Firefox Profiler for performance analysis
Harald’s Introduction
Firefox Profiler became a cornerstone of Firefox’s performance work in the days of Project Quantum. When you open up an example recording, you first see a powerful web-based performance analysis interface featuring call trees, stack charts, flame graphs, and more. All data filtering, zooming, slicing, transformation actions are preserved in a sharable URL. You can share it in a bug, document your findings, compare it side-by-side with other recordings, or hand it over for further investigation. Firefox DevEdition has a sneak peek of a built-in profiling flow that makes recording and sharing frictionless. Our goal is to empower all developers to collaborate on performance – even beyond Firefox.
Early on, the Firefox Profiler could import other formats, starting with Linux perf and Chrome’s profiles. More formats were added over time by individual developers. Today, the first projects are emerging that adopt Firefox for analysis tools. FunctionTrace is one of these, and here is Matt to tell the story of how he built it.
Meet FunctionTrace, a profiler for Python code
Matt’s Project
I recently built a tool to help developers better understand what their Python code is doing. FunctionTrace is a non-sampled profiler for Python that runs on unmodified Python applications with very low (<5%) overhead. Importantly, it’s integrated with the Firefox Profiler. This allows you to graphically interact with profiles, making it easier to spot patterns and make improvements to your codebase.
In this post, I’ll discuss why we built FunctionTrace, and share some technical details of its implementation. I’ll show how tools like this can target the Firefox Profiler as a powerful open-source visualization tool. To follow along, you can also play with a small demo of it!

An example of a FunctionTrace profile opened in the Firefox Profiler.
Technical debt as motivation
Codebases tend to grow larger over time, especially when working on complex projects with many people. Some languages have great support for dealing with this, such as Java with its IDE capabilities built up over decades, or Rust with its strong type system that makes refactoring a breeze. Codebases in other languages sometimes seem to become increasingly less maintainable as they grow. This is particularly true in older Python codebases (at least we’re all on Python 3 now, right?).
It can be extremely difficult to make broad changes or refactor pieces of code you’re not familiar with. In contrast, I have a much easier time making correct changes when I’m able to see what a program is doing and all its interactions. Often, I even find myself making improvements to pieces of the code that I’d never intended to touch, as inefficiencies become glaringly obvious when presented on my screen.
I wanted to be able to understand what the Python codebases I work in were doing without needing to read through hundreds of files. I was unable to find existing tools for Python that were satisfactory, and I mostly lost interest in building a tool myself due the amount of UI work that would be necessary. However, when I stumbled across the Firefox Profiler, my hopes of quickly understanding a program’s execution were reignited.
The Profiler provided all of the “hard” pieces – an intuitive open-source UI that could display stack charts, time-correlated log markers, a flame graph, and the stability that comes from being tied to a major web browser. Any tool able to emit a properly-formatted JSON profile would be able to reuse all of the previously mentioned graphical
Who knows, maybe May 18 2020 will mark some sort of historic change when we look back on this day in the future.
On this day, the curl project received the first “AI-powered” submitted issues and pull-requests. They were submitted by MonocleAI, which is described as:
MonocleAI, an AI bug detection and fixing platform where we use AI & ML techniques to learn from previous vulnerabilities to discover and fix future software defects before they cause software failures.
I’m sure these are still early days and we can’t expect this to be perfected yet, but I would still claim that from the submissions we’ve seen so far that this is useful stuff! After I tweeted about this “event”, several people expressed interest in how well the service performs, so let me elaborate on what we’ve learned already in this early phase. I hope I can back in the future with updates.
Disclaimers: I’ve been invited to try this service out as an early (beta?) user. No one is saying that this is complete or that it replaces humans. I have no affiliation with the makers of this service other than as a receiver of their submissions to the project I manage. Also: since this service is run by others, I can’t actually tell how much machine vs humans this actually is or how much human “assistance” the AI required to perform these actions.
I’m looking forward to see if we get more contributions from this AI other than this first batch that we already dealt with, and if so, will the AI get better over time? Will it look at how we adjusted its suggested changes? We know humans adapt like that.
Pull-request quality
Monocle still needs to work on adapting its produced code to follow the existing code style when it submits a PR, as a human would. For example, in curl we always write the assignment that initializes a variable to something at declaration time immediately on the same line as the declaration. Like this:
int name = 0;
… while Monocle, when fixing cases where it thinks there was an assignment missing, adds it in a line below, like this:
int name;
name = 0;
I can only presume that in some projects that will be the preferred style. In curl it is not.
White space
Other things that maybe shouldn’t be that hard for an AI to adapt to, as you’d imagine an AI should be able to figure out, is other code style issues such as where to use white space and where not no. For example, in the curl project we write pointers like char * or void *. That is with the type, a space and then an asterisk. Our code style script will yell if you do this wrong. Monocle did it wrong and used it without space: void*.
