Today the US Department of Justice (“DOJ”) filed an antitrust lawsuit against Google, alleging that it unlawfully maintains monopolies through anticompetitive and exclusionary practices in the search and search advertising markets. While we’re still examining the complaint our initial impressions are outlined below.
Like millions of everyday internet users, we share concerns about how Big Tech’s growing power can deter innovation and reduce consumer choice. We believe that scrutiny of these issues is healthy, and critical if we’re going to build a better internet. We also know from firsthand experience there is no overnight solution to these complex issues. Mozilla’s origins are closely tied to the last major antitrust case against Microsoft in the nineties.
In this new lawsuit, the DOJ referenced Google’s search agreement with Mozilla as one example of Google’s monopolization of the search engine market in the United States. Small and independent companies such as Mozilla thrive by innovating, disrupting and providing users with industry leading features and services in areas like search. The ultimate outcomes of an antitrust lawsuit should not cause collateral damage to the very organizations – like Mozilla – best positioned to drive competition and protect the interests of consumers on the web.
For the past 20 years, Mozilla has been leading the fight for competition, innovation and consumer choice in the browser market and beyond. We have a long track record of creating innovative products and services that respect the privacy and security of consumers, and have successfully pushed the market to follow suit.
Unintended harm to smaller innovators from enforcement actions will be detrimental to the system as a whole, without any meaningful benefit to consumers — and is not how anyone will fix Big Tech. Instead, remedies must look at the ecosystem in its entirety, and allow the flourishing of competition and choice to benefit consumers.
We’ll be sharing updates as this matter proceeds.
The post Mozilla Reaction to U.S. v. Google appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2020/10/20/mozilla-reaction-to-u-s-v-google/
As October ushers in the tail-end of the year, we are pushing Firefox 82 out the door. This time around we finally enable support for the Media Session API, provide some new CSS pseudo-selector behaviours, close some security loopholes involving the Window.name property, and provide inspection for server-sent events in our developer tools.
This blog post provides merely a set of highlights; for all the details, check out the following:
Inspecting server-sent events
Server-sent events allow for an inversion of the traditional client-initiated web request model, with a server sending new data to a web page at any time by pushing messages. In this release we’ve added the ability to inspect server-sent events and their message contents using the Network Monitor.
You can go to the Network Monitor, select the file that is sending the server-sent events, and view the received messages in the Response tab on the right-hand panel.
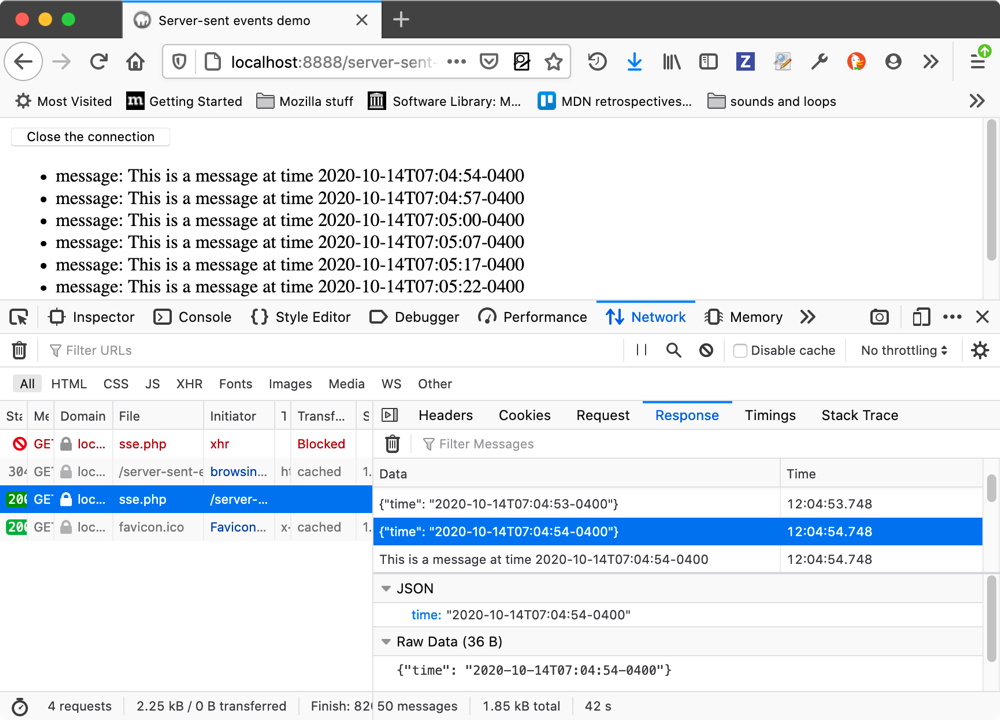
For more information, check out our Inspecting server-sent events guide.
