A browser is an incredibly complex piece of software. With such enormous complexity, the only way to maintain a rapid pace of development is through an extensive CI system that can give developers confidence that their changes won’t introduce bugs. Given the scale of our CI, we’re always looking for ways to reduce load while maintaining a high standard of product quality. We wondered if we could use machine learning to reach a higher degree of efficiency.
Continuous integration at scale
At Mozilla we have around 50,000 unique test files. Each contain many test functions. These tests need to run on all our supported platforms (Windows, Mac, Linux, Android) against a variety of build configurations (PGO, debug, ASan, etc.), with a range of runtime parameters (site isolation, WebRender, multi-process, etc.).
While we don’t test against every possible combination of the above, there are still over 90 unique configurations that we do test against. In other words, for each change that developers push to the repository, we could potentially run all 50k tests 90 different times. On an average work day we see nearly 300 pushes (including our testing branch). If we simply ran every test on every configuration on every push, we’d run approximately 1.35 billion test files per day! While we do throw money at this problem to some extent, as an independent non-profit organization, our budget is finite.
So how do we keep our CI load manageable? First, we recognize that some of those ninety unique configurations are more important than others. Many of the less important ones only run a small subset of the tests, or only run on a handful of pushes per day, or both. Second, in the case of our testing branch, we rely on our developers to specify which configurations and tests are most relevant to their changes. Third, we use an integration branch.
Basically, when a patch is pushed to the integration branch, we only run a small subset of tests against it. We then periodically run everything and employ code sheriffs to figure out if we missed any regressions. If so, they back out the offending patch. The integration branch is periodically merged to the main branch once everything looks good.
 A subset of the tasks we run on a single mozilla-central push. The full set of tasks were too hard to distinguish when scaled to fit in a single image.
A subset of the tasks we run on a single mozilla-central push. The full set of tasks were too hard to distinguish when scaled to fit in a single image.
A new approach to efficient testing
These methods have served us well for many years, but it turns out they’re still very expensive. Even with all of these optimizations our CI still runs around 10 compute years per day! Part of the problem is that we have been using a naive heuristic to choose which tasks to run on the integration branch. The heuristic ranks tasks based on how frequently they have failed in the past. The ranking is unrelated to the contents of the patch. So a push that modifies a README file would run the same tasks as a push that turns on site isolation. Additionally, the responsibility for determining which tests and configurations to run on the testing branch has shifted over to the developers themselves. This wastes their valuable time and tends towards over-selection of tests.
About a year ago, we started asking ourselves: how can we do better? We realized that the current implementation of our CI relies heavily on human intervention. What if we could instead correlate patches to tests using historical regression data? Could we use a machine learning algorithm to figure out the optimal set of tests to run? We hypothesized that we could simultaneously save money by running fewer tests, get results faster, and reduce the cognitive burden on developers. In the process, we would build out the infrastructure necessary to keep our CI pipeline running efficiently.
Having fun with historical
On Desktop, I'm very often in a situation where I want to read a long article in a browser tab with a certain number of hypertext links. The number of actions I have to do to properly read the text is tedious. It's prone to errors, requires a bit of preparation and has a lot of manual actions.
The Why?
Take for example this article about The End of Tourism. There are multiple ways to read it.
- We can read the text only.
- We can click on each invidiual link when we reach it to open in the background tab, that we will check later.
- We can click, read and come back to the main article.
- We can open a new window and drag and drop the link to this new window.
- We can ctrl+click in a new tab or a new window and then go to the context of this tab and window.
We can do better.
Having the possibility to read contextual information is useful for having a better understanding of the current article we are reading. Making this process accessible with only one click without losing the initial context would be tremendous.
What I Want: Tab Splitting For Contextual Reading
The "open a new window + link drag and drop" model of interactions is the closest of what I would like as a feature for reading things with hypertext links, but it's not practical.
- I want to be able to switch my current tab in a split tab either horizontally or vertically.
- Once the tab is in split mode. The first part is the current article, I'm reading. The second part is blank.
