You might know that I’ve posted funny emails I’ve received on my blog several times in the past. The kind of emails people send me when they experience problems with some device they own (like a car) and they contact me because my email address happens to be visible somewhere.
People sometimes say I should get a different email address or use another one in the curl license file, but I’ve truly never had a problem with these emails, as they mostly remind me about the tough challenges the modern technical life bring to people and it gives me insights about what things that run curl.
But not all of these emails are “funny”.
Category: not funny
Today I received the following email
From: Al Nocai <[redacted]@icloud.com> Date: Fri, 19 Feb 2021 03:02:24 -0600 Subject: I will slaughter you
That subject.
As an open source maintainer since over twenty years, I know flame wars and personal attacks and I have a fairly thick skin and I don’t let words get to me easily. It took me a minute to absorb and realize it was actually meant as a direct physical threat. It found its ways through and got to me. This level of aggressiveness is not what I’m prepared for.
Attached in this email, there were seven images and no text at all. The images all look like screenshots from a phone and the first one is clearly showing source code I wrote and my copyright line:

The other images showed other source code and related build/software info of other components, but I couldn’t spot how they were associated with me in any way.
No explanation, just that subject and the seven images and I was left to draw my own conclusions.
I presume the name in the email is made up and the email account is probably a throw-away one. The time zone used in the Date: string might imply US central standard time but could of course easily be phony as well.
How I responded
Normally I don’t respond to these confused emails because the distance between me and the person writing them is usually almost interplanetary. This time though, it was so far beyond what’s acceptable to me and in any decent society I couldn’t just let it slide. After I took a little pause and walked around my house for a few minutes to cool off, I wrote a really angry reply and sent it off.
This was a totally and completely utterly unacceptable email and it hurt me deep in my soul. You should be ashamed and seriously reconsider your manners.
I have no idea what your screenshots are supposed to show, but clearly something somewhere is using code I wrote. Code I have written runs in virtually every Internet connected device on the planet and in most cases the users download and use it without even telling me, for free.
Clearly you don’t deserve my code.
I don’t expect that it will be read or make any difference.
Update below, added after my initial post.
Al Nocai’s response
Contrary to my expectations above, he responded. It’s not even worth commenting but for transparency I’ll include it here.
I do not care. Your bullshit software was an attack vector that cost me a multimillion dollar defense project.
Your bullshit software has been used to root me and multiple others. I lost over $15k in prototyping alone from bullshit rooting to the charge arbitrators.
I have now since October been sandboxed because of your bullshit software so dipshit google kids could grift me trying to get out of the sandbox because they are too piss poor to know shat they are doing.
You know what I did to deserve that? I tried to develop a trade route in tech and establish project based learning methodologies to make sure kids aren’t left behind. You know who is all over those god damn files? You are. Its sickening. I got breached in Oct 2020 through federal server hijacking, and I owe a great amount of that to you.
Ive had to sit and watch as i reported:
- fireeye Oct/2020
- Solarwinds Oct/2020
- Zyxel Modem Breach Oct/2020
- Multiple Sigover attack vectors utilizing favicon XML injection
- JS Stochastic templating utilizing comparison expressions to write
I’m delighted to share that the Mozilla Foundation and Corporation Boards are each welcoming a new member.
Wambui Kinya is Vice President of Partner Engineering at Andela, a Lagos-based global talent network that connects companies with vetted, remote engineers from Africa and other emerging markets. Andela’s vision is a world where the most talented people can build a career commensurate with their ability – not their race, gender, or geography. Wambui joins the Mozilla Foundation Board and you can read more from her, here, on why she is joining. Motivated by the intersection of Africa, technology and social impact, Wambui has led business development and technology delivery, digital technology implementation, and marketing enablement across Africa, the United States, Europe and South America. In 2020 she was selected as one of the “Top 30 Most Influential Women” by CIO East Africa.
Laura Chambers is Chief Executive Officer of Willow Innovations, which addresses one of the biggest challenges for mothers, with the world’s first quiet, all-in-one, in-bra, wearable breast pump. She joins the Mozilla Corporation Board. Laura holds a wealth of knowledge in internet product, marketplace, payment, and community engagement from her time at AirBnB, eBay, PayPal, and Skype, as well as her current role at Willow. Her experience also includes business operations, marketing, shipping, global customer trust and community engagement. Laura brings a clear understanding of the challenges we face in building a better internet, coupled with strong business acumen, and an acute ability to hone in on key issues and potential solutions. You can read more from Laura about why she is joining here.
At Mozilla, we invite our Board members to be more involved with management, employees and volunteers than is generally the case, as I’ve written about in the past. To ready them for this, Wambui and Laura met with existing Board members, members of the management team, individual contributors and volunteers.
We know that the challenges of the modern internet are so big, and that expanding our capacity will help us develop solutions to those challenges. I am sure that Laura and Wambui’s insights and strategic thinking will be a great addition to our boards.
The post Expanding Mozilla’s Boards appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2021/02/18/expanding-mozillas-boards/

Laura Chambers
Like many of us I suspect, I have long been a fairly passive “end-user” of the internet. In my daily life, I’ve merrily skipped along it to simplify and accelerate my life, to be entertained, to connect with far-flung friends and family, and to navigate my daily life. In my career in Silicon Valley, I’ve happily used it as a trusty building block to help build many consumer technologies and brands – in roles leading turnarounds and transformations at market-creating companies like eBay, PayPal, Skype, Airbnb, and most recently as CEO of Willow Innovations Inc.
But over the past few years, my relationship with the internet has significantly changed. We’ve all had to face up to the cracks and flaws … many of which have been there for a while, but have recently opened into gaping chasms that we can’t ignore. The impact of curated platforms and data misuse on families, friendships, communities, politics and the global landscape has been staggering. And it’s hit close to home … I have three young children, all of whom are getting online much faster and earlier than expected, due to the craziness of homeschooling, and my concerns about their safety and privacy are tremendous. All of a sudden, my happy glances at the internet have been replaced with side-eyes of mistrust.
So last year, in between juggling new jobs, home-offices full of snoring dogs, and home schooling, I started to think about what I could do to help. In that journey, I was incredibly fortunate to connect with the team at Mozilla. As I learned more about the team, met the talented people at the helm, and dove into their incredible mission to ensure the internet is free, open and accessible to all, I couldn’t think of a better way to do something practical and meaningful to help than through joining the Board.
The opportunity ahead is astounding … using the power of the open internet to make the world a better, freer, more positively connected place. Mozilla has an extraordinary legacy of leading that charge, and I couldn’t be more thrilled to be join the exceptional group driving toward a much better future. I look forward to us all once again being able to merrily skip along our daily lives, with the internet as our trusty guide and friend along the way.
