Ken Cunningham figured out the build issues he was having with the Intel version and has updated TenFourFox for Intel systems to FPR23, now up to date with the Power Mac version. As always, there is no support for any Intel build of TenFourFox; do not report issues to Tenderapp. You can get it from SourceForge.
Ken's patches have also been incorporated into the tree along with a workaround submitted by Rapha"el Guay to deal with Twitch overflowing our JIT stack. This is probably due to something we don't support causing infinite function call recursion since with the JIT disabled it correctly just runs out of stack and stops. There is no way to increase stack further since we are strictly 32-bit builds and the stack already consumes 1GB of our 2.2-ish GB available, so we need to a) figure out why the stack overflow happens without being detected and b) temporarily disable that script until we do. It's part B that is implemented as a second blacklist which is on unless disabled, since other sites may do this, until we find a better solution to part A. This will be in FPR24 along with probably some work on MP3 compliance issues since TenFourFox gets used as a simple little Internet radio a lot more than I realized, and a few other odds and ends.
In case you missed it, I am now posting content I used to post here as "And now for something completely different" over on a new separate blog christened Old Vintage Computing Research, or my Old VCR (previous posts will remain here indefinitely). Although it will necessarily have Power Mac content, it will also cover some of my other beloved older systems all in one place. Check out properly putting your old Mac to Terminal sleep (and waking it back up again), along with screenshots of the unscreenshotable, including grabs off the biggest computer Apple ever made, the Apple Network Server. REWIND a bit and PLAY.
http://tenfourfox.blogspot.com/2020/06/tenfourfox-fpr23-for-intel-available.html
![]() When the Recommended Extensions program debuted last year, it listed about 60 extensions. Today the program has grown to just over a hundred as we continue to evaluate new nominations and carefully grow the list. The curated collection grows slowly because one of the program’s goals is to cultivate a fairly fixed list of content so users can feel confident the Recommended extensions they install will be monitored for safety and security for the foreseeable future.
When the Recommended Extensions program debuted last year, it listed about 60 extensions. Today the program has grown to just over a hundred as we continue to evaluate new nominations and carefully grow the list. The curated collection grows slowly because one of the program’s goals is to cultivate a fairly fixed list of content so users can feel confident the Recommended extensions they install will be monitored for safety and security for the foreseeable future.
Here are some of the more exciting recent additions to the program…
DuckDuckGo Privacy Essentials provides a slew of great privacy features, like advanced ad tracker and search protection, encryption enforcement, and more.
Read Aloud: Text to Speech converts any web page text (even PDF’s) to audio. This can be a very useful extension for everyone from folks with eyesight or reading issues to someone who just wants their web content narrated to them while their eyes roam elsewhere.
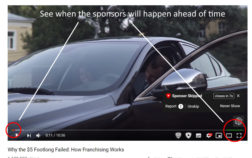
SponsorBlock addresses the nuisance of this newer, more intrusive type of video advertising.
Metastream Remote has been extremely valuable to many of us during pandemic related home confinement. It allows you to host streaming video watch parties with friends. Metastream will work with any video streaming platform, so long as the video has a URL (in the case of paid platforms like Netflix, Hulu, or Disney+, they too will work provided all watch party participants have their own accounts).
Cookie AutoDelete summarizes its utility right in the title. This simple but powerful extension will automatically delete your cookies from closed tabs. Customization features include whitelist support and informative visibility into the number of cookies used on any given site.
AdGuard AdBlocker is a popular and highly respected content blocker that works to block all ads—banner, video, pop-ups, text ads—all of it. You may also notice the nice side benefit of faster page loads, since AdGuard prohibits so much content you didn’t want anyway.
If you’re the creator of an extension you feel would make a strong candidate for the Recommended program, or even if you’re just a huge fan of an extension you think merits consideration, please submit nominations to amo-featured [at] mozilla [dot] org. Due to the high volume of submissions we receive, please understand we’re unable to respond to every inquiry.
The post Recommended extensions — recent additions appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2020/06/11/recommended-extensions-recent-additions/
The MDN Web Docs Learning Area (LA) was first launched in 2015, with the aim of providing a useful counterpart to the regular MDN reference and guide material. MDN had traditionally been aimed at web professionals, but we were getting regular feedback that a lot of our audience found MDN too difficult to understand, and that it lacked coverage of basic topics.
Fast forward 5 years, and the Learning Area material is well-received. It boasts around 3.5–4 million page views per month; a little under 10% of MDN Web Docs’ monthly web traffic.
At this point, the Learning Area does its job pretty well. A lot of people use it to study client-side web technologies, and its loosely-structured, unopinionated, modular nature makes it easy to pick and choose subjects at your own pace. Teachers like it because it is easy to include in their own courses.
However, at the beginning of the year, this area had two shortcomings that we wanted to improve upon:
- We’d gotten significant feedback that our users wanted a more opinionated, structured approach to learning web development.
- We didn’t include any information on client-side tooling, such as JavaScript frameworks, transformation tools, and deployment tools widely used in the web developer’s workplace.
To remedy these issues, we created the Front-end developer learning pathway (FED learning pathway).