- Each time I'm clicking on a link in the first part (current article), it loads the content of the link in the second part.
- If I find that I want to keep the second part, I would be able to extract it in a new tab or new window.
This provides benefits for reading long forms with a lot of hypertext links. But you can imagine also how practical it could become for code browsing sites. It would create a very easy way to access another part of the code for contextual information or documentation.
There's nothing new required in terms of technologies to implement this. This is just browser UI manipulation and in which context to display a link.
Otsukare!
https://www.otsukare.info/2020/07/09/split-tab-contextual-reading
The Malaysian government’s decision to initiate criminal contempt proceedings against Malaysiakini for third party comments on the news portal’s website is deeply concerning. The move sets a dangerous precedent against intermediary liability and freedom of expression. It ignores the internationally accepted norm that holding publishers responsible for third party comments has a chilling effect on democratic discourse. The legal outcome the Malaysian government is seeking would upend the careful balance which places liability on the bad actors who engage in illegal activities, and only holds companies accountable when they know of such acts.
Intermediary liability safe harbour protections have been fundamental to the growth of the internet. They have enabled hosting and media platforms to innovate and flourish without the fear that they would be crushed by a failure to police every action of their users. Imposing the risk of criminal liability for such content would place a tremendous, and in many cases fatal, burden on many online intermediaries while negatively impacting international confidence in Malaysia as a digital destination.
We urge the Malyasian government to drop the proceedings and hope the Federal Court of Malaysia will meaningfully uphold the right to freedom of expression guaranteed by Malaysia’s Federal Constitution.
The post Criminal proceedings against Malaysiakini will harm free expression in Malaysia appeared first on Open Policy & Advocacy.
When an add-on is submitted to Firefox for validation, the add-ons linter checks its code and displays relevant errors, warnings, or friendly messages for the developer to review. JavaScript is constantly evolving, and when the linter lags behind the language, developers may see syntax errors for code that is generally considered acceptable. These errors block developers from getting their add-on signed or listed on addons.mozilla.org.

On July 2, the linter was updated from ESLint 5.16 to ESLint 7.3 for JavaScript validation. This upgrades linter support to most ECMAScript 2020 syntax, including features like optional chaining, BigInt, and dynamic imports. As a quick note, the linter is still slightly behind what Firefox allows. We will post again in this blog the next time we make an update.
Want to help us keep the linter up-to-date? We welcome code contributions and encourage developers to report bugs found in our validation process.
The post Additional JavaScript syntax support in add-on developer tools appeared first on Mozilla Add-ons Blog.
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
Check out this week's This Week in Rust Podcast
Updates from Rust Community
News & Blog Posts
- Announcing Rustup 1.22.0
- Ownership of the standard library implementation
- Compiler Team 2020-2021 Roadmap Meeting Minutes
- Back to old tricks ..(or, baby steps in Rust)
- Small strings in Rust
- Choosing a Rust web framework, 2020 edition
- Writing Interpreters in Rust: a Guide
- Transpiling A Kernel Module to Rust: The Good, the Bad and the Ugly
- Bad Apple!! and how I wrote a Rust video player for Task Manager!!
- Boa release v0.9 and make use of Rust's measureme
- RiB (Rust in Blockchain) Newsletter #13
- 7 Things I learned from Porting a C Crypto Library to Rust
- This Month in Rust GameDev #11 (June 2020)
- AWS Lambda with Rust
- Writing a winning 4K intro in Rust
- Ringbahn II: the central state machine
- Bastion floating on Tide - Part 2
- Porting Godot Games To Rust (Part 1)
- Image decay as a service
- IntelliJ Rust Changelog #125
- Abstracting away correctness
- Rendering in Rust
- Super hero Rust fuzzing
- What Is a Dangling Pointer?
- Simple Rocket Web Framework Tutorial | POST Request
- Adventures of OS - System Calls
- Allocation API, Allocators and Virtual Memory
The rustup working group is happy to announce the release of rustup version 1.22.1. Rustup is the recommended tool to install Rust, a programming language that is empowering everyone to build reliable and efficient software.
