Summary / TL;DR
| Project | What’s in it? | Status |
| C++20 | See Reddit report | Technically complete |
| Library Fundamentals TS v3 | Library utilities incubating for standardization | Under development |
| Concepts | Constrained templates | Shipping as part of C++20 |
| Parallelism TS v2 | Task blocks, library vector types and algorithms, and more | Published! |
| Executors | Abstraction for where/how code runs in a concurrent context | Targeting C++23 |
| Concurrency TS v2 | Concurrency-related infrastructure (e.g. fibers) and data structures | Under active development |
| Networking TS | Sockets library based on Boost.ASIO | Published! Not in C++20. |
| Ranges | Range-based algorithms and views | Shipping as part of C++20 |
| Coroutines | Resumable functions (generators, tasks, etc.) | Shipping as part of C++20 |
| Modules | A component system to supersede the textual header file inclusion model | Shipping as part of C++20 |
| Numbers TS | Various numerical facilities | Under active development |
| C++ Ecosystem TR | Guidance for build systems and other tools for dealing with Modules | Under active development |
| Contracts | Preconditions, postconditions, and assertions | Under active development |
| Pattern matching | A match-like facility for C++ |
Under active development |
| Reflection TS | Static code reflection mechanisms | Publication imminent |
| Reflection v2 | A value-based constexpr formulation of the Reflection TS facilities, along with more advanced features such as code injection |
Under active development |
A few links in this blog post may not resolve until the committee’s post-meeting mailing is published (expected any day). If you encounter such a link, please check back in a few days.
Introduction
A few weeks ago I attended a meeting of the ISO C++ Standards Committee (also known as WG21) in Prague, Czech Republic. This was the first committee meeting in 2020; you can find my reports on 2019’s meetings here (November 2019, Belfast), here (July 2019, Cologne), and here (February 2019, Kona), and previous ones linked from those. These reports, particularly the Belfast one, provide useful context for this post.
This meeting once again broke attendance records, with about ~250 people present. It also broke the record for the number of national standards bodies being physically represented at a meeting, with reps from Austria and Israel joining us for the first time.
The Prague meeting wrapped up the C++20 standardization cycle as far as technical work is concerned. The highest-priority work item for all relevant subgroups was to continue addressing any remaining comments on the C++20 Committee Draft, a feature-complete C++20 draft that was circulated for feedback in July 2019 and received several hundred comments from national standards bodies (“NB comments”). Many comments had been addressed already at the previous meeting in Belfast, and the committee dealt with the remaining ones at this meeting.
The next step procedurally is for the committee to put out a revised draft called the Draft International Standard (DIS) which includes the resolutions of any NB comments. This draft, which was approved at the end of the meeting, is a technically complete draft of C++20. It will undergo a further ballot by the national bodies, which is widely expected to pass, and the official standard revision will be
So far another uneventful release on ppc64le; I'm typing this blog post in Fx74. Most of what's new in this release is under the hood, and there are no OpenPOWER specific changes (I need to sit down with some of my other VMX/VSX patches and prep them for upstream). The working debug and optimized .mozconfigs are unchanged from Firefox 67.
The Rust team is happy to announce a new version of Rust, 1.42.0. Rust is a programming language that is empowering everyone to build reliable and efficient software.
If you have a previous version of Rust installed via rustup, getting Rust 1.42.0 is as easy as:
rustup update stable
If you don't have it already, you can get rustup from the appropriate page on our website, and check out the detailed release notes for 1.42.0 on GitHub.
What's in 1.42.0 stable
The highlights of Rust 1.42.0 include: more useful panic messages when unwrapping, subslice patterns, the deprecation of Error::description, and more. See the detailed release notes to learn about other changes not covered by this post.
Useful line numbers in Option and Result panic messages
In Rust 1.41.1, calling unwrap() on an Option::None value would produce an error message looking something like this:
thread 'main' panicked at 'called `Option::unwrap()` on a `None` value', /.../src/libcore/macros/mod.rs:15:40
Similarly, the line numbers in the panic messages generated by unwrap_err, expect, and expect_err, and the corresponding methods on the Result type, also refer to core internals.
In Rust 1.42.0, all eight of these functions produce panic messages that provide the line number where they were invoked. The new error messages look something like this:
thread 'main' panicked at 'called `Option::unwrap()` on a `None` value', src/main.rs:2:5
This means that the invalid call to unwrap was on line 2 of src/main.rs.
This behavior is made possible by an annotation, #[track_caller]. This annotation is not yet available to use in stable Rust; if you are interested in using it in your own code, you can follow its progress by watching this tracking issue.
Subslice patterns
In Rust 1.26, we stabilized "slice patterns," which let you match on slices. They looked like this:
fn foo(words: &[&str]) {
match words {
[] => println!("empty slice!"),
[one] => println!("one element: {:?}", one),
[one, two] => println!("two elements: {:?} {:?}", one, two),
_ => println!("I'm not sure how many elements!"),
}
}
This allowed you to match on slices, but was fairly limited. You had to choose the exact sizes you wished to support, and had to have a catch-all arm for size you didn't want to support.
In Rust 1.42, we have expanded support for matching on parts of a slice:
fn foo(words: &[&str]) {
match words {
["Hello", "World", "!", ..] => println!("Hello World!"),
["Foo", "Bar", ..] => println!("Baz"),
rest => println!("{:?}", rest),
}
}
The .. is called a "rest pattern," because it matches the rest of the slice. The above example uses the rest pattern at the end of a slice, but you can also use it in other ways:
fn foo(words: &[&str]) {
match words {
// Ignore everything but the last element, which must be "!".
[.., "!"] => println!("!!!"),
// `start` is a slice of everything except the last element, which must be "z".
[start @ .., "z"] => println!("starts with: {:?}", start),
// `end` is a slice of everything but the first element, which must be "a".