C89
We use and stick to the most conservative ANSI C version in curl. C89/C90 (and we have CI jobs failing if we deviate from this). In this version of C you cannot mix variable declarations and code. Yet Monocle did this in one of its PRs. It figured out an assignment was missing and added the assignment in a new line immediately below, which of course is wrong if there are more variables declared below!
int missing; missing = 0; /* this is not C89 friendly */ int fine = 0;
NULL
We use the symbol NULL in curl when we zero a pointer . Monocle for some reason decided it should use (void*)0 instead. Also seems like something virtually no human would do, and especially not after having taken a look at our code…
The first issues
MonocleAI found a few issues in curl without filing PRs for them, and they were basically all of the same kind of inconsistency.
It found function calls for which the return code wasn’t checked, while it was checked in some other places. With the obvious and rightful thinking that if it was worth checking at one place it should be worth checking at other places too.
Those kind of “suspicious” code are also likely much harder fix automatically as it will include decisions on what the correct action should actually be when checks are added, or perhaps the checks aren’t necessary…
Credits
--range or -r for short. As the name implies, this option is for doing “range requests”. This flag was available already in the first curl release ever: version 4.0. This option requires an extra argument specifying the specific requested range. Read on the learn how!
What exactly is a range request?
Get a part of the remote resource
Maybe you have downloaded only a part of a remote file, or maybe you’re only interested in getting a fraction of a huge remote resource. Those are two situations in which you might want your internet transfer client to ask the server to only transfer parts of the remote resource back to you.
Let’s say you’ve tried to download a 32GB file (let’s call it a huge file) from a slow server on the other side of the world and when you only had 794 bytes left to transfer, the connection broke and the transfer was aborted. The transfer took a very long time and you prefer not to just restart it from the beginning and yet, with many file formats those final 794 bytes are critical and the content cannot be handled without them.
We need those final 794 bytes! Enter range requests.
With range requests, you can tell curl exactly what byte range to ask for from the server. “Give us bytes 12345-12567” or “give us the last 794 bytes”. Like this:
curl --range 12345-12567 https://example.com/
and:
curl --range -794 https://example.com/
This works with curl with several different protocols: HTTP(S), FTP(S) and SFTP. With HTTP(S), you can even be more fancy and ask for multiple ranges in the same request. Maybe you want the three sections of the resource?
curl --range 0-1000,2000-3000,4000-5000 https://example.com/
Let me again emphasize that this multi-range feature only exists for HTTP(S) with curl and not with the other protocols, and the reason is quite simply that HTTP provides this by itself and we haven’t felt motivated enough to implement it for the other protocols.
Not always that easy
The description above is for when everything is fine and easy. But as you know, life is rarely that easy and straight forward as we want it to be and nether is the --range option. Primarily because of this very important detail:
Range support in HTTP is optional.
It means that when curl asks for a particular byte range to be returned, the server might not obey or care and instead it delivers the whole thing anyway. As a client we can detect this refusal, since a range response has a special HTTP response code (206) which won’t be used if the entire thing is sent back – but that’s often of little use if you really want to get the remaining bytes of a larger resource out of which you already have most downloaded since before.
One reason it is optional for HTTP and why many sites and pages in the wild refuse range requests is that those sites and pages generate contend on demand, dynamically. If we ask for a byte range from a static file on disk in the server offering a byte range is easy. But if the document is instead the result of lots of scripts and dynamic content being generated uniquely in the server-side at the time of each request, it isn’t.
HTTP 416 Range Not Satisfiable
If you ask for a range that is outside of what the server can provide, it will respond with a 416 response code. Let’s say for example you download a complete 200 byte resource and then you ask that server for the range 200-202 – you’ll get a 416 back because 200 bytes are index 0-199 so there’s nothing available at byte index 200 and beyond.
HTTP other ranges
--range for HTTP content implies “byte ranges”. There’s this theoretical support for other units of ranges in HTTP but that’s not supported by curl and in fact is not widely used over the Internet. Byte ranges are complicated enough!
Related command line options
curl also offers the --continue-at (-C) option which is a perhaps more user-friendly way to resume transfers without the user having to specify the exact byte range and handle data concatenation etc.
The annual curl user survey is up. If you ever used curl or libcurl during the last year, please consider donating ten minutes of your time and fill in the question on the link below!
https://forms.gle/4L4A2de4WgmJbJkg9
The survey will be up for 14 days. Please share this with your curl-using friends as well and ask them to contribute. This is our only and primary way to find out what users actually do with curl and what you want with it – and don’t want it to do!
The survey is hosted by Google forms. The curl project will not track users and we will not ask who you are (and than some general details to get a picture of curl users in general).
The analysis from the 2019 survey is available.
https://daniel.haxx.se/blog/2020/05/18/help-curl-the-user-survey-2020/
Recently, Mozilla introduced an official blog about all things accessibility. This blog is transitioning to a pure personal journal.
For years, this blog was a mixed bag between information about my official work at Mozilla and my personal views on accessibility. Now that Mozilla has its own accessibility blog, my personal blog at this space will contain less work-related material and more personal views on the broader subject of accessibility. I am also co-authoring the Mozilla accessibility blog, and will continue to inform the community about our work there. But this blog here will no longer receive such updates unless I find something personally noteworthy.
So, if you continue to follow this blog, I promise no duplicated content. If you are interested about what‘s happening at Mozilla, the new official source is linked above, and it also has an RSS feed to follow along.
https://marcozehe.de/2020/05/17/the-focus-of-this-blog-is-changing/
This week (no pun intended), the IndieWeb community’s “This Week in the IndieWeb” turned 6!