If you have a previous version of rustup installed, getting rustup 1.22.1 may be as easy as closing your IDE and running:
rustup self update
Rustup will also automatically update itself at the end of a normal toolchain update:
rustup update
If you don't have it already, or if the 1.22.0 release of rustup caused you to experience the problem that 1.22.1 fixes, you can get rustup from the appropriate page on our website.
What's new in rustup 1.22.1
When updating dependency crates for 1.22.0, a change in behaviour of the url crate slipped in which caused env_proxy to cease to work with proxy data set in the environment. This is unfortunate since those of you who use rustup behind a proxy and have updated to 1.22.0 will now find that rustup may not work properly for you.
If you are affected by this, simply re-download the installer and run it. It will update your existing installation of Rust with no need to uninstall first.
Thanks
Thanks to Ivan Nejgebauer who spotted the issue, provided the fix, and made rustup 1.22.1 possible, and to Ben Chen who provided a fix for our website.
Firefox for Android Nightly (formerly known as Firefox Preview) is a sneak peek of the new Firefox for Android experience. The browser is being rebuilt based on GeckoView, an embeddable component for Android, and we are continuing to gradually roll out extension support.
Including the add-ons from our last announcement, there are currently nine Recommended Extensions available to users. The latest three additions are in Firefox for Android Nightly and will be available on Firefox for Android Beta soon:
Decentraleyes prevents your mobile device from making requests to content delivery networks (i.e. advertisers), and instead provides local copies of common libraries. In addition to the benefit of increased privacy, Decentraleyes also reduces bandwidth usage—a huge benefit in the mobile space.
Privacy Possum has a unique approach to dealing with trackers. Instead of playing along with the cat and mouse game of removing trackers, it falsifies the information trackers used to create a profile of you, in addition to other anti-tracking techniques.
Youtube High Definition gives you more control over how videos are displayed on Youtube. You have the opportunity to set your preferred visual quality option and have it shine on your high-DPI device, or use a lower quality to save bandwidth.If you have more questions on extensions in Firefox for Android Nightly, please check out our FAQ. We will be posting further updates about our future plans on this blog.
The post New Extensions in Firefox for Android Nightly (Previously Firefox Preview) appeared first on Mozilla Add-ons Blog.
Each time, when asking around you how many tabs are opened in the current desktop browser session, most people will have around per session (July 2020):
- Release: 4 tabs (median) and 8 tabs (mean)
- Nightly: 4 tabs (median) and 51 tabs (mean)
(Having a graph of the full distribution would be interesting here.)
It would be interesting to see the exact distribution, because there is a cohort with a very high number of tabs. I have usually in between 300 and 500 tabs opened. And sometimes I'm cleaning up everything. But after an internal discussion at Mozilla, I realized some people had even more toward a couple of thousand tabs opened at once.
While we are not the sheer majority, we are definitely a group of people probably working with browsers intensively and with specific needs that the browsers currently do not address. Also we have to be careful with these stats which are auto-selecting group of people. If there's nothing to manage a high number of tabs, it is then likely that there will not be a lot of people ready to painstakly manage a high number of tabs.
The Why?
I use a lot of tabs.
But if I turn my head to my bookshelf, there are probably around 2000+ books in there. My browser is a bookshelf or library of content and a desk. But one which is currently not very good at organizing my content. I keep tabs opened
- to access reference content (articles, guidebook, etc)
- to talk about it later on with someone else or in a blog post
- to have access to tasks (opening 30 bugs I need to go through this week)
I sometimes open some tabs twice. I close by mistake a tab without realizing and then when I search the content again I can't find it. I can't do a full text search on all open tabs. I can only manage the tabs vertically with an addon (right now I'm using Tabs Center Redux). And if by any bad luck, we are offline and the tabs had not been navigated beforehand, we loose the full content we needed.
So I’m often grumpy at my browser.
What I want: Content Management
Here I will be focusing on my own use case and needs.
