and is faster to establish the connection. If many connections or requests are made, the potential savings could be considerable, such as to a site like Google where many connections may be made in a short period of time. 0RTT only happens if both the client and server allow it and there are a couple technical limitations in our implementation that restrict it further (I'm planning to address these assuming the base implementation sticks).
0RTT comes with a couple caveats which earlier made it controversial, and some browsers have chosen to unconditionally disable it in response. A minor one is a theoretical risk to forward secrecy, which would require a malicious server caching keys (but a malicious server could do other more useful things to compromise you) or an attack on TenFourFox to leak those keys. Currently neither is a realistic threat at present, but the potential exists. A slightly less minor concern is that users requiring anonymity may be identified by 0RTT pre-shared keys being reused, even if they change VPNs or exit nodes. However, the biggest is that, if handled improperly, it may facilitate a replay attack where encrypted data could be replayed to trigger a particular action on the server (such as sending Mallory a billion dollars twice). Firefox/TenFourFox avoid this problem by never using 0RTT when a non-idempotent action is taken (i.e., any HTTP method that semantically changes state on the server, as opposed to something that merely fetches data), even if the server allows it. Furthermore, if the server doesn't allow it, then 0RTT is not used (and if the server inappropriately allows it, consider that their lack of security awareness means they're probably leaking your data in other, more concerning ways too).
All that said, even considering these deficiencies, TLS 1.3 with 0-RTT is still more secure than TLS 1.2, and the performance benefits are advantageous.
HTML was initially designed as a semantic markup language,
with elements having semantics (meaning)
describing general roles within a document.
These semantic elements have been added to over time.
Markup as it is used on the web is often criticized for not following the semantics,
but rather being a soup of divs and spans,
the most generic sorts of elements.
The Web has also evolved over the last 25 years from a web of documents
to a web where many of the most visited pages are really applications rather than documents.
The HTML markup used on the Web is a representation of a tree structure,
and the user interface of these web applications
is often based on dynamic changes made through the DOM,
which is what we call both the live representation of that tree structure
and the API through which that representation is accessed.
Browsers exist as tools for users to browse the Web; they strike a balance between showing the content as its author intended versus adapting that content to the device it is being displayed on and the preferences or needs of the user.
Given the unreliable use of semantics on the Web, most of the ways browsers adapt content to the user rarely depend deeply on semantics, although some of them (such as reader mode) do have significant dependencies. However, browser adaptations of content or interventions that browsers make on behalf of the user very frequently depend on the persistent object identity in the DOM. That is, nodes in the DOM tree (such as sections of the page, or paragraphs) have an identity over the lifetime of the page, and many things that browsers do depend on that identity being consistent over time. For example, exposing the page to a screen reader, scroll anchoring, and I think some aspects of ad blocking all depend on the idea that there are elements in the web page that the browser understands the identity of over time.
This might seem like it's not a very interesting observation. However, I believe it's important in the context of frameworks, like React, that use a programming model (which many developers find easier) where the developer writes code to map application state to user interface rather than having to worry about constantly altering the DOM to match the current state. These frameworks have an expensive step where they have to map the generated virtual DOM into a minimal set of changes to the real DOM. It is well known that it's important for performance for this set of changes to be minimal, since making fewer changes to the DOM results in the browser doing less work to render the updated page. However, this process is also important for the site to be a true part of the Web, since this rectification is important for being something that the browser can properly adapt to the device and to the user's needs.
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean. You can find an index of all TWiG posts online.)
Last Week: Extending Glean: build re-usable types for new use-cases by Alessio
I was recently struck by a realization that the position of our data org’s team members around the globe mimics the path that data flows through the Glean Ecosystem.