["a", end @ ..] => println!("ends with: {:?}", end),
rest => println!("{:?}", rest),
}
}
If you're interested in learning more, we published a post on the Inside Rust blog discussing these
I work from home. I have been doing so for the last four years, ever since I joined Mozilla. Some people dislike it, but it suits me well: I get the calm, focused, relaxing environment needed to work on complex problems all in the comfort of my home.

Even given the opportunity, I probably wouldn't go back to working in an office. For the kind of work that I do, quiet time is more important than high bandwidth human interaction.
Yet, being able to talk to my colleagues and exchanges ideas or solve problems is critical to being productive. That's where the video-conferencing bit comes in. At Mozilla, we use Vidyo Zoom primarily, sometimes Hangout and more rarely Skype. We spend hours every week talking to each other via webcams and microphones, so it's important to do it well.
Having a good video setup is probably the most important and yet least regarded aspect of working remotely. When you start at Mozilla, you're given a laptop and a Zoom account. No one teaches you how to use it. Should I have an external webcam or use the one on your laptop? Do I need headphones, earbuds, a headset with a microphone? What kind of bandwidth does it use? Those things are important to good telepresence, yet most of us only learn them after months of remote work.
When your video setup is the main interface between you and the rest of your team, spending a bit of time doing it right is far from wasted. The difference between a good microphone and a shitty little one, or a quiet room and taking calls from the local coffee shop, influence how much your colleagues will enjoy working with you. I'm a lot more eager to jump on a call with someone I know has good audio and video, than with someone who will drag me in 45 minutes of ambient noise and coughing in his microphone.
This is a list of tips and things that you should care about, for yourself, and for your coworkers. They will help you build a decent setup with no to minimal investment.
The place
It may seem obvious, but you shouldn't take calls from a noisy place. Airports, coffee shops, public libraries, etc. are all horribly noisy environments. You may enjoy working from those places, but your interlocutors will suffer from all the noise. Nowadays, I refuse to take calls and cut meetings short when people try to force me into listening to their surrounding. Be respectful of others and take meetings from a quiet space.
Bandwidth
Despite what ISPs are telling you, no one needs 300Mbps of upstream bandwidth. Take a look at the graph below. It measures the egress point of my gateway. The two yellow spikes are video meetings. They don't even reach 1Mbps! In the middle of the second one, there's a short spike at 2Mbps when I set Vidyo to send my stream at 1080p, but shortly reverted because that software is broken and the faces of my coworkers disappeared. Still, you get the point: 2Mbps is the very maximum you'll need for others to see you, and about the same amount is needed to download their streams.
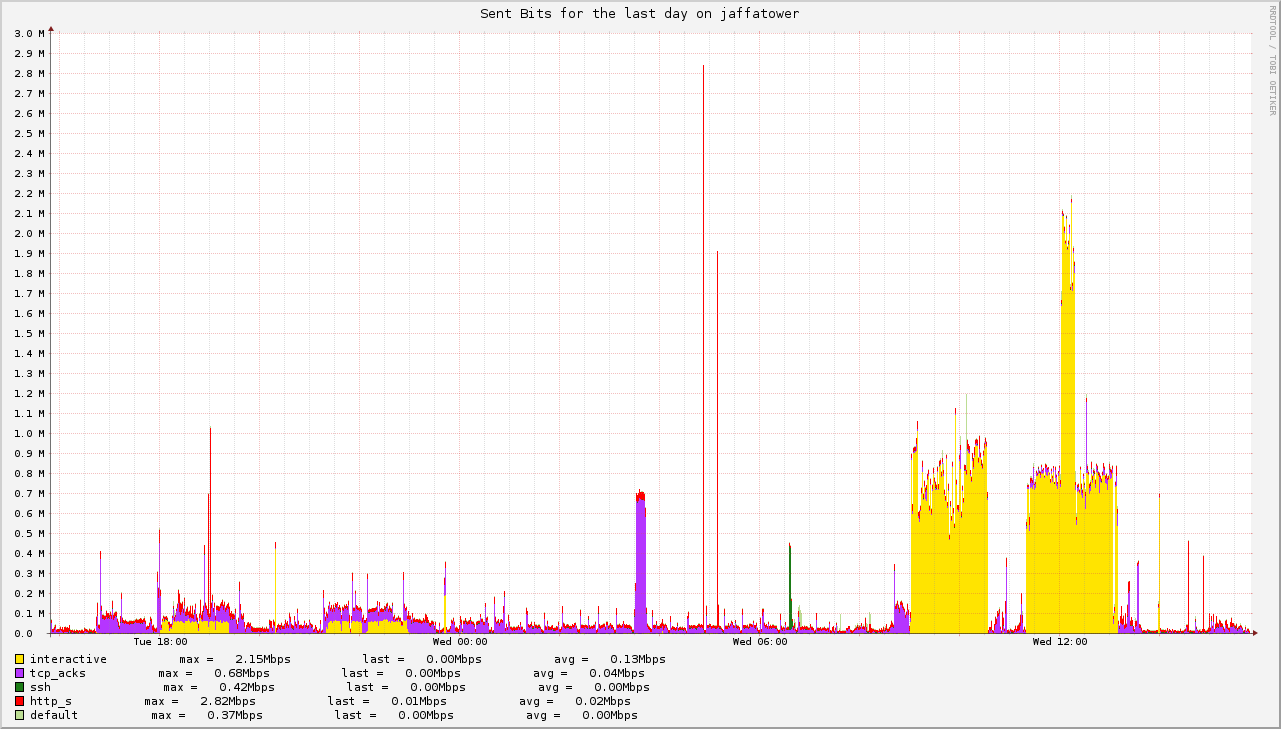
You do want to be careful about ping: latency can increase up to 200ms without issue, but even 5% packet drop is enough to make your whole experience miserable. Ask Tarek what bad connectivity does to your productivity: he works from a remote part of france where bandwidth is scarce and latency is high. I coined him the inventor of the Tarek protocol, where you have to repeat each word twice for others to understand what you're saying. I'm joking, but the truth is that it's exhausting for everyone. Bad connectivity is tough on remote workers.