The post Why I’m Joining Mozilla’s Board of Directors appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2021/02/18/why-im-joining-mozillas-board-of-directors-2/
I recently noticed the following message in Sentry’s pip installation step:
Using legacy ‘setup.py install’ for openapi-core, since package ‘wheel’ is not installed.
Upon some investigation, I noticed that the package wheel was not being installed. After making some changes, I can now guarantee that our development environment installs it by default and it’s given us about 40–50% speed gain.

The screenshot above shows the steps from two different Github workflows; it installs Sentry’s Python packages inside of a fresh virtualenv and the pip cache is available.
If you see a message saying that wheelpackage is not installed, make sure to attend to it!

Wambui Kinya
My introduction to Mozilla was when Firefox was first launched. I was starting my career as a software developer in Boston, MA at the time. My experience was Firefox was a far superior browser. I was also deeply fascinated by the notion that, as an open community, we could build and evolve a product for greater good.
You have probably deduced from this, that I am also old enough that growing up in my native country, Kenya, most of my formative years were under the policies of “poverty reduction programs” dictated and enforced by countries and institutions in the northern hemisphere. My firsthand experience of many of these programs was observing my mother, a phenomenal environmental engineer and academic, work tirelessly to try to convince donor organizations to be more inclusive of the communities they sought to serve and benefit.
This drive to have greater inclusion and representation was deepened over ten years of being a woman and person of color in technology in corporate America. I will spare you the heartache of recounting my experiences of being the first or the only one. But I must also acknowledge, I was fortunate enough to have leaders who wanted to help me succeed and grow. As my professional exposure became more global, I felt an urgency to have more representation and greater voice from Africa.
When I moved back to Kenya, ten years ago, I was excited about the advances in access to technology. However, I was disheartened that it was primarily as consumers rather than creators of technology products. We were increasingly distanced from the concentration of power influencing our access, our data and our ability to build and compete in this internet age.
My professional journey has since been informed by the culmination of believing in the talent that is in Africa, the desire to build for Africa and by extension the digital sovereignty of citizens of the global south. I was greatly influenced by the audacity of organizations like ThoughtWorks that thought deeply about the fight against digital colonialism and invested in free and open source products and communities. This is the context in which I was professionally reintroduced to Mozilla and its manifesto.
Mozilla’s commitment and reputation to “ensure the internet remains a public resource that is open and accessible to us all” has consistently inspired me. However, there is an increased urgency to HOW this is done given the times we live in. We must not only build, convene and enable technology and communities on issues like disinformation, privacy, trustworthy AI and digital rights, but it is imperative that we consider:
- how to rally citizens and ensure greater representation;
- how we connect leaders and enable greater agency to produce; and finally,
- how we shape an agenda that is more inclusive.
This is why I have joined the Mozilla board. I am truly honored and look forward to contributing but also learning alongside you.
Onwards ever, backwards never!
The post Why I’m Joining Mozilla’s Board of Directors appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2021/02/18/why-im-joining-mozillas-board-of-directors/
Warning: this post is full of libcurl internal architectural details and not much else.
Within libcurl there are two primary objects being handled; transfers and connections. The transfers objects are struct Curl_easy and the connection counterparts are struct connectdata.
This is a separation and architecture as old as libcurl, even if the internal struct names have changed a little through the years. A transfer is associated with none or one connection object and there’s a pool with potentially several previously used, live, connections stored for possible future reuse.
A simplified schematic picture could look something like this:
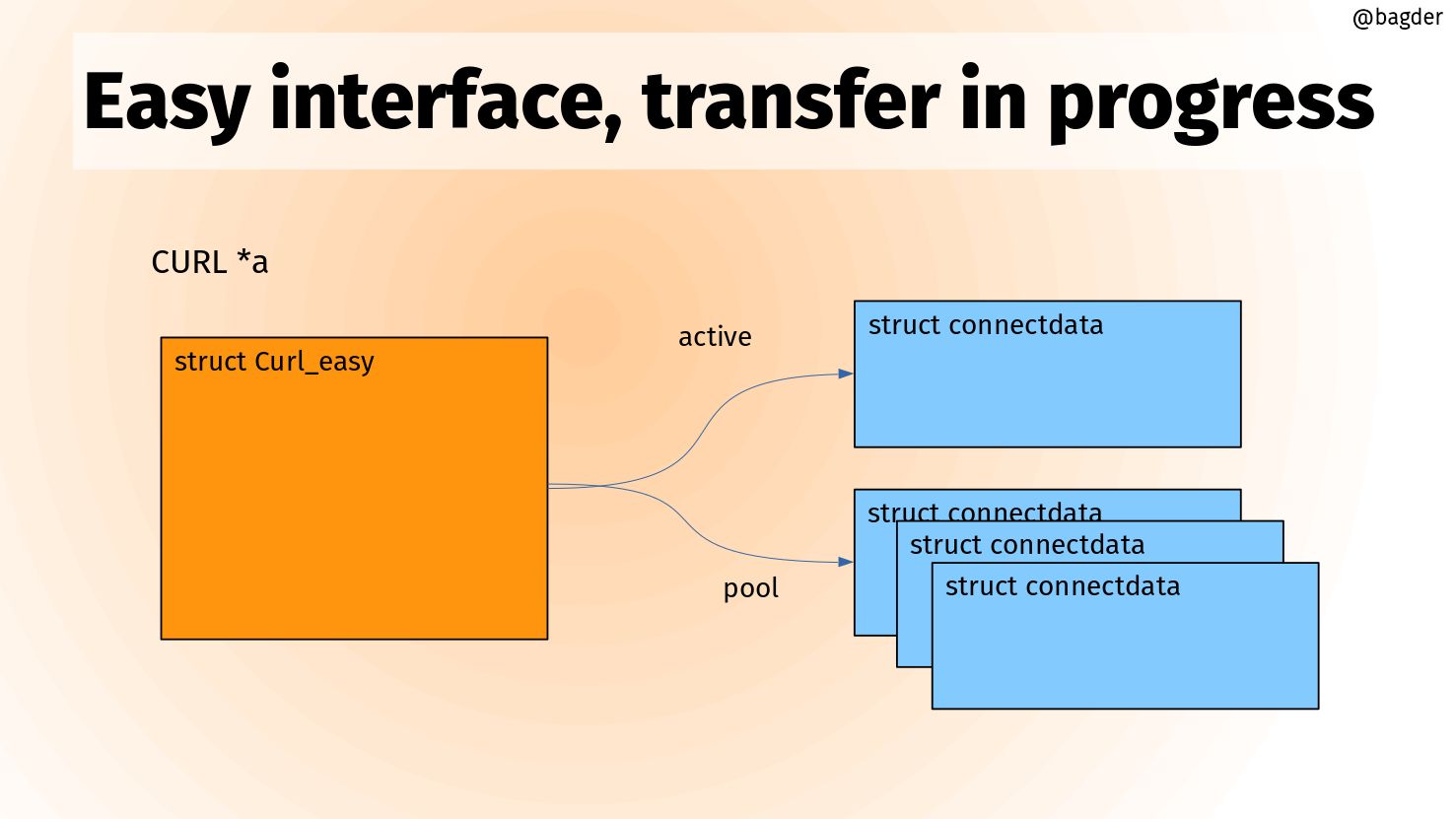
Transfers to connections
These objects are protocol agnostic so they work like this no matter which scheme was used for the URL you’re transferring with curl.