Web platform updates
Now let’s look at the web platform additions we’ve got in store in 82.
Media Session API
The Media Session API enables two main sets of functionality:
- First of all, it provides a way to customize media notifications. It does this by providing metadata for display by the operating system for the media your web app is playing.
- Second, it provides event handlers that the browser can use to access platform media keys such as hardware keys found on keyboards, headsets, remote controls, and software keys found in notification areas and on lock screens of mobile devices. So you can seamlessly control web-provided media via your device, even when not looking at the web page.
The code below provides an overview of both of these in action:
if ('mediaSession' in navigator) {
navigator.mediaSession.metadata = new MediaMetadata({
title: 'Unforgettable',
artist: 'Nat King Cole',
album: 'The Ultimate Collection (Remastered)',
artwork: [
{ src: 'https://dummyimage.com/96x96', sizes: '96x96', type: 'image/png' },
{ src: 'https://dummyimage.com/128x128', sizes: '128x128', type: 'image/png' },
{ src: 'https://dummyimage.com/192x192', sizes: '192x192', type: 'image/png' },
{ src: 'https://dummyimage.com/256x256', sizes: '256x256', type: 'image/png' },
{ src: 'https://dummyimage.com/384x384', sizes: '384x384', type: 'image/png' },
{ src: 'https://dummyimage.com/512x512', sizes: '512x512', type: 'image/png' },
]
});
navigator.mediaSession.setActionHandler('play', function() { /* Code excerpted. */ });
navigator.mediaSession.setActionHandler('pause', function() { /* Code excerpted. */ });
navigator.mediaSession.setActionHandler('seekbackward', function() { /* Code excerpted. */ });
navigator.mediaSession.setActionHandler('seekforward', function() { /* Code excerpted. */ });
navigator.mediaSession.setActionHandler('previoustrack', function() { /* Code excerpted. */ });
navigator.mediaSession.setActionHandler('nexttrack', function() { /* Code excerpted. */ });
}
Let’s consider what this could look like to a web user — say they are playing music through a web app like Spotify or YouTube. With the first block of code above we can provide metadata for the currently playing track that can be displayed on a system notification, on a lock screen, etc.
The second block of code illustrates that we can set special action handlers, which work the same way as event handlers but fire when the equivalent action is performed at the OS-level. This could include for example when a keyboard play button is pressed, or a skip button is pressed on a mobile lock screen.
The aim is to allow users to know what’s playing and to control it, without needing to open the specific web page that launched it.
What’s in a Window.name?
This Window.name property is used to get or set the name of the window’s current browsing
With Firefox 82 hot off the byte presses, we are pleased to welcome the developers whose first code contributions shipped in this release, 18 of whom were new volunteers! Please join us in thanking each of them for their persistence and enthusiasm, and take a look at their contributions:
- tony: 1648874
- Ben D: 1606626
- Chris Jackson: 1599376
- Glen Whitney: 1381231
- Hunter Jones: 1534986
- Jake Mulhern: 1660715
- Jens Stutte: 1660950
- John Bieling: 1661216
- Junior Hsu: 1655636, 1655895
- Martin Schr"oder: 1427353, 1528238
- Michael Goossens: 1654833, 1662329, 1662704, 1664725
- Michael Pobega: 1648024
- Peter Habcak: 1550446
- Philemon Johnson: 1583504
- Philipp Fischbeck: 1622680, 1622683
- Ping Chen: 862292, 1658890
- Reid Shinabarker: 1599803
- YuFu Kao: 1662655
- gene smith: 1563891, 1665652
- yozaam: 1586441, 1651208, 1655110
https://blog.mozilla.org/community/2020/10/20/new-contributors-firefox-82/
Wowee what a year that was. And I’m pretty sure the year to come will be even more so.
Me, in last year’s moziversary post
Oof. I hate being right for the wrong reasons. And that’s all I’ll say about COVID-19 and the rest of the 2020 dumpster fire.