First published on 2014-05-12, the newsletter started as a fully-automatically generated weekly summary of activity on the IndieWeb’s community wiki: a list of edited and new pages, followed by the full content of the new pages, and then the recent edit histories of pages changed that week.
Since then the Newsletter has grown to include photos from recent events, the list of upcoming events, recent posts about the IndieWeb syndicated to the IndieNews aggregator, new community members (and their User pages), and a greatly simplified design of new & changed pages.
You can subscribe to the newsletter via email, RSS, or h-feed in your favorite Reader.
This week we also celebrated:
- 6 years of WithKnown
- 5 years of IndieWebCamps in D"usseldorf
See the Timeline page for more significant events in IndieWeb community history.
In the last few months I’ve worked with contributors who wanted to be selected to work on Treeherder during this year’s Google Summer of Code. The initial proposal was to improve various Treeherder developer ergonomics (read: make Treeherder development easier). I’ve had three very active contributors that have helped to make a big difference (in alphabetical order): Shubham, Shubhank and Suyash.
In this post I would like to thank them publicly for all the work they have accomplished as well as list some of what has been accomplished. There’s also listed some work from Kyle who tackled the initial work of allowing normal Python development outside of Docker (more about this later).
After all, I won’t be participating in GSoC due to burn-out and because this project is mostly completed (thanks to our contributors!). Nevertheless, two of the contributors managed to get selected to help with Treeherder (Suyash) and Firefox Accounts (Shubham) for GSoC. Congratulations!
Some of the developer ergonomics improvements that landed this year are:
- Support running Treeherder & tests outside of Docker. Thanks to Kyle we can now set up a Python virtualenv outside of Docker and interact with all dependent services (mysql, redis and rabbitmq). This is incredibly useful to run tests and the backend code outside of Docker and to help your IDE install all Python packages in order to better analyze and integrate with your code (e.g., add breakpoints from your IDE). See PR here.
- Support manual ingestion of data. Before, you could only ingest data when you would set up the Pulse ingestion. This mean that you could only ingest real-time data (and all of it!) and you could not ingest data from the past. Now, you can ingest pushes, tasks and even Github PRs. See documentation.
- Add pre-commit hooks to catch linting issues. Prior to this, linting issues would require you to remember to run a script with all the linters or Travis to let you know. You can now get the linters to execute automatically on modified files (instead of all files in the repo), shortening the linting-feedback cycle. See hooks in pre-commit file
- Use Poetry to generate the docs. Serving locally the Treeherder docs is now as simple as running “poetry install && poetry run mkdocs serve.” No more spinning up Docker containers or creating and activating virtualenvs. We also get to introduce Poetry as a modern dependency and virtualenv manager. See code in pyproject.toml file
- Automatic syntax formatting. The black pre-commit hook now formats files that the developer touches. No need to fix the syntax after Travis fails with linting issues.
- Ability to run the same tests as Travis locally. In order to reduce differences between what Travis tests remotely and what we test locally, we introduced tox. The Travis code simplifies, the tox code can even automate starting the Docker containers and it removed a bash script that was trying to do what tox does (Windows users cannot execute bash scripts).
- Share Pulse credentials with random queue names. In the past we required users to set up an account with Pulse Guardian and generate their own PULSE_URL in order to ingest data. Last year, Dustin gave me the idea that we can share Pulse credentials; however, each consumer must ingest from dynamically generated queue names. This was initially added to support Heroku Review Apps, however, this works as well for local consumers. This means that a developer ingesting data would not be taking away Pulse messages from the queue of another developer.
- Automatically delete Pulse queues. Since we started using shared credentials with random queue names, every time a developer started ingesting data locally it would
Sitting in front of a computer all day (and getting caught up in the never-ending bad news cycle) can be draining. And if you happen to be working from home, … Read more
The post Relaxing video series brings serenity to your day appeared first on The Firefox Frontier.
With all that's going on in the world you'd be forgiven for forgetting that as of today, it has been five years since we released 1.0! Rust has changed a lot these past five years, so we wanted to reflect back on all of our contributors' work since the stabilization of the language.
Rust is a general purpose programming language empowering everyone to build reliable and efficient software. Rust can be built to run anywhere in the stack, whether as the kernel for your operating system or your next web app. It is built entirely by an open and diverse community of individuals, primarily volunteers who generously donate their time and expertise to help make Rust what it is.
Major Changes since 1.0
2015
1.2 — Parallel Codegen: Compile time improvements are a large theme to every release of Rust, and it's hard to imagine that there was a short time where Rust had no parallel code generation at all.
1.3 — The Rustonomicon: Our first release of the fantastic "Rustonomicon", a book that explores Unsafe Rust and its surrounding topics and has become a great resource for anyone looking to learn and understand one of the hardest aspects of the language.
1.4 — Windows MSVC Tier 1 Support: The first tier 1 platform promotion was bringing native support for 64-bit Windows using the Microsoft Visual C++ toolchain (MSVC). Before 1.4 you needed to also have MinGW (a third party GNU environment) installed in order to use and compile your Rust programs. Rust's Windows support is one of the biggest improvements these past five years. Just recently Microsoft announced a public preview of their official Rust support for the WinRT API! Now it's easier than ever build top quality native and cross platform apps.