Before the introduction of HTTP/2 into curl, which landed for the first time in September 2013 there was also a fixed relationship that one transfer always used (none or) one connection and that connection then also was used by a single transfer. libcurl then stored the association in the objects both ways. The transfer object got a pointer to the current connection and the connection object got a pointer to the current transfer.
Multiplexing shook things up
Lots of code in libcurl passed around the connection pointer (conn) because well, it was convenient. We could find the transfer object from that (conn->data) just fine.
When multiplexing arrived with HTTP/2, we then could start doing multiple transfers that share a single connection. Since we passed around the conn pointer as input to so many functions internally, we had to make sure we updated the conn->data pointer in lots of places to make sure it pointed to the current driving transfer.
This was always awkward and the source for agony and bugs over the years. At least twice I started to work on cleaning this up from my end but it quickly become a really large work that was hard to do in a single big blow and I abandoned the work. Both times.
Third time’s the charm
This architectural “wart” kept bugging me and on January 8, 2021 I emailed the curl-library list to start a more organized effort to clean this up:
Conclusion: we should stop using ‘conn->data’ in libcurl
Status: there are 939 current uses of this pointer
Mission: reduce the use of this pointer, aiming to reach a point in the future when we can remove it from the connection struct.
Little by little
With the help of fellow curl maintainer Patrick Monnerat I started to submit pull requests that would remove the use of this pointer.
Little by little we changed functions and logic to rather be anchored on the transfer rather than the connection (as data->conn is still fine as that can only ever be NULL or a single connection). I made a wiki page to keep an updated count of the number of references. After the first ten pull requests we were down to just over a hundred from the initial 919 – yeah the mail quote says 939 but it turned out the grep pattern was slightly wrong!
We decided to hold off a bit when we got closer to the 7.75.0 release so that we wouldn’t risk doing something close to the ship date that would jeopardize it. Once the release had been pushed out the door we could continue the journey.
Gone!
As of today, February 16 2021, the internal pointer formerly known as conn->data doesn’t exist anymore in libcurl and therefore it can’t be used and this refactor is completed. It took at least 20 separate commits to get the job done.
I hope this new order will help us do less mistakes as we don’t have to update this pointer anymore.
I’m very happy we could do this revamp without it affecting the API or ABI in any way. These are all just internal artifacts that are not visible to the outside.
One of a thousand little things
This is just a tiny detail but the internals of a project like curl consists of a thousand little details and this is one way we make sure the code remains in a good shape. We identify improvements and we perform them. One by one. We never stop and we’re never done. Together we take this project into the future and help
 On 25 February, Mozilla will host the next installment of Mozilla Mornings – our regular event series that brings together policy experts, policymakers and practitioners for insight and discussion on the latest EU digital policy developments.
On 25 February, Mozilla will host the next installment of Mozilla Mornings – our regular event series that brings together policy experts, policymakers and practitioners for insight and discussion on the latest EU digital policy developments.
This installment of Mozilla Mornings will focus on the DSA’s risk-based approach, specifically the draft law’s provisions on risk assessment, risk mitigation, and auditing for very large online platforms. We’ll be looking at what these provisions seek to solve for; how they’re likely to work in practice; and what we can learn from related proposals in other jurisdictions.
Speakers
Carly Kind
Director, Ada Lovelace Institute
Ben Scott
Executive Director, Reset
Owen Bennett
Senior Policy Manager, Mozilla Corporation
Moderated by Brian Maguire
EU journalist and broadcaster
Logistical information
25 February, 2021
11:00-12:00 CET
Zoom Webinar (conferencing details to be provided on morning of event)
Register your attendance here
The post Mozilla Mornings: Unpacking the DSA’s risk-based approach appeared first on Open Policy & Advocacy.
This is to keep track and document the sequence of events related to macOS 11 and another cascade of breakages related to the change of user agent strings. There is no good solution. One more time it shows how sniffing User Agent strings are both dangerous (future fail) and source of issues.
Brace for impact!
Capping macOS 11 version in User Agent History
-
2020-06-25 OPENED WebKit 213622 - Safari 14 - User Agent string shows incorrect OS version
A reporter claims it breaks many websites but without giving details about which websites. There's a mention about VP9
browser supports vp9
I left a comment there to get more details.
-
2020-09-15 OPENED WebKit 216593 - [macOS] Limit reported macOS release to 10.15 series.
if (!osVersion.startsWith("10")) osVersion = "10_15_6"_s;With some comments in the review:
preserve original OS version on older macOS at Charles's request
I suspect this is the Charles, the proxy app.
2020-09-16 FIXED
-
2020-10-05 OPENED WebKit 217364 - [macOS] Bump reported current shipping release UA to 10_15_7
On macOS Catalina 10.15.7, Safari reports platform user agent with OS version 10_15_7. On macOS Big Sur 11.0, Safari reports platform user agent with OS version 10_15_6. It's a bit odd to have Big Sur report an older OS version than Catalina. Bump the reported current shipping release UA from 10_15_6 to 10_15_7.
The issue here is that macOS 11 (Big Sur) reports an older version number than macOS 10.15 (Catalina), because the previous bug harcoded the string number.
if (!osVersion.startsWith("10")) osVersion = "10_15_7"_s;This is still harcoded because in this comment:
Catalina quality updates are done, so 10.15.7 is the last patch version. Security SUs from this point on won’t increment the patch version, and does not affect the user agent.
2020-10-06 FIXED
-
2020-10-11 Unity [WebGL][macOS] Builds do not run when using Big Sur
UnityLoader.jsis the culprit.They fixed it on January 2021(?). But there are a lot of legacy codes running out there which could not be updated.