In team news, Georg’s short break turned into the neverending kind as he left Mozilla late last year. We gained Michael Droettboom as our new fearless leader, and from my perspective he seems to be doing quite well at the managery things. Bea and Travis, our two newer team members, have really stepped into their roles well, providing much needed bench depth on Rust and Mobile. And Jan-Erik has taken over leadership of the SDK, freeing up Alessio to think about data collection for Web Extensions.
2020 is indeed being the Year of Glean on the Desktop with several projects already embedding the now-successful Glean SDK, including our very own mach (Firefox Build Tooling Commandline) and mozregression (Firefox Bug Regression Window Finding Tool). Oh, and Jan-Erik and I’ve spent ten months planning and executing on Project FOG (Firefox on Glean) (maybe you’ve heard of it), on track (more or less) to be able to recommend it for all new data collections by the end of the year.
My blogging frequency has cratered. Though I have a mitt full of ideas, I’ve spent no time developing them into proper posts beyond taking my turn at This Week in Glean. In the hopper I have “Naming Your Kid Based on how you Yell At Them”, “Tools Externalize Costs to their Users”, “Writing Code for two Wolves: Computers and Developers”, “Glean is Frictionless”, “Distributed Teams: Proposals are Inclusive”, and whatever of the twelve (Twelve?!) drafts I have saved up in wordpress that have any life in them.
Progress on my resolutions to blog more, continue improving, and put Glean on Firefox? Well, I think I’ve done the latter two. And I think those resolutions are equally valid for the next year, though I may tweak “put Glean on Firefox” to “support migrating Firefox Telemetry to Glean” which is more or less the same thing.
:chutten
https://chuttenblog.wordpress.com/2020/10/20/five-year-moziversary/
Last week, one of my peers asked me to explain what I meant by "Data Intuition", and I realized I really didn't have a good definition. That's a problem! I refer to data intuition all the time!
Data intuition is one of the three skills I interview new data scientists …
The Rust project gets many issues filed every day, and we need to keep track of them all to make sure we don't miss anything. To do that we use GitHub's issue labels feature, and we need your help to make sure we fix regressions as soon as possible!
We have many issue labels that help us organize our issues, and we have a few in particular that mark an issue as a regression. These labels will ping a Rust working group called the prioritization working group, whose members will work to determine the severity of an issue and then prioritize it. But, this won't happen unless someone marks the issue with one of those labels!
We recently had a case where a regression was not caught before a release because the issue was not marked with a regression label. So we have now added the ability for anyone to set regression labels on issues! This is all you have to do to mark an issue as a regression and it will automatically ping people to prioritize it:
@rustbot modify labels: regression-untriaged
Alternatively, if you are reporting a new regression, you can use the regression issue template. It will guide you through the process of reporting a regression and providing information that will help us fix the issue.
Finally, if you have an issue that is not a regression, but is still something that is important to be fixed, you can request prioritization with:
@rustbot prioritize
We really appreciate it if you mark all regressions with an appropriate label so we can track them and fix them as soon as possible!
https://blog.rust-lang.org/2020/10/20/regression-labels.html
On 29 October, Mozilla will host the next installment of Mozilla Mornings – our regular breakfast series that brings together policy experts, policymakers and practitioners for insight and discussion on the latest EU digital policy developments.
A key focus of the upcoming Digital Services Act and European Democracy Action Plan initiatives is platform transparency – transparency about content curation, commercial practices, and data use to name a few. This installment of Mozilla Mornings will focus on transparency of online advertising, and in particular, how mechanisms for greater transparency of ad placement and ad targeting could mitigate the spread and impact of illegal and harmful content online.
As the European Commission prepares to unveil a series of transformative legislative proposals on these issues, the discussion promises to be timely and insightful.
aaaa
Deputy Head of Cabinet of Ms. Vera Jourov'a, European Commission Vice-President
Karolina Iwa'nska
Lawyer and Policy Analyst, Panoptykon Foundation
Sam Jeffers
Co-Founder and Executive Director, Who Targets Me
With opening remarks by Raegan MacDonald
Head of Public Policy, Mozilla Corporation
Moderated by Jennifer Baker
EU Tech Journalist
Logistical information
29 October, 2020
10:30-12:00 CET
Zoom Webinar (conferencing details to be provided on morning of event)
Register your attendance here
The post Mozilla Mornings on addressing online harms through advertising transparency appeared first on Open Policy & Advocacy.
