Today, I’m excited to welcome Navrina Singh as a new member of the Mozilla Foundation Board of Directors. You can see comments from Navrina here.
Navrina is the Co-Founder of Credo AI, an AI Fund company focused on auditing and governing Machine Learning. She is the former Director of Product Development for Artificial Intelligence at Microsoft. Throughout her career she has focused on many aspects of business including start up ecosystems, diversity and inclusion, development of frontier technologies and products. This breadth of experience is part of the reason she’ll make a great addition to our board.
In early 2020, we began focusing in earnest on expanding Mozilla Foundation’s board. Our recruiting efforts have been geared towards building a diverse group of people who embody the values and mission that bring Mozilla to life and who have the programmatic expertise to help Mozilla, particularly in artificial intelligence.
Since January, we’ve received over 100 recommendations and self-nominations for possible board members. We ran all of the names we received through a desk review process to come up with a shortlist. After extensive conversations, it is clear that Navrina brings the experience, expertise and approach that we seek for the Mozilla Foundation Board.
Prior to working on AI at Microsoft, Navrina spent 12 years at Qualcomm where she held roles across engineering, strategy and product management. In her last role as the head of Qualcomm’s technology incubator ‘ImpaQt’ she worked with early start-ups in machine intelligence. Navrina is a Young Global Leader with the World Economic Forum; and has previously served on the industry advisory board of the University of Wisconsin-Madison College of Engineering; and the boards of Stella Labs, Alliance for Empowerment and the Technology Council for FIRST Robotics.
Navrina has been named as Business Insiders Top Americans changing the world and her work in Responsible AI has been featured in FORTUNE, Geekwire and other publications. For the past decade she has been thinking critically about the way AI and other emerging technologies impact society. This included a non-profit initiative called Marketplace for Ethical and Responsible AI Tools (MERAT) focused on building, testing and deploying AI responsibly. It was through this last bit of work that Navrina was introduced to our work at Mozilla. This experience will help inform Mozilla’s own work in trustworthy AI.
We also emphasized throughout this search a desire for more global representation. And while Navrina is currently based in the US, she has a depth of experience partnering with and building relationships across important markets – including China, India and Japan. I have no doubt that this experience will be an asset to the board. Navrina believes that technology can open doors, offering huge value to education, economies and communities in both the developed and developing worlds.
Please join me in welcoming Navrina Singh to the Mozilla Foundation Board of Directors.
PS. You can read Navrina’s message about why she’s joining Mozilla here.
Background:
Twitter: @navrina_singh
LinkedIn: https://www.linkedin.com/in/navrina/
The post Navrina Singh Joins the Mozilla Foundation Board of Directors appeared first on The Mozilla Blog.
Firefox was my window into Mozilla 15 years ago, and it’s through this window I saw the power of an open and collaborative community driving lasting change. My admiration and excitement for Mozilla was further bolstered in 2018, when Mozilla made key additions to its Manifesto to be more explicit around it’s mission to guard the open nature of the internet. For me this addendum signalled an actionable commitment to promote equal access to the internet for ALL, irrespective of the demographic characteristic. Growing up in a resource constrained India in the nineties with limited access to global opportunities, this precise mission truly resonated with me.
Technology should always be in service of humanity – an ethos that has guided my life as a technologist, as a citizen and as a first time co-founder of Credo.ai. Over the years, I have seen the deepened connection between my values and Mozilla’s commitment. I had come to Mozilla as a user for the secure, fast and open product, but I stayed because of this alignment of missions. And today, I’m very honored to join Mozilla’s Board.
Growing up in India, having worked globally and lived in the United States for the past two decades, I have first hand witnessed the power of informed communities and transparent technologies to drive innovation and change. It is my belief that true societal transformation happens when we empower our people, give them the right tools and the agency to create. Since its infancy Mozilla has enabled exactly that, by creating an open internet to serve people first, where individuals can shape their own empowered experiences.
Though I am excited about all the areas of Mozilla’s impact, I joined the Mozilla board to strategically support the leaders in Mozilla’s next frontier – supporting it’s theory of change for pursuing more trustworthy Artificial Intelligence.
Mozilla has, from the beginning, rejected the idea of the black box by creating a transparent and open ecosystem making visible all the inner working and decision making within its organizations and products. I am beyond excited to see that this is the same mindset (of transparency and accountability) the Mozilla leaders are bringing to their initiatives in trustworthy Artificial Intelligence (AI).
AI is a defining technology of our times which will have a broad impact on every aspect of our lives. Mozilla is committed to mobilizing public awareness and demand for more responsible AI technology especially in consumer products. In my new role as a Mozilla Foundation Board Member, I am honored to support Mozilla’s AI mission, its partners and allies around the world to build momentum for a responsible and trustworthy digital world.
Today the world crumbles under the weight of multiple pandemics – racism, misinformation, coronavirus – powered and resolved by people and technology. Now more than ever the internet and technology needs to bring equal opportunity, verifiable facts, human dignity, individual expression and collaboration among diverse communities to serve humanity. Mozilla has championed for these tenants and brought about change for decades. Now with it’s frontier focus on trustworthy AI, I am excited to see the continued impact it brings to our world.
We are at a transformational intersection in our lives where we need to critically examine and explore our choices around technology to serve our communities. How can we build technology that is demonstrably worthy of trust? How can we empower people to design systems for transparency and accountability? How can we check the values and biases we are bringing to building this fabric of frontier technology? How can we build diverse communities to catalyze change? How might we build something better, a better world through responsible technology? These questions have shaped my journey. I hope to bring this learning mindset and informed action in service of the Mozilla board and its trustworthy AI mission.
The post Why I’m Joining the Mozilla Board appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2020/06/22/why-im-joining-the-mozilla-board/
Alternative title: “testing, Q&A, CI, fuzzing and security in curl”
June 30 2020, at 10:00 AM in Pacific Time (17:00 GMT, 19:00 CEST).
