These days, smartphones are in just about everyone’s pocket. We use them for entertainment, sending messages, storing notes, taking photos, transferring money and even making the odd phone call. Our … Read more
The post Mozilla Explains: SIM swapping appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/mozilla-explains-sim-swapping/
I have a lot of different hats and roles in the curl project. One of them is “release manager” and in this post I’ve tried to write down pretty much all the steps I do to prepare and ship a curl release at the end of every release cycle in the project.
I’ve handled every curl release so far. All 198 of them. While the process certainly wasn’t this formal or extensive in the beginning, we’ve established a set of steps that have worked fine for us, that have been mostly unchanged for maybe ten years by now.
There’s nothing strange or magic about it. Just a process.
Release cycle
A typical cycle between two releases starts on a Wednesday when we do a release. We always release on Wednesdays. A complete and undisturbed release cycle is always exactly 8 weeks (56 days).
The cycle starts with us taking the remainder of the release week to observe the incoming reports to judge if there’s a need for a follow-up patch release or if we can open up for merging features again.
If there was no significant enough problems found in the first few days, we open the “feature window” again on the Monday following the release. Having the feature window open means that we accept new changes and new features getting merged – if anyone submits such a pull-request in a shape ready for merge.
If there was an issue found to be important enough to a warrant a patch release, we instead schedule a new release date and make the coming cycle really short and without opening the feature window. There aren’t any set rules or guidelines to help us judge this. We play this by ear and go with what feels like the right action for our users.
Closing the feature window

When there’s exactly 4 weeks left to the pending release we close the feature window. This gives us a period where we only merge bug-fixes and all features are put on hold until the window opens again. 28 days to polish off all sharp corners and fix as many problems we can for the coming release.
Contributors can still submit pull-requests for new stuff and we can review them and polish them, but they will not be merged until the window is reopened. This period is for focusing on bug-fixes.
We have a web page that shows the feature window’s status and I email the mailing list when the status changes.
Slow down
A few days before the pending release we try to slow down and only merge important bug-fixes and maybe hold off the less important ones to reduce risk.
This is a good time to run our copyright.pl script that checks copyright ranges of all files in the git repository and makes sure they are in sync with recent changes. We only update the copyright year ranges of files that we actually changed this year.
Security fixes
If we have pending security fixes to announce in the coming release, those have been worked on in private by the curl security team. Since all our test infrastructure is public we merge our security fixes into the main source code and push them approximately 48 hours before the planned release.
These 48 hours are necessary for CI and automatic build jobs to verify the fixes and still give us time to react to problems this process reveals and the subsequent updates and rinse-repeats etc until everyone is happy. All this testing is done using public code and open infrastructure, which is why we need the code to be pushed for this to work.
At this time we also have detailed security advisories written for each vulnerability that are ready to get published. The advisories are stored in the website repository and have been polished by the curl security team and the reporters of the issues.
Release notes
The release notes for the pending release is a document that we keep in sync and updated at a regular interval so that users have a decent idea of what to expect in the coming release – at all times.
It is basically a matter of running the release-notes.pl script, clean up the list of bug-fixes, then the run
My week is very scheduled, so I am not able to host any public drafting sessions this week – however, Ryan Levick will be hosting two sessions!
| When | Who | Topic |
|---|---|---|
| Thu at 07:00 ET | Ryan | The need for Async Traits |
| Fri at 07:00 ET | Ryan | Challenges from cancellation |
If you’re available and those stories sound like something that interests you, please join him! Just ping me or Ryan on Discord or Zulip and we’ll send you the Zoom link. If you’ve already joined a previous session, the link is the same as before.
Sneak peek: Next week
Next week, we will be holding more vision doc writing sessions. We are now going to expand the scope to go beyond “status quo” stories and cover “shiny future” stories as well. Keep your eyes peeled for a post on the Rust blog and further updates!
The vision…what?
Never heard of the async vision doc? It’s a new thing we’re trying as part of the Async Foundations Working Group:
We are launching a collaborative effort to build a shared vision document for Async Rust. Our goal is to engage the entire community in a collective act of the imagination: how can we make the end-to-end experience of using Async I/O not only a pragmatic choice, but a joyful one?
Read the full blog post for more.
http://smallcultfollowing.com/babysteps/blog/2021/04/07/async-vision-doc-writing-sessions-iv/
In September 2018 I celebrated 10,000 stars, up from 5,000 back in May 2017. We made 1,000 stars on August 12, 2014.
Today I’m cheering for the 20,000 stars curl has received on GitHub.
It is worth repeating that this is just a number without any particular meaning or importance. It just means 20,000 GitHub users clicked the star symbol for the curl project over at curl/curl.
At exactly 08:15:23 UTC today we reached this milestone. Checked with a curl command line like this:
$ curl -s https://api.github.com/repos/curl/curl | jq '.stargazers_count' 20000
(By the time I get around to finalize this post, the count has already gone up to 20087…)
To celebrate this occasion, I decided I was worth a beer and this time I went with a hand-written note. The beer was a Swedish hazy IPA called Amazing Haze from the brewery Stigbergets. One of my current favorites.