Today, exactly three years ago, I received flowers, money and a gold medal at a grand prize ceremony that will forever live on in my mind and memory. I was awarded the Polhem Prize for my decades of work on curl. The prize itself was handed over to me by no one else than the Swedish king himself. One of the absolute top honors I can imagine in my little home country.
In some aspects, my life is divided into the life before this event and the life after. The prize has even made little me being presented on a poster in the Technical Museum in Stockholm. The medal itself still sits on my work desk and if I just stop starring at my monitors for a moment and glance a little over to the left – I can see it. I think the prize made my surroundings, my family and friends get a slightly different view and realization of what I actually do all these hours in front of my screens.
In the tree years since I received the prize, we’ve increased the total number of contributors and authors in curl by 50%. We’ve done over 3,700 commits and 25 releases since then. Upwards and onward.
Life moved on. It was not “peak curl”. There was no “prize curse” that left us unable to keep up the pace and development. It was possibly a “peak life moment” there for me personally. As an open source maintainer, I can’t imagine many bigger honors or awards to come my way ever again, but I’m not complaining. I got the prize and I still smile when I think about it.

https://daniel.haxx.se/blog/2020/10/19/three-years-since-the-polhem-prize/
TenFourFox Feature Parity Release 28 final is now available for testing (downloads, hashes, release notes). Since there are a couple more user-facing features landing hopefully for FPR29 out of some great work by OlgaTPark, we've temporarily held Rapha"el's Enable JavaScript menu option since these will both require new locale strings and I'd rather not release two language pack sets back to back. Both features will instead debut officially in FPR29 with new langpacks side-by-side, along with some targeted Gecko fixes which should improve site compatibility as well.
In the meantime, all the other improvements and upgrades planned for FPR28 have stuck, and this final release adds updated timezone data as well as all outstanding security updates. Assuming no issues, it will go live as usual on or around Monday, October 19 Pacific time.
http://tenfourfox.blogspot.com/2020/10/tenfourfox-fpr28-available.html
In international curling competitions, each team is given 73 minutes to complete all of its throws. Welcome to curl 7.73.0.
Release presentation
Numbers
the 195th release
9 changes
56 days (total: 8,2XX)
135 bug fixes (total: 6,462)
238 commits (total: 26,316)
3 new public libcurl function (total: 85)
1 new curl_easy_setopt() option (total: 278)
2 new curl command line option (total: 234)
63 contributors, 31 new (total: 2,270)
35 authors, 17 new (total: 836)
0 security fix (total: 95)
0 USD paid in Bug Bounties (total: 2,800 USD)
Changes
We have to look back almost two years to find a previous release packed with more new features than this! The nine changes we’re bringing to the world this time are…
--output-dir
Tell curl where to store the file when you use -o or -O! Requested by users for a long time. Now available!
find .curlrc in $XDG_CONFIG_HOME
If this environment variable is set and there’s a .curlrc in there, it will now be used in preference to the other places curl will look for it.
--help has categories
The huge wall of text that --help previously gave us is now history. “curl --help” will now only show a few important options and the rest is provided if you tell curl which category you want to list help for. Requested by users for a long time.
API for meta-data about easy options
With three new functions, libcurl now provides an API for getting meta-data and information about all existing easy options that an application (possibly via a binding) can set for a transfer in libcurl.
CURLE_PROXY
We’ve introduced a new error code, and what makes this a little extra note-worthy besides just being a new way to signal a particular error, is that applications that receive this error code can also query libcurl for extended error information about what exactly in the proxy use or handshake that failed. The extended explanation is extracted with the new CURLINFO_PROXY_ERROR.
MQTT by default
This is the first curl release where MQTT support is enabled by default. We’ve had it marked experimental for a while, which had the effect that virtually nobody actually used it, tried it or even knew it existed. I’m very eager to get some actual feedback on this…
SFTP commands: atime and mtime
The “quote” functionality in curl which can sends custom commands to the SFTP server to perform various instructions now also supports atime and mtime for setting the access and modification times of a remote file.
knownhosts “fine replace” instruction
The “known hosts” feature is a SSH “thing” that lets an application get told if libcurl connects to a host that isn’t already listed in the known hosts file and what to do about it. This new feature lets the application return CURLKHSTAT_FINE_REPLACE which makes libcurl treat the host as “fine” and it will then replace the host key for that host in the known hosts file.