(Tarek thought it'd be worth mentioning that he tried to improve his connectivity by subscribing to a satellite connection, but ran into issues in the routing of his traffic: 700ms latency was actually worse than his broken DSL.)
Microphone
Perhaps the single most important aspect of video-conferencing is the quality of your microphone and how you use it. When everyone is wearing headphones, voice quality matters a lot. It is the difference between a pleasant 1h conversation, or a frustrating one that leaves you with a headache.
Rule #1: MUTE!
Let me say that again: FREAKING MUTE ALREADY!
Video softwares are terrible at routing the audio of several people at the same time. This isn't the same as a meeting room, where your brain will gladly separate the voice of someone you're speaking to from the keyboard of the dude next to you. On video, everything is at the same volume, so when you start answering that email while your colleagues are speaking, you're pretty much taking over their entire conversation with keyboard noises. It's terrible, and there's nothing more annoying than
This release comes but 7 days since the previous and is a patch release only, hence called 7.69.1.
Numbers
the 190th release
0 changes
7 days (total: 8,027)
27 bug fixes (total: 5,938)
48 commits (total: 25,405
0 new public libcurl function (total: 82)
0 new curl_easy_setopt() option (total: 270)
0 new curl command line option (total: 230)
19 contributors, 6 new (total: 2,133)
7 authors, 1 new (total: 772)
0 security fixes (total: 93)
0 USD paid in Bug Bounties
Unplanned patch release
Quite obviously this release was not shipped aligned with our standard 8-week cycle. The reason is that we had too many semi-serious or at least annoying bugs that were reported early on after the 7.69.0 release last week. They made me think our users will appreciate a quick follow-up that addresses them. See below for more details on some of those flaws.
How can this happen in a project that soon is 22 years old, that has thousands of tests, dozens of developers and 70+ CI jobs for every single commit?
The short answer is that we don’t have enough tests that cover enough use cases and transfer scenarios, or put another way: curl and libcurl are very capable tools that can deal with a nearly infinite number of different combinations of protocols, transfers and bytes over the wire. It is really hard to cover all cases.
Also, an old wisdom that we learned already many years ago is that our code is always only properly widely used and tested the moment we do a release and not before. Everything can look good in pre-releases among all the involved developers, but only once the entire world gets its hands on the new release it really gets to show what it can or cannot do.
This time, a few of the changes we had landed for 7.69.0 were not good enough. We then go back, fix issues, land updates and we try again. So here comes 7.69.1 – better patch than sorry!
Bug-fixes
As the numbers above show, we managed to land an amazing number of bug-fixes in this very short time. Here are seven of the more important ones, from my point of view! Not all of them were regressions or even reported in 7.69.0, some of them were just ripe enough to get landed in this release.
unpausing HTTP/2 transfers
When I fixed the pausing and unpausing of HTTP/2 streams for 7.69.0, the fix was inadequate for several of the more advanced use cases and unfortunately we don’t have good enough tests to detect those. At least two browsers built to use libcurl for their HTTP engines reported stalled HTTP/2 transfers due to this.
I reverted the previous change and I’ve landed a different take that seems to be a more appropriate one, based on early reports.
pause: cleanups
After I had modified the curl_easy_pause function for 7.69.0, we also got reports about crashes with uses of this function.
It made me do some additional cleanups to make it more resilient to bad uses from applications, both when called without a correct handle or when it is called to just set the same pause state it is already in
socks: connection regressions
I was so happy with my overhauled SOCKS connection code in 7.69.0 where it was made entirely non-blocking. But again it turned out that our test cases for this weren’t entirely mimicking the real world so both SOCKS4 and SOCKS5 connections where curl does the name resolving could easily break. The test cases probably worked fine there because they always resolve the host name really quick and locally.
SOCKS4 connections are now also forced to be done over IPv4 only, as that was also something that could trigger a funny error – the protocol doesn’t support IPv6, you need to go to SOCKS5 for that!
Both version 4 and 5 of the SOCKS proxy protocol have options to allow the proxy to resolve the server name or you can have the client (curl) do it. (Somewhat described in the CURLOPT_PROXY man page.) These problems were found for the cases when curl resolves the server name.
libssh: MD5 hex comparison
For application users of the libcurl CURLOPT_SSH_HOST_PUBLIC_KEY_MD5 option, which is used to verify that curl connects to the right server, this change makes sure that the libssh backend does the right thing
Someone tried using rr to debug gdb and reported an rr issue because it didn't work. With some effort I was able to fix a couple of bugs and get it working for simple cases. Using improved debuggers to improve debuggers feels good!
The main problem when running gdb under rr is the need to emulate ptrace. We had the same problem when we wanted to debug rr replay under rr. In Linux a process can only have a single ptracer. rr needs to ptrace all the processes it's recording — in this case gdb and the process(es) it's debugging. Gdb needs to ptrace the process(es) it's debugging, but they can't be ptraced by both gdb and rr. rr circumvents the problem by emulating ptrace: gdb doesn't really ptrace its debuggees, as far as the kernel is concerned, but instead rr emulates gdb's ptrace calls. (I think in principle any ptrace user, e.g. gdb or strace, could support nested ptracing in this way, although it's a lot of work so I'm not surprised they don't.)