Photos from previous GitHub-star celebrations :


We successfully deployed ThreadSanitizer in the Firefox project to eliminate data races in our remaining C/C++ components. In the process, we found several impactful bugs and can safely say that data races are often underestimated in terms of their impact on program correctness. We recommend that all multithreaded C/C++ projects adopt the ThreadSanitizer tool to enhance code quality.
What is ThreadSanitizer?
ThreadSanitizer (TSan) is compile-time instrumentation to detect data races according to the C/C++ memory model on Linux. It is important to note that these data races are considered undefined behavior within the C/C++ specification. As such, the compiler is free to assume that data races do not happen and perform optimizations under that assumption. Detecting bugs resulting from such optimizations can be hard, and data races often have an intermittent nature due to thread scheduling.
Without a tool like ThreadSanitizer, even the most experienced developers can spend hours on locating such a bug. With ThreadSanitizer, you get a comprehensive data race report that often contains all of the information needed to fix the problem.
 ThreadSanitizer Output for this example program (shortened for article)
ThreadSanitizer Output for this example program (shortened for article)
One important property of TSan is that, when properly deployed, the data race detection does not produce false positives. This is incredibly important for tool adoption, as developers quickly lose faith in tools that produce uncertain results.
Like other sanitizers, TSan is built into Clang and can be used with any recent Clang/LLVM toolchain. If your C/C++ project already uses e.g. AddressSanitizer (which we also highly recommend), deploying ThreadSanitizer will be very straightforward from a toolchain perspective.
Challenges in Deployment
Benign vs. Impactful Bugs
Despite ThreadSanitizer being a very well designed tool, we had to overcome a variety of challenges at Mozilla during the deployment phase. The most significant issue we faced was that it is really difficult to prove that data races are actually harmful at all and that they impact the everyday use of Firefox. In particular, the term “benign” came up often. Benign data races acknowledge that a particular data race is actually a race, but assume that it does not have any negative side effects.
While benign data races do exist, we found (in agreement with previous work on this subject [1] [2]) that data races are very easily misclassified as benign. The reasons for this are clear: It is hard to reason about what compilers can and will optimize, and confirmation for certain “benign” data races requires you to look at the assembler code that the compiler finally produces.
Needless to say, this procedure is often much more time consuming than fixing the actual data race and also not future-proof. As a result, we decided that the ultimate goal should be a “no data races” policy that declares even benign data races as undesirable due to their risk of misclassification, the required time for investigation and the potential risk from future compilers (with better optimizations) or future platforms (e.g. ARM).
However, it was clear that establishing such a policy would require a lot of work, both on the technical side as well as in convincing developers and management. In particular, we could not expect a large amount of resources to be dedicated to fixing data races with no clear product impact. This is where TSan’s suppression list came in handy:
We knew we had to stop the influx of new data races but at the same time get the tool usable without fixing all legacy issues. The suppression list (in particular the version compiled into Firefox) allowed us to temporarily ignore data races once we had them on file and ultimately
If it ain’t broke don’t fix it.
This old addage is valuable advice that has been passed down through generations. But it hasn’t stopped these people from rewriting command line tools perfected 30+ years ago in Rust.
This week we’ll take a quick look at exa, a replacement for ls. So why
should you ignore the wise advice from the addage and replace ls? Because there are marginal
improvements to be had, duh! Although the improvements in this case are far from marginal.
In an important victory for software developers, the Supreme Court ruled today that reimplementing an API is fair use under US copyright law. The Court’s reasoning should apply to all cases where developers reimplement an API, to enable interoperability, or to allow developers to use familiar commands. This resolves years of uncertainty, and will enable more competition and follow-on innovation in software.

Yes you would – Credit: Parker Higgins (https://twitter.com/XOR)
This ruling arrives after more than ten years of litigation, including two trials and two appellate rulings from the Federal Circuit. Mozilla, together with other amici, filed several briefs throughout this time because we believed the rulings were at odds with how software is developed, and could hinder the industry. Fortunately, in a 6-2 decision authored by Justice Breyer, the Supreme Court overturned the Federal Circuit’s error.
When the case reached the Supreme Court, Mozilla filed an amicus brief arguing that APIs should not be copyrightable or, alternatively, reimplementation of APIs should be covered by fair use. The Court took the second of these options:
We reach the conclusion that in this case, where Google reimplemented a user interface, taking only what was needed to allow users to put their accrued talents to work in a new and transformative program, Google’s copying of the Sun Java API was a fair use of that material as a matter of law.
In reaching his conclusion, Justice Breyer noted that reimplementing an API “can further the development of computer programs.” This is because it enables programmers to use their knowledge and skills to build new software. The value of APIs is not so much in the creative content of the API itself (e.g. whether a particular API is “Java.lang.Math.max” or, as the Federal Circuit once suggested as an alternative, ““Java.lang.Arith.Larger”) but in the acquired experience of the developer community that uses it.