Elliptic curves
Assuming you use the supported backend, you can now select which curves libcurl should use in the TLS handshake, with CURLOPT_SSL_EC_CURVES for libcurl applications and with --curves for the command line tool.
Bug-fixes
As always, here follows a small selection of the many bug-fixes done this cycle.
buildconf: invoke ‘autoreconf -fi’ instead
Born in May 2001, this script was introduced to build configure etc so that you can run configure etc, when you’re building code straight from git (even if it was CVS back in 2001).
Starting now, the script just runs ‘autoreconf -fi‘ and no extra custom magic
Firefox PiP (Picture in Picture) is a wondeful feature of the native video html element. But we could probably do better.
Here a very simple video element that you can copy and paste in your URL bar.
data:text/html,span> controls>span> src="https://interactive-examples.mdn.mozilla.net/media/cc0-videos/flower.mp4" type="video/mp4">
But these are a couple of things I wish were accessible natively.
- Move frame by frame (forward backward)
- Save as an animated GIF or another video from this frame to this frame
- Show me the video as a film strip with this granularity (example: an image every 10s). Global view navigation on a video is the equivalent of zooming out on a map to relocate more quickly on the area we are interested by
- Make it possible to associate any subtitles URL or file of my own choice.
Otsukare!
Last week I presented the idea of Intentional Documentation to Mozilla's data science team. Here's a link to the slides.
The rest of this post is a transcription of what I shared with the team (give or take).
In Q4, I'm trying to build a set of trainings to help …
There are many experiences in a person's life that in some way more or less strongly influence their course of life. However, there are some such events whose impact is so lasting that they can rightly be described as a key experience.
The beginnings
I had such an experience in the autumn of 1995. I visited a small exhibition of assistive technology products for the blind, which took place at the Hamburg-Farmsen Vocational Promotion Agency. At that time I had just started my studies in business informatics at the University of Applied Sciences Wedel and needed a notebook with a refreshable Braille display. Up to that point, I had already visited some exhibitions and Hamburg-based representatives of assistive technology vendors, but by then I had not found anything that I had been really convinced of. Either there was no mobile solution at all, or the systems on offer were so unwieldy that they were simply too heavy to carry around. I had to go by public transit for an hour each direction, from the place where I lived to the place I was studying at. Weight was therefore a key factor for me.
I had heard that Help Tech, which at that time was still called Handy Tech, would be present at this exhibition. Handy Tech had just emerged from another company called Blista-EHG a year earlier. In addition, the company had no representative in Hamburg, so I had not yet been able to try their products. According to the announcement, they would exhibit their new innovative line of Braille displays, combined with a first version of the screen reader JAWS for Windows. That definitely piqued my curiosity.
I arrived at the exhibition place and found the exhibit hall right away. An employee showed me the table where Handy Tech had set up a Braille display connected to a desktop computer. The Handy Tech representative was in conversation with another interested party at that moment. I just sat in front of the display and started exploring what was in front of me.
And what can I say? It was love on first touch, so to speak! The Braille display that stood in front of me was a model called "Braille Window Modular 84". Unlike all the other displays I had looked at, it had no flat, but cells that were curved inwards, with an upward tilt towards the user. These felt very gentle under my fingertips. The hand automatically fell into a slightly curved posture, similar to what is ideal for pianists to play the most relaxed. The dot caps were pleasantly round, and the fingers glided over the displayed information effortlessly in this natural hand posture.
The keyboard mounted on the display had clearly noticeable dots on the common keys, so that orientation was a breeze. The PC was open to MS Word in a document in which someone had written the mandatory "This is a test". I started writing something into the document to see how the keyboard felt, then opened the menu bar using the Alt key, then flipped through other applications and the program manager of Windows 3.11 with Alt-Tab. Surprised, I found that I was just using Windows all the time, and the Braille display always showed me the current location. I didn't have to learn awkwardly complicated keyboard shortcuts. In contrast to many other screen reader experiments at the time JAWS followed a different philosophy. Right from the start, JAWS had the aim of not standing in the way of the user, but to put the usage of Windows and its programs at the forefront.
At that moment I knew I wanted this system for my studies. The Handy Tech employee had since ended his conversation and turned to me. He was blind himself, which pleased me very much. This meant that he would probably be able to answer some more in-depth questions, which had caused stuttering, long faces, and other signs of lack of knowledge in mostly sighted representatives from other AT vendors before.