Structured learning
Take a look at the Front-end developer pathway linked above — you’ll see that it provides a clear structure for learning front-end web development. This is our opinion on how you should get started if you want to become a front-end developer. For example, you should really learn vanilla HTML, CSS, and JavaScript before jumping into frameworks and other such tooling. Accessibility should be front and center in all you do. (All Learning Area sections try to follow accessibility best practices as much as possible).
While the included content isn’t completely exhaustive, it delivers the essentials you need, along with the confidence to look up other information on your own.
The pathway starts by clearly stating the subjects taught, prerequisite knowledge, and where to get help. After that, we provide some useful background reading on how to set up a minimal coding environment. This will allow you to work through all the examples you’ll encounter. We explain what web standards are and how web technologies work together, as well as how to learn and get help effectively.
The bulk of the pathway is dedicated to detailed guides covering:
- HTML
- CSS
- JavaScript
- Web forms
- Testing and accessibility
- Modern client-side tooling (which includes client-side JavaScript frameworks)
Throughout the pathway we aim to provide clear direction — where you are now, what you are learning next, and why. We offer enough assessments to provide you with a challenge, and an acknowledgement that you are ready to go on to the next section.
Tooling
MDN’s aim is to document native web technologies — those supported in browsers. We don’t tend to document tooling built on top of native web technologies because:
- The creators of that tooling tend to produce their own documentation resources. To repeat such content would be a waste of effort, and confusing for the community.
- Libraries and frameworks tend to change much more often than native web technologies. Keeping the documentation up to date would require a lot of effort. Alas, we don’t have the bandwidth to perform regular large-scale testing and updates.
- MDN is seen as a neutral documentation provider. Documenting tooling is seen by many as a departure from neutrality, especially for tooling created by major players such as Facebook or Google.
Therefore, it came as a surprise to some that we were looking to document such tooling. So why did we do it? Well, the word here is pragmatism. We want to provide the information people need to build sites and apps on the web. Client-side frameworks and other tools are an unmistakable part of that. It would look foolish to leave out that entire part of the ecosystem. So we opted to provide coverage of a subset of tooling “essentials” — enough information to understand the tools, and use them at a basic level. We aim to provide the confidence to look up more advanced information on your own.
New Tools and testing modules
In the Tools and testing Learning Area topic, we’ve provided the following new modules:
We’re revamping the statistics we make available to add-on developers on addons.mozilla.org (AMO).
These stats are aggregated from add-on update logs and don’t include any personally identifiable user data. They give developers information about user adoption, general demographics, and other insights that might help them make changes and improvements.
The current system is costly to run, and glitches in the data have been a long-standing recurring issue. We are addressing these issues by changing the data source, which will improve reliability and reduce processing costs.
Usage Statistics
Until now, add-on usage statistics have been based on add-on updates. Firefox checks AMO daily for updates for add-ons that are hosted there (self-distributed add-ons generally check for updates on a server specified by the developer). The server logs for these update requests are aggregated and used to calculate the user counts shown on add-on pages on AMO. They also power a statistics dashboard for developers that breaks down the usage data by language, platform, application, etc.
Stats dashboard showing new version adoption for uBlock Origin
In a few weeks, we will stop using the daily pings as the data source for usage statistics. The new statistics will be based on Firefox telemetry data. As with the current stats, all data is aggregated and no personally identifiable user data is shared with developers.
The data shown on AMO and shared with developers will be essentially the same, but the move to telemetry means that the numbers will change a little. Firefox users can opt out of sending telemetry data, and the way they are counted is different. Our current stats system counts distinct users by IP address, while telemetry uses a per-profile ID. For most add-ons you should expect usage totals to be lower, but usage trends and fluctuations should be nearly identical.
Telemetry data will enable us to show data for add-on versions that are not listed on AMO, so all developers will now be able to analyze their add-on usage stats, regardless of how the add-on is distributed. This also means some add-ons will have higher usage numbers, since the average will be calculated including both AMO-hosted and self-hosted versions.
Other changes that will happen due to this update:
- The dashboards will only show data for enabled installs. There won’t be a breakdown of usage by add-on status anymore.
- A breakdown of usage by country will be added.
- Usage data for our current Firefox for Android browser (also known as Fennec) isn’t included. We’re working on adding data for our next mobile browser (Fenix), currently in development.
- It won’t be possible to make your statistics dashboard publicly available anymore. Dashboards will only be accessible to add-on developers and admins, starting on June 11. If you are a member of a team that maintains an add-on and you need to access its stats dashboard, please ask your team to add you as an author in the Manage Authors & License page on AMO. The Listed property can be checked off so you don’t show up in the add-on’s public listing page.
We will begin gradually rolling out the new dashboard on June 11. During the rollout, a fraction of add-on dashboards will default to show the new data, but they will also have a link to access the old data. We expect to complete the rollout and discontinue the old dashboards on July 9. If you want to export any of your old stats, make sure you do it before then.
Download Statistics
We plan to make a similar overhaul to download statistics in the coming months. For now they will remain the same. You should expect an announcement around August, when we are closer to switching over to the new download data.