1.5 — Cargo Install: The addition of being able to build Rust binaries alongside cargo's pre-existing plugin support has given birth to an entire ecosystem of apps, utilities, and developer tools that the community has come to love and depend on. Quite a few of the commands cargo has today were first plugins that the community built and shared on crates.io!
2016
1.6 — Libcore: libcore is a subset of the standard library that only
contains APIs that don't require allocation or operating system level features.
The stabilization of libcore brought the ability to compile Rust with no allocation
or operating system dependency was one of the first major steps towards Rust's
support for embedded systems development.
1.10 — C ABI Dynamic Libraries: The cdylib crate type allows Rust to be
compiled as a C dynamic library, enabling you to embed your Rust projects in
any system that supports the C ABI. Some of Rust's biggest success stories
among users is being able to write a small critical part of their system in
Rust and seamlessly integrate in the larger codebase, and it's now easier
than ever.
1.12 — Cargo Workspaces: Workspaces allow you to organise multiple rust projects and share the same lockfile. Workspaces have been invaluable in building large multi-crate level projects.
1.13 — The Try Operator: The first major syntax addition was the ? or
the "Try" operator. The operator allows you to easily propagate your error
through your call stack. Previously you had to use the try! macro, which
required you to wrap the entire expression each time you encountered a result,
now you can easily chain methods with ? instead.
try!(try!(expression).method()); // Old
expression?.method()?; // New
1.14 — Rustup
A little over a year ago, I wrote the first of many posts arguing: if we want a healthy internet — and a healthy digital society — we need to make sure AI is trustworthy. AI, and the large pools of data that fuel it, are central to how computing works today. If we want apps, social networks, online stores and digital government to serve us as people — and as citizens — we need to make sure the way we build with AI has things like privacy and fairness built in from the get go.
Since writing that post, a number of us at Mozilla — along with literally hundreds of partners and collaborators — have been exploring the questions: What do we really mean by ‘trustworthy AI’? And, what do we want to do about it?
How do we collaboratively make trustworthy AI a reality?
Today, we’re kicking off a request for comment on v0.9 of Mozilla’s Trustworthy AI Whitepaper — and on the accompanying theory of change diagram that outlines the things we think need to happen. While I have fallen out of the habit, I have traditionally included a simple diagram in my blog posts to explain the core concept I’m trying to get at. I would like to come back to that old tradition here:
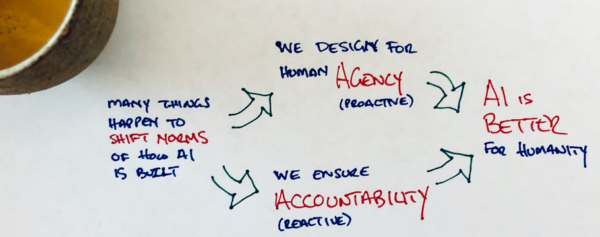
This cartoonish drawing gets to the essence of where we landed in our year of exploration: ‘agency’ and ‘accountability’ are the two things we need to focus on if we want the AI that surrounds us everyday to be more trustworthy. Agency is something that we need to proactively build into the digital products and services we use — we need computing norms and tech building blocks that put agency at the forefront of our design process. Accountability is about having effective ways to react if things go wrong — ways for people to demand better from the digital products and services we use everyday and for governments to enforce rules when things go wrong. Of course, I encourage you to look at the full (and fancy) version of our theory of change diagram — but the fact that ‘agency’ (proactive) and ‘accountability’ (reactive) are the core, mutually reinforcing parts of our trustworthy AI vision is the key thing to understand.
In parallel to developing our theory of change, Mozilla has also been working closely with partners over the past year to show what we mean by trustworthy AI, especially as it relates to consumer internet technology. A significant portion of our 2019 Internet Health Report was dedicated to AI issues. We ran campaigns to: pressure platforms like YouTube to make sure their content recommendations don’t promote misinformation; and call on Facebook and others to open up APIs to make political ad targeting more transparent. We provided consumers with a critical buying guide for AI-centric smart home gadgets like Amazon Alexa. We invested ~$4M in art projects and awarded fellowships to explore AI’s impact on society. And, as the world faced a near universal health crisis, we asked questions about how issues like AI, big data and privacy will play during — and after — the pandemic. As with all of Mozilla’s movement building work, our intention with our trustworthy AI efforts is to bias towards action and working with others.
A request for comments
It’s with this ‘act + collaborate’ bias in mind that we are embarking on a request for comments on v0.9 of the Mozilla Trustworthy AI Whitepaper. The paper talks about how industry, regulators and citizens of the
Distractions tempt us at every turn, from an ever-growing library of Netflix titles to video games (Animal Crossing is my current vice) to all of the other far more tantalizing … Read more
The post How to overcome distractions (and be more productive) appeared first on The Firefox Frontier.
Over the past year, our top priority for Firefox was the Electrolysis project to deliver a multi-process browsing experience to users. Running Firefox in multiple processes greatly improves security and performance. This is the largest change we’ve ever made to Firefox, and we’ll be rolling out the first stage of Electrolysis to 100% of Firefox desktop users over the next few months.