Glean Data takes this five-fold path (corresponding to five teams):
- Data is collected in a client using the Glean SDK (Glean Team)
- Data is transmitted to the Structured Ingestion pipeline (Data Platform)
- Data is stored and maintained in our infrastructure (Data Operations)
- Data is presented in our tools (Data Tools)
- Data is analyzed and reported on (Data Science)
The geographical midpoint of the Glean Team is about halfway across the north atlantic. For Data Platform it’s on the continental US, anchored by three members in the midwestern US. Data Ops is further West still, with four members in the Pacific timezone and no Europeans. Data Tools breaks the trend by being a bit further East, with fewer westcoasters. Data Science (for Firefox) is centred farther west still, with only two members East of the Rocky Mountains.
Or, graphically:

Given the rotation of the Earth, the sun rises first on the Glean Team and the data collected by the Glean SDK. Then the data and the sun move West to the Data Platform where it is ingested. Data Tools gets the data from the Platform as morning breaks over Detroit. Data Operations keeps it all running from the midwest. And finally, the West Coast Centre of Firefox Data Science Excellence greets the data from a mountaintop, to try and make sense of it all.
(( Lying orthogonal to the data organization is the secret Sixth Glean Data “Team”: Data Stewardship. They ensure all Glean Data is collected in accordance with Mozilla’s Privacy Promise. The sun never sets on the Stewardship’s global coverage, and it’s a volunteer effort supplied from eight teams (and growing!), so I’ve omitted them from this narrative. ))
Bad metaphors about sunlight aside, I wonder whether this is random or whether this is some sort of emergent behaviour.
Conway’s Law suggests that our system architecture will tend to reflect our orgchart (well, the law is a bit more explicit about “communication structure” independent of organizational structure, but in the data org’s case they’re pretty close). Maybe this is a specific example of that: data architecture as a reflection of orgchart geography.
Or perhaps five dots on a globe that are only mostly in some order is too weak of a coincidence to even bear thinking about? Nah, where’s the blog post in that thinking…
If it’s emergent, it then becomes interesting to consider the “chicken and egg” point of view: did the organization beget the system or the system beget the organization? When I joined Mozilla some of these teams didn’t exist. Some of them only kinda existed within other parts of the company. So is the situation we’re in today a formalization by us of a structure that mirrors the system we’re building, or did we build the system in this way because of the structure we already had?
:chutten

After a nine month leadup, chat.mozilla.org, our Matrix-based replacement for IRC, has been up running for about a month now.
While we’ve made a number of internal and community-facing announcements about progress, access and so forth, we’ve deliberately run this as a quiet, cautious, low-key rollout, letting our communities find their way to chat.m.o and Matrix organically while we sort out the bugs and rough edges of this new experience.
Last week we turned on federation, the last major step towards opening Mozilla to the wider Matrix ecosystem, and it’s gone really well. Which means that as of last week, Mozilla’s transition from IRC to Matrix is within arm’s reach of done.
The Matrix team have been fantastic partners throughout this process, open to feedback and responsive to concerns throughout. It’s been a great working relationship, and as investments of effort go one that’s already paying off exactly the way want our efforts to pay off, with functional, polish and accessibility improvements that benefit the entire Matrix ecosystem coming from the feedback from the Mozilla community.
We still have work to do, but this far into the transition it sure feels like winning. The number of participants in our primary development channels has already exceeded their counterparts on IRC at their most active, and there’s no sign that’s slowing down. Many of our engineering and ops teams are idling or archiving their Slack channels and have moved entirely to Matrix, and that trend isn’t slowing down either.
As previously announced, we’re on schedule to turn off IRC.m.o at the end of the month, and don’t see a reason to reconsider that decision. So far, it looks like we’re pretty happy on the new system. It’s working well for us.
So: Welcome. If you’re new to Mozilla or would like to get involved, come see us in the #Introduction channel on our shiny new Matrix system. I hope to see you there.
http://exple.tive.org/blarg/2020/02/20/synchronous-messaging-were-live/
A short while ago curl‘s 230th command line option was added (it was --mail-rcpt-allowfails). Two hundred and thirty command line options!