The post Improvements to Statistics Processing on AMO appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2020/06/10/improvements-to-statistics-processing-on-amo/
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
Check out this week's This Week in Rust Podcast
Updates from Rust Community
News & Blog Posts
- Announcing Rust 1.44.0
- RustConf 2020 Registration is Open
- Enumerating monitors in Rust using Win32 API
- Rust cli app integrated with slack
- Hack week: miniCouchDB in Rust
- Zero To Production #1: toolchains, IDEs, CI
- From Rust to Svelte, what tech stack will I use
- Graph & Tree Traversals in Rust
- Programming languages: Rust enters top 20 popularity rankings for the first time
- A Rust SentencePiece implementation
- Rust Things I Miss in C
- So What's Up with Microsoft's (and Everyone Else's) Love of Rust?
- Why the developers who use Rust love it so much
- The Story of Tail Call Optimizations in Rust
- Taking the Unhappy Path with Result, Option, unwrap and ? operator in Rust
- This Month in Rust OSDev (May 2020)
- This Month in Rust GameDev #10 - May 2020
- This month in rustsim #11 (April - May 2020)
- Rust in Blockchain Newsletter #12 - ZK-Rustups
- Memory-Safety Challenge Considered Solved? An Empirical Study with All Rust CVEs
- Creating Your Own Programming Language with Rust
- rust-analyzer changelog #28
- Getting started with Rust/WinRT
- [Chinese] Simple sorting algorithms in Rust
- [Indonesian] Berbagai alasan melakukan Programming dalam Rust
- [slides] Rust in 15 Minutes
- [video]
In 2020 the way we can do events suddenly changed. In the past we had in-person events all around the world, with some major conferences throughout the year. With everything changed due to a global pandemic this won't be possible anymore. Nonetheless the Rust community found ways to continue with events in some form or another. With more and more events moving online they are getting more accessible to people no matter where they are.
Below you find updated information about Rust events in 2020.
Do you plan to run a Rust online event? Send an email to the Rust Community team and the team will be able to get your event on the calendar and might be able to offer further help.
Rust LATAM
Unfortunately the Latin American event Rust LATAM had to be canceled this year. The team hopes to be able to resume the event in the future.
Oxidize
July 17th-20th, 2020
The Oxidize conference was relabeled to become Oxidize Global. From July 17-20 you will be able to learn about embedded systems and IoT in Rust. Over the course of 4 days you will be able to attend online workshops (July 17th), listen to talks (July 18th) and take part in the Impl Days, where you can collaborate with other Embedded Rust contributors in active programming sessions.
Tickets are on sale and the speakers & talks will be announced soon.
RustConf
August 20th, 2020
The official RustConf will be taking place fully online. Listen to talks and meet other Rust enthusiasts online in digital meetups & breakout rooms. See the list of speakers, register already and follow Twitter for updates as the event date approaches!
Rusty Days
July 27th - August 2nd, 2020
Rusty Days is a new conference and was planned to happen in Wroclaw, Poland. It now turned into a virtual Rust conference stretched over five days. You'll be able to see five speakers with five talks -- and everything is free of charge, streamed online and available to watch later.
The Call for Papers is open. Follow Twitter for updates.
RustLab
October 16th-17th, 2020
RustLab 2020 is also turning into an online event. The details are not yet settled, but they are aiming for the original dates. Keep an eye on their Twitter stream for further details.
RustFest Netherlands
Q4, 2020
RustFest Netherlands was supposed to happen this June. The team decided to postpone the event and is now happening as an online conference in Q4 of this year. More information will be available soon on the RustFest blog and also on Twitter.
Conferences are not the only thing happening. More and more local meetups get turned into online events. We try to highlight these in the community calendar as well as in the This Week in Rust newsletter. Some Rust developers are streaming their work on the
Last fall, we launched the Firefox Private Network browser extension beta as a part of our Test Pilot experiments program. The extension offers safe, no-hassle network protection in the Firefox browser. Since our initial launch, we’ve released a number of versions offering different capabilities. We’ve also launched a Virtual Private Network (VPN) for users interested in full device protection.
Today we are pleased to announce the next step in our Firefox Private Network browser extension Beta. Starting soon, we will be transitioning from a free beta to a paid subscription beta for the Firefox Private Network browser extension. This version will be offered for a limited time for $2.99/mo and will provide unlimited access while using the Firefox Private Network extension. Like our existing extension, this version will be available in the U.S. first, but we hope to expand to other markets soon. Unlike our previous beta, this version will also allow users to connect up to three Firefox browsers at once using the same account. This will only be available for desktop users. For this release, we will also be updating our product icon to differentiate more clearly from the VPN. More information about our VPN as a stand-alone product offering will be shared in the coming weeks.
What did we learn
Last fall, when we first launched the Firefox Private Network browser extension, we saw a lot of early excitement around the product followed by a wave of users signing up. From September through December, we offered early adopters a chance to sign up for the extension with unlimited access, free of charge. In December, when the subscription VPN first launched, we updated our experimental offering to understand if giving participants a certain number of hours a month for browsing in coffee shops or at airports (remember those?) would be appealing. What we learned very quickly was that the appeal of the proxy came most of all from the simplicity of the unlimited offering. Users of the unlimited version appreciated having set and forget privacy, while users of the limited version often didn’t remember to turn on the extension at opportune moments.
These initial findings were borne out in subsequent research. Users in the unlimited cohort engaged at a high level, while users in the limited cohort often stopped using the proxy after only a few hours. When we spoke to proxy users, we found that for many the appeal of the product was in the set-it-and-forget-it protection it offered.