Time: 30-40 minutes
Abstract: curl runs in some ten billion installations in the world, in
virtually every connected device on the planet and ported to more operating systems than most. In this presentation, curl’s lead developer Daniel Stenberg talks about how the curl project takes on testing, QA, CI and fuzzing etc, to make sure curl remains a stable and secure component for everyone while still getting new features and getting developed further. With a Q&A session at the end for your questions!
Register here at attend the live event. The video will be made available afterward.

https://daniel.haxx.se/blog/2020/06/22/webinar-testing-curl-for-security/
In Q4 2020 the EU will propose what’s likely to be the world’s first general AI regulation. While there is still much to be defined, the EU looks set to establish rules and obligations around what it’s proposing to define as ‘high-risk’ AI applications. In advance of that initiative, we’ve filed comments with the European Commission, providing guidance and recommendations on how it should develop the new law. Our filing brings together insights from our work in Open Innovation and Emerging Technologies, as well as the Mozilla Foundation’s work to advance trustworthy AI in Europe.
We are in alignment with the Commission’s objective outlined in its strategy to develop a human-centric approach to AI in the EU. There is promise and the potential for new and cutting edge technologies that we often collectively refer to as “AI” to provide immense benefits and advancements to our societies, for instance through medicine and food production. At the same time, we have seen some harmful uses of AI amplify discrimination and bias, undermine privacy, and violate trust online. Thus the challenge before the EU institutions is to create the space for AI innovation, while remaining cognisant of, and protecting against, the risks.
We have advised that the EC’s approach should be built around four key pillars:
- Accountability: ensuring the regulatory framework will protect against the harms that may arise from certain applications of AI. That will likely involve developing new regulatory tools (such as the ‘risk-based approach’) as well as enhancing the enforcement of existing relevant rules (such as consumer protection laws).
- Scrutiny: ensuring that individuals, researchers, and governments are empowered to understand and evaluate AI applications, and AI-enabled decisions – through for instance algorithmic inspection, auditing, and user-facing transparency.
- Documentation: striving to ensure better awareness of AI deployment (especially in the public sector), and to ensure that applications allow for documentation where necessary – such as human rights impact assessments in the product design phase, or government registries that map public sector AI deployment.
- Contestability: ensuring that individuals and groups who are negatively impacted by specific AI applications have the ability to contest those impacts and seek redress e.g. through collective action.
The Commission’s consultation focuses heavily on issues related to AI accountability. Our submission therefore provides specific recommendations on how the Commission could better realise the principle of accountability in its upcoming work. Building on the consultation questions, we provide further insight on:
- Assessment of applicable legislation: In addition to ensuring the enforcement of the GDPR, we underline the need to take account of existing rights and protections afforded by EU law concerning discrimination, such as the Racial Equality directive and the Employment Equality directive.
- Assessing and mitigating “high risk” applications: We encourage the Commission to further develop (and/or clarify) its risk mitigation strategy, in particular how, by whom, and when risk is being assessed. There are a range of points we have highlighted here, from the importance of context and use being critical components of risk assessment, to the need for comprehensive safeguards, the importance of diversity in the risk assessment process, and that “risk” should not be the only tool in the mitigation toolbox (e.g. consider moratoriums).
- Use of biometric data: the collection and use of biometric data comes with significant privacy risks and should be carefully considered where possible in an open, consultative, and evidence-based process. Any AI applications harnessing biometric data should conform to existing legal standards governing the collection and processing of biometric data in the GDPR. Besides questions of enforcement and risk-mitigation, we also encourage the Commission to explore edge-cases around biometric data that are likely to come to prominence in the AI sphere, such as voice recognition.
A special thanks goes to the Mozilla Fellows 2020 cohort, who contributed to the development of our submission, in particular Frederike Kaltheuner, Fieke Jansen, Harriet Kingaby, Karolina Iwanska, Daniel Leufer, Richard Whitt, Petra Molnar, and Julia Reinhardt.
This public consultation is one of the first steps in the Commission’s lawmaking process. Consultations in various forms will continue through the end of the year when the draft legislation is planned to be proposed. We’ll continue to build out our thinking on these recommendations, and look forward to collaborating further
My tour through vulnerabilities in antivirus applications continues with Bitdefender. One thing shouldn’t go unmentioned: security-wise Bitdefender Antivirus is one of the best antivirus products I’ve seen so far, at least in the areas that I looked at. The browser extensions minimize attack surface, the crypto is sane and the Safepay web browser is only suggested for online banking where its use really makes sense. Also very unusual: despite jQuery being used occasionally, the developers are aware of Cross-Site Scripting vulnerabilities and I only found one non-exploitable issue. And did I mention that reporting a vulnerability to them was a straightforward process, with immediate feedback and without any terms to be signed up front? So clearly security isn’t an afterthought which is sadly different for way too many competing products.

But they aren’t perfect of course, or I wouldn’t be writing this post. I found a combination of seemingly small weaknesses, each of them already familiar from other antivirus products. When used together, the effect was devastating: any website could execute arbitrary code on user’s system, with the privileges of the current user (CVE-2020-8102). Without any user interaction whatsoever. From any browser, regardless of what browser extensions were installed.
Contents
Summary of the findings
As part of its Online Protection functionality, Bitdefender Antivirus will inspect secure HTTPS connections. Rather than leaving error handling to the browser, Bitdefender for some reason prefers to display their own error pages. This is similar to how Kaspersky used to do it but without most of the adverse effects. The consequence is nevertheless that websites can read out some security tokens from these error pages.
These security tokens cannot be used to override errors on other websites, but they can be used to start a session with the Chromium-based Safepay browser. This API was never meant to accept untrusted data, so it is affected by the same vulnerability that we’ve seen in Avast Secure Browser before: command line flags can be injected, which in the worst case results in arbitrary applications starting up.