Irony, there’s no easy way to detect the unity library to create a site intervention that would apply to all games with the issue. Capping the UA string will fix that.
-
2020-11-30 OPENED Webkit 219346 - User-agent on macOS 11.0.1 reports as 10_15_6 which is older than latest Catalina release.
It was closed as a duplicate of 217364, but there's an interesting description:
Regression from 216593. That rev hard codes the User-Agent header to report MacOS X 10_15_6 on macOS 11.0+ which breaks Duo Security UA sniffing OS version check. Duo security check fails because latest version of macOS Catalina is 10.15.7 but 10.15.6 is being reported.
-
2020-11-30 OPENED Gecko 1679929 - Cap the User-Agent string's reported macOS version at 10.15
There is a patch for Gecko to cap the user agent string the same way that Apple does for Safari. This will solve the issue with Unity Games which have been
Some of us are keeping notes of bread and crumbs fallen everywhere. A dead leaf, a piece of string, a forgotten note washed away on a beach, and things read in a book. We collect memories and inspiration.
All browsers have a feature called "Bookmark This Page". It is essentially the same poor badly manageable tool on every browsers. If you do not want to rely on a third party service, or an addon, what the browser has to offer is not very satisfying.
Firefox gives a possibility to change the name, to choose where to put it and to add tags at the moment we save it.
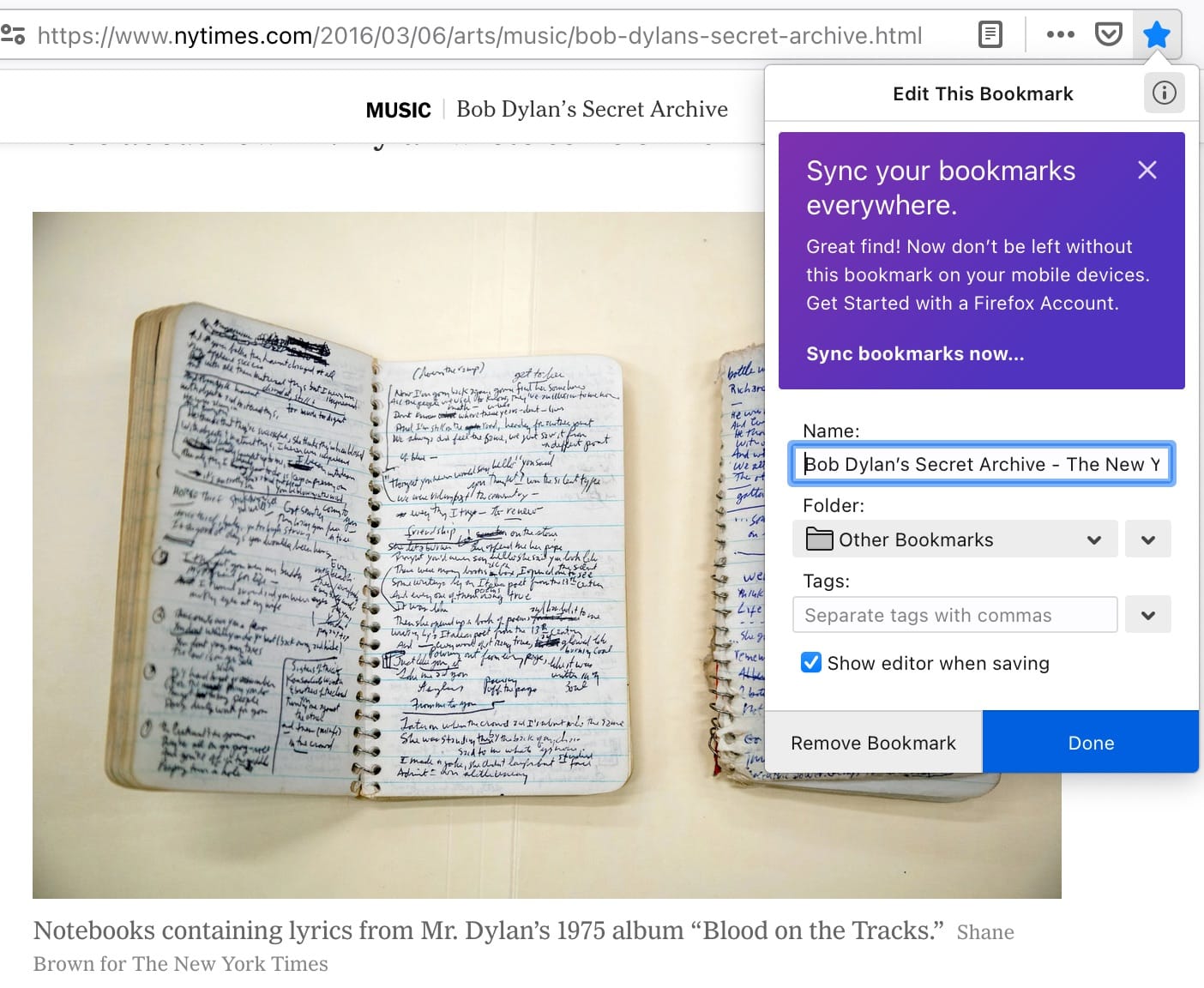
Edge follows the same conventions without the tagging.