We also knew from the outset that we could not offer this product for free forever. While there are some free proxy products available in the market, there is always a cost associated with the network infrastructure required to run a secure proxy service. We believe the simplest and most transparent way to account for these costs is by providing this service at a modest subscription fee. After conducting a number of surveys, we believe that the appropriate introductory price for the Firefox Private Network browser extension is $2.99 a month.
What will be testing?
So the next thing we want to understand is basically this: will people pay for a browser-based privacy tool? It’s a simple question really, and one we think is best answered by the market. Over the summer we will be conducting a series of small marketing tests to determine interest in the Firefox Private Network browser extension as both a standalone subscription product and as well as part of a larger privacy and security bundle for Firefox.
In conjunction, we will also continue to explore the relationship between the Firefox Private Network extension and the VPN. Does it make sense to bundle them? Do VPN subscribers want access to the browser extension? How can we best communicate the different values and attributes of each?
What you can expect next
Starting in a few weeks, new users and users in the limited experiment will be offered the opportunity to subscribe to the unlimited beta for $2.99 a month. Shortly thereafter we will be asking our unlimited users to migrate as well.
The post Next steps in testing our Firefox Private Network browser extension beta appeared first on Future Releases.
Innovations spanning food supplies, medical records and PPE manufacture were today included in the final three awards made by Mozilla from its COVID-19 Solutions Fund. The Fund was established at the end of March by the Mozilla Open Source Support Program (MOSS), to offer up to $50,000 each to open source technology projects responding to the COVID-19 pandemic. In just two months, the Fund received 163 applicants from 30 countries and is now closed to new applications.
OpenMRS is a robust, scalable, user-driven, open source electronic medical record system platform currently used to manage more than 12.6 million patients at over 5,500 health facilities in 64 countries. Using Kenya as a primary use case, their COVID-19 Response project will coordinate work on OpenMRS COVID-19 solutions emerging from their community, particularly “pop-up” hospitals, into a COVID-19 package for immediate use.
This package will be built for eventual re-use as a foundation for a suite of tools that will become the OpenMRS Public Health Response distribution. Science-based data collection tools, reports, and data exchange interfaces with other key systems in the public health sector will provide critical information needed to contain disease outbreaks. The committee approved an award of $49,754.
Open Food Network offers an open source platform enabling new, ethical supply chains. Food producers can sell online directly to consumers and wholesalers can manage buying groups and supply produce through networks of food hubs and shops. Communities can bring together producers to create a virtual farmers’ market, building a resilient local food economy.
At a time when supply chains are being disrupted around the world — resulting in both food waste and shortages — they’re helping to get food to people in need. Globally, the Open Food Network is currently deployed in India, Brazil, Italy, South Africa, Australia, the UK, the US and five other countries. They plan to use their award to extend to ten other countries, build tools to allow vendors to better control inventory, and scale up their support infrastructure as they continue international expansion. The Committee approved a $45,210 award.
Careables Casa Criatura Olinda in northeast Brazil is producing face shields for local hospitals based on an open source design. With their award, they plan to increase their production of face shields as well as to start producing aerosol boxes using an open source design, developed in partnership with local healthcare professionals.
Outside of North American ICUs, many hospitals cannot maintain only one patient per room, protected by physical walls and doors. In such cases, aerosol boxes are critical to prevent the spread of the virus from patient to patient and patient to physician. Yet even the Brazilian city of Recife (population: 1.56 million), has only three aerosol boxes. The Committee has approved a $25,000 award and authorized up to an additional $5,000 to help the organization spread the word about their aerosol box design.
“Healthcare has for too long been assumed to be too high risk for open source development. These awards highlight how critical open source technologies are to helping communities around the world to cope with the pandemic,” said Jochai Ben-Avie, Head of International Public Policy and Administrator of the Program at Mozilla. “We are indebted to the talented global community of open source developers who have found such vital ways to put our support to good use.”
Information on the first three recipients from the Fund can be found here.
The post Mozilla Announces Second Three COVID-19 Solutions Fund Recipients appeared first on The Mozilla Blog.
Mozilla recently submitted our response to the European Commission’s public consultation on its European Strategy for Data. The Commission’s data strategy is one of the pillars of its tech strategy, which was published in early 2020 (more on that here). To European policymakers, promoting proper use and management of data can play a key role in a modern industrial policy, particularly as it can provide a general basis for insights and innovations that advance the public interest.
Our recommendations provide insights on how to manage data in a way that protects the rights of individuals, maintains trust, and allows for innovation. In addition to highlighting some of Mozilla’s practices and policies which underscore our commitment to ethical data and working in the open – such as our Lean Data Practices Toolkit, the Data Stewardship Program, and the Firefox Public Data Report – our key recommendations for the European Commission are the following:
- Address collective harms: In order to foster the development of data ecosystems where data can be leveraged to serve collective benefits, legal and policy frameworks must also reflect an understanding of potential collective harms arising from abusive data practices and how to mitigate them.