Most of the ptrace machinery that gdb needs already worked in rr, and we have quite a few ptrace tests to prove it. All I had to do to get gdb working for simple cases was to fix a couple of corner-case bugs. rr has to synthesize SIGCHLD signals sent to the emulated ptracer; these signals weren't interacting properly with sigsuspend. For some reason gdb spawns a ptraced process, then kills it with SIGKILL and waits for it to exit; that wait has to be emulated by rr because in Linux regular "wait" syscalls can only wait for a non-child process if the waiter is ptracing the target process, and under rr gdb is not really the ptracer, so the native wait doesn't work. We already had logic for that, but it wasn't working for process exits triggered by signals, so I had to rework that, which was actually pretty hard (see the rr issue for horrible details).
After I got gdb working I discovered it loads symbols very slowly under rr. Every time gdb demangles a symbol it installs (and later removes) a SIGSEGV handler to catch crashes in the demangler. This is very sad and does not inspire trust in the quality of the demangling code, especially if some of those crashes involve potentially corrupting memory writes. It is slow under rr because rr's default syscall handling path makes cheap syscalls like rt_sigaction a lot more expensive. We have the "syscall buffering" fast path for the most frequent syscalls, but supporting rt_sigaction along that path would be rather complicated, and I don't think it's worth doing at the moment, given you can work around the problem using maint set catch-demangler-crashes off. I suspect that (with KPTI especially) doing 2-3 syscalls per symbol demangle (sigprocmask is also called) hurts gdb performance even without rr, so ideally someone would fix that. Either fix the demangling code (possibly writing it in a safe language like Rust), or batch symbol demangling to avoid installing and removing a signal handler thousands of times, or move it to a child process and talk to it asynchronously over IPC — safer too!
http://robert.ocallahan.org/2020/03/debugging-gdb-using-rr-ptrace-emulation.html
Today sees the release of Firefox number 74. The most significant new features we’ve got for you this time are security enhancements: Feature Policy, the Cross-Origin-Resource-Policy header, and removal of TLS 1.0/1.1 support. We’ve also got some new CSS text property features, the JS optional chaining operator, and additional 2D canvas text metric features, along with the usual wealth of DevTools enhancements and bug fixes.
As always, read on for the highlights, or find the full list of additions in the following articles:
Security enhancements
Let’s look at the security enhancement we’ve got in 74.
Feature Policy
We’ve finally enabled Feature Policy by default. You can now use the allow attribute and the Feature-Policy HTTP header to set feature permissions for your top level documents and IFrames. Syntax examples follow:
Feature-Policy: microphone 'none'; geolocation 'none'CORP
We’ve also enabled support for the Cross-Origin-Resource-Policy (CORP) header, which allows web sites and applications to opt in to protection against certain cross-origin requests (such as those coming from
https://hacks.mozilla.org/2020/03/security-means-more-with-firefox-74-2/
Today marks the release of Firefox 74 and as we announced last fall, developers will no longer be able to install extensions without the user taking an action. This installation method was typically done through application installers, and is commonly referred to as “sideloading.”
If you are the developer of an extension that installs itself via sideloading, please make sure that your users can install the extension from your own website or from addons.mozilla.org (AMO).
We heard several questions about how the end of sideloading support affects users and developers, so we wanted to clarify what to expect from this change:
- Starting with Firefox 74, users will need to take explicit action to install the extensions they want, and will be able to remove previously sideloaded extensions when they want to.
- Previously installed sideloaded extensions will not be uninstalled for users when they update to Firefox 74. If a user no longer wants an extension that was sideloaded, they must uninstall the extension themselves.
- Firefox will prevent new extensions from being sideloaded.
- Developers will be able to push updates to extensions that had previously been sideloaded. (If you are the developer of a sideloaded extension and you are now distributing your extension through your website or AMO, please note that you will need to update both the sideloaded .xpi and the distributed .xpi; updating one will not update the other.)
Enterprise administrators and people who distribute their own builds of Firefox (such as some Linux and Selenium distributions) will be able to continue to deploy extensions to users. Enterprise administrators can do this via policies. Additionally, Firefox Extended Support Release (ESR) will continue to support sideloading as an extension installation method.
We will continue to support self-distributed extensions. This means that developers aren’t required to list their extensions on AMO and users can install extensions from sites other than AMO. Developers just won’t be able to install extensions without the user taking an action. Users will also continue being able to manually install extensions.
We hope this helps clear up any confusion from our last post. If you’re a user who has had difficulty uninstalling sideloaded extensions in the past, we hope that you will find it much easier to remove unwanted extensions with this update.
The post Support for extension sideloading has ended appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2020/03/10/support-for-extension-sideloading-has-ended/
Greetings fellow Rustaceans!
The 2020 RustConf Call for Proposals is now open!
Got something to share about Rust? Want to talk about the experience of learning and using Rust? Want to dive deep into an aspect of the language? Got something different in mind? We want to hear from you! The RustConf 2020 CFP site is now up and accepting proposals.
If you may be interested in speaking but aren't quite ready to submit a proposal yet, we are here to help you. We will be holding speaker office hours regularly throughout the proposal process, after the proposal process, and up to RustConf itself on August 20 and 21, 2020. We are available to brainstorm ideas for proposals, talk through proposals, and provide support throughout the entire speaking journey. We need a variety of perspectives, interests, and experience levels for RustConf to be the best that it can be - if you have questions or want to talk through things please don't hesitate to reach out to us! Watch this blog for more details on speaker office hours - they will be posted very soon.
The RustConf CFP will be open through Monday, April 5th, 2020, hope to see your proposal soon!
Previous command line options of the week.
This option is called -Q in its short form, --quote in its long form. It has existed for as long as curl has existed.
Quote?
The name for this option originates from the traditional unix command ‘ftp’, as it typically has a command called exactly this: quote. The quote command for the ftp client is a way to send an exact command, as written, to the server. Very similar to what --quote does.
FTP, FTPS and SFTP
This option was originally made for supported only for FTP transfers but when we added support for FTPS, it worked there too automatically.