The conversation was indeed very constructive, informative and illuminating. We discussed my requirements, he noted down my details, and a few weeks later, they made me an offer. At that time, however, I needed the mobile version of the system, i.e. the little sibling display "Modular 44". Using an auxiliary construction, I could connect this display to a suitable notebook in a way that it formed a stable unit. Just as easily, however, the notebook could be undocked, and the keyboard and the corresponding number pad could then be clipped on. I could then use the display comfortably with the stationary PC at home.
Just in time for the 2nd semester at the beginning of 1996, I had mastered the administrative procedures and received the system along with my first JAWS version. A few weeks later I programmed my first Windows application in Borland Delphi. I reported on my experience in the Henter-Joyce Forum on CompuServe, and how I managed to make the development environment itself more accessible using configuration
This blog post is the first of several guest blog posts we’ll be publishing, where we invite participants of our bug bounty program to write about bugs they’ve reported to us.
This blog post is about a vulnerability I found in the Mozilla Maintenance Service on Windows that allows an attacker to elevate privileges from a standard user account to SYSTEM. While the specific vulnerability only works on Windows, this is not really because of any Windows-specific issue but rather about how Mozilla validated trust in files it operated on with privileged components. This vulnerability is assigned CVE-2020-15663. It was reported on Mozilla Bugzilla Bug 1643199.
One day I read the “Mozilla Foundation Security Advisory 2019-25,” and one bug caught my attention: “CVE-2019-11753: Privilege escalation with Mozilla Maintenance Service in custom Firefox installation location.” The description mentioned that a privilege escalation was caused “due to a lack of integrity checks.” My past experience taught me that maybe the fix was to check digital signatures only. If that’s the case, then a version rollback attack may be used to bypass the fix. So, I decided to check that, and it worked.
The Bug: A Classic Rollback Attack
Firefox’s Windows installer allows users to customize the Firefox installation directory. If Firefox is installed to a non-standard location, and not the typical C:\Program Files\Mozilla Firefox\, the Firefox installation path may be user-writable. If that is the case, then a local attacker with a standard account can replace any files in the installation path. If the attacker has permission to do this, they can already execute arbitrary code as the user – but they are interested in elevating privileges to SYSTEM.
The Mozilla Maintenance Service is a Windows service, installed by default. This service runs with SYSTEM privilege. One of its tasks is to launch the Firefox updater with SYSTEM privilege, so that it can update write-protected files under C:\Program Files\Mozilla Firefox without showing UAC prompts. The Mozilla Maintenance Service can be started by standard users, but its files are in C:\Program Files (x86)\Mozilla Maintenance Service\ and not writable by standard users.
However, the Maintenance Service copies files from the Firefox installation and then runs them with SYSTEM privileges: those files are updater.exe and updater.ini. Although the Maintenance Service checks if updater.exe contains an identity string and is signed by Mozilla, it doesn’t check the file version. Thus, an attacker can replace the currently installed updater.exe with an old and vulnerable version of updater.exe. Then the Maintenance Service copies the old updater.exe and updater.ini to C:\Program Files (x86)\Mozilla Maintenance Service\update\, and runs the updater.exe in this update directory with SYSTEM privilege.
This type of bug is a classic rollback attack (sometimes called a replay attack). Most search results for this attack are focused on network protocols (especially TLS), but it’s also applicable to software updates. It was described for Linux package managers at least ten years ago. The general fix for this type of bug is to include in the signed metadata for a file when it should no longer be trusted. Debian uses a Valid-Until date in the metadata for the entire package repository; and The Update Framework is a specification for doing this in a more generic way.
Another example of a software rollback attack is a Steam Service privilege escalation vulnerability, CVE-2019-15315, which I discovered last year. The Steam Service vulnerability was also caused by only verifying digital signatures but not the file version.
Finding a Candidate Bug for Exploitation
I looked for old bugs that may allow me to exploit this issue by searching “Mozilla updater privilege escalation” on MITRE. Luckily, there were two matches: CVE-2017-7766 and CVE-2017-7760. The description of CVE-2017-7766 is “an attack using manipulation of
tldr: work has started to make Hyper work as a backend in curl for HTTP.
curl and its data transfer core, libcurl, is all written in C. The language C is known and infamous for not being memory safe and for being easy to mess up and as a result accidentally cause security problems.