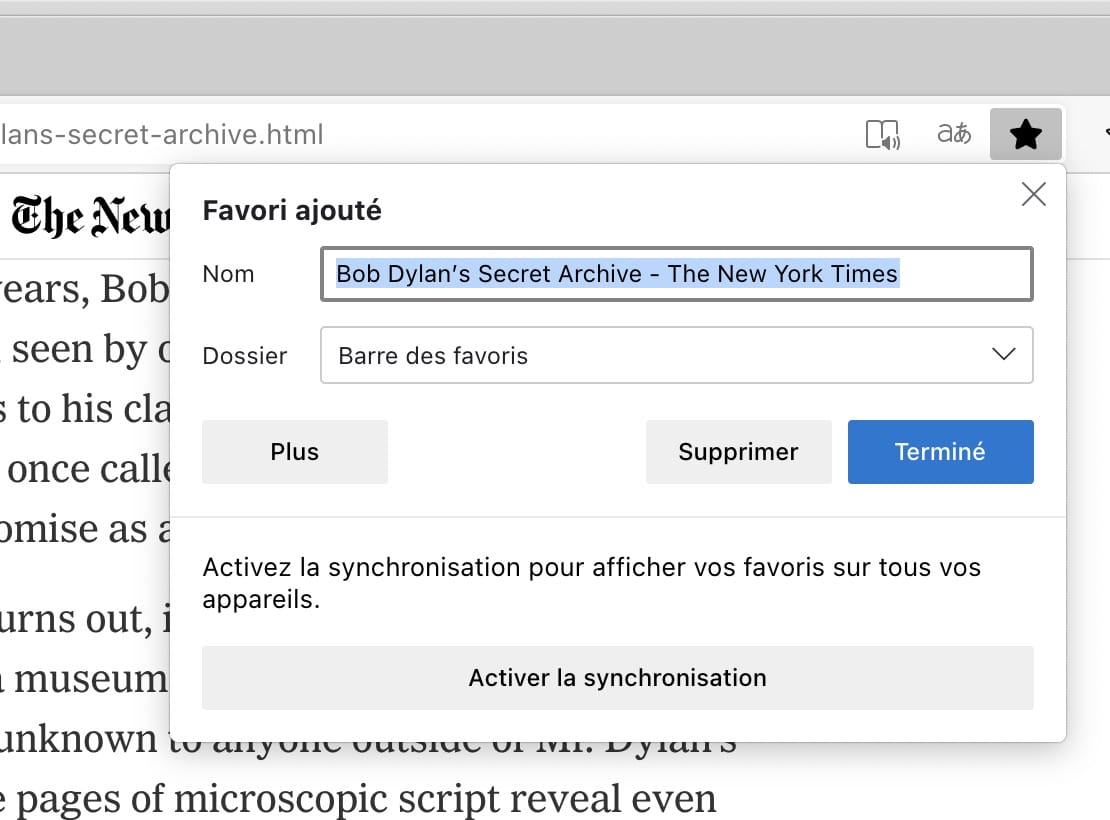
Safari offers something slightly more evolved with a Description field.
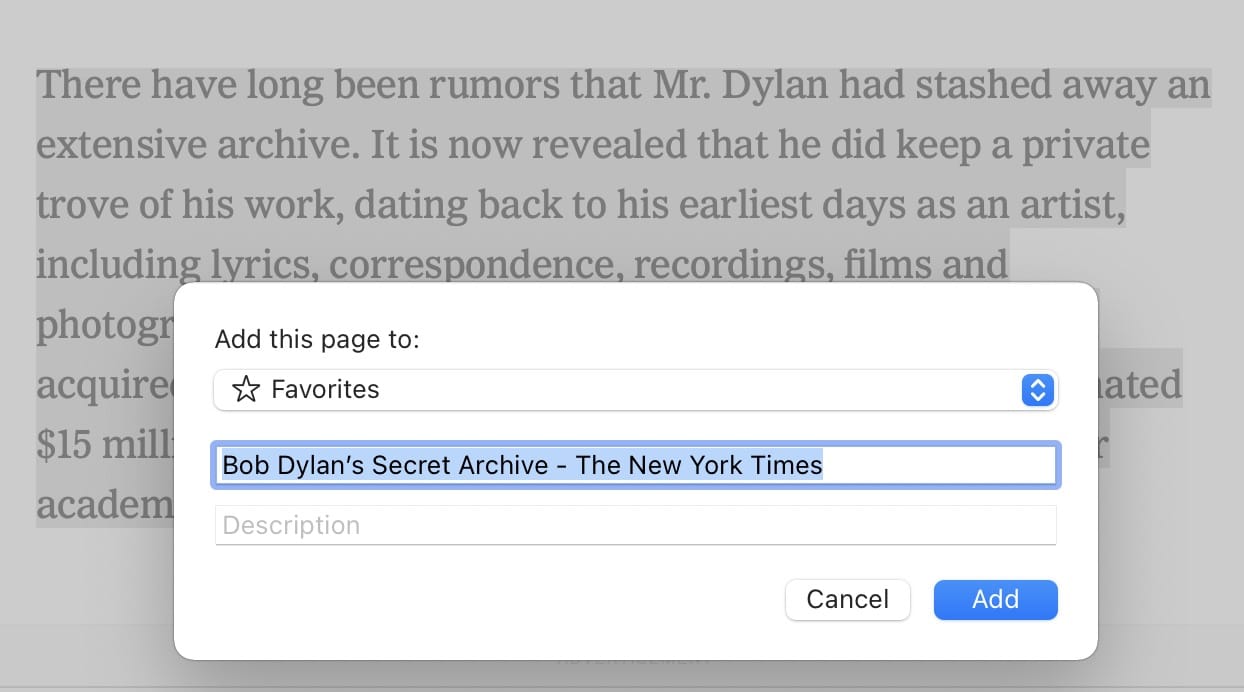
but none of them is satisfying for the Web drifters, the poets collecting memories, the archivists and the explorers. And it's unfortunate because it looks like such a low hanging fruit. It ties very much in my previous post about Browser Time Machine.
Bookmark This Selection
What I would like from the bookmark feature in the browser is the ability to not only bookmark the full page but be able to select a piece of the page that is reflected in the bookmark, be through the normal menu as we have seen above or through the contextual menu of the browser.

Then once the bookmarks are collected I can do full text searches on all the collected texts.
And yes, some add-ons exist, but I just wish the feature was native to the browser. And I do not want to rely on a third party service. My quotes are mine only and should not necessary be shared with a server on someone's else machine.
Memex which has very interesting features, but it is someone else service. Pocket (even if it belongs to Mozilla) is not answering my needs. I need to open an account, and it is someone's else server.
Otsukare!
Welcome!
New localizers
- Ibrahim of Hausa (ha) drove the Common Voice web part to completion shortly after he joined the community.
- Crowdsource Kurdish, and Amed of Kurmanji Kurdish (kmr) teamed up to finish the Common Voice site localization.
- Saltykimchi of Malay (ms) joins us from the Common Voice community.
- Ibrahimi of Pashto (ps) completed the Common Voice site localization in a few days!
- Reem of Swahili (sw) has been laser focused on the Terminology project.
Are you a locale leader and want us to include new members in our upcoming reports? Contact us!
New community/locales added
New content and projects
What’s new or coming up in Firefox desktop
First of all, let’s all congratulate the Silesian (szl) team for making their way into the official builds of Firefox. After spending several months in Nightly, they’re now ready for general audience and will ride the trains to Beta and Release with Firefox 87.
Upcoming deadlines:
- Firefox 86 is currently in Beta and will be released on February 23. The deadline to update localizations is on February 14.
- Firefox 87 is in Nightly and will move to Beta on February 22.