What I would love is an “Apple Time Machine”-like for my browser, aka dated archives of my browsing session, with full text search.
- Search through text keyword all tabs content, not only the title.
- Possibility to filter search queries with time and uri. "Search this keyword only on wikipedia pages opened less than one week ago"
- Tag tabs to create collections of content.
- Archive the same exact uri at different times. Imagine the homepage of the NYTimes at different dates or times and keeping each version locally. (Webarchive is incomplete and online, I want it to work offline).
- The storage format doesn't need to be the full stack of technologies of the current page. Opera Mini for example is using a format which is compressing the page as a more or less interactive image with limited capabilities.
- You could add automation with an automatic backup of everything you are browsing, or have the possibility to manually select the pages you want to keep (like when you decide to pin a tab)
- If the current computer doesn't have enough storage for your needs, an encrypted (paid) service could be provided where you would specify which page you want to be archived away and the ones that you want to keep locally.
Firefox becomes a portable bookshelf and the desk with the piles of papers you are working on.
Browser Innovation
Innovation in browsers don't have to be only about supported technologies, but also about features of the browser itself. I have the feeling that we have dropped the ball on many things, as we race to be transparent with regards to websites and applications. Allowing technologies giving tools to web developers to create cool things is certainly very useful, but making a browser more useful for the immediate users is as much important. I don't want the browser to disappear in this mediating UI, I want it to give me more ways to manage and mitigate my interactions with the Web.
Slightly Related
Open tabs are cognitive spaces by Michail Rybakov.
It is time we stop treating websites as something solitary and alien to us. Web pages that we visit and leave open are artifacts of externalized cognition; keys to thinking and remembering.
The browser of today is a transitory space that brings us into a mental state, not just to a specific website destination. And we should design our browsers for
Last year, the accessibility team worked to identify and fix gaps in our screen reader support, as well as on some new areas of focus, like improving Firefox for users with low vision. As a result, we shipped some great features. In addition, we’ve begun building awareness across Mozilla and putting in place processes to help ensure delightful accessibility going forward, including a Firefox wide triage process.
With a solid foundation for delightful accessibility well underway, we’re looking at the next step in broadening our impact: expanding our engagement with our passionate, global community. It’s our hope that we can get to a place where a broad community of interested people become active participants in the planning, design, development and testing of Firefox accessibility. To get there, the first step is open communication about what we’re doing and where we’re headed.
To that end, we’ve created this blog to keep you all informed about what’s going on with Firefox accessibility. As a second step, we’ve published the Firefox Accessibility Roadmap. This document is intended to communicate our ongoing work, connecting the dots from our aspirations, as codified in our Mission and Manifesto, through our near term strategy, right down to the individual work items we’re tackling today. The roadmap will be updated regularly to cover at least the next six months of work and ideally the next year or so.
Another significant area of new documentation, pushed by Eitan and Morgan, is around our ongoing work to bring VoiceOver support to Firefox on macOS. In addition to the overview wiki page, which covers our high level plan and specific lists of bugs we’re targeting, there’s also a work in progress architectural overview and a technical guide to contributing to the Mac work.
We’ve also transitioned most of our team technical discussions from a closed Mozilla Slack to the open and participatory Matrix instance. Some exciting conversations are already happening and we hope that you’ll join us.
And that’s just the beginning. We’re always improving our documentation and onboarding materials so stay tuned to this channel for updates. We hope you find access to the team and the documents useful and that if something in our docs calls out to you that you’ll find us on Matrix and help out, whether that’s contributing ideas for better solutions to problems we’re tackling, writing code for features and fixes we need, or testing the results of development work.
We look forward to working with you all to make the Firefox family of products and services the best they can be, a delight to use for everyone, especially people with disabilities.
The post Broadening Our Impact appeared first on Mozilla Accessibility.
https://blog.mozilla.org/accessibility/broadening-our-impact/
Two years ago we first brought Mozilla v. FCC in federal court, in an effort to save the net neutrality rules protecting American consumers. Mozilla has long fought for net neutrality because we believe that the internet works best when people control their own online experiences.