A look at curl history shows that on average we’ve added more than ten new command line options per year for very long time. As we don’t see any particular slowdown, I think we can expect the number of options to eventually hit and surpass 300.
Is this manageable? Can we do something about it? Let’s take a look.
Why so many options?
There are four primary explanations why there are so many:
- curl supports 24 different transfer protocols, many of them have protocol specific options for tweaking their operations.
- curl’s general design is to allow users to individual toggle and set every capability and feature individually. Every little knob can be on or off, independently of the other knobs.
- curl is feature-packed. Users can customize and adapt curl’s behavior to a very large extent to truly get it to do exactly the transfer they want for an extremely wide variety of use cases and setups.
- As we work hard at never breaking old scripts and use cases, we don’t remove old options but we can add new ones.
An entire world already knows our options
curl is used and known by a large amount of humans. These humans have learned the way of the curl command line options, for better and for worse. Some thinks they are strange and hard to use, others see the logic behind them and the rest simply accepts that this is the way they work. Changing options would be conceived as hostile towards all these users.
curl is used by a very large amount of existing scripts and programs that have been written and deployed and sit there and do their work day in and day out. Changing options, even ever so slightly, risk breaking some to many of these scripts and make a lot of developers out there upset and give them everything from nuisance to a hard time.
curl is the documented way to use APIs, REST calls and web services in numerous places. Lots of examples and tutorials spell out how to use curl to work with services all over the world for all sorts of interesting things. Examples and tutorials written ages ago that showcase curl still work because curl doesn’t break behavior.
curl command lines are even to some extent now used as a translation language between applications:
All the four major web browsers let you export HTTP requests to curl command lines that you can then execute from your shell prompts or scripts. Other web tools and proxies can also do this.
There are now also tools that can import said curl command lines so that they can figure out what kind of transfer that was exported from those other tools. The applications that import these command lines then don’t want to actually run curl, they want to figure out details about the request that the curl command line would have executed (and instead possibly run it themselves). The curl command line has become a web request interchange language!
There are also a lot of web services provided that can convert a curl command line into a source code snippet in a variety of languages for doing the same request (using the language’s native preferred method). A few examples of this are: curl as DSL, curl to Python Requests, curl to Go, curl to PHP and curl to perl.
Can the options be enhanced?
I hope I’ve made it clear why we need to maintain the options we already support. However, it doesn’t limit what we can add or that we can’t add new ways of doing things. It’s just code, of course it can be improved.
We could add alternative options for existing ones that make sense, if there are particular ones that are considered complicated or messy.
We could add a new “mode” that would have a totally new set of options or new way of approaching what we think of options today.
Heck, we could even consider doing a separate tool next to curl that would similarly use libcurl for the transfers but offer a totally new command line option approach.
None of these options are ruled out as too crazy or far out. But they all of course require that someone think of them as a good ideas and is prepared to work on making
Welcome!
Please note some of the information provided in this report may be subject to change as we are sometimes sharing information about projects that are still in early stages and are not final yet.
New localizers
- Bora of Kabardian joined us through the Common Voice project
- Kevin of Swahili
- Habib and Shamim of Bengali joined us through the WebThings Gateway project
Are you a locale leader and want us to include new members in our upcoming reports? Contact us!
New community/locales added
- Karakalpak
- Luganda: revitalization of the community, thanks to the Common Voice projects.
- Scots
New content and projects
What’s new or coming up in Firefox desktop
Firefox is now officially following a 4-weeks release cycle:
- Firefox 74 is currently in beta and it will be released on March 10. The deadline to update your localization is February 25.
- Firefox 75, currently in Nightly, will move to Beta when 74 is officially released. The deadline to update localizations for that version will be on March 24 (4 weeks after the current deadline).
In terms of localization priority and deadlines, note that the content of the What’s new panel, available at the bottom of the hamburger menu, doesn’t follow the release train. For example, content for 74 has been exposed on February 17, and it will be possible to update translations until the very end of the cycle (approximately March 9), beyond the normal deadline for that version.