How Bitdefender deals with HTTPS connections
It seems that these days every antivirus product is expected to come with three features as part of their “online protection” component: Safe Browsing (blocking of malicious
In 2020, the curl user survey ran for the 7th consecutive year. It ended on May 31 and this year we manage to get feedback donated by 930 individuals.

Analysis
Analyzing this huge lump of data, comments and shared experiences is a lot of work and I’m sorry it’s taken me several weeks to complete it. I’m happy to share this 47 page PDF document here with you:
curl user survey 2020 analysis
If you have questions on the content or find mistakes or things looking odd in the data or graphs, do let me know!
If you want to help out to do a better survey or analysis next year, I hope you know that you’d be much appreciated…
https://daniel.haxx.se/blog/2020/06/21/curl-user-survey-2020-analysis/
TenFourFox Feature Parity Release 24 beta 1 is now available (downloads, hashes, release notes). This includes Rapha"el's mitigation for Twitch frame crashes and Ken's Intel build system fixes, plus minor updates to JavaScript, DOM and layout, and fixes for sundry issues with MP3 playback (make that G4 Mac mini an Internet radio today) along with the usual security updates. Assuming all goes well, TenFourFox FPR24 will go final on or about June 29 parallel with Firefox 78.
http://tenfourfox.blogspot.com/2020/06/tenfourfox-fpr24b1-available.html
In this moment of rapid change, we recognize that the relics of racism exist. The actions we have seen most recently are not isolated actions. Racial injustice affects all aspects of life in our society, our collective progress has been insufficient, Mozilla’s progress has been insufficient. As we said earlier this month, we have work to do.
Today, we are sharing a set of commitments that are a starting point for three areas where we will drive change across Mozilla:
1. Who we are: Our employee base and our communities
To begin, we are committed to significantly increasing Black and Latinx representation in Mozilla in the next two years. We will:
- Double the percentage of Black and Latinx representation of our U.S. staff. This is a starting point for what Mozilla should look like, not an aspirational end point, and it applies to all levels of the organization.
- Increase Black representation in the U.S. at the leadership level, aiming for 6% Black employees at the Director level and up, as well as representation on Mozilla Corporation and Mozilla Foundation boards.
- Create dedicated and comprehensive recruiting, development and inclusion efforts that attract and retain Black and Latinx Mozillans.
These commitments are not just about numbers, but about people, and that means having an environment that is diverse, inclusive and welcoming and addresses issues in people’s lives. Our work ahead is in hiring and retaining and also in providing the resources to mentor, develop and advance diverse employees, as well as ongoing education and reflection for our full staff, so that we can create the environment that reflects our mission and our users.
2. What we build: Our outreach with our products
Educating ourselves is how we can begin dismantling systemic racism, and to do that we started with surfacing content via Pocket through Firefox. These collections of works by Black writers and thought leaders are being distributed through our Pocket product with companion promotion through Firefox product messaging. It was new for us to use our products in this way. We will continue to explore how we can leverage the functionality and reach of our products and services to advance change.
Our user research and understanding of our users, their stories and problems also need broadening. We see this as a journey, with undoubtedly other ways that our products can contribute more.
3. What we do beyond products: Our broader engagement with the world
How Mozilla shows up in the world and engages to uplift and increase Black voices in the broader efforts to build a better internet, beyond just our own teams, is equally important. We have supported organizations working at the intersection of tech and racial justice such as the ACLU, Color of Change and Astraea Foundation. We’ve already committed to further work at the intersection of technology and racial justice in 2020 because it helps us build a bigger and stronger movement for a healthy internet.
Beyond those existing partnerships, we are also committing to:
- Direct at least 40% of Mozilla Foundation grants in 2020 to Black-led projects or organizations, with specific targets to come for 2021 and beyond. We see this as critical to the transformation of our organization and the broader healthy internet movement we are part of.
- Develop and invest in new college engagement programs with Historically Black Colleges and Universities (HBCUs) and Black student networks. We will work closely with professors and students on topics like open source and trustworthy AI, and connect them to the Mozilla community. Mozilla is committed to a culture shift in tech.
- Focus Mozilla’s brand and social media efforts on lifting up people and organizations standing for Black lives and communities, especially where they’re working at the intersection of technology and racial justice.
By committing to change who we are, what we build and what we do beyond our products, we are talking about transforming how Mozilla shows up in the world in fundamental ways. Making this change will require us to support each other, to allow for mistakes and to embrace learning. But most of all it will require us to focus tenaciously on our values and lean into the idea that we’re creating an open internet for all. This isn’t just essential for this moment in time. It’s critical for the future of Mozilla, the future of the internet and the
TL;DR: The Social Support Program is moving from Buffer Reply to Conversocial per June, 1st 2020. We’re also going to reply from @FirefoxSupport now instead of the official brand account. If you’re interested to join us in Conversocial, please fill out this form (make sure you meet the requirements before you fill out the form).
We have very exciting news from the Social Support Program. In the past, we invited a few trusted contributors to Buffer Reply in order to let them reply to Twitter conversations from the official account. However, since Buffer sunset their Reply service per the 1st of June, now we officially moved to Conversocial to replace Buffer Reply.
Conversocial is one of a few tools that stood out from the search process that began at the beginning of the year because it focuses on support rather than social media management. We like the pricing model as well since it doesn’t restrict us from adding more contributors because it’s volume-based instead of seat-based.
If you’re interested to join us on Conversocial, please fill out this form. However, please be advised that we have a few requirements before we can let you into the tool.
Here are a few resources that we’ve updated to reflect the changes in the Social Support program:
We also just acquire @FirefoxSupport account on Twitter with the help of the Marketing team. Moving forward, contributors from the social support program will continue to reply from this account instead of the official brand account. This will allow the official brand account to focus on brand engagement and will also give us an opportunity to utilize the greater functionality of a full account.