When we subsequently added SFTP support, even such users occasionally have a need for this style of extra commands so we made curl support it there too. Although for SFTP we had to do it slightly differently as SFTP as a protocol can’t actually send commands verbatim to the server as we can with FTP(S). I’ll elaborate a bit more below.
Sending FTP commands
The FTP protocol is a command/response protocol for which curl needs to send a series of commands to the server in order to get the transfer done. Commands that log in, changes working directories, sets the correct transfer mode etc.
Asking curl to access a specific ftp:// URL more or less converts into a command sequence.
The --quote option provides several different ways to insert custom FTP commands into the series of commands curl will issue. If you just specify a command to the option, it will be sent to the server before the transfer takes places – even before it changes working directory.
If you prefix the command with a minus (-), the command will instead be send after a successful transfer.
If you prefix the command with a plus (+), the command will run immediately before the transfer after curl changed working directory.
As a second (!) prefix you can also opt to insert an asterisk (*) which then tells curl that it should continue even if this command would cause an error to get returned from the server.
The actually specified command is a string the user specifies and it needs to be a correct FTP command because curl won’t even try to interpret it but will just send it as-is to the server.
FTP examples
For example, remove a file from the server after it has been successfully downloaded:
curl -O ftp://ftp.example/file -Q '-DELE file'
Issue a NOOP command after having logged in:
curl -O ftp://user:password@ftp.example/file -Q 'NOOP'
Rename a file remotely after a successful upload:
curl -T infile ftp://upload.example/dir/ -Q "-RNFR infile" -Q "-RNTO newname"
Sending SFTP commands
Despite sounding similar, SFTP is a very different protocol than FTP(S). With SFTP the access is much more low level than FTP and there’s not really a concept of command and response. Still, we’ve created a set of command for the --quote option for SFTP that lets the users sort of pretend that it works the same way.
Since there is no sending of the quote commands verbatim in the SFTP case, like curl does for FTP, the commands must instead be supported by curl and get translated into their underlying SFTP binary protocol bits.
In order to support most of the basic use cases people have reportedly used with curl and FTP over the years, curl supports the following commands for SFTP: chgrp, chmod, chown, ln, mkdir, pwd, rename, rm, rmdir and symlink.
The minus and asterisk prefixes as described above work for SFTP too (but not the plus prefix).
Example, delete a file after a successful download over SFTP:
curl -O sftp://example/file -Q '-rm file'
Rename a file on the target server after a successful upload:
curl -T infile sftp://example/dir/ -Q "-rename infile newname"
SSH backends
The SSH support in curl is powered by a third party SSH library. When you build curl, there are three different libraries to select from and they will have a slightly varying degree of support. The libssh2 and libssh backends are pretty much feature complete and have been around for a while, where as the wolfSSH backend is more bare bones with less features supported but at much
If you are reading this, you probably know already that you are supposed to use two-factor authentication for your most important accounts. This way you make sure that nobody can take over your account merely by guessing or stealing your password, which makes an account takeover far less likely. And what could be more important than your email account that everything else ties into? So you probably know, when Yahoo! greets you like this on login – it’s only for your own safety:
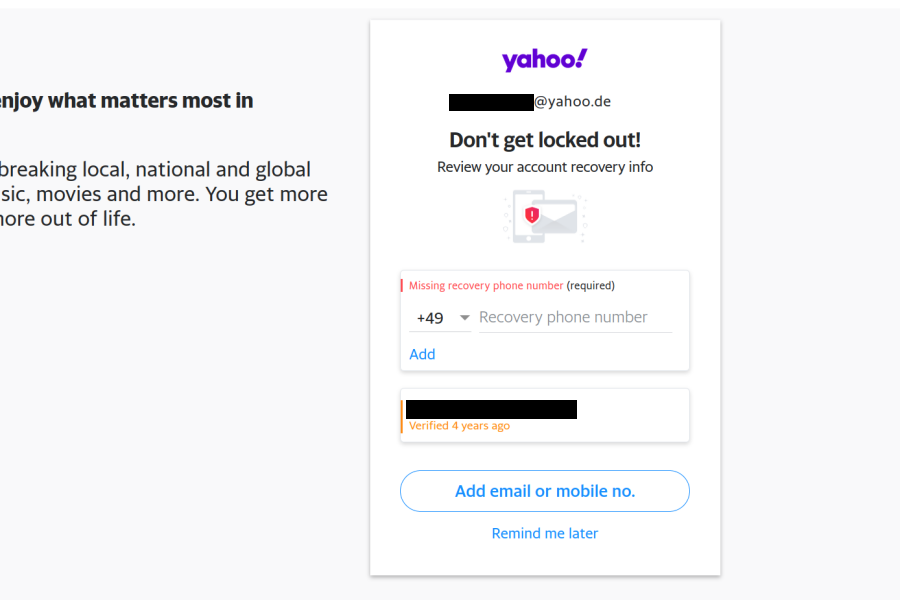
Yahoo! makes sure that “Remind me later” link is small and doesn’t look like an action, so it would seem that adding a phone number is the only way out here. And why would anybody oppose adding it anyway? But here is the thing: complying reduces the security of your account considerably. This is due to the way Verizon Media (the company which acquired Yahoo! and AOL a while ago) implements account recovery. And: yes, everything I say about Yahoo! also applies to AOL accounts.
Summary of the findings
I’m not the one who discovered the issue. A Yahoo! user wrote me:
I entered my phone number to the Yahoo! login, and it asked me if I wanted to receive a verification key/access key (2fa authentication). So I did that, and typed in the access key… Surprise, I logged in ACCIDENTALLY to the Yahoo! mail of the previous owner of my current phone number!!!
I’m not even the first one to write about this issue. For example, Brian Krebs mentioned this a year ago. Yet here we still are: anybody can take over a Yahoo! or AOL account as long as they control the recovery phone number associated with it.