What’s new or coming up in mobile
We have some exciting news to announce on the Android front!
Fenix, the new Android browser, is going to release in April. The transition from Firefox for Android (Fennec) to Fenix has already begun! Now that we have an in-app locale switcher in place, we have the ability to add languages even when they are not supported by the Android system itself.
As a result, we’ve opened up the project on Pontoon to many new locales (89 total). Our goal is to reach Firefox for Android parity in terms of completion and number of locales.
This is a much smaller project than Firefox for Android, and a very innovative and quick software. We hope this excites you as much as us. And we truly hope to deliver to users across the world the same experience as with Firefox for Android, in terms of localization.
Delphine will be away for the next few months. Jeff is standing in for her on the PM front, with support from Flod on the technical front. While Delphine is away, we won’t be enabling new locales on mobile products outside of Fenix. This is purely because our current resourcing allows us to give Fenix the priority, but at the expense of other products. Stay tuned for more open and individual outreach from Jeff about Fenix and other mobile projects.
What’s new or coming up in web projects
Mozilla.org
Changes are coming to mozilla.org. The team behind mozilla.org has been working all year to transition from the .lang format to Fluent. Communications on the details around this transition will be coming through the mailing list.
Additionally, the following pages were added since the last report
New:
- firefox/browsers.lang
- firefox/products.lang
- firefox/whatsnew_73.lang
- firefox/set-default-thanks.lang
Community Participation Guideline (CPG)
The CPG has a major update, including a new page and additional locales. Feel free to review and provide feedback by filing a bug.
- New: /mozorg/about/governance/policies/community-hotline.lang
- Updated: /mozorg/about/governance/policies/participation.lang
- No change: /mozorg/about/governance/policies/reporting.lang
Languages:
So what’s going on with the SUMO platform? We’re moving forward in 2020 with new plans, new challenges and a new roadmap.
We’re continuing this year to track all development work in 2 week sprints. You can see everything that is currently being worked on and our current sprint here (please note: this is only a project tracking board, do not use it to file bugs, bugs should continue to be filed via Bugzilla)
In order to be more transparent about what’s going on we are starting a round of blog posts to summarize every sprint and plan for the next. We’ve just closed Sprint no. 3 of 2020 and we’re moving into Sprint no.4
What happened in the last two weeks?
During the last two weeks we have been working tirelessly together with our partner, Lincoln Loop, to get Responsive Redesign out the door. The good news is that we are almost done.
We have also been working on a few essential upgrades. Currently support.mozilla.org is running on Python 2.7 which is no longer supported. We have been working on upgrading to Python3.7 and the latest Django Long Term Support (LTS) version 2.2. This is also almost done and we are expecting to move into the QA and bug fixing phase.
What’s happening in the next sprint?
During the next two weeks we’re going to start wrapping up Responsive redesign as well as the Python/Django upgrade and focus on QA and bug fixing. We’re also planning to finalize a Celery 4 upgrade.
The next big thing is the integration of Firefox Accounts. As of May 2019 we have been working towards using Firefox Accounts as the authentication system on support.mozilla.org Since the first phase of this project was completed we have been using both login via Firefox Accounts as well as the old SUMO login. It is now time to fully switch to Firefox Accounts. The current plan is to do this mid-March but expect to see some communication about this later this week.
For more information please check out our roadmap and feel free to reach out if you have any questions
https://blog.mozilla.org/sumo/2020/02/19/whats-happening-on-the-sumo-platform-sprint-updates/
To avoid having to deal with escapes (other than for <, >, &, and "), to avoid data loss in form submission, to avoid XSS when serving user-provided content, and to comply with the HTML Standard, always encode your HTML as UTF-8. Furthermore, in order to let browsers know that the document is UTF-8-encoded, always label it as such. To label your document, you need to do at least one of the following:
Put
as the first thing after thetag.The
metatag, including its ending>character needs to be within the first 1024 bytes of the file. Putting it right afteris the easiest way to get this right. Do not put comments before.Configure your server to send the header
Content-Type: text/html; charset=utf-8on the HTTP layer.Start the document with the UTF-8 BOM, i.e. the bytes 0xEF, 0xBB, and 0xBF.