But, that doesn’t mean we’re all out of ideas in terms of how to improve performance and security. In fact, Electrolysis has just set us up to do something we think will be really big.
We’re calling it Project Quantum.
Quantum is our effort to develop Mozilla’s next-generation web engine and start delivering major improvements to users by the end of 2017. If you’re unfamiliar with the concept of a web engine, it’s the core of the browser that runs all the content you receive as you browse the web. Quantum is all about making extensive use of parallelism and fully exploiting modern hardware. Quantum has a number of components, including several adopted from the Servo project.
The resulting engine will power a fast and smooth user experience on both mobile and desktop operating systems — creating a “quantum leap” in performance. What does that mean? We are striving for performance gains from Quantum that will be so noticeable that your entire web experience will feel different. Pages will load faster, and scrolling will be silky smooth. Animations and interactive apps will respond instantly, and be able to handle more intensive content while holding consistent frame rates. And the content most important to you will automatically get the highest priority, focusing processing power where you need it the most.
So how will we achieve all this?
Web browsers first appeared in the era of desktop PCs. Those early computers only had single-core CPUs that could only process commands in a single stream, so they truly could only do one thing at a time. Even today, in most browsers an individual web page runs primarily on a single thread on a single core.
But nowadays we browse the web on phones, tablets, and laptops that have much more sophisticated processors, often with two, four or even more cores. Additionally, it’s now commonplace for devices to incorporate one or more high-performance GPUs that can accelerate rendering and other kinds of computations.
One other big thing that has changed over the past fifteen years is that the web has evolved from a collection of hyperlinked static documents to a constellation of rich, interactive apps. Developers want to build, and consumers expect, experiences with zero latency, rich animations, and real-time interactivity. To make this possible we need a web platform that allows developers to tap into the full power of the underlying device, without having to agonize about the complexities that come with parallelism and specialized hardware.
And so, Project Quantum is about developing a next-generation engine that will meet the demands of tomorrow’s web by taking full advantage of all the processing power in your modern devices. Quantum starts from Gecko, and replaces major engine components that will benefit most from parallelization, or from offloading to the GPU. One key part of our strategy is to incorporate groundbreaking components of Servo, an independent, community-based web engine sponsored by Mozilla. Initially, Quantum will share a couple of components with Servo, but as the projects evolve we will experiment with adopting even more.
A number of the Quantum components are written in Rust. If you’re not familiar with Rust, it’s a systems programming language that runs blazing fast, while simplifying development of parallel programs by guaranteeing thread and memory safety. In most cases, Rust code won’t even compile unless it is safe.
We’re taking on a lot of separate but related initiatives as part of Quantum, and we’re revisiting many old assumptions and implementations. The high-level approach is to rethink many fundamental aspects of how a browser engine works. We’ll be re-engineering foundational building blocks, like how we apply CSS styles, how we execute DOM operations, and how we render graphics to your screen.
Quantum is an ambitious project, but users won’t have to wait long to start seeing improvements roll out. We’re going to ship major improvements next year, and we’ll iterate from there. A first version of our new engine will ship on Android, Windows, Mac, and Linux. Someday we hope to offer this new engine for iOS, too.
We’re confident Quantum will deliver significantly improved performance. If you’re a developer and you’d like to get involved, you can learn more about

With today’s release of Firefox, we are the first browser to support WebAssembly. If you haven’t yet heard of WebAssembly, it’s an emerging standard inspired by our research to enable near-native performance for web applications.
WebAssembly is one of the biggest advances to the Web Platform over the past decade.
This new standard will enable amazing video games and high-performance web apps for things like computer-aided design, video and image editing, and scientific visualization. Over time, many existing productivity apps (e.g. email, social networks, word processing) and JavaScript frameworks will likely use WebAssembly to significantly reduce load times while simultaneously improving performance while running. Unlike other approaches that have required plug-ins to achieve near-native performance in the browser, WebAssembly runs entirely within the Web Platform. This means that developers can integrate WebAssembly libraries for CPU-intensive calculations (e.g. compression, face detection, physics) into existing web apps that use JavaScript for less intensive work.
To get a quick understanding of WebAssembly, and to get an idea of how some companies are looking at using it, check out this video. You’ll hear from engineers at Mozilla, and partners such as Autodesk, Epic, and Unity.
https://medium.com/media/1858e816355bfa288aa7294e39278e67/hrefIt’s been a long, winding, and exciting road getting here.
JavaScript was originally intended as a lightweight language for fairly simple scripts. It needed to be easy for novice developers to code in. You know — for relatively simple things like making sure that you fill out a form correctly when you submit it.
A lot has changed since then. Modern web apps are complex computer programs, with client and server code, much of it written in JavaScript.
But, for all the advances in the JavaScript programming language and the engines that run it (including Mozilla’s SpiderMonkey engine), JavaScript still has inherent limitations that make it a poor fit for some scenarios. Most notably, when a browser actually executes JavaScript it typically can’t run the program as fast as the operating system can run a comparable native program written in other programming languages.