So if you’ve got a new phone number recently, you could check whether its previous owner has a Yahoo! or AOL account. Nothing will stop you from taking over that account. And not just that: adding a recovery phone number doesn’t necessarily require verification! So when I tested it out, I was offered access to a Yahoo! account which was associated with my phone number even though the account owner almost certainly never proved owning this number. No, I did not log into their account…
How two-factor authentication is supposed to work
The idea behind two-factor authentication is making account takeover more complicated. Instead of logging in with merely a password (something you know), you also have to demonstrate access to a device like your phone (something you have). There is a number of ways how malicious actors could learn your password, e.g. if you are in the habit of reusing passwords; chances are that your password has been compromised in one of the numerous data breaches. So it’s a good idea to set the bar for account access higher.
The already mentioned article by Brian Krebs explains why phone numbers aren’t considered a good second factor. Not only do phone numbers change hands quite often, criminals have been hijacking them en masse via SIM swapping attacks. Still, despite sending SMS messages to a phone number being considered a weak authentication scheme, it provides some value when used in addition to querying the password.
The Yahoo! and AOL account recovery process
But that’s not how it works with Yahoo! and
Our HOPL paper is done—all 190 pages of it. The preprint will be posted this week. In the meantime, here’s a little teaser.
JavaScript: The First 20 Years
By Allen Wirfs-Brock and Brendan Eich
Introduction
In 2020, the World Wide Web is ubiquitous with over a billion websites accessible from billions of Web-connected devices. Each of those devices runs a Web browser or similar program which is able to process and display pages from those sites. The majority of those pages embed or load source code written in the JavaScript programming language. In 2020, JavaScript is arguably the world’s most broadly deployed programming language. According to a Stack Overflow [2018] survey it is used by 71.5% of professional developers making it the world’s most widely used programming language.
This paper primarily tells the story of the creation, design, and evolution of the JavaScript language over the period of 1995–2015. But the story is not only about the technical details of the language. It is also the story of how people and organizations competed and collaborated to shape the JavaScript language which dominates the Web of 2020.
This is a long and complicated story. To make it more approachable, this paper is divided into four major parts—each of which covers a major phase of JavaScript’s development and evolution. Between each of the parts there is a short interlude that provides context on how software developers were reacting to and using JavaScript.
In 1995, the Web and Web browsers were new technologies bursting onto the world, and Netscape Communications Corporation was leading Web browser development. JavaScript was initially designed and implemented in May 1995 at Netscape by Brendan Eich, one of the authors of this paper. It was intended to be a simple, easy to use, dynamic language that enabled snippets of code to be included in the definitions of Web pages. The code snippets were interpreted by a browser as it rendered the page, enabling the page to dynamically customize its presentation and respond to user interactions.
Part 1, The Origins of JavaScript, is about the creation and early evolution of JavaScript. It examines the motivations and trade-offs that went into the development of the first version of the JavaScript language at Netscape. Because of its name, JavaScript is often confused with the Java programming language. Part 1 explains the process of naming the language, the envisioned relationship between the two languages, and what happened instead. It includes an overview of the original features of the language and the design decisions that motivated them. Part 1 also traces the early evolution of the language through its first few years at Netscape and other companies.
A cornerstone of the Web is that it is based upon non-proprietary open technologies. Anybody should be able to create a Web page that can be hosted by a variety of Web servers from different vendors and accessed by a variety of browsers. A common specification facilitates interoperability among independent implementations. From its earliest days it was understood that JavaScript would need some form of standard specification. Within its first year Web developers were encountering interoperability issues between Netscape’s JavaScript and Microsoft’s reverse-engineered implementation. In 1996, the standardization process for JavaScript was begun under the auspices of the Ecma International standards organization. The first official standard specification for the language was issued in 1997 under the name “ECMAScript”
Two additional revised and enhanced editions, largely based upon Netscape’s evolution of the language, were issued by the end of 1999.
Part 2, Creating a Standard, examines how the JavaScript standardization effort was initiated, how the specifications were created, who contributed to the effort, and how decisions were made.
By the year 2000, JavaScript was widely used on the Web but Netscape was in rapid decline and Eich had moved on to other projects. Who would lead the evolution of JavaScript into the future? In the absence of either a corporate or
individual “Benevolent Dictator for Life,” the responsibility for evolving JavaScript fell upon the ECMAScript standards committee. This transfer of design responsibility did not go smoothly. There was a decade-long period of false starts, standardization hiatuses, and misdirected efforts as the ECMAScript committee tried to find its own path forward evolving the language. All the while, actual usage of JavaScript rapidly grew, often using implementation-specific extensions. This created a huge legacy of
Being online can be an overwhelming experience especially when it comes to misinformation, toxicity and inequality. Many of us have the option to disconnect and retreat from it all when … Read more
The post Meet the women who man social media brand accounts appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/women-who-man-social-media-accounts/
TenFourFox Feature Parity Release 20 final is now available for testing (downloads, hashes, release notes). This version is the same as the beta except for one more tweak to fix the preferences for those who prefer to suppress Reader mode. Assuming no issues, it will go live Monday evening Pacific as usual.
I have some ideas for FPR21, including further updates to Reader mode, AltiVec acceleration for GCM (improving TLS throughput) and backporting later improvements to 0RTT, but because of a higher than usual workload it is possible development may be stalled and the next release will simply be an SPR. More on that once I get a better idea of the timeframes necessary.
http://tenfourfox.blogspot.com/2020/03/tenfourfox-fpr20-available.html
The problem
Google's "Manifest V3" ongoing API changes are severely hampering browser extensions in their ability to block unwanted content and to enforce additional security policies, threatening the usefulness, if not to the very existence, of many popular privacy and security tools. uBlock's developer made clear that this will cause him to cease supporting Chromium-based browsers. Also EFF (which develops extensions such as HTTPS Everywhere and Privacy Badger) publicly stigmatized Google's decisions, questioning both their consequences and their motivations.