Doing more than one of these is OK.
Answers to Questions
The above says the important bit. Here are answers to further questions:
Why Do I Need to Label UTF-8 in HTML?
Because HTML didn’t support UTF-8 in the very beginning and legacy content can’t be expected to opt out, you need to opt into UTF-8 just like you need to opt into the standards mode (via ) and to mobile-friedly layout (via ). (Longer answer)
Which Method Should I Choose?
has the benefit of keeping the label within your document even if you move it around. The main risk is that someone forgets that it needs to be within the first 1024 bytes and puts comments, Facebook metadata, rel=preloads, stylesheets or scripts before it. Always put that other stuff after it.
The HTTP header has the benefit that if you are setting up a new server that doesn’t have any old non-UTF-8 documents on it, you can configure the header once, and it works for all HTML documents on the server thereafter.
The BOM method has the problem that it’s too easy to edit the file in a text editor that removes the BOM and not notice that this has happened. However, if you are writing a serializer library and you are neither in control of the HTTP header nor can inject a tag without interfering with what your users are doing, you can make the serializer always start with the UTF-8 BOM and know that things will be OK.
Can I Use UTF-16 Instead?
Don’t. If you serve user-provided content as UTF-16, it is possible to smuggle content that becomes executable when interpreted as other encodings. This is a cross-site scripting vulnerability if the user uses a browser that allows the user to manually override UTF-16 with another encoding.
UTF-16 cannot be labeled via .
What about Plain Text?
The method is not available for plain text, but the other two are. In the case of plain text, the HTTP header is obviously Content-Type: text/plain; charset=utf-8 instead.
What about JavaScript?
If you’ve labeled your HTML as UTF-8, you don’t need to label your UTF-8-encoded JavaScript files, since by default they inherit the encoding from the document that includes them. However, to make your JavaScript robust when referenced form non-UTF-8 HTML you can use the UTF-8 BOM or the HTTP header, which is Content-Type: application/javascript; charset=utf-8 in the JavaScript case.
What about CSS?
If you’ve labeled your HTML as UTF-8, you don’t need to label your UTF-8-encoded CSS files, since by default they inherit the encoding from the document that includes them. However, to make your CSS robust when referenced form non-UTF-8 HTML you can use the UTF-8 BOM or the HTTP header, which is Content-Type: text/css; charset=utf-8 in the CSS case, or you can put @charset "utf-8"; as the very first thing in the CSS file.
What about XML (Including SVG)?
Unlabeled XML defaults to UTF-8, so you don’t need to label it.
What about JSON?
JSON must be UTF-8 and is processed as UTF-8, so there’s no labeling.
What about WebVTT?
WebVTT is always UTF-8, so there’s no labeling.
In a strategy and two white papers published today, the Commission has laid out its vision for the next five years of EU tech policy: achieving trust by fostering technologies working for people, a fair and competitive digital economy, and a digital and sustainable society. This vision includes big ambitions for content regulation, digital competition, artificial intelligence, and cybersecurity. Here we give some recommendations on how the Commission should take it forward.
We welcome this vision the Commission sketches out and are eager to contribute, because the internet today is not what we want it to be. A rising tide of illegal and harmful content, the pervasiveness of the surveillance economy, and increased centralisation of market power have damaged the internet’s original vision of openness. We also believe that innovation and fundamental rights are complementary and should always go hand in hand – a vision we live out in the products we build and the projects we take on. If built on carefully, the strategy can provide a roadmap to address the many challenges we face, in a way that protects citizens’ rights and enhances internet openness.