- Empower users: While enhancing data literacy is a laudable objective, data literacy is not a silver bullet in mitigating the risks and harms that would emerge in an unbridled data economy. Data literacy – i.e. the ability to understand, assess, and ultimately choose between certain data-driven market offerings – is effective only if there is actually meaningful choice of privacy-respecting goods and services for consumers. Creating the conditions for privacy-respecting goods and services to thrive should be a key objective of the strategy.
- Explore data stewardship models (with caution): We welcome the Commission’s exploration of novel means of data governance and management. We believe data trusts and other models and structures of data governance may hold promise. However, there are a range of challenges and complexities associated with the concept that will require careful navigation in order for new data governance structures to meaningfully improve the state of data management and to serve as the foundation for a truly ethical and trustworthy data ecosystem.
We’ll continue to build out our thinking on these recommendations, and will work with the European Commission and other stakeholders to make them a reality in the EU data strategy. For now, you can find our full submission here.
The post Mozilla releases recommendations on EU Data Strategy appeared first on Open Policy & Advocacy.
https://blog.mozilla.org/netpolicy/2020/06/05/eudatastrategy/
With the release of Firefox 77, we are pleased to welcome the 38 developers who contributed their first code change to Firefox in this release, 36 of whom were brand new volunteers! Please join us in thanking each of these diligent and enthusiastic individuals, and take a look at their contributions:
- daltonsam437: 1626784
- joshuagahan: 1622655
- mhd.tahawi: 1629435
- morganeckenroth: 1626769
- ryan.pauls67: 1626762
- tim.chenbw: 1629440
- severin Rudie: 1277172, 1532377, 1537634, 1569253, 1628528, 1629143, 1630380, 1632405
- Abdallah Afify: 1629431
- Abhirav Kariya: 908954
- Alex: 1627882
- Alice: 1620935
- Andrew Nicols: 1556903
- Ankita: 1612527, 1630797
- Arash Fotouhi: 1629426, 1629428
- Dace Jansone : 1553795
- Eames: 1622659
- Granjon Antoine: 1632413
- Konstantin: 1629427, 1629432
- Lilian Braud: 1624230
- Miguel Roncancio: 1489489
- Mitchell Hentges: 1569115, 1624380, 1634116
- NicolasPacheco: 1626765, 1626776
- Ojaswa Sharma: 1623004
- Omri Sarig: 1626787
- Riley Byrd: 1608202
- Roger Zanoni: 1626777
- Sergey Yarin: 1626774
- Shishir Jaiswal: 1629429
- Shyam Sundar: 1626766
- Sumagna Das: 1622687
- Sven Marnach:
Back when I first moved to Silicon Valley in 1998, I tried to understand how capital markets made the valley such a unique place for inventors and entrepreneurs. Corporate stocks, real estate, international currency and commodities markets were concepts I was well familiar with from my time working at a financial news service in the nation's capital in the mid 1990's. However, crowdfunding and angel investing were new concepts to me 20 years ago. Crowdfunding platforms seemed to be more to the advantage of the funding recipient than the balanced two-sided exchanges of the commercial financial system. I often wondered what motivated generosity-driven models that was different from reward-driven sponsorships.
When trying to grasp the way angel investors think about entrepreneurship, my friend Willy, a serial entrepreneur and investor, said: “If you want to see something succeed, throw money at it!” The idea behind the "angel" is that they are the riskiest of risk-capital. Angel investors join the startup funding before banks and venture capital firms. They seldom get payback in kind from the companies they sponsor and invest in. Angels are the lenders of first-resort for founders because they tend to be more generous, more flexible and more forgiving than lenders. They value the potential success of the venture far more than they value the money they put forth. And the contributions of an angel investor can have an outsized benefit in the early stage of an initiative by sustaining the founder/creator at their most vulnerable stage. But what is this essence they get out of it that is worth more than money to them?
Over the course of the last couple of decades I've become a part of the crowdfunding throng of inventors and sponsors. I have contributed to small business projects on Kiva in over 30 countries, and backed many small-scale projects across Kickstarter, Indiegogo and Appbackr. I've also been on the receiving side, having the chance to pitch my company for funding on Sand Hill Road, the strip of financial lending firms that populate Palo Alto's hillsides. As a funder, it has been very enlightening to know that I can be part of someone else's project by chipping in time, sharing insights and capital to get improbable projects off the ground. And the excitement of following the path of the entrepreneurs has been the greatest reward. As a founder, I remember framing the potential of a future that, if funded, would yield significant returns to the lenders and shareholders. Of course, the majority of new ventures do not come to market in the form of their initial invention. Some of the projects I participated in have launched commercially and I've been able to benefit. (By getting shares in a growing venture or by getting nifty gadgets and software as part of the pre-release test audience.) But those things aren't the reward I was seeking when I signed up. It was the energy of participating in the innovation process and the excitement about making a difference. After many years of working in the corporate world, I became hooked on the idea of working with engineers and developers who are bringing about the next generation of our expressive/experiential platforms of the web.

Okay, so I’ll delve a bit deeper into the libcurl internals than usual here. Beware of low-level talk!
There’s a never-ending stream of things to polish and improve in a software project and curl is no exception. Let me tell you what I fell over and worked on the other day.
Smaller than what holds Linux
We have users who are running curl on tiny devices, often put under the label of Internet of Things, IoT. These small systems typically have maybe a megabyte or two of ram and flash and are often too small to even run Linux. They typically run one of the many different RTOS flavors instead.