NoScript is gravely affected too, although its position is not as dire as others': in facts, I've finished porting it to Chromium-based browsers in the beginning of 2019, when Manifest V3 had already been announced. Therefore, in the late stages of that project and beyond, I've spent considerable time researching and experimenting alternate techniques, mostly based on standardized Web Platform APIs and thus unaffected by Manifest V3, allowing to implement comparable NoScript functionality albeit at the price of added complexity and/or performance costs. Furthermore Mozilla developers stated that, even though staying as much compatible as possible with the Chome extensions API is a goal of theirs, they do not plan to follow Google in those choices which are more disruptive for content blockers (such as the deprecation of blocking webRequest).
While this means that the future of NoScript is relatively safe, on Firefox and the Tor Browser at least, the browser extensions APIs and capabilities are going to diverge even more: developing and maintaining a cross-browser extension, especially if privacy and/or security focused, will become a complexity nightmare, and sometimes an impossible puzzle: unsurprisingly, many developers are ready to throw in the towel.
What would I do?

The collection of alternate content interception/blocking/filtering techniques I've experimented with and I'm still researching in order to overcome the severe limitations imposed by Manifest V3, in their current form are best defined as "a bunch of hacks": they're hardly maintainable, and even less so reusable by the many projects which are facing similar hurdles. What I'd like to do is to refine, restructure and organize them into an open source NoScript Commons Library. It will provide an abstraction layer on top of common functionality needed to implement in-browser security and privacy software tools.
The primary client of the library will be obviously NoScript itself, refactored to decouple its core high-level features from their browser-dependent low-level implementation details, becoming easier to isolate and manage. But this library will also be freely available (under the General Public License) in a public code repository which any developer can reuse as it is or improve/fork/customize according to their needs, and hopefully contribute back to.
What do I hope?
Some of the desired outcomes:
- By refactoring its browser-dependent "hacks" into a Commons Library, NoScript manages to keep its recently achieved cross-browser compatibility while minimizing the cross-browser maintenance burden and the functionality loss coming from Manifest V3, and mitigating the risk of bugs, regressions and security flaws caused by platform-specific behaviors and unmanageable divergent code paths.
- Other browser extensions in the same privacy/security space as NoScript are offered similar advantages by a toolbox of cross-browser APIs and reusable code, specific to their application domain. This can also motivate their developers (among the most competent people in this field) to scrutinize, review and improve this code, leading to a less buggy, safer and overall healthier privacy and security browser extensions ecosystem.
- Clearly documenting and benchmarking the unavoidable differences between browser-specific implementations help users make informed choices based on realistic expectations, and pressure browser vendors into providing better support (either natively
I don’t spend a lot of time in here patting myself on the back, but today you can indulge me.
In the last few weeks it was a ghost town, and that felt like a victory. From a few days after we’d switched it on to Monday, I could count the number of human users on any of our major channels on one hand. By the end, apart from one last hurrah the hour before shutdown, there was nobody there but bots talking to other bots. Everyone – the company, the community, everyone – had already voted with their feet.
About three weeks ago, after spending most of a month shaking out some bugs and getting comfortable in our new space we turned on federation, connecting Mozilla to the rest of the Matrix ecosystem. Last Monday we decommissioned IRC.Mozilla.org for good, closing the book on a 22-year-long chapter of Mozilla’s history as we started a new one in our new home on Matrix.
I was given this job early last year but the post that earned it, I’m guessing, was from late 2018:
I’ve mentioned before that I think it’s a mistake to think of federation as a feature of distributed systems, rather than as consequence of computational scarcity. But more importantly, I believe that federated infrastructure – that is, a focus on distributed and resilient services – is a poor substitute for an accountable infrastructure that prioritizes a distributed and healthy community. […] That’s the other part of federated systems we don’t talk about much – how much the burden of safety shifts to the individual.
Some inside baseball here, but if you’re wondering: that’s why I pushed back on the idea of federation from the beginning, for all invective that earned me. That’s why I refused to include it as a requirement and held the line on that for the entire process. The fact that on classically-federated systems distributed access and non-accountable administration means that the burden of personal safety falls entirely on the individual. That’s not a unique artifact of federated systems, of course – Slack doesn’t think you should be permitted to protect yourself either, and they’re happy to wave vaguely in the direction of some hypothetical HR department and pretend that keeps their hands clean, as just one example of many – but it’s structurally true of old-school federated systems of all stripes. And bluntly, I refuse to let us end up in a place where asking somebody to participate in the Mozilla project is no different from asking them to walk home at night alone.
And yet here we are, opting into the Fediverse. It’s not because I’ve changed my mind.
One of the strongest selling points of Matrix is the combination of powerful moderation and safety tooling that hosting organizations can operate with robust tools for personal self-defense available in parallel. Critically, these aren’t half-assed tools that have been grafted on as an afterthought; they’re first-class features, robust enough that we can not only deploy them with confidence, but can reasonably be held accountable by our colleagues and community for their use. In short, we can now have safe, accountable infrastructure that complements, rather than comes at the cost, of individual user agency.
That’s not the best thing, though, and I’m here to tell you about my favorite Matrix feature that nobody knows about: Federated auto-updating blocklist sharing.
If you decide you trust somebody else’s decisions, at some other organization – their judgment calls about who is and is not welcome there – those decisions can be immediately and automatically reflected in your own. When a site you trust drops the hammer on some bad actor that ban can be adopted almost immediately by your site and your community as well. You don’t have to have ever seen that person or have whatever got them banned hit you in the eyes. You don’t even need to know they exist. All you need to do is decide you trust that other site judgment and magically someone persona non grata on their site is precisely that grata on yours.