We’re happy about the change and excited to see how we can scale the program moving forward. I hope you all share the same excitement and will continue to support and rocking the helpful web!
https://blog.mozilla.org/sumo/2020/06/18/social-support-program-updates/
We are now spending more time online than ever. At Mozilla, we are working hard to build products to help you take control of your privacy and stay safe online. To help us better understand your needs and challenges, we reached out to you — our users and supporters of Firefox Private Network.
We learned from you and our peers that many of you want to feel safer online without jumping through hoops and decided to start with the goal of providing device-level protection. This is why we built the Firefox Private Network’s Mozilla VPN, to help you control how your data is shared within your network. Although there are a lot of VPNs out there, we felt like you deserved a VPN with the Mozilla name behind it.
To build the best VPN, we turned to you again. After all, who knows you better than you, right? We started recruiting Beta testers in 2019. It was amazing to see the recruitment attract potential testers from over 200 countries around the world.
We started working with a small group of you and learned a lot. With the VPN in your hands, we confirmed some of our initial hypotheses and identified important priorities for the future. For example, over 70% of early Beta-testers say that the VPN helps them feel empowered, safe and independent while online. In addition, 83% of early Beta-testers found the VPN easy to use.
We know that we are on the right path to building a VPN that makes your online experience safer and easier to manage. We’ll keep making the right decisions for you guided by our Data Privacy Principles. This means that we are actively forgoing revenue streams and additional profit-making opportunities by committing to never track your browsing activities and avoiding any third party in-app data analytics platforms.
Your feedback also helped us identify ways to make the VPN more impactful and privacy-centric, which includes building features like split tunneling and making it available on Mac clients. The VPN will exit Beta phase in the next few weeks, move out of the Firefox Private Network brand, and become a stand-alone product, Mozilla VPN, to serve a larger audience.
To our Beta-testers, we would like to thank you for working with us. Your feedback and support made it possible for us to launch Mozilla VPN.
We are working hard to make the official product, the Mozilla VPN, available in selected regions this year. We will continue to offer the Mozilla VPN at the current pricing model for a limited time, which allows you to protect up to five devices on Windows, Android, and iOS at $4.99/month.
As we realize our vision to provide next-generation privacy and security solutions, we would like to invite you to continue to share your thoughts with us. Follow our journey through this blog, and stay connected via the waitlist here*. If you are interested to learn more about the product, the Beta Mozilla VPN is available for download in the U.S. now.
*For users outside of the U.S., We will only contact you with product updates when Mozilla VPN becomes available for your region and device.
From The Firefox Private Network Mozilla VPN Team
The post Introducing Firefox Private Network’s VPN – Mozilla VPN appeared first on Future Releases.
Last week, I finished a three-part pilot for a new stream called Compiler Compiler, which looks at how the JavaScript Specification, ECMA-262, is implemented in SpiderMonkey.
JavaScript …is a programming language. Some people love it, others don’t. JavaScript might be a bit messy, but it’s easy to get started with. It’s the programming language that taught me how to program and introduced me to the wider world of programming languages. So, it has a special place in my heart. As I taught myself, I realized that other people were probably facing a lot of the same struggles as I was. And really that is what Compiler Compiler is about.
The first bug of the stream was a test failure around increment/decrement. If you want to catch up on the series so far, the pilot episodes have been posted and you can watch those in the playlist here:
Future episodes will be scheduled here with descriptions, in case there is a specific topic you are interested in. Look for blog posts here to wrap up each bug as we go.
What is SpiderMonkey?
SpiderMonkey is the JavaScript engine for Firefox. Along with V8, JSC, and other implementations, it is what makes JavaScript run. Contributing to an engine might be daunting due to the sheer amount of underlying knowledge associated with it.
- Compilers are well studied, but the materials available to learn about them (such as the Dragon book, and other texts on compilers) are usually oriented to university-setting study — with large dedicated periods of time to understanding and practicing. This dedicated time isn’t available for everyone.
- SpiderMonkey is written in C++. If you come from an interpreted language, there are a number of tools to learn in order to really get comfortable with it.
- It is an implementation of the ECMA-262 standard, the standard that defines JavaScript. If you have never read programming language grammars or a standard text, this can be difficult to read.
The Compiler Compiler stream is about making contributing easier. If you are not sure how to get started, this is for you!
The Goals and the Structure
I have two goals for this series. The first, and more important one, is to introduce people to the world of language specification and implementation through SpiderMonkey. The second is to make SpiderMonkey as conformant to the ECMA-262 specification as possible, which luckily is a great framing device for the first goal.
I have organized the stream as a series of segments with repeating elements, every segment consisting of about 5 episodes. A segment will start from the ECMA-262 conformance test suite (Test262) with a test that is failing on SpiderMonkey. We will take some time to understand what the failing test is telling us about the language and the SpiderMonkey implementation. From there we will read and understand the behavior specified in the ECMA-262 text. We will implement the fix, step by step, in the engine, and explore any other issues that arise.
Each episode in a segment will be 1 hour long, followed by free chat for 30 minutes afterwards. If you have questions, feel free to ask them at any time. I will try to post materials ahead of time for you to read about before the stream.
If you missed part of the series, you can join at the beginning of any segment. If you have watched previous segments, then new segments will uncover new parts of the specification for you, and the repetition will make it easier to learn. A blog post summarizing the information in the stream will follow each completed segment.
Last but not least, a few thank yous
I have been fortunate enough to have my colleagues from the SpiderMonkey team and TC39 join the chat. Thank you to Iain Ireland,
We have started the work on extending wolfSSL to provide the necessary API calls to power QUIC and HTTP/3 implementations!
Small, fast and FIPS
The TLS library known as wolfSSL is already very often a top choice when users are looking for a small and yet very fast TLS stack that supports all the latest protocol features; including TLS 1.3 support – open source with commercial support available.
As manufacturers of IoT devices and other systems with memory, CPU and footprint constraints are looking forward to following the Internet development and switching over to upcoming QUIC and HTTP/3 protocols, wolfSSL is here to help users take that step.