This means that, as of February 23, we’ll be only two cycles away from the next big release of Firefox (89), which will include the UI redesign internally called Proton. Several strings have already been exposed for localization, and you can start testing them – always in a new profile! – by manually setting these preferences to true in about:config:
- browser.proton.appmenu.enabled
- browser.proton.enabled
- browser.proton.tabs.enabled
It’s a constant work in progress, so expect the UI to change frequently, as new elements are added every few days.
One important thing to note: English will change several elements of the UI from Title Case to Sentence case. These changes will not require locales to retranslate all the strings, but it also expects each locale to have clearly defined rules in their style guides about the correct capitalization to use for each part of the UI. If your locale is following the same capitalization rules as en-US, then you’ll need to manually change these strings to match the updated version.
We’ll have more detailed follow-ups in the coming week about Proton, highlighting the key areas to test. In the meantime, make sure that your style guides are in good shape, and get in touch if you don’t know how to work on them in GitHub.
What’s new or coming up in mobile
You may have noticed some changes to the Firefox for Android (“Fenix”) release schedule – that affects in turn our l10n schedule for the project.
In fact, Firefox for Android is now mirroring the Firefox Desktop schedule (as much as possible). While you will notice that the Pontoon l10n deadlines are not quite the same between Firefox Android and Firefox Desktop, their release cadence will be the same, and this will help streamline our main products.
Firefox for iOS remains unchanged for now – although the team is aiming to streamline the release process as well. However, this also depends on Apple, so this may take more time to implement.
Concerning the Proton redesign (see section above about Desktop), we still do not know to what extent it will affect mobile. Stay tuned!
What’s new or coming up in web projects
Firefox Accounts:
The payment settings
In our previous post, An update on MDN Web Docs’ localization strategy, we explained our broad strategy for moving forward with allowing translation edits on MDN again. The MDN localization communities are waiting for news of our progress on unfreezing the top-tier locales, and here we are. In this post we’ll look at where we’ve got to so far in 2021, and what you can expect moving forward.
Normalizing slugs between locales
Previously on MDN, we allowed translators to localize document URL slugs as well as the document title and body content. This sounds good in principle, but has created a bunch of problems. It has resulted in situations where it is very difficult to keep document structures consistent.
If you want to change the structure or location of a set of documentation, it can be nearly impossible to verify that you’ve moved all of the localized versions along with the en-US versions — some of them will be under differently-named slugs both in the original and new locations, meaning that you’d have to spend time tracking them down, and time creating new parent pages with the correct slugs, etc.
As a knock-on effect, this has also resulted in a number of localized pages being orphaned (not being attached to any parent en-US pages), and a number of en-US pages being translated more than once (e.g. localized once under the existing en-US slug, and then again under a localized slug).
For example, the following table shows the top-level directories in the en-US locale as of Feb 1, 2021, compared to that of the fr locale.
en-US |
fr |
| games glossary learn mdn mozilla plugins related tools web webassembly |
accessibilit'e adaptation_des_applications_xul_pour_firefox_1.5 am'eliorations_dom_dans_firefox_3 am'eliorations_svg_dans_firefox_3 am'eliorations_xul_dans_firefox_3 apprendre astuces_css bugs_importants_corrig'es_dans_firefox_3 changements_dans_gecko_1.9_affectant_les_sites_web chrome comment_cr'eer_un_arbre_dom compilation_et_installation contr^oles_dhtml_personnalis'es_navigables_au_clavier css dhtml dom d'eveloppement_web explorer_un_tableau_html_avec_des_interfaces_dom_et_javascript faq_sur_les_transformations_xsl_dans_mozilla fuel games glossaire glossary html inset-block-end inset-block-start inset-inline-end inset-inline-start inspecteur_dom introduction_(alternative) introduction_`a_la_cryptographie_`a_clef_publique javascript jeux la_s'ecurit'e_dans_firefox_2 learn localization mdn mdn_a_dix_ans mise_`a_jour_des_applications_web_pour_firefox_3 mise_`a_jour_des_extensions_pour_firefox_2 mise_`a_jour_des_extensions_pour_firefox_3 mozilla navigatorusermedia.getusermedia npapi outils r'ef'erence_dom_gecko sgml svg_dans_firefox tosource tostring type_mime_incorrect_pour_les_fichiers_css un_raycaster_basique_avec_canvas utilisation_de_xpath utilisation_du_cache_de_firefox_1.5 web webapi webassembly webrtc xhtml xmlserializer xpcom xslt_dans_gecko xsltprocessor zoom_pleine_page `a_propos_du_document_object_model |
To make the non-en-US locales consistent and manageable, we are going to move to having en-US slugs only — all localized pages will be moved under their equivalent location in the en-US tree. In cases where that location cannot be reliably determined — e.g. where the documents are orphans or duplicates — we will put those documents into a specific storage directory, give them an appropriate prefix, and ask the maintenance communities for each unfrozen locale to sort out what to do with them.
- Every localized document will be kept in a separate repo to the
en-UScontent, but will have a correspondingen-USdocument with the same slug (folder path). - At first this will be enforced during deployment — we will move all the localized documents so that their locations are synchronized with their
en-USequivalents. Every document that does not have a correspondingen-USdocument will be prefixed withorphanedduring deployment. We plan to further automate this to check whenever a PR is created against the repo. We will also funnel back changes
The eminent Mike Taylor has dubbed us with one of his knightly tweets. Something something about
new interview question: on a whiteboard, re-implement the following in React (using the marker color of your choice)
Sir Bruce Lawson OM (Oh My…), a never ending disco knight, has commented about Mike's tweet, pointing out that:
the real test is your choice of marker colour. So, how would you go about making the right choice? Obviously, that depends where you’re interviewing.
I simply and firmly disagree and throw my gauntlet at Bruce's face. Choose your weapons, time and witnesses.
The important part of this tweet is how Mike Taylor points out how the Sillycon Valley industry is a just a pack of die-hard stick-in-the-mud reactionaries who have promoted the whiteboard to the pinnacle of one's dull abilities to regurgitate the most devitalizing Kardashianesque answers to stackoverflow problems. Young programmers! Rise! In front of the whiteboard, just walk out. Refuse the tiranny of the past, the chalk of ignorance.
Where are the humans, the progress? Where are the shores of the oceans, the C'elestin Freinet, Maria Montessori and A. S. Neill, the lychens, the moss and the humus, the sap of imagination, the liberty of our creativity.
Otsukare!
https://www.otsukare.info/2021/02/11/whiteboard-reactionaries
That’s --fail-with-body, using two dashes in front of the name.