Today is the deadline to petition the Supreme Court for review of the D.C. Circuit decision in Mozilla v. FCC. After careful consideration, Mozilla—as well as its partners in this litigation—are not seeking Supreme Court review of the D.C. Circuit decision. Even though we did not achieve all that we hoped for in the lower court, the court recognized the flaws of the FCC’s action and sent parts of it back to the agency for reconsideration. And the court cleared a path for net neutrality to move forward at the state level. We believe the fight is best pursued there, as well as on other fronts including Congress or a future FCC.
Net neutrality is more than a legal construct. It is a reflection of the fundamental belief that ISPs have tremendous power over our online experiences and that power should not be further concentrated in actors that have often demonstrated a disregard for consumers and their digital rights. The global pandemic has moved even more of our daily lives—our work, school, conversations with friends and family—online. Internet videos and social media debates are fueling an essential conversation about systemic racism in America. At this moment, net neutrality protections ensuring equal treatment of online traffic are critical. Recent moves by ISPs to favor their own content channels or impose data caps and usage-based pricing make concerns about the need for protections all the more real.
The fight for net neutrality will continue on. The D.C. Circuit decision positions the net neutrality movement to continue on many fronts, starting with a defense of California’s strong new law to protect consumers online—a law that was on hold pending resolution of this case.
Other states have followed suit and we expect more to take up the mantle. We will look to a future Congress or future FCC to take up the issue in the coming months and years. Mozilla is committed to continuing our work, with our broad community of allies, in this movement to defend the web and consumers and ensure the internet remains open and accessible to all.
The post Next Steps for Net Neutrality appeared first on Open Policy & Advocacy.
https://blog.mozilla.org/netpolicy/2020/07/06/next-steps-for-net-neutrality/
Cryptographic primitives, while extremely complex and difficult to implement, audit, and validate, are critical for security on the web. To ensure that NSS (Network Security Services, the cryptography library behind Firefox) abides by Mozilla’s principle of user security being fundamental, we’ve been working with Project Everest and the HACL* team to bring formally-verified cryptography into Firefox.
In Firefox 57, we introduced formally-verified Curve25519, which is a mechanism used for key establishment in TLS and other protocols. In Firefox 60, we added ChaCha20 and Poly1305, providing high-assurance authenticated encryption. Firefox 69, 77, and 79 improve and expand these implementations, providing increased performance while retaining the assurance granted by formal verification.
Performance & Specifics
For key establishment, we recently replaced the 32-bit implementation of Curve25519 with one from the Fiat-Crypto project. The arbitrary-precision arithmetic functions of this implementation are proven to be functionally correct, and it improves performance by nearly 10x over the previous code. Firefox 77 updates the 64-bit implementation with new HACL* code, benefitting from a ~27% speedup. Most recently, Firefox 79 also brings this update to Windows. These improvements are significant: Telemetry shows Curve25519 to be the most widely used elliptic curve for ECDH(E) key establishment in Firefox, and increased throughput reduces energy consumption, which is particularly important for mobile devices.
 64-bit Curve25519 with HACL* |
 32-bit Curve25519 with Fiat-Crypto |
For encryption and decryption, we improved the performance of ChaCha20-Poly1305 in Firefox 77. Throughput is doubled by taking advantage of vectorization with 128-bit and 256-bit integer arithmetic (via the AVX2 instruction set on x86-64 CPUs). When these features are unavailable, NSS will fall back to an AVX or scalar implementation, both of which have been further optimized.

ChaCha20-Poly1305 with HACL* and AVX2
The HACL* project has introduced new techniques and libraries to improve efficiency in writing verified primitives for both scalar and vectorized variants. This allows aggressive code sharing and reduces the verification effort across many different platforms.
What’s Next?
For Firefox 81, we intend to incorporate a formally-verified implementation of the P256 elliptic curve for ECDSA and ECDH. Middle-term targets for verified implementations include GCM, the P384 and P521 elliptic curves, and the ECDSA signature scheme itself. While there remains work to be done, these updates provide an improved user experience and ease the implementation burden for future inclusion of platform-optimized primitives.