A QUIC reminder
In case you have forgot, here’s a schematic view of HTTPS stacks, old vs new. On the right side you can see HTTP/3, QUIC and the little TLS 1.3 box there within QUIC.

ngtcp2
There are no plans to write a full QUIC stack. There are already plenty of those. We’re talking about adjustments and extensions of the existing TLS library API set to make sure wolfSSL can be used as the TLS component in a QUIC stack.
One of the leading QUIC stacks and so far the only one I know of that does this, ngtcp2 is written to be TLS library agnostic and allows different TLS libraries to be plugged in as different backends. I believe it makes perfect sense to make such a plugin for wolfSSL to be a sensible step as soon as there’s code to try out.

A neat effect of that, would be that once wolfSSL works as a backend to ngtcp2, it should be possible to do full-fledged HTTP/3 transfers using curl powered by ngtcp2+wolfSSL. Contact us with other ideas for QUIC stacks you would like us to test wolfSSL with!
FIPS 140-2
We expect wolfSSL to be the first FIPS-based implementation to add support for QUIC. I hear this is valuable to a number of users.
When
This work begins now and this is just a blog post of our intentions. We and I will of course love to get your feedback on this and whatever else that is related. We’re also interested to get in touch with people and companies who want to be early testers of our implementation. You know where to find us!
I can promise you that the more interest we can sense to exist for this effort, the sooner we will see the first code to test out.
It seems likely that we’re not going to support any older TLS drafts for QUIC than draft-29.

The Rust team has published a new point release of Rust, 1.44.1. Rust is a programming language that is empowering everyone to build reliable and efficient software.
If you have a previous version of Rust installed via rustup, getting Rust 1.44.1 is as easy as:
rustup update stable
If you don't have it already, you can get rustup from the
appropriate page on our website.
What's in Rust 1.44.1
Rust 1.44.1 addresses several tool regressions in Cargo, Clippy, and Rustfmt introduced in the 1.44.0 stable release. You can find more detailed information on the specific regressions in the release notes.
Contributors to 1.44.1
Many people came together to create Rust 1.44.1. We couldn't have done it without all of you. Thanks!
TLDR: I’m back, everyone.
Yes, I’ve spent the last ten years working on a bachelor’s degree. That’s because I’ve been working full-time as a software engineer, and going to school part-time. It’s long overdue, but California State University, East Bay has just awarded me a bachelor’s of science degree in computer science, with a minor in mathematics and cum laude honors.
With no college debt, to boot.
I held off on posting it here, since CSUEB hadn’t officially confirmed the degree until I logged in and saw it today. There was always an ever-so-slight chance that something would be missed along the way. I owe thanks to a lot of people, including most memorably:
- Dr. Robert Yest, Chabot College
- Professor Jonathan Traugott, Chabot College and CSUEB
- Professor Keith Mehl, Chabot College
- Professor Egl Batchelor, Chabot College
- Dr. Roger Doering, CSUEB
- Dr. Matt Johnson, CSUEB
- Dr. Eddie Reiter, CSUEB
- Dr. Zahra Derakshandeh, CSUEB
I have not yet decided whether to go for a master’s degree. I have decided I need at least a year away from college to recover.
Besides, I’ve already dived into a big project, making Mozilla’s UpdateManager operate asynchronously. This is not easy… but I’m crafting a tool, StackLizard, to help me find all the places where a function must be marked async, its callers await, their enclosing functions async, and so on. Throw XPCOM components into the mix, and it’s going to get deep. But not impossible. I’m basing StackLizard on various tools eslint already uses and supports, in the hope that I can add it to Mozilla’s tool chest as it evolves. (Folding StackLizard into eslint does seem impractical, as eslint operates on individual scripts, and StackLizard will be jumping all over the place.)
I’ll get back to es-membrane and the “Membrane concepts” presentation when I can.
Even in the “before” times, the Firefox UX team was distributed across many different time zones. Some of us already worked remotely from our home offices or co-working spaces. Other team members worked from one of the Mozilla offices around the world.
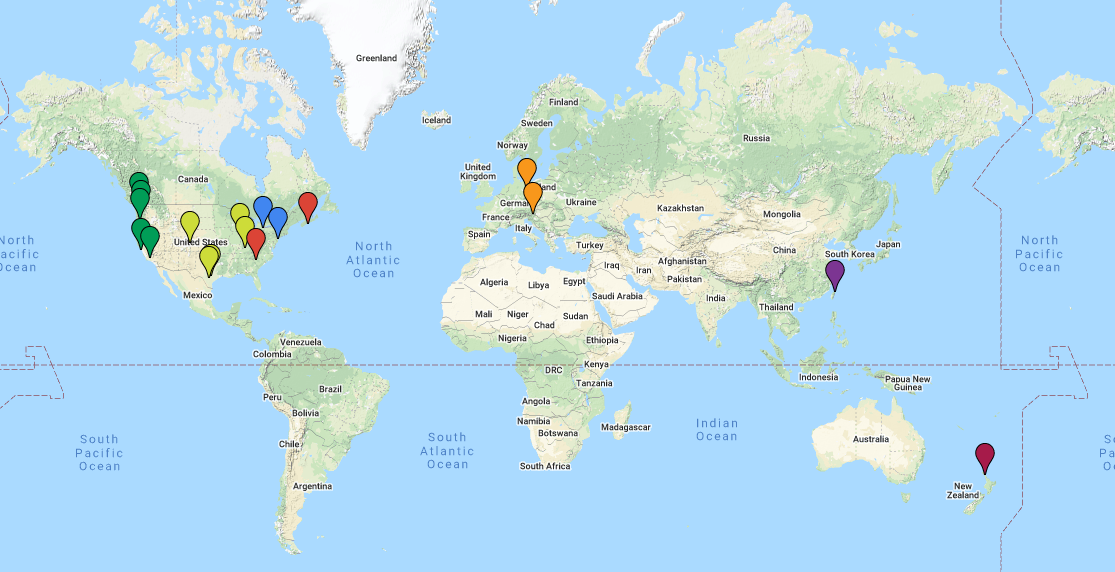
The content strategists, designers, and researchers on the Firefox UX team span many time zones.