This is a brand new command line option added to curl, to appear in the 7.76.0 release. This function works like --fail but with one little addition and I’m hoping the name should imply it good enough: it also provides the response body. The --fail option has turned out to be a surprisingly popular option but users have often repeated the request to also make it possible to get the body stored. --fail makes curl stop immediately after having received the response headers – if the response code says so.
--fail-with-body will instead first save the body per normal conventions and then return an error if the HTTP response code was 400 or larger.
To be used like this:
curl --fail-with-body -o output https://example.com/404.html
If the page is missing on that HTTPS server, curl will return exit code 22 and save the error message response in the file named ‘output’.
Not complicated at all. But has been requested many times!
This is curl’s 238th command line option.
The Rust team is happy to announce a new version of Rust, 1.50.0. Rust is a programming language that is empowering everyone to build reliable and efficient software.
If you have a previous version of Rust installed via rustup, getting Rust 1.50.0 is as easy as:
rustup update stable
If you don't have it already, you can get rustup
from the appropriate page on our website, and check out the
detailed release notes for 1.50.0 on GitHub.
What's in 1.50.0 stable
For this release, we have improved array indexing, expanded safe access to union fields, and added to the standard library. See the detailed release notes to learn about other changes not covered by this post.
Const-generic array indexing
Continuing the march toward stable const generics, this release adds
implementations of ops::Index and IndexMut for arrays [T; N] for
any length of const N. The indexing operator [] already worked on
arrays through built-in compiler magic, but at the type level, arrays
didn't actually implement the library traits until now.
fn second(container: &C) -> &C::Output
where
C: std::ops::Index + ?Sized,
{
&container[1]
}
fn main() {
let array: [i32; 3] = [1, 2, 3];
assert_eq!(second(&array[..]), &2); // slices worked before
assert_eq!(second(&array), &2); // now it also works directly
}
const value repetition for arrays
Arrays in Rust can be written either as a list [a, b, c] or a repetition [x; N].
For lengths N greater than one, repetition has only been allowed for xs that are Copy,
and RFC 2203 sought to allow any const expression there. However,
while that feature was unstable for arbitrary expressions, its implementation
since Rust 1.38 accidentally allowed stable use of const values in array
repetition.
fn main() {
// This is not allowed, because `Option>` does not implement `Copy`.
let array: [Option>; 10] = [None; 10];
const NONE: Option> = None;
const EMPTY: Option> = Some(Vec::new());
// However, repeating a `const` value is allowed!
let nones = [NONE; 10];
let empties = [EMPTY; 10];
}
In Rust 1.50, that stabilization is formally acknowledged. In the future, to avoid such "temporary" named
constants, you can look forward to inline const expressions per RFC 2920.
Safe assignments to ManuallyDrop union fields
Rust 1.49 made it possible to add ManuallyDrop fields to a union as part
of allowing Drop for unions at all. However, unions don't drop old values
when a field is assigned, since they don't know which variant was formerly
valid, so safe Rust previously limited this to Copy types only, which never Drop.
Of course, ManuallyDrop also doesn't need to Drop, so now Rust 1.50
allows safe assignments to these fields as well.
A niche for File on Unix platforms
Some types in Rust have specific limitations on what is considered a
valid value, which may not cover the entire range of possible memory
values. We call any remaining invalid value a niche, and this space
may be used for type layout optimizations. For example, in Rust 1.28
we introduced NonZero integer types (like

This image is a reference to the four-square Drake template – originally Drake holding up a hand and turning away from something disapprovingly in the top half, while pointing favorably to something else in the lower half – featuring Xzibit rather than Drake, himself meme-famous for “yo dawg we heard you like cars, so we put a car in your car so you can drive while you drive”, to whose recursive nature this image is of course an homage. In the upper left panel, Xzibit is looking away disappointedly from the upper right, which contains a painting by Pieter Bruegel the Elder of the biblical Tower Of Babel. In the lower left, Xzibit is now looking favorably towards an image of another deeply nested meme.
This particular meme features the lead singer from Nickelback holding up a picture frame, a still from the video of their song “Photograph”. The “you know I had to do it to ’em” guy is in the distant background. Inside, the frame is cut in four by a two-axis graph, with “authoritarian/libertarian” on the Y axis and “economic-left/economic-right” on the X axis, overlaid with the words “young man, take the breadsticks and run, I said young man, man door hand hook car gun“, a play on both an old bit about bailing out of a bad conversation while stealing breadsticks, the lyrics to The Village People’s “YMCA”, and adding “gun” to the end of some sentence to shock its audience. These lyrics are arranged within those four quadrants in a visual reference to “loss.jpg”, a widely derided four-panel webcomic from 2008.
Taken as a whole the image is an oblique comment on the Biblical “Tower Of Babel” reference, specifically Genesis 11, in which “… the Lord said, Behold, the people is one, and they have all one language; and this they begin to do: and now nothing will be restrained from them, which they have imagined to do. Go to, let us go down, and there confound their language, that they may not understand one another’s speech” and the proliferation of deeply nested and frequently incomprehensible memes as a form of explicitly intra-generational communication.
So, yeah, there’s a lot going on in there.
I asked about using alt-text for captioning images like that in a few different forums the other day, to learn what the right thing is with respect to memes or jokes. If the image is the joke, is it useful (or expected) that the caption is written to try to deliver the joke, rather than be purely descriptive?
On the one hand, I’d expect you want the punchline to land, but I also want the caption to be usable and useful, and I assume that there are cultural assumptions and expectations in this space that I’m unaware of.
As intended, the question I asked wasn’t so much about “giving away” the punchline as it is about ensuring its delivery; either way you have to give away the joke, but does an image description phrased as a joke help, or hinder (or accidentally insult?) its intended audience?
I’m paraphrasing, but a few of the answers all said sort of the same useful and insightful thing: “The tool is the description of the image; the goal is to include people in the conversation. Use the tool to accomplish the goal.”
Which I kind of love.
And in what should not have stopped surprising me ages ago but still but consistently does, I was reminded that accessibility efforts support people far outside their intended
Over the last few years, Mozilla has turned its attention to AI, asking: how can we make the data driven technologies we all use everyday more trustworthy? How can we make things like social networks, home assistants and search engines both more helpful and less harmful in the era ahead?
In 2021, we will take a next step with this work by digging deeper in three areas where we think we can make real progress: transparency, bias and better data governance. While these may feel like big, abstract concepts at first glance, all three are at the heart of problems we hear about everyday in the news: problems that are top of mind not just in tech circles, but also amongst policy makers, business leaders and the public at large.