We’ve always been well aware of this at Mozilla but that has never limited our ambitions for the web. So a few years ago we embarked on a research project — to build a true virtual machine in the browser that would be capable of safely running both JavaScript and high-speed languages at near-native speeds. In particular we set a goal to allow modern video games to run in Firefox without plug-ins, knowing the Web Platform would then be able to run nearly any kind of application. Our first major step, after a great deal of experimentation, was to demonstrate that games built upon popular game engines could run in Firefox using an exploratory low-level subset of JavaScript called asm.js.
The asm.js sub-language worked impressively well, and we knew the approach could work even better as a first-class web standard. So, using asm.js as a proof of concept, we set out to collaborate with other browser makers to establish such a standard that could run as part of browsers. Together with expert engineers across browser makers, we established consensus on WebAssembly. We expect support for it will soon start shipping in other browsers.
Web apps written with WebAssembly can run at near-native speeds because, unlike JavaScript, all the code a programmer writes is parsed and compiled ahead of time before reaching the browser. The browser then just sees low-level, machine-ready instructions it can quickly validate, optimize, and run.
In some ways, WebAssembly changes what it means to be a web developer, as well as the fundamental abilities of the web. With WebAssembly and an accompanying set of tools, programs written in languages like C/C++ can be ported to the web so they run with near-native performance. We expect that, as WebAssembly continues to evolve, you’ll also be able to use it with programming languages often used for mobile apps, like Java, Swift, and C#.
If you’re interested in hearing more about the backstory of WebAssembly, check out this behind-the-scenes look.

If you are following the tech news, you might have seen the announcement that ICANN withheld consent for the change of control of the Public Interest Registry and that this had some implications for .org. However, unless you follow a lot of DNS inside baseball, it might not be that clear what all this means. This post is intended to give a high level overview of the background here and what happened with .org. In addition, Mozilla has been actively engaged in the public discussion on this topic; see here for a good starting point.
The Structure and History of Internet Naming
As you’ve probably noticed, Web sites have names like “mozilla.org”, “google.com”, etc. These are called “domain names.” The way this all works is that there are a number of “top-level domains” (.org, .com, .io, …) and then people can get names within those domains (i.e., that end in one of those). Top level domains (TLDs) come in two main flavors:
- Country-code top-level domains (ccTLDs) which represent some country or region like .us (United States), .uk (United Kingdom, etc.)
- Generic top-level domains (gTLDs) which don’t correspond to some country or region, such as .com, .org, etc.
Back at the beginning of the Internet, there were five gTLDs which were intended to roughly reflect the type of entity registering the name:
- .com: for “commercial-related domains”
- .edu: for educational institutions
- .gov: for government entities (really, US government entities)
- .mil: for the US Military (remember, the Internet came out of US government research)
- .org: for organizations (“any other domains”)
It’s important to remember that until the 90s, much of the Internet ran under an Acceptable Use Policy which discouraged/forbid commercial use and so these distinctions were inherently somewhat fuzzy, but nevertheless people had the rough understanding that .org was for non-profits and the like and .com was for companies.
During this period the actual name registrations were handled by a series of government contractors (first SRI and then Network Solutions) but the creation and assignment of the top-level domains was under the control of the Internet Assigned Numbers Authority (IANA), which in practice, mostly meant the decisions of its Director, Jon Postel. However, as the Internet became bigger, this became increasingly untenable especially as IANA was run under a contract to the US government. Through a long and somewhat complicated series of events, in 1998 this responsibility was handed off to the Internet Corporation for Assigned Names and Numbers (ICANN), which administers the overall system, including setting the overall rules and determining which gTLDs will exist (which ccTLDs exist is determined by ISO 3166-1 country codes, as described in RFC 1591). ICANN has created a pile of new gTLDs, such as .dev, .biz, and .wtf (you may be wondering whether the world really needed .wtf, but there it is). As an aside, many of the newer names you see registered are not actually under gTLDs, but rather ccTLDs that happen to correspond to countries lucky enough to have cool sounding country codes. For instance, .io is actually the British Indian Ocean’s TLD and .tv belongs to Tuvalu.
One of the other things that ICANN does is determine who gets to run each TLD. The way this all works is that ICANN determines who gets to be the registry, i.e., who keeps the records of who has which name as well as some of the technical data needed to actually route name lookups. The actual work of
(Previous options of the week)
Today we take a closer look at one of the real vintage curl options. It was added already in early 1999. -Y for short, --speed-limit is the long version. This option needs an additional argument:
Slow or stale transfers
Very early on in curl’s lifetime, it became obvious to us that lots of times when you use curl in order to do an Internet transfer, that transfer could sometimes take a long time. Occasionally even ridiculously long times and it could seem that the transfers just stalled without any hope of resurrecting and completing its mission.
How do you tell curl to abandon such lost-hope transfers? The options we provide for timeouts provide one answer. But since the transfer speeds can vary greatly from time to time and machine to machine, you have to use a timeout value that uses an insane margin, which for the cases when everything flies fast turns out annoying.
We needed another way to detect and abort these stale transfers. Enter speed limit.
Lower than speed-limit bytes per second during speed-time
The --speed-limit you tell curl is the transfer speed threshold below which you think the transfer is untypically slow, specified as bytes per second. If you have a really fast Internet, you might for example think that a transfer that is below 1000 bytes/second is a sign of something not being right.