However, it’s essential that the EU does not repeat the mistakes of the past, and avoids misguided, heavy handed and/or one-size-fits-all regulations. The Commission should look carefully at the problems we’re trying to solve, consider all actors impacted and think innovatively about smart interventions to open up markets and protect fundamental rights. This is particularly important in the content regulation space, where the last EU mandate saw broad regulatory interventions (e.g. on copyright or terrorist content) that were crafted with only the big online platforms in mind, undermining individuals’ rights and competition. Yet, and despite such interventions, big platforms are not doing enough to tackle the spread of illegal and harmful content. To avoid such problematic outcomes, we encourage the European Commission to come up with a comprehensive framework for ensuring that tech companies really do act responsibly, with a focus on the companies’ practices and processes.
Elsewhere we are encouraged to see that the Commission intends on evaluating and reviewing EU competition rules to ensure that they remain fit for purpose. The diminishing nature of competition online and the accelerating trend towards web centralisation in the hands of a few powerful companies goes against the open and diverse internet ecosystem we’ve always fought for. The nature of the networked platform ecosystem is giving rise to novel competition challenges, and it is clear that the regulatory toolbox for addressing them is not fit-for-purpose. We look forward to working with EU lawmakers on how EU competition policy can be modernised, to take into account bundling, vertical integration, the role of data silos, and the potential of novel remedies.
We’re also happy to see the EU take up the mantle of AI accountability and seek to be a standard-setter for better regulation in this space. This is an area that will be of crucial importance in the coming years, and we are intent on shaping a progressive, human-centric approach in Europe and beyond.
The opportunity for EU lawmakers to truly lead and to set the future of tech regulation on the right path is theirs for the taking. We are eager and willing to help contribute and look forward to continuing our own work to take back the web.
The post The new EU digital strategy: A good start, but more to be done appeared first on Open Policy & Advocacy.
A string of secondary issues have been plaguing our restart of anonymous reporting on webcompat.com.
- This week's issues
-
fixed! Dependencies upgrade
- fixed! Anonymous reporting works on staging but fails on prod. This one gave me headaches and a lot of testing, but mike got us out of the woods. OAuth tokens have scope. Our token was valid only for public repos, not the private ones. It's why webcompat-bot was unable to publish in public.
- fixed! Closing a private issue after it's been moved to "accepted" sets the moderation template to rejected belt-on: phase 2 . So I probably need to explain the new workflow here.
new anonymous workflow reporting.
- A bug is reported anonymously
- We send the data to a private repository (waiting for moderation)
- We put a placeholder on the public repository, saying that this will be moderated later on.
- In the private repo, the moderators can either:
- set the milestone to accepted in the private repo and the public moderation placeholder will be replaced with the real issue content.
- close the issue in the private repo (means it has been rejected) and it will replace the public moderation placeholder by another message saying it was rejected.
Simple! I had forgotten to handle the case of private issue with milestone accepted being closed. This erased a valid moderated issue. Not good. So we fixed it. This is now working.
from string to boolean in python
There was a solution to the issue we had last week about our string which is not a boolean: strtobool. Thanks to rik. Implementation details. Values include on and off. Neat!
coverage and pytest
In the process of trying to improve the project, I looked at the results of coverage on the project. I was pleasantly surprised for some areas of the code. But I also decided to open a couple of issues related to other parts. The more and better tests we have, the more robust the project will be.
While running coverage, I also stumbled upon this sentence in the documentation:
Nose has been unmaintained for a long time. You should seriously consider adopting a different test runner.
So I decided to create an issue specific on switching from nosetests to pytest.
And I started to work on that. It led to an interesting number of new breakages and warnings. First pytest is working better with an installable code.
pip install -e .
So I created a very simple and basic setup.py
then I ran to an issue that has bitten me in the past: flask blueprint.
Do NOT name the module, the directory and the blueprint with the same name.
Basically our code has this kind of constructs. subtree to make it simpler.
-- webcompat |-- __init__.py |-- form.py |-- api | |-- __init__.py | |-- uploads.py | |--