The post Performance
Just like so many other antivirus applications, BullGuard antivirus promises to protect you online. This protection consists of the three classic components: protection against malicious websites, marking of malicious search results and BullGuard Secure Browser for your special web surfing needs. As so often, this functionality comes with issues of its own, some being unusually obvious.

Contents
Summary of the findings
The first and very obvious issue was found in the protection against malicious websites. While this functionality often cannot be relied upon, circumventing it typically requires some effort. Not so with BullGuard Antivirus: merely adding a hardcoded character sequence to the address would make BullGuard ignore a malicious domain.
Further issues affected BullGuard Secure Browsers: multiple Cross-Site Scripting (XSS) vulnerabilities in its user interface potentially allowed websites to spy on the user or crash the browser. The crash might be exploitable for Remote Code Execution (RCE). Proper defense in depth prevented worse here.
Online protection approach
BullGuard Antivirus listens in on all connections made by your computer. For some of these connections it will get between the server and the browser in order to manipulate server responses. That’s especially the case for malicious websites of course, but the server response for search pages will also be manipulated in order to indicate which search results are supposed to be trustworthy.
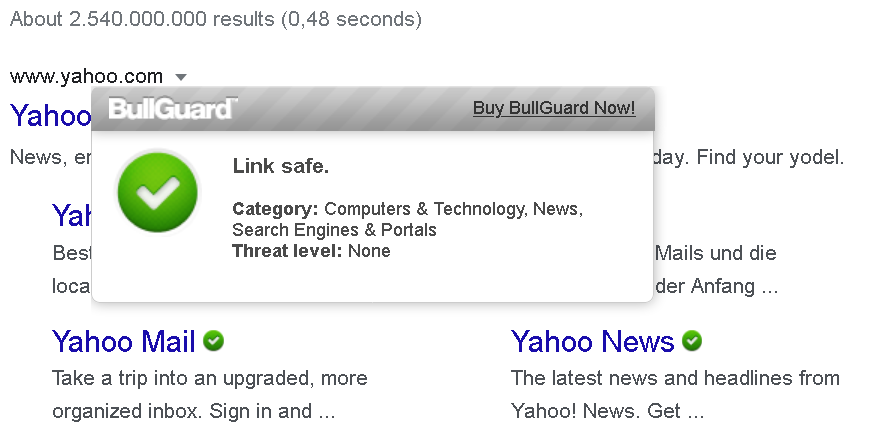
To implement this pop-up, the developers used an interesting trick: connections to port 3220 will always be redirected to the antivirus application, no matter which domain. So navigating to http://www.yahoo.com:3220/html?eWFob28uY29t will yield the following response:
The Firefox UX book club comes together a few times a year to discuss books related to the user experience practice. We recently welcomed authors Michael Metts and Andy Welfle to discuss their book Writing is Designing: Words and the User Experience (Rosenfeld Media, Jan. 2020).

To make the most of our time, we collected questions from the group beforehand, organized them into themes, and asked people to upvote the ones they were most interested in.
An overview of Writing is Designing
“In many product teams, the words are an afterthought, and come after the “design,” or the visual and experiential system. It shouldn’t be like that: the writer should be creating words as the rest of the experience is developed. They should be iterative, validated with research, and highly collaborative. Writing is part of the design process, and writers are designers.” — Writing is Designing
Andy and Michael kicked things off with a brief overview of Writing is Designing. They highlighted how writing is about fitting words together and design is about solving problems. Writing as design brings the two together. These activities — writing and designing — need to be done together to create a cohesive user experience.
They reiterated that effective product content must be:
- Usable: It makes it easier to do something. Writing should be clear, simple, and easy.
- Useful: It supports user goals. Writers need to understand a product’s purpose and their audience’s needs to create useful experiences.
- Responsible: What we write can be misused by people or even algorithms. We must take care in the language we use.
We then moved onto Q&A which covered these themes and ideas.