That said, remote collaboration still has its challenges. When you’re not in the same room with your teammates — or even the same time zone — problem solving and iterating together might not come as naturally. Don’t get discouraged. It can be done, and done well.
We recently built a prototype for the Firefox Private Network extension. Fast iteration on the current experience was needed to introduce new functionality. The challenge? Our content strategist was based in Chicago, and our interaction designer was 7 hours ahead in Berlin. Here’s how we came together to co-design the prototype despite the time zone challenges.
Align on your goals and working process.
You have a deadline. You have a general idea of what you need to do to get there. You’re enthusiastic and ready to go. But wait! Don’t get started just yet.
First, schedule time with your teammate. Grab a cup of coffee (if you’re Betsy) or espresso (if you’re Emanuela). Talk about how you plan to work together. By building a set of shared expectations at the outset, you can minimize confusion and frustration later.
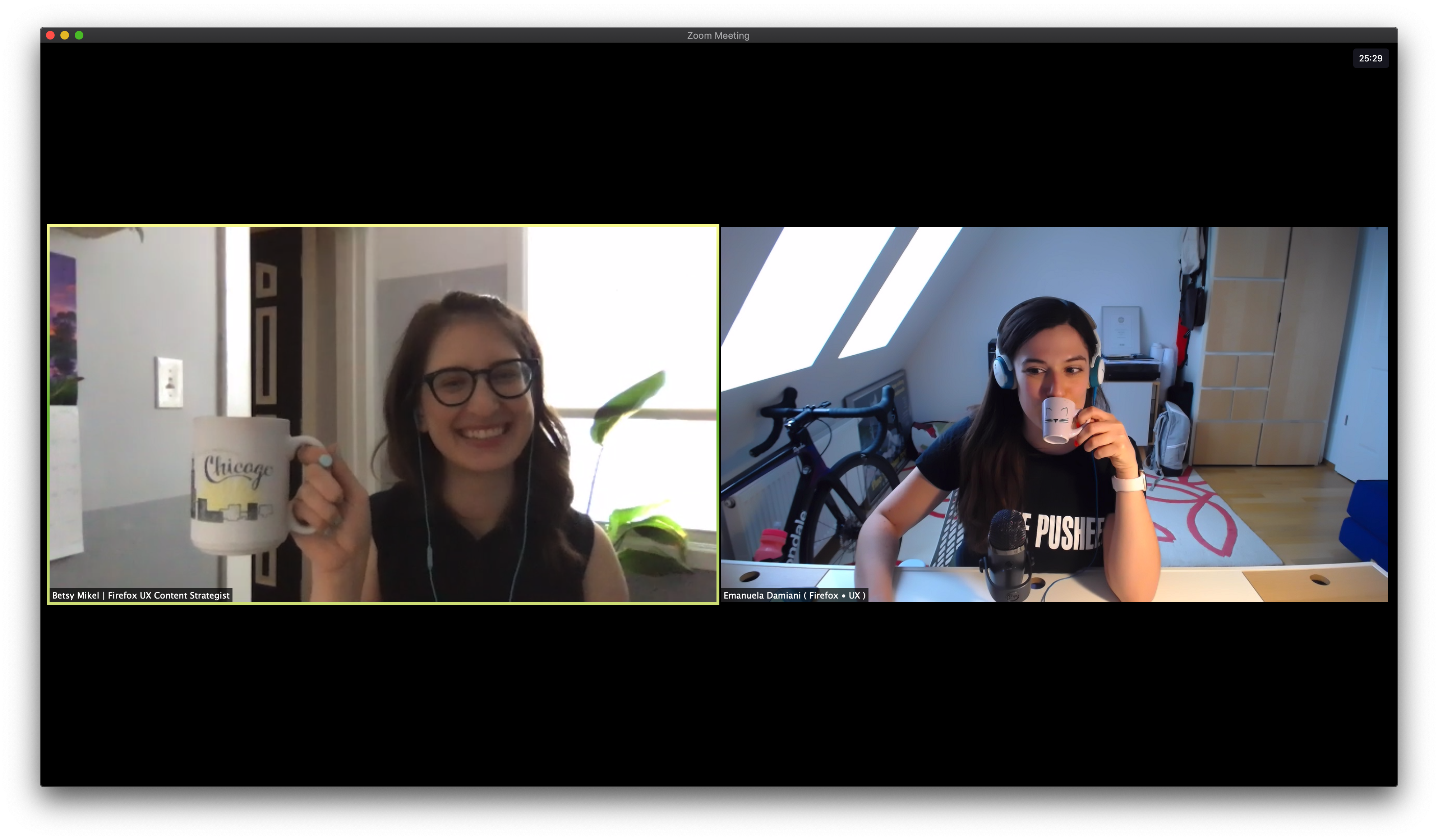
Betsy is just starting her day in Chicago while it’s afternoon for Emanuela in Berlin.
Here are a few questions to help guide this conversation.
- What tools will you use? Is there a shared workspace where you can both contribute?
- When will you converge and diverge? Find times when your working hours overlap so you can have in-person conversations.
- How will you communicate asynchronously? Will you keep a running conversation in Slack? Or leave comments for each other on documents or Miro boards?
- Who will own certain aspects of the work?
Even though we had already worked together, we came up with a set of guidelines to best approach this specific challenge. The important part is that you align as a team about your approach. You can always fine-tune as you go.
The process we defined for our asynchronous collaboration.
Our task was to make significant functionality changes to an existing experience for the Firefox Private Network extension. We agreed on these tools and process.
- We’d use Miro, a collaborative whiteboarding tool.