Another way to say that is: among people or communities who trust each other in these decisions, an act of self-defense becomes, seamlessly and invisibly, an act of collective defense. No more everyone needing to fight their own fights alone forever, no more getting isolated and picked off one at a time, weakest first; shields-up means shields-up for everyone. Effective,
Over the past few months, we’ve raised concerns about the Internet Society’s plan to sell the non-profit Public Interest Registry (PIR) to Ethos Capital. Given the important role of dot org in providing a platform for free and open speech for non-profits around the world, we believe this deal deserves close scrutiny.
In our last post on this issue, we urged ICANN to take a closer look at the dot org sale. And we called on Ethos and the Internet Society to move beyond promises of accountability by posting a clear stewardship charter for public comment. As we said in our last post:
One can imagine a charter that provides the council with broad scope, meaningful independence, and practical authority to ensure PIR continues to serve the public benefit. One that guarantees Ethos and PIR will keep their promises regarding price increases, and steer any additional revenue from higher prices back into the dot org ecosystem. One that enshrines quality service and strong rights safeguards for all dot orgs. And one that helps ensure these protections are durable, accounting for the possibility of a future resale.
On February 21, Ethos and ISOC posted two proposals that address many concerns Mozilla and others have raised. The proposals include: 1. a charter for a stewardship council, including sections on free expression and personal data; and 2. an amendment to the contract between PIR and ICANN (aka a Public Interest Commitment), touching on price increases and the durability of the stewardship council. Ethos and ISOC also announced a public engagement process to gather input on these proposals.
These new proposals get a number of things right, but they also leave us with some open questions.
What do they get right? First, the proposed charter gives the stewardship council the veto power over any changes that PIR might want to make to the freedom of expression and personal data rules governing dot org domains. These are two of the most critical issues that we’d urged Ethos and ISOC to get specific about. Second, the proposed Public Interest Commitment provides ICANN with forward-looking oversight over dot org. It also codifies both the existence of the stewardship council and a price cap for dot org domains. We’d suggested a modification to the contract between PIR and ICANN in one of our posts. It was encouraging to see this suggestion taken on board.
Yet questions remain about whether the proposals will truly provide the level of accountability the dot org community deserves.
The biggest question: with PIR having the right to make the initial appointments and to veto future members, will the stewardship council really be independent? The fact that the council alone can nominate future members provides some level of independence, but that independence could be compromised by the fact that PIR will make all the initial nominations and board appointment veto authority. While it makes sense for PIR to have a significant role, the veto power should be cabined in some way. For example, the charter might call for the stewardship council to propose a larger slate of candidates and give the PIR board optional veto, down the number of positions to fill, should it so choose. And, to address the first challenge, maybe a long standing and trusted international non profit could nominate the initial council instead of PIR?
There is also a question about whether the council will have enough power to truly provide oversight of dot org freedom of expression and personal data policies. The charter requires that council vetoes of PIR freedom of expression and data policy changes require a supermajority — five out of seven members. Why not make it a simple majority?
There are a number of online meetings happening over the next week during ICANN 67, including a meeting of the
With the release of Firefox 74, we are pleased to welcome the 29 developers who contributed their first code change to Firefox in this release, 27 of whom were brand new volunteers! Please join us in thanking each of these diligent and enthusiastic individuals, and take a look at their contributions:
- jpmohr: 1599731
- louiscontant: 1598447
- mforney: 1157850, 1611536, 1611565, 1612025
- sanchit.arora.2002: 1602048, 1605876
- tds803: 1613257
- Arno Renevier: 1608911
- Arnout Engelen: 1612667
- Ashu Ghildiyal: 1613858
- Asumu Takikawa: 1608772
- Brandon Kraft: 1609807
- Chris Henry: 1604970
- Elad Zelingher: 1566755
- Jon Bauman: 1611431, 1614097
- Khushal Sahni: 1604143
- Kousuke Takaki: 1542975, 1602088, 1613094
- Mahak: 1208906, 1603100
- Martin McNickle: 1349658, 1593772, 1611043, 1611044, 1611829
- Michael Wilson: 1605874
- Nicol`o Ribaudo: 1607050
- Nikolai Lopin: 1484256
- Pranav pandey: 1517969, 1593607, 1604115
- Richard Matheson: 1102584
- Rob: 1604066, 1605263, 1608183
- Sakura Mochizuki: 1611040
- Samarjeet: 1612956
- Sawyer Bergeron: 1605755
- Stefan Hindli: 1611264
- Thomas Dolezal:
(late publishing on March 6, 2020)
Diagnosis
last Friday, Monday and Tuesday have led some interesting new issues.
- youtube users on firefox could not see a 3d navigation widget, it came out that Firefox had a bug about the default value of ATTACHED_SHADERS in WebGL and it is now fixed. Very quick turnaround and good success story for webcompat.
- stacking contexts in between firefox, chrome, edge (pre-chromium) and safari have different behaviors. Daniel opened an issue about the stacking contexts differences.
- some of the issues are harder to test. For example, everything related to instagram and facebook, if you do not have a personal active account will be canned at a point. Testing accounts shared in between people of different countries are quickly killed.
- probably a race issue.
- weird junky animation with webgl on canvas
- svg animations defined in
defsare not working the same in chrome, safari and firefox. - downloading files on fenix is still not a good story.
- location being requested all the time, this is a dupe
- we are still seing sites with ill-defined user agent sniffing both client side and server side.
- sometimes tracking protection breaks stuff.
pytest
A couple of months ago i had a discussion about unittests and nosetests with friends. On webcompat.com we are using nose (nosetests) to run the tests. My friends encouraged me to switch to pytest. I didn't have yet the motivation to do it. But last week, I started to look at it. And I finally landed this week the pull request for switching to pytest. I didn't convert all tests. This will be done little by little when touching the specific tests. The tests are running as-is, so there's not much benefits to change them at this point.
Hello modernity.
Otsukare!