On writing a book that’s not just for UX writers
“Even if you only do this type of writing occasionally, you’ll learn from this book. If you’re a designer, product manager, developer, or anyone else who writes for your users, you’ll benefit from it. This book will also help people who manage or collaborate with writers, since you’ll get to see what goes into this type of writing, and how it fits into the product design and development process.” — Writing is Designing
You don’t have to be a UX writer or content strategy to benefit from Writing Is Designing. The book includes guidance for anyone involved in creating content for a user experience, including designers, researchers, engineers, and product managers. Writing is just as much of a design tool as Sketch or Figma—it’s just that the material is words not pixels.
When language perpetuates racism
“The more you learn and the more you are able to engage in discussions about racial justice, the more you are able to see how it impacts everything we do. Not questioning systems can lead to perpetuating injustice. It starts with our workplaces. People are having important conversations and questioning things that already should have been questioned.” — Michael Metts
Given the global focus on racial justice issues, it wasn’t surprising that we spent a good part of our time discussing how the conversation intersects with our day-to-day work.
Andy talked about the effort at Adobe, where he is the UX Content Strategy Manager, to expose racist terminology in its products, such as ‘master-slave’ and ‘whitelist-blacklist’ pairings. It’s not just about finding a neutral replacement term that appears to users in the interface, but rethinking how we’ve defined these terms and underlying structures entirely in our code.
Moving beyond anti-racist language
“We need to focus on who we are doing this for. We worry what we look like and that we’re doing the right thing. And that’s not the priority. The goal is to dismantle harmful systems. It’s important for white people to get away from your own feelings of wanting to look good. And focus on who you are doing it for and making it a better world for those people.” — Michael Metts
Beyond the language that appears in our products, Michael encouraged the group to educate themselves, follow Black writers and designers, and be open and willing to change. Any effective UX practitioner needs to approach their work with a sense of humility and openness to being wrong.
Supporting racial justice and the Black Lives Matter movement must also include raising long-needed conversations in the workplace, asking tough questions, and sitting with discomfort. Michael recommended reading
A week ago Saturday morning co-organizer Chris Aldrich opened IndieWebCamp West and introduced the keynote speakers. After their inspiring talks he asked me to say a few words about changes we’re making in the IndieWeb community around organizing. This is an edited version of those words, rewritten for clarity and context. — Tantek
Chris mentioned that one of his favorite parts of our code of conduct is that we prioritize marginalized people’s safety above privileged folks’s comfort.
That was a change we deliberately made last year, announced at last year’s summit. It was well received, but it’s only one minor change.
Those of us that have organized and have been organizing our all-volunteer IndieWebCamps and other IndieWeb events have been thinking a lot about the events of the past few months, especially in the United States. We met the day before IndieWebCamp West and discussed our roles in the IndieWeb community and what can we do to to examine the structural barriers and systemic racism and or sexism that exists even in our own community. We have been asking, what can we do to explicitly dismantle those?
We have done a bunch of things. Rather, we as a community have improved things organically, in a distributed way, sharing with each other, rather than any explicit top-down directives. Some improvements are smaller, such as renaming things like whitelist & blacklist to allowlist & blocklist (though we had documented blocklist since 2016, allowlist since this past January, and only added whitelist/blacklist as redirects afterwards).
Many of these changes have been part of larger quieter waves already happening in the technology and specifically open source and standards communities for quite some time. Waves of changes that are now much more glaringly obviously important to many more people than before. Choosing and changing terms to reinforce our intentions, not legacy systemic white supremacy.
Part of our role & responsibility as organizers (as anyone who has any power or authority, implied or explicit, in any organization or community), is to work to dismantle any aspect or institution or anything that contributes to white supremacy or to patriarchy, even in our own volunteer-based community.
We’re not going to get everything right. We’re going to make mistakes. An important part of the process is acknowledging when that happens, making corrections, and moving forward; keep listening and keep learning.