- Emanuela would place her first iteration of screens on the board, starting with existing copy.
- Betsy would post questions as comments. She would post copy changes as sticky notes.
- If the question could be easily answered, Emanuela would reply and resolve it. If it wasn’t a quick answer, we would discuss it at our next in-person check-in.
- Emanuela would incorporate copy changes and move the sticky notes off the board to signal this task was done.
Now we were ready to get to work!
Share your ideas early and often to build trust.
It’s easy to quickly build trust when you work together in the same physical space. You can better read how the other person is reacting to your ideas. You ideate, sketch, and design together at the same time.
To best replicate this trust building when working independently in different time zones, we used Miro as a shared collaboration workspace. We agreed to put concepts on the board before they truly felt “done.” This allowed us to share our thinking as it evolved and prevented our efforts from becoming too siloed. When each of us started our work day, the board looked a lot different than it had our previous evening.
We could then bounce ideas back and forth, just as we would have done when sitting in the same room sketching together. We each added stickies, product screenshots, and wireframes to visualize our ideas. Content and design were so closely knit throughout that we found ourselves contributing ideas in both domains.
Ask clarifying questions and over-communicate your thinking.
Because there are 7 hours between us, we weren’t always able to work together at the same time. We both did quite a bit of work
Our newest Friend of Add-ons is Juraj M"asiar! Juraj is the developer of several extensions for Firefox, including Scroll Anywhere, which is part of our Recommended Extensions program. He is also a frequent contributor on our community forums, where he offers friendly advice and input for extension developers looking for help.
Juraj first started building extensions for Firefox in 2016 during a quiet weekend trip to his hometown. The transition to the WebExtensions API was less than a year away, and developers were starting to discuss their migration plans. After discovering many of his favorite extensions weren’t going to port to the new API, Juraj decided to try the migration process himself to give a few extensions a second life. “I was surprised to see it’s just normal JavaScript, HTML and CSS — things I already knew,” he says. “I put some code together and just a few moments later I had a working prototype of my ScrollAnywhere add-on. It was amazing!”
Juraj immersed himself in exploring the WebExtensions API and developing extensions for Firefox. It wasn’t always a smooth process, and he’s eager to share some tips and tricks to make the development experience easier and more efficient. “Split your code to ES6 modules. Share common code between your add-ons — you can use `git submodule` for that. Automate whatever can be automated. If you don’t know how, spend the time learning how to automate it instead of doing it manually,” he advises. Developers can also save energy by not reinventing the wheel. “If you need a build script, use webpack. Don’t build your own DOM handling library. If you need complex UI, use existing libraries like Vue.js.”
Juraj recommends staying active, saying. “Doing enough sport every day will keep your mind fresh and ready for new challenges.” He stays active by playing VR games and rollerblading.
Currently, Juraj is experimenting with the CryptoAPI and testing it with a new extension that will encrypt user notes and synchronize them with Firefox Sync. The goal is to create a secure extension that can be used to store sensitive material, like a server configuration or a home wifi password.
On behalf of the Add-ons Team, thank you for all of your wonderful contributions to our community, Juraj!
If you are interested in getting involved with the add-ons community, please take a look at our current contribution opportunities.
The post Friend of Add-ons: Juraj M"asiar appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2020/06/15/friend-of-add-ons-juraj-masiar/
This is just some quick notes (for myself) of how I recently setup my Raspberry Pi as a file server. The goal was to have a shared folder so that a Sonos could play music from it. The data would be backed via a microSD card plugged into USB.
- Update …
https://patrick.cloke.us/posts/2020/06/12/raspberry-pi-file-server/
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean. You can find an index of all TWiG posts online.)
It’s been a while since last I wrote on Project FOG, so I figure I should update all of you on the progress we’ve made.
A reminder: Project FOG (Firefox on Glean) is the year-long effort to bring the Glean SDK to Firefox. This means answering such varied questions as “Where are the docs going to live?” (here) “How do we update the SDK when we need to?” (this way) “How are tests gonna work?” (with difficulty) and so forth. In a project this long you can expect updates from time-to-time. So where are we?
First, we’ve added the Glean SDK to Firefox Desktop and include it in Firefox Nightly. This is only a partial integration, though, so the only builtin ping it sends is the “deletion-request” ping when the user opts out of data collection in the Preferences. We don’t actually collect any data, so the ping doesn’t do anything, but we’re sending it and soon we’ll have a test ensuring that we keep sending it. So that’s nice.
Second, we’ve written a lot of Design Proposals. The Glean Team and all the other teams our work impacts are widely distributed across a non-trivial fragment of the globe. To work together and not step on each others’ toes we have a culture of putting most things larger than a bugfix into Proposal Documents which we then pass around asynchronously for ideation, feedback, review, and signoff. For something the size and scope of adding a data collection library to Firefox Desktop, we’ve needed more than one. These design proposals are Google Docs for now, but will evolve to in-tree documentation (like this) as the proposals become code. This way the docs live with the code and hopefully remain up-to-date for our users (product developers, data engineers, data scientists, and other data consumers), and are made open to anyone in the community who’s interested in learning how it all works.
Third, we have a Glean SDK Rust API! Sorta. To limit scope creep we haven’t added the Rust API to mozilla/glean and are testing its suitability in FOG itself. This allows us to move a little faster by mixing our IPC implementation directly into the API, at the expense of needing to extract the common foundation later. But when we do extract it, it will be fully-formed and ready for consumers since it’ll already have been serving the demanding needs of FOG.
Fourth, we have tests. This was a bit of a struggle as the build order of Firefox means that any Rust code we write that touches Firefox internals can’t be tested in Rust tests (they must be tested by higher-level integration tests instead). By damming off the Firefox-adjacent pieces of the code we’ve been able to write and run Rust tests of the metrics API after all. Our code coverage is still a
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean. You can find an index of all TWiG posts online.)