At the same time, C compilers are very widely used and available and you can compile C programs for virtually every operating system and CPU out there. A C program can be made far more portable than code written in just about any other programming language.
curl is a piece of “insecure” C code installed in some ten billion installations world-wide. I’m saying insecure within quotes because I don’t think curl is insecure. We have our share of security vulnerabilities of course, even if I think the rate of them getting found has been drastically reduced over the last few years, but we have never had a critical one and with the help of busloads of tools and humans we find and fix most issues in the code before they ever land in the hands of users. (And “memory safety” is not the single explanation for getting security issues.)
I believe that curl and libcurl will remain in wide use for a long time ahead: curl is an established component and companion in scripts and setups everywhere. libcurl is almost a de facto standard in places for doing internet transfers.
A rewrite of curl to another language is not considered. Porting an old, established and well-used code base such as libcurl, which to a far degree has gained its popularity and spread due to a stable API, not breaking the ABI and not changing behavior of existing functionality, is a massive and daunting task. To the degree that so far it hasn’t been attempted seriously and even giant corporations who have considered it, have backpedaled such ideas.
Change, but not change
This preface above might make it seem like we’re stuck with exactly what we have for as long as curl and libcurl are used. But fear not: things are more complicated, or perhaps brighter, than it first seems.
What’s important to users of libcurl needs to be kept intact. We keep the API, the ABI, the behavior and all the documented options and features remain. We also need to continuously add stuff and keep up with the world going forward.
But we can change the internals! Refactor as the kids say.
Backends, backends, backends
Already today, you can build libcurl to use different “backends” for TLS, SSH, name resolving, LDAP, IDN, GSSAPI and HTTP/3.
A “backend” in this context is a piece of code in curl that lets you use a particular solution, often involving a specific third party library, for a certain libcurl functionality. Using this setup you can, for example, opt to build libcurl with one or more out of thirteen different TLS libraries. You simply pick the one(s) you prefer when you build it. The libcurl API remains the same to users, it’s just that some features and functionality might differ a bit. The number of TLS backends is of course also fluid over time as we add support for more libraries in the future, or even drop support for old ones as they fade away.
When building curl, you can right now make it use up to 33 different third party libraries for different functions. Many of them of course mutually exclusive, so no single build can use all 33.
Said differently: you can improve your curl and libcurl binaries without changing any code, by simply rebuilding it to use another backend combination.

libcurl as a glorified switch
With an extensive set of backends that use third party libraries, the job of libcurl to a large extent becomes to act as a switch between the provided stable external API and the particular third party library that does the heavy lifting.
API <=> glue code in C <=> backend library
libcurl as the rock, with a door and the entry rules written in stone. The backends can come and go, change and improve, but the applications outside the entrance won’t notice that. They get a stable API and ABI that they know and trust.
Safe backends
This setup provides a foundation and infrastructure to offer backends written in other languages as part of the package. As long
Since its founding in 1998, Mozilla has championed human-rights-compliant innovation as well as choice, control, and privacy for people on the Internet. We have worked hard to actualise this belief for the billions of users on the Web by actively leading and participating in the creation of Web standards that drive the Internet. We recently submitted our thoughts to the European Commission on its survey and public consultation regarding the eIDAS regulation, advocating for an interpretation of eIDAS that is better for user security and retains innovation and interoperability of the global Internet.
Given our background in the creation of the Transport Layer Security (TLS) standard for website security, we believe that mandating an interpretation of eIDAS that requires Qualified Website Authentication Certificates (QWACs) to be bound with TLS certificates is deeply concerning. Along with weakening user security, it will cause serious harm to the single European digital market and its place within the global internet.
Some high-level reasons for this position, as elucidated in our multiple recent submissions to the European Commission survey, are:
- It violates the eIDAS Requirements: The cryptographic binding of a QWAC to a connection or TLS certificate will violate several provisions of the eIDAS regulation, including Recital 67 (website authentication), Recital 27 (technological neutrality), and Recital 72 (interoperability). The move to cryptographically bind a QWAC to a connection or TLS certificate will negate this wise consideration and go against the legislative intent of the Council.
- It will undermine technical neutrality and interoperability: Mandating TLS binding with QWACs will hinder technological neutrality and interoperability, as it will go against established best practices which have successfully helped keep the Web secure for the past two decades. Apart from being central to the goals of the eIDAS regulation itself, technological neutrality and interoperability are the pillars upon which innovation and competition take place on the web. Limiting them will severely hinder the ability of the EU digital single market to remain competitive within the global economy in a safe and secure manner.