It is with these users in mind I’ve worked on the tiny-curl effort. To make curl a viable alternative even there. And believe me, the world of RTOSes and IoT is literally filled with really low quality and half-baked HTTP client implementations. Often certainly very small but equally as often with really horrible shortcuts or protocol misunderstandings in them.
Going with curl in your IoT device means going with decades of experience and reliability. But for libcurl to be an option for many IoT devices, a libcurl build has to be able to get really small. Both the footprint on storage but also in the required amount of dynamic memory used while executing.
Being feature-packed and attractive for the high-end users and yet at the same time being able to get really small for the low-end is a challenge. And who doesn’t like a good challenge?
Reduce reduce reduce
I’ve set myself on a quest to make it possible to build libcurl smaller than before and to use less dynamic memory. The first tiny-curl releases were only the beginning and I already then aimed for a libcurl + TLS library within 100K storage size. I believe that goal was met, but I also think there’s more to gain.
I will make tiny-curl smaller and use less memory by making sure that when we disable parts of the library or disable specific features and protocols at build-time, they should no longer affect storage or dynamic memory sizes – as far as possible. Tiny-curl is a good step in this direction but the job isn’t done yet – there’s more “dead meat” to carve off.
One example is my current work (PR #5466) on making sure there’s much less proxy remainders left when libcurl is built without support for such. This makes it smaller on disk but also makes it use less dynamic memory.
To decrease the maximum amount of allocated memory for a typical transfer, and in fact for all kinds of transfers, we’ve just switched to a model with on-demand download buffer allocations (PR #5472). Previously, the download buffer for a transfer was allocated at the same time as the handle (in the curl_easy_init call) and kept allocated until the handle was cleaned up again (with curl_easy_cleanup). Now, we instead lazy-allocate it first when the transfer starts, and we free it again immediately when the transfer is over.
It has several benefits. For starters, the previous initial allocation would always first allocate the buffer using the default size, and the user could then set a smaller size that would realloc a new smaller buffer. That double allocation was of course unfortunate, especially on systems that really do want to avoid mallocs and want a minimum buffer size.
The “price” of handling many handles drastically went down, as only transfers that are actively in progress will actually have a receive buffer allocated.
A positive side-effect of this refactor, is that we could now also make sure the internal “closure handle” actually doesn’t use any buffer allocation at all now. That’s the “spare” handle we create internally to be able to associate certain connections with, when there’s no user-provided handles left but we need to for example close down an FTP connection as there’s a command/response procedure involved.
Downsides? It means a slight increase in number of allocations and frees of dynamic memory for doing new transfers. We do however deem this a sensible trade-off.
Numbers
I always hesitate to bring up numbers since it will vary so much depending on your particular setup, build, platform and more. But okay, with that said, let’s take a look at the numbers I could generate on my dev machine. A now rather dated x86-64 machine running Linux.
For measurement, I perform a standard single transfer getting a 8GB file from http://localhost, written to stderr:
curl -s http://localhost/8GB
TenFourFox Feature Parity Release 23 final is now available for testing (downloads, hashes, release notes). This blog post was composed in the new Blogger interface, which works fine but is slower, so I'm going back to the old one. Anyway, there's no difference from the beta except for outstanding security fixes and as usual, if all goes well, it will go live Monday evening Pacific time.
http://tenfourfox.blogspot.com/2020/05/tenfourfox-fpr23-available.html
Today marks 20 years I’ve been working full-time for Mozilla.
As the Mozilla organization evolved, I moved with it. I started with staff@mozilla.org at Netscape 20 years ago, moved to the Mozilla Foundation ~17 years ago, and the Mozilla Corporation ~15 years ago.
Thank you to Mitchell Baker for taking a chance on me. I’m eternally grateful for that opportunity.

We are happy to announce that version 2.0 of WebXR Viewer, released today, is the first web browser on iOS to implement the new WebXR Device API, enabling high-performance AR experiences on the web that don't share pictures of your private spaces with third party Javascript libraries and websites.
It's been almost a year since the previous release (version 1.17) of our experimental WebXR platform for iOS, and over the past year we've been working on two major changes to the app: (1) we updated the Javascript API to implement the official WebXR Device API specification, and (2) we ported our ARKit-based WebXR implementation from our minimal single-page web browser to the full-featured Firefox for iOS code-base.
WebXR Device API: Past, Present, and Future
The first goal this release is to update the browser's Javascript API for WebXR to support the official WebXR Device API, including an assortment of approved and proposed AR features. The original goal with the WebXR Viewer was to give us an iOS-based platform to experiment with AR features for WebXR, and we've written previous posts about experimenting with privacy and world structure, computer vision, and progressive and responsive WebXR design. We would like to continue those explorations in the context of the emerging standard.
We developed the API used in the first version of the WebXR Viewer more than 3 years ago (as a proposal for how WebXR might combine AR and VR; see the WebXR API proposal here, if you are interested), and then updated it a year ago to match the evolving standard. While very similar to the official API, this early version of the official API is not compatible with the final standard, in some substantial ways. Now that WebXR is appearing in mainstream browsers, it's confusing to developers to have an old, incompatible API out in the world.