It’s been a while since last I wrote on Project FOG, so I figure I should update all of you on the progress we’ve made.
A reminder: Project FOG (Firefox on Glean) is the year-long effort to bring the Glean SDK to Firefox. This means answering such varied questions as “Where are the docs going to live?” (here) “How do we update the SDK when we need to?” (this way) “How are tests gonna work?” (with difficulty) and so forth. In a project this long you can expect updates from time-to-time. So where are we?
First, we’ve added the Glean SDK to Firefox Desktop and include it in Firefox Nightly. This is only a partial integration, though, so the only builtin ping it sends is the “deletion-request” ping when the user opts out of data collection in the Preferences. We don’t actually collect any data, so the ping doesn’t do anything, but we’re sending it and soon we’ll have a test ensuring that we keep sending it. So that’s nice.
Second, we’ve written a lot of Design Proposals. The Glean Team and all the other teams our work impacts are widely distributed across a non-trivial fragment of the globe. To work together and not step on each others’ toes we have a culture of putting most things larger than a bugfix into Proposal Documents which we then pass around asynchronously for ideation, feedback, review, and signoff. For something the size and scope of adding a data collection library to Firefox Desktop, we’ve needed more than one. These design proposals are Google Docs for now, but will evolve to in-tree documentation (like this) as the proposals become code. This way the docs live with the code and hopefully remain up-to-date for our users (product developers, data engineers, data scientists, and other data consumers), and are made open to anyone in the community who’s interested in learning how it all works.
Third, we have a Glean SDK Rust API! Sorta. To limit scope creep we haven’t added the Rust API to mozilla/glean and are testing its suitability in FOG itself. This allows us to move a little faster by mixing our IPC implementation directly into the API, at the expense of needing to extract the common foundation later. But when we do extract it, it will be fully-formed and ready for consumers since it’ll already have been serving the demanding needs of FOG.
Fourth, we have tests. This was a bit of a struggle as the build order of Firefox means that any Rust code we write that touches Firefox internals can’t be tested in Rust tests (they must be tested by higher-level integration tests instead). By damming off the Firefox-adjacent pieces of the code we’ve been able to write and run Rust tests of the metrics API after all. Our code
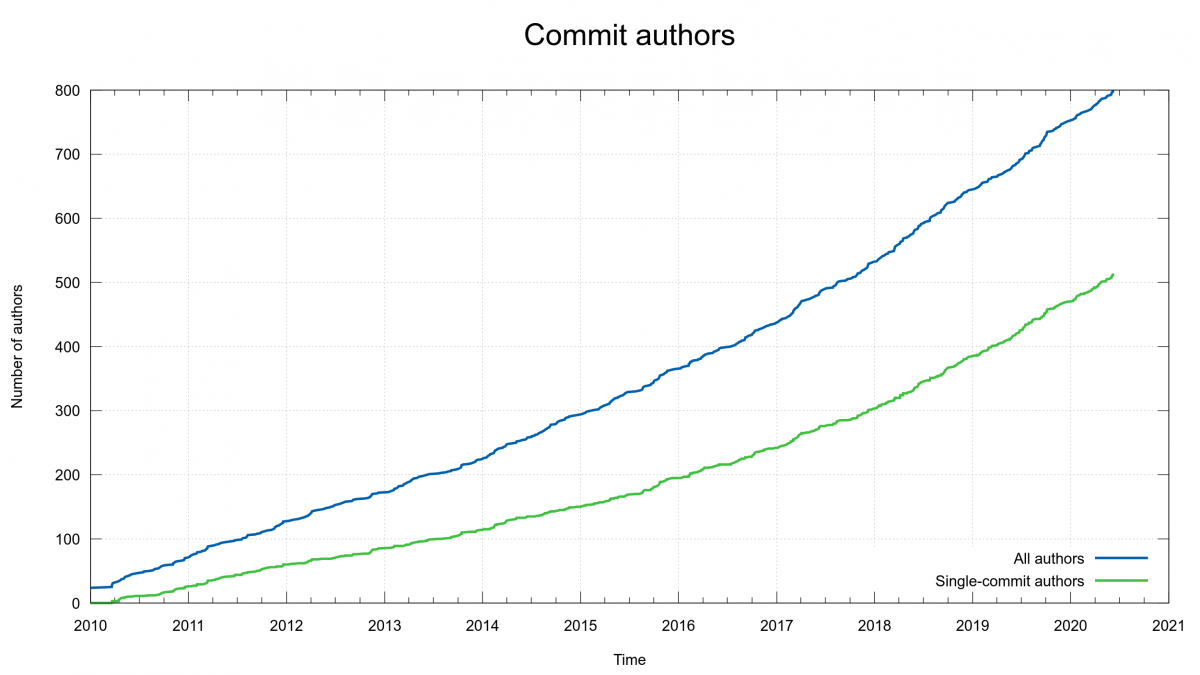
Today marks the day when we merged the commit authored by the 800th person in the curl project.
We turned 22 years ago this spring but it really wasn’t until 2010 when we switched to git when we started to properly keep track of every single author in the project. Since then we’ve seen a lot of new authors and a lot of new code.
The “explosion” is clearly visible in this graph generated with fresh data just this morning (while we were still just 799 authors). See how we’ve grown maybe 250 authors since 1 Jan 2018.
Author number 800 is named Nicolas Sterchele and he submitted an update of the TODO document. Appreciated!
As the graph above also shows, a majority of all authors only ever authored a single commit. If you did 10 commits in the curl project, you reach position #61 among all the committers while 100 commits takes you all the way up to position #13.
Become one!
If you too want to become one of the cool authors of curl, I fine starting point for that journey could be the Help Us document. If that’s not enough, you’re also welcome to contact me privately or maybe join the IRC channel for some socializing and “group mentoring”.
If we keep this up, we could reach a 1,000 authors in 2022…
https://daniel.haxx.se/blog/2020/06/12/800-authors-and-counting/