But just measuring a the transfer speed to be below that special threshold in a single snapshot is not a strong enough signal for curl to act on it. The speed also needs to be measure below that threshold during --limit-time . If the transfer speed just incidentally sometimes and very quickly drops below the threshold (bad wifi?) that’s not a reason for concern. The default limit time (when --limit-speed is used without --limit-time set) is 30. The transfer speed needs to be measured below the threshold for that many consecutive seconds (and it samples once per second).
If curl deems that your transfer speed was too slow during the given period, it will break the transfer and return 28. Timeout.
These two options are entirely protocol independent and work for all transfers using any of the protocols curl supports.
Examples
Tell curl to give up the transfer if slower than 1000 bytes per second during 20 seconds:
curl --speed-limit 1000 --speed-time 20 https://example.com
Tell curl to give up the transfer if slower than 100000 bytes per second during 60 seconds:
curl --speed-limit 100000 --speed-time 60 https://example.com
It also works the same for uploads. If the speed is below 2000 bytes per second during 45 seconds, abort:
curl --speed-limit 2000 --speed-time 45 ftp://example.com/upload/ -T sendaway.txt
Related options
--max-time and --connect-timeout are options with similar functionality and purpose, and you can indeed in many cases add those as well.
https://daniel.haxx.se/blog/2020/05/11/curl-ootw-y-speed-limit/

The HP Color LaserJet CP3525 Printer looks like any other ordinary printer done by HP. But there’s a difference!
A friend of mine fell over this gem, and told me.
TCP/IP Settings
If you go to the machine’s TCP/IP settings using the built-in web server, the printer offers the ordinary network configure options but also one that sticks out a little exta. The “Manual cURL cURL” option! It looks like this:
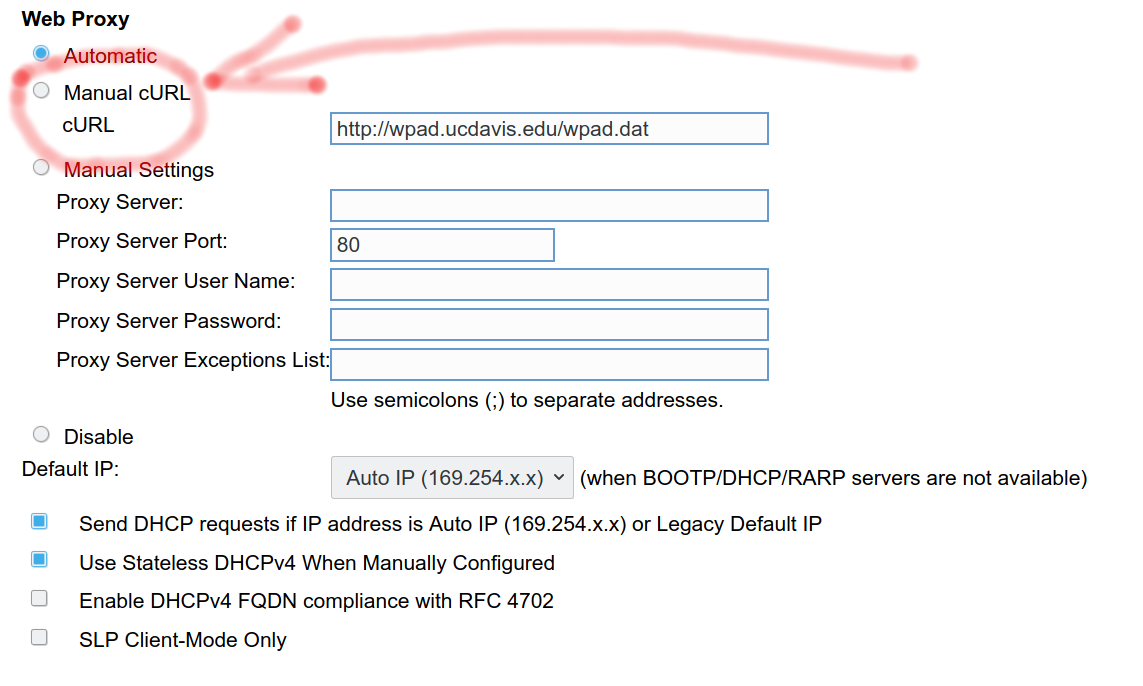
I could easily confirm that this is genuine. I did this screenshot above by just googling for the string and printer model, since there appears to exist printers like this exposing their settings web server to the Internet. Hilarious!
What?
How on earth did that string end up there? Certainly there’s no relation to curl at all except for the actual name used there? Is it a sign that there’s basically no humans left at HP that understand what the individual settings on that screen are actually meant for?
Given the contents in the text field, a URL containing the letters WPAD twice, I can only presume this field is actually meant for Web Proxy Auto-Discovery. I spent some time trying to find the user manual for this printer configuration screen but failed. It would’ve been fun to find “manual cURL cURL” described in a manual! They do offer a busload of various manuals, maybe I just missed the right one.
Does it use curl?