Over the past year, we rebuilt the API to conform to the official spec, and either updated our old API features to match current proposals (e.g., anchors, hit testing, and DOM overlay), marked them more explicitly as non-standard (e.g., by adding a nonStandard_ prefix to the method names), or removed them from the new version (e.g., camera access). Most WebXR AR examples on the web now work with the WebXR Viewer, such as the "galaxy" example from the WebXR Samples repository shown in the banner above.
(The WebXR Viewer's Javascript API is entirely defined in the Javascript library in the webxr-ios-js repository linked above, and the examples are there as well; the library is loaded on demand from the github master branch when a page calls one of the WebXR API calls. You can build the API yourself, and change the URL in the iOS app settings to load your version instead of ours, if you want to experiment with changes to the API. We'd be happy to receive PRs, and issues, at that github repository.)

In the near future, we're interested in continuing to experiment with more advanced AR capabilities for WebXR, and seeing what kinds of
Originally published as a cookbook on docs.telemetry.mozilla.org to instruct data users within Mozilla how to take advantage of the usage history stored in our BigQuery tables.

Monthly active users (MAU) is a windowed metric that requires joining data
per client across 28 days. Calculating this from individual pings or daily
aggregations can be computationally expensive, which motivated creation of the
clients_last_seen dataset
for desktop Firefox and similar datasets for other applications.
A powerful feature of the clients_last_seen methodology is that it doesn’t
record specific metrics like MAU and WAU directly, but rather each row stores
a history of the discrete days on which a client was active in the past 28 days.
We could calculate active users in a 10 day or 25 day window just as efficiently
as a 7 day (WAU) or 28 day (MAU) window. But we can also define completely new
metrics based on these usage histories, such as various retention definitions.
https://jeff.klukas.net/writing/2020-05-29-encoding-usage-history-in-bit-patterns/
Yes, you read that right! This blog has just relaunched. It runs on a new platform. And it is a lot faster, and has a very slick look and feel to it. Read on to find out some more details.
Why the switch?
Well, after 13 years, I felt it was time for something new. Also, as I wrote recently, Mozilla now has a dedicated accessibility blog, so I feel that I am free to do other things with my blog now. As a sign of that, I wanted to migrate it to a new platform.
This is not to say the old platform, WordPress, is bad or anything like that. But for my needs, it has become much too heavy-weight in features, and also in the way how it feels when performing day to day tasks. 80% of features it offers are features I don't use. This pertains both to the blog system itself as well as its new block editor. But those features don't get out of the way easily, so over the months and actually last two to three years, I felt that I was moving mountains just to accomplish simple things. It has nothing to do with the steadily improving accessibility, either. That is, as I said, getting better all the time. It just feels heavy-weight to the touch and keyboard when using it.
So one day earlier this year, I read a post on my favorite publishing editor's web site, where they told the story how they migrated to the Ghost platform. I must admit I had never heard of Ghost before, but was curious, so I started poking around.
Discovering the JAMstack
As I did so, I quickly stumbled on the term JAMstack. Some of you may now ask: "Stumbled upon? What rock have you been living under these past 5 or 6 years?" Well, you know, I had heard of some of the software packages I am going to mention, but I didn't have the time, and more recently, energy, to actually dig into these technology stacks at all.
The truth is, I started asking myself this question as I became more familiar with Ghost itself, static site generators, and how this can all hang together. JAM stands for JavaScript, APIs and Markup, and describes the mental separation between how and where content is created, how it's being transferred, and then finally, output to the world.
In a nutshell - and this is just the way I understand things so far -, applications like WordPress or Drupal serve the content from a database every time someone visits a site or page. So every time an article on my blog was being brought up, database queries were made, HTML was put together, and then served to the recipient. This all happens in the same place.
Better efficiency
However, there are other ways to do that, aren't there? Articles usually don't change every day, so it is actually not necessary to regenerate the whole thing each time. Granted, there are caching options for these platforms, but from past experience, I know that these weren't always that reliable, even when they came from the same vendor as the main platform.
JAMstack setups deal with this whole thing in a different way. The content is generated somewhere, by writers who feel comfortable with a certain platform. This can, for all intents and purposes, even be WordPress nowadays since it also offers a REST API. But it can also be Ghost. Or NetlifyCMS together with a static site generator. Once the content is done, like this blog post, it is being published to that platform.
What can happen then depends on the setup. Ghost has its own front-end, written in Ember, and can serve the content directly using one of the many templates available now. This is how my blog is set up right now. So this is not that much different from WordPress, only that Ghost is much more light-weight and faster, and built entirely, not just partially, on modern JS stacks.
However, it doesn't have to be that way. Through integrations, web hooks and by leveraging source code management systems like Github or Gitlab, every time my content updates, a machinery can be set in motion that publishes my posts to a static site generator or fast JavaScript application framework. That then serves the content statically, and thus much faster than a constant rebuild, whenever it is being called from a visitor.
Such static site generators are, for example, Hugo or Eleventy, which both serve static HTML pages to the audience with only minimal JavaScript. Or they can be application frameworks like Gatsby.js, which is a single page application serving the

Virtual events are unique, and each one has varying needs for how many users can be present. In this blog post, we’ll talk about the different ways that you can consider concurrency as part of a virtual event, the current capabilities of Mozilla Hubs and Hubs Cloud for supporting users, and considerations for using Hubs as part of events of varying sizes. If you’ve considered using Hubs for a meetup or conference, or are just generally interested in how the platform works, read on!