- It will undermine privacy for end users: Validating QWACs, as currently envisaged by ETSI, poses serious privacy risks to end users. In particular, the proposal uses validation procedures or protocols that would reveal a user’s browsing activity to a third-party validation service. This third party service would be in a position to track and profile users based on this information. Even if this were to be limited by policy, this information is largely indistinguishable from a privacy-problematic tracking technique known as “link decoration”.
- It will create dangerous security risks for the Web: It has been repeatedly suggested that Trust Service Providers (TSPs) who issue QWACs under the eIDAS regulation automatically be included in the root certificate authority (CA) stores of all browsers. Such a move will amount to forced website certificate whitelisting by government dictate and will irremediably harm users’ safety and security. It goes against established best practices of website authentication that have been created by consensus from the varied experiences of the Internet’s explosive growth. The technical and policy requirements for a TSP to be included in the root CA store of Mozilla Firefox, for example, compare much more favourably than the framework
The Rust team is happy to announce a new version of Rust, 1.47.0. Rust is a programming language that is empowering everyone to build reliable and efficient software.
If you have a previous version of Rust installed via rustup, getting Rust 1.47.0 is as easy as:
rustup update stable
If you don't have it already, you can get rustup from the
appropriate page on our website, and check out the detailed release notes for
1.47.0 on GitHub.
What's in 1.47.0 stable
This release contains no new language features, though it does add one long-awaited standard library feature. It is mostly quality of life improvements, library stabilizations and const-ifications, and toolchain improvements. See the detailed release notes to learn about other changes not covered by this post.
Traits on larger arrays
Rust does not currently have a way to be generic over integer values. This
has long caused problems with arrays, because arrays have an integer as part
of their type; [T; N] is the type of an array of type T of N length.
Because there is no way to be generic over N, you have to manually implement
traits for arrays for every N you want to support. For the standard library,
it was decided to support up to N of 32.
We have been working on a feature called "const generics" that would allow
you to be generic over N. Fully explaining this feature is out of the scope
of this post, because we are not stabilizing const generics just yet.
However, the core of this feature has been implemented in the compiler, and
it has been decided that the feature is far enough along that we are okay
with the standard library using it to implement traits on arrays of any
length. What this means in
practice is that if you try to do something like this on Rust 1.46:
fn main() {
let xs = [0; 34];
println!("{:?}", xs);
}
you'd get this error:
error[E0277]: arrays only have std trait implementations for lengths 0..=32
--> src/main.rs:4:22
|
4 | println!("{:?}", xs);
| ^^ the trait `std::array::LengthAtMost32` is not implemented for `[{integer}; 34]`
|
= note: required because of the requirements on the impl of `std::fmt::Debug` for `[{integer}; 34]`
= note: required by `std::fmt::Debug::fmt`
= note: this error originates in a macro (in Nightly builds, run with -Z macro-backtrace for more info)
But with Rust 1.47, it will properly print out the array.
This should make arrays significantly more useful to folks, though it will take until the const generics feature stabilizes for libraries to be able to do this kind of implementation for their own traits. We do not have a current estimated date for the stabilization of const generics.
Shorter backtraces
Back in Rust 1.18, we made some changes to the backtraces rustc would
print on panic. There are a
number of things in a backtrace that aren't useful the majority of the time.
However, at some point, these
regressed. In Rust 1.47.0,
the culprit was found, and this has now been
fixed. Since the regression,
this program:
fn main() {
panic!();
}
would give you a backtrace that looks like this:
thread 'main' panicked at 'explicit panic', src/main.rs:2:5
stack backtrace:
0: backtrace::backtrace::libunwind::trace
at /cargo/registry/src/github.com-1ecc6299db9ec823/backtrace-0.3.46/src/backtrace/libunwind.rs:86
1: backtrace::backtrace::trace_unsynchronized
at /cargo/registry/src/github.com-1ecc6299db9ec823/backtrace-0.3.46/src/backtrace/mod.rs:66
2: std::sys_common::backtrace::_print_fmt
at src/libstd/sys_common/backtrace.rs:78
3: ::fmt
at src/libstd/sys_common/backtrace.rs:59
4: core::fmt::write