Yes, it seems HP generally use curl at least as I found the “Open-Source Software License Agreements for HP LaserJet and ScanJet Printers” and it contains the curl license:
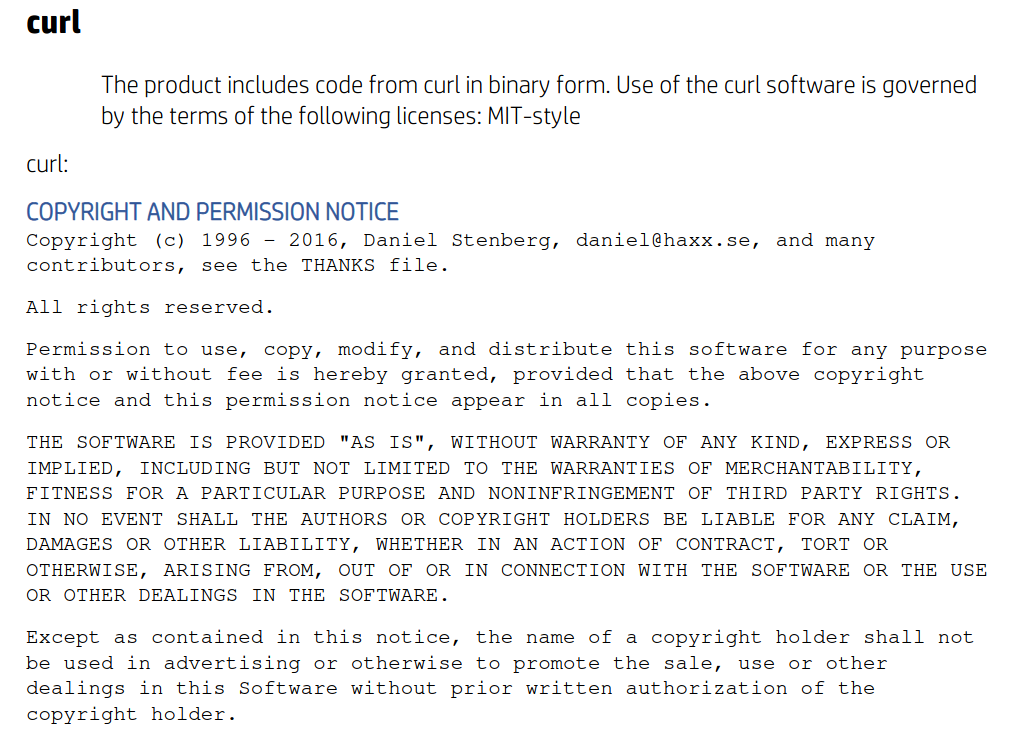
HP using curl for Print-Uri?
Independently, someone else recently told me about another possible HP + curl connection. This user said his HP printer makes HTTP requests using the user-agent libcurl-agent/1.0:

I haven’t managed to get this confirmed by anyone else (although the license snippet above certainly implies they use curl) and that particular user-agent string has been used everywhere for a long time, as I believe it is copied widely from the popular libcurl example getinmemory.c where I made up the user-agent and put it there already in 2004.
Credits
Frank Gevaerts tricked me into going down this rabbit hole as he told me about this string.
At my new job we publish an open source webapp map systems uxing a mix of technologies, we also offer it as SAS. Last Thursday I looked at how our Nginx server was configured TLS wise.
I was thrilled to see the comment in our nginx code saying the configuration had been built using mozilla's ssl config tool. At the same time I was shocked to see that the configuration that dated from early 2018 was completely out of date. Half of the ciphers were gone. So we took a modern config and applied it.
Once done we turned ourselves to the observatory to check out our score, and me and my colleague were disappointed to get an F. So we fixed what we could easily (the cyphers) and added an issue to our product to make it more secure for our users.
We'll also probably add a calendar entry to check our score on a regular basis, as the recommendation will change, our software configuration will change too.
https://www.hirlimann.net/Ludovic/carnet/?post/2020/05/09/Recommendations-are-moving-entities
Mozilla has sent a CA Communication and Survey to inform Certification Authorities (CAs) who have root certificates included in Mozilla’s program about current expectations. Additionally this survey will collect input from CAs on potential changes to Mozilla’s Root Store Policy. This CA communication and survey has been emailed to the Primary Point of Contact (POC) and an email alias for each CA in Mozilla’s program, and they have been asked to respond to the following items:
- Review guidance about actions a CA should take if they realize that mandated restrictions regarding COVID-19 will impact their audits or delay revocation of certificates.
- Inform Mozilla if their CA’s ability to fulfill the commitments that they made in response to the January 2020 CA Communication has been impeded.
- Provide input into potential policy changes that are under consideration, such as limiting maximum lifetimes for TLS certificates and limiting the re-use of domain name verification.
The full communication and survey can be read here. Responses to the survey will be automatically and immediately published by the CCADB.
With this CA Communication, we reiterate that participation in Mozilla’s CA Certificate Program is at our sole discretion, and we will take whatever steps are necessary to keep our users safe. Nevertheless, we believe that the best approach to safeguard that security is to work with CAs as partners, to foster open and frank communication, and to be diligent in looking for ways to improve.
The post May 2020 CA Communication appeared first on Mozilla Security Blog.
https://blog.mozilla.org/security/2020/05/08/may-2020-ca-communication/