Think about this: we know that social networks are driving misinformation and political divisions around the world. And there is growing consensus that we urgently need to do something to fix this. Yet we can’t easily see inside — we can’t scrutinize — the AI that drives these platforms, making genuine fixes and real accountability impossible. Researchers, policy makers and developers need to be able to see how these systems work (transparency) if we’re going to tackle this issue.
Or, this: we know that AI driven technology can discriminate, exclude or otherwise harm some people more than others. And, as automated systems become commonplace in everything from online advertising to financial services to policing, the impact of these systems becomes ever more real. We need to look at how systemic racism and the lack of diversity in the tech industry sits at the root of these problems (bias). Concretely, we also need to build tools to detect and mitigate bias — and to build for inclusivity — within the technologies that we use everyday.
And, finally, this: we know the constant collection of data about what we do online makes (most of) us deeply uncomfortable. And we know that current data collection practices are at the heart of many of the problems we face with tech today, including misinformation and discrimination. Yet there are few examples of technology that works differently. We need to develop new methods that use AI and data in a way that respects us as people, and that gives us power over the data collected about us (better data governance) — and then using these new methods to create alternatives to the online products and services we all use today.
Late last year, we zeroed in on transparency, bias and data governance for the reasons suggested above — each of these areas are central to the biggest ‘technology meets society’ issues that we face today. There is growing consensus that we need to tackle these issues. Importantly, we believe that this widespread awareness creates a unique opportunity for us to act: to build products, write laws and develop norms that result in a very different digital world. Over the next few years, we have a chance to make real progress towards more trustworthy AI — and a better internet — overall.
This opportunity for action — the chance to make the internet different and better — has shaped how we think about the next steps in our work. Practically, the teams within Mozilla Foundation are organizing our 2021 work around objectives tied to these themes:
- Test AI transparency best practices to increase adoption by builders and policymakers.
- Accelerate the impact of people working to mitigate bias in AI.
- Accelerate equitable data governance alternatives as a way to advance trustworthy AI.
These teams are also focusing on collaborating with others across the internet health movement — and with people in other social movements — to make progress on these issues. We’ve set a specific 2021 objective to ‘partner with diverse movements at the intersection of their primary issues and trustworthy AI’.
We already have momentum — and work underway — on all of these topics, although more with some than others. We spent much of last year developing initiatives related to better data governance, including the Data Futures Lab, which announced its first round of grantee partners in December. And, also in
Dating during a global pandemic is the definition of “it’s complicated”. Between the screen fatigue and social distancing, meeting someone in today’s world feels impossible. Yet, people are still finding … Read more
The post Love lockdown: Four people reveal how they stay privacy-aware while using dating apps appeared first on The Firefox Frontier.
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
Official
- [Foundation] Hello World!
- [Inside] 1.50.0 pre-release testing
Newsletters
Project/Tooling Updates
- rust-analyzer Changelog #63
- Launching wasm.rs: a collection of crates, a community
- A Memory Safe TLS Module for the Apache HTTP Server
Observations/Thoughts
- Benchmarking Tokio Tasks and Goroutines
- A Better Rust Profiler
- An unsafe tour of Rust's Send and Sync
- Improving texture atlas allocation in WebRender
Rust Walkthroughs
- Async Rust: Futures, Tasks, Wakers; Oh My!
- Rust for Haskell Programmers!
- Rust CLI Game of Life tutorial - Part 1
- Where everything went wrong...
- Rust for Clojurists
- [ES] El formato RON: Rusty Object Notation
- [video] 1Password Developer Fireside Chat: Introduction to Rust Macros
- [video] Dynamic vs Static Dispatch in Rust
Miscellaneous
- Congratulations, Rustaceans, on the creation of the Rust Foundation!
- Microsoft joins Rust Foundation
- Google joins the Rust Foundation
- Mozilla Welcomes the Rust Foundation
- Trusted Programming - Our Rust Mission at Huawei
- YSK: VSCode's most recent update fixed a quirk in Rust workflows
- curl supports rustls
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla uses to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as Glean inspires it. You can find an index of all TWiG posts online.)
Data ingestion is a process that involves decompressing, validating, and transforming millions of documents every hour. The schemas of data coming into our systems are ever-evolving, sometimes causing partial outages of data availability when the conditions are ripe. Once the outage has been resolved, we run a backfill to fill in the gaps for all the missing data. In this post, I’ll discuss the error discovery and recovery processes through a recent bug.
Catching and fixing the error
Every Monday, a group of data engineers pours over a set of dashboards and plots indicating data ingestion health. On 2020-08-04, we filed a bug where we observed an elevated rate of schema validation errors coming from environment/system/gfx/adapters/N/GPUActive. For mistakes like these that are small fractions of our overall volume, partial outages are typically not urgent (as in not “we need to drop everything right now and resolve this stat!” critical). We called the subject experts and found out that the code responsible for reporting multiple GPUs in the environment had changed.
An intern reached out to me about a DNS study running a few weeks after filing the bug about GPUActive. I helped figure out that his external monitor setup with his Macbook was causing rejections like the ones that we had seen weeks before. One PR and one deploy later, I watched the error rates for the GPUActive field abruptly drop to zero.

Figure: Error counts for environment/system/gfx/adapters/N/GPUActive
The schema’s misspecification resulted in 4.1 million documents between 2020-07-04 and 2020-08-20 to be sent to our error stream, awaiting reprocessing.
Running a backfill
In January of 2021, we ran the backfill of the GPUActive rejects. First, we determined the backfill range by querying the relevant error table:
SELECT DATE(submission_timestamp) AS dt, COUNT(*)FROM `moz-fx-data-shared-prod.payload_bytes_error.telemetry`WHERE submission_timestamp < '2020-08-21' AND submission_timestamp > '2020-07-03' AND exception_class = 'org.everit.json.schema.ValidationException' AND error_message LIKE '%GPUActive%'GROUP BY 1ORDER BY 1 |
The query helped verify the date range of the errors and their counts: 2020-07-04 through 2020-08-20. The following tables were affected:
crashdnssec-study-v1eventfirst-shutdownheartbeatmainmodulesnew-profileupdatevoice |
We isolated the error documents into a backfill project named moz-fx-data-backfill-7 and mirrored our production BigQuery datasets and tables into it.
SELECT *FROM `moz-fx-data-shared-prod.payload_bytes_error.telemetry`WHERE DATE(submission_timestamp) BETWEEN "2020-07-04" AND "2020-08-20" AND exception_class = 'org.everit.json.schema.ValidationException' AND error_message LIKE '%GPUActive%' |
Then we ran a suitable Dataflow job to populate our tables using the same ingestion code as the production jobs. It took about 31 minutes to run to completion. We copied and deduplicated the data into a dataset that mirrored our