Concurrency Planning for Virtual Events
When we think about traditional event planning, we have one major restriction that guides us: the physical amount of space that is available to us. When we take away the physical location as a restriction for our event by moving our event online, it can be hard to understand what limits might exist for a given platform.
With online collaboration software, there are many factors that come into play. Applications might have a per-event limit, a per-room limit, or a per-platform limit that can influence how capacity planning is done. Hubs has both ‘per-room’ and ‘per-platform’ user limits. These limits are dependent on whether you are creating a room on hubs.mozilla.com, or using Hubs Cloud. When considering the number of people who you might want to have participate in your event, it’s important to think about the distribution of those users and the content of the event that you’re planning. This relates back to physical event planning: while your venue may have an overall capacity in the thousands, you will also need to consider how many people can fit in different rooms.
When thinking about how to use Hubs or Hubs Cloud for an event, you can consider two different options -- one where you start from how many people you want to support, and how they will be split across rooms, and one where you start from the total event size and figure out how many rooms will be necessary. Below, we cover some of the considerations for room and system-wide capabilities for Hubs and Hubs Cloud.
Hubs Room Capacity
With Hubs, the question gets a bit more complicated, because you can control the room capacity and the “venue” capacity via Hubs Cloud. Hubs supports up to 50 users in an individual room. However, it is important to note that this is the server limit on the number of people who can be accommodated in a single room - it does not guarantee that everyone will be able to have a good experience. Generally speaking, users who are connecting with a mobile phone or standalone virtual reality headset (for example, something with an Qualcomm 835 chipset) will start to see performance drops before users on a gaming PC with hardwired internet will. While Hubs offers a great amount of flexibility in sharing all sorts of content from around the web, user-generated content can often bring with it a large amount of overhead to support sharing large files or streaming content. Oftentimes, these performance issues manifest in a degraded audio experience or frame rate drops.
With virtual events, the device that your attendees are connecting from will make a difference, as will their home network configurations. Factors that impact performance in Hubs include:
- The number of people who are in a room
- The amount of content that is in a room
- The type of content that is in a room
As a result of these considerations, we set a default room capacity at about half of the total server capacity, because users will likely experience issues connecting to a room that has 50 avatars in it. The server limit is capped because each user that connects to a room opens up a channel to the server to send network data (specifically, voice data) and at higher number of users, the software running on the server has to do a lot of work to get that data processed and sent back out to the other clients in real-time. While increasing the size and number of servers that are available can help the system-wide concurrency, it will not increase individual room capacity beyond the 50 connection cap given that the underlying session description protocol (SDP) negotiations between the connected clients is a single-threaded process.
Firefox 77 is loaded with great improvements for the WebExtensions API. These additions to the API will help you provide a great experience for your users.
Optional Permissions
Since Firefox 57, users have been able to see what permissions an extension wants to access during the installation process. The addition of any new permissions to the extension triggers another notification that users must accept during the extension’s next update. If they don’t, they won’t receive the updated version.
These notifications were intended to provide transparency about what extensions can do and help users make informed decisions about whether they should complete the installation process. However, we’ve seen that users can feel overwhelmed by repeated prompts. Worse, failure to see and accept new permissions requests for updated versions can leave users stranded on older versions.
We’re addressing this with optional permissions. First, we have made a number of permissions optional. Optional permissions don’t trigger a permission prompt for users during installation or when the extension updates. It also means that users have less of a chance of becoming stranded.
If you use the following permissions, please feel welcome to move them from the permissions manifest.json key to the optional_permissions key:
- management
- devtools
- browsingData
- pkcs11
- proxy
- session
Second, we’re encouraging developers who use optional permissions to request them at runtime. When you use optional permissions with the permissions.request API, permission requests will be triggered when permissions are needed for a feature. Users can then see which permissions are being requested in context of using the extension. For more information, please see our guide on requesting permissions at runtime.
As an added bonus, we’ve also implemented the permissions.onAdded and permissions.onRemoved events, allowing you to react to permissions being granted or revoked.
Merging CSP headers
Users who have multiple add-ons installed that modify the content security policy headers of requests may have been seeing their add-ons behave erratically and will likely blame the add-on(s) for not working. Luckily, we now properly merge the CSP headers when two add-ons modify them via webRequest. This is especially important for content blockers leveraging the CSP to block resources such as scripts and images.
Handling SameSite cookie restrictions
We’ve seen developers trying to work around SameSite cookie restrictions. If you have been using iframes on your extension pages and expecting them to behave like first party frames, the SameSite cookie attribute will keep your add-on from working properly. In Firefox 77, the cookies for these frames will behave as if it was a first party request. This should ensure that your extension continues to work as expected.
Other updates
Please also see these additional changes:
- The tabs.duplicate API now allows the position and active status of a duplicated tab to be specified.
- We’ve limited the ability to monitor data: URIs using the webRequest API. This feature was never clearly documented, and is also not supported by Chrome. Please see the bug for more details.
- WebExtensions can now also clear IndexedDB and