The most recent change we’ve made has to do with Organizers Meetups that we have been doing for several years, usually a half day logistics & community issues meeting the day before an IndieWebCamp. Or Organizers Summits a half day before our annual IndieWeb Summits; in 2019 that’s when we made that aforementioned update to our Code of Conduct to prioritize marginalized people’s safety.
Typically we have asked people to have some experience with organizing in order to participate in organizers meetups. Since the community actively helps anyone who wants to put in the work to become an organizer, and provides instructions, guidelines, and tips for successfully doing so, this seemed like a reasonable requirement. It also kept organizers meetups very focused on both pragmatic logistics, and dedicated time for continuous community improvement, learning from other events and our own IndieWebCamps, and improving future IndieWebCamps accordingly.
However, we must acknowledge that our community, like a lot of online, open communities, volunteer communities, unfortunately reflects a very privileged demographic. If you look at the photos from Homebrew Website Clubs, they’re mostly white individuals, mostly male, mostly apparently cis. Mostly white cis males. This does not represent the users of the Web. For that matter, it does not represent the demographics of the society we're in.
One of our ideals, I believe, is to better reflect in the IndieWeb community, both the demographic of everyone that uses the Web, and ideally, everyone in society. While we don't expect to solve all the problems of the Web (or society) by ourselves, we believe we can take steps towards dismantling white supremacy and patriarchy where we encounter them.
One step we are taking, effective immediately, is making all of our organizers meetups forward-looking for those who want to organize a Homebrew Website Club or IndieWebCamp. We still suggest people have experience organizing. We also explicitly recognize that any
This post will be very short. That's the goal. And this is addressed to the Mozilla community as large (be employes or contributors).
- Create a blog.^1
- Ask to be added to Planet Mozilla.^2
- Write small, simple short things.^3
And that's all.
The more you write, the easier it will become.
Write short form, long form will come later. Just by itself. Without you noticing it.
Want good examples?
- Henri Sivonen
- Honza Bambas
- Dzmitry Malyshau
- Kushal Das
- and many more
Notes:
- Wordpress. Tumblr. SquareSpace. Ghost. Medium. Qiita. Or host your own with your own domain name: Gandi. DigitalOcean. It doesn't have to be beautiful. It needs to have content.
- For Example, how I asked to add mine.
- What you are working? What you think the Web should be? What this small feature would do? Have an idea? Wondering about something? Instead of sending an email to one individual or an internal group chat or a private mailing list, just write a blog post and then send an email with a link to the blog post asking for feedback.
Otsukare!
Welcome back everyone - it’s been a year without written updates, but we’re getting this train back on track! Servo hasn’t been dormant in that time; the biggest news was the public release of Firefox Reality (built on Servo technology) in the Microsoft store.
In the past week, we merged 44 PRs in the Servo organization’s repositories.
The latest nightly builds for common platforms are available at download.servo.org.
Planning and Status
Our roadmap is available online, including the team’s plans for 2020.
This week’s status updates are here.
Exciting works in progress
- jdm is replacing the websocket backend.
- cybai and jdm are implementing dynamic module script imports.
- kunalmohan is implementing the draft WebGPU specification.
Notable Additions
- SimonSapin fixed a source of Undefined Behaviour in the
smallveccrate. - muodov improved the compatibility of invalid form elements with the HTML specification, and added
the missing
requestSubmitAPI. - kunalmohan implemented GPUQueue APIs for WebGPU, and avoided synchronous updates, and implemented the getMappedRange API for GPUBuffer.
- alaryso fixed a bug preventing running tests when using rust-analyzer.
- alaryso avoided a panic in pages that perform layout queries on disconnected iframes.
- paulrouget integrated virtual keyboard support for text inputs into Firefox Reality, as well as added support for keyboard events.
- Manishearth implemented WebAudio node types for reading and writing MediaStreams.
- gterzian improved the responsiveness of the browser when shutting down.
- utsavoza updated the referrer policy implementation to match the updated specification.
- ferjm implemented support for WebRTC data channels.
New Contributors
Interested in helping build a web browser? Take a look at our curated list of issues that are good for new contributors!