We are pleased that the Supreme Court has reached this decision and that copyright will no longer stand in the way of software developers reimplementing APIs in socially, technologically, and economically beneficial ways.
The post Software Innovation Prevails in Landmark Supreme Court Ruling in Google v. Oracle appeared first on The Mozilla Blog.
Every time you visit a website and it seems to remember you, that’s a cookie at work. You might have heard that all cookies are bad, but reality is a … Read more
The post Mozilla Explains: Cookies and supercookies appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/mozilla-explains-cookies-and-supercookies/
I decided not to post this on April Fools Day since a lot of people were hoping the last post was a mistimed April Fools prank, and it wasn't. For one thing, I've never worked that hard on an April Fools joke, even the time when I changed the printer READY messages all over campus to say INSERT FIVE CENTS.
Anyway, the beta for the final TenFourFox Feature Parity Release, FPR32, is now available (downloads, hashes, release notes). This release adds another special preference dialogue for auto reader view, allowing you to automatically jump to reader view for subpages or all pages of domains you enter. I also updated Readability, the underlying Reader View library, to the current tip and also refreshed the ATSUI font blocklist. It will become final on or about April 20 parallel to Firefox 88.
I received lots of kind messages which I have been replying to. Many people appreciated that they could use their hardware for longer, even if they themselves are no longer using their Power Macs, and I even heard about a iMac G4 that is currently a TenFourFox-powered kiosk. I'm willing to bet there are actually a number of these systems hauled out of the closet easily serving such purposes by displaying a ticker or dashboard that can be tweaked to render quickly.
Don't forget, though, that even after September 7 I will still make intermittent updates (primarily security-based) for my own use which will be public and you can use them too. However, as I mentioned, you'll need to build the browser yourself, and since it will only be on a rolling basis (I won't be doing specific versions or tags), you can decide how often you want to update your own local copy. I'll make a note here on the blog when I've done a new batch so that your feedreader can alert you if you aren't watching the Github repository already. The first such batch is a near certainty since it will be me changing the certificate roots to 91ESR.
If you come up with simpler or better build instructions, I'm all ears.
I'm also willing to point people to third-party builds. If you're able to do it and want to take on the task, and don't mind others downloading it, post in the comments. You declare how often you want to do it and which set of systems you want to do it for. The more builders the merrier so that the load can be shared and people can specialize in the systems they most care about.
As a last comment, a few people have asked what it would take to get later versions (52ESR, etc.) to run on Power Macs. Fine, here's a summarized to-do list. None of them are (probably) technically impossible; the real issue is the amount of time required and the ongoing burden needed, plus any unexpected regressions you'd incur. (See also the flap over the sudden Rust requirement for the Python cryptography library, an analogous situation which broke a number of other platforms of similar vintage.)
- Upgrade gcc and validate it.
- Transplant the 32-bit PowerPC JIT to 52's JavaScript. This isn't automatic because you would need to add any new code to the backend required by Ion, and there are some hacks in the source to fix various assumptions SpiderMonkey makes that have to be rechecked and carried forward. There are also some endian fixes. You could get around this by making it interpreter-only, but since much of the browser itself is written in JavaScript, everything will slow down, not just web pages. This task is additionally complicated by our post-45 changes which would need to be undone.
- Transplant the local Cocoa widget changes and merge them with any additional OS support Mozilla added. There are a lot of these patches; some portions were completely rewritten for 10.4 or use old code I dragged along from version to version. A couple people proposed an X11-only version to get around this too. You should be able to do this, and it would probably work, but the code needs some adjustment to deal with the fact it's running on Mac OS X but not with a Cocoa widget system. There are a number of places you would need to manually patch, though this is mostly tedium and not terribly complex.
- The 2D drawing backend changed from CoreGraphics to Skia for technical reasons. Unfortunately, Skia at the time had a lot of problems on big endian and didn't compile properly with 10.4. The former problem might
tldr: the level of HTTP/3 support in servers are surprisingly high considering very few clients enable it by default.
The specs
The specifications are all done. They’re now waiting in queues to get their final edits and approvals before they will get assigned RFC numbers and get published as such – they will not change any further. That’s a set of RFCs (six I believe) for various aspects of this new stack. The HTTP/3 spec is just one of those. Remember: HTTP/3 is the application protocol done over the new transport QUIC. (See http3 explained for a high-level description.)
The HTTP/3 spec was written to refer to, and thus depend on, two other HTTP specs that are in the works: httpbis-cache and https-semantics. Those two are mostly clarifications and cleanups of older HTTP specs, but this forces the HTTP/3 spec to have to get published after the other two, which might introduce a small delay compared to the other QUIC documents.
The working group has started to take on work on new specifications for extensions and improvements beyond QUIC version 1.
HTTP/3 Usage
In early April 2021, the usage of QUIC and HTTP/3 in the world is measured by a few different companies.
QUIC support
netray.io scans the IPv4 address space weekly and checks how many hosts that speak QUIC. Their latest scan found 2.1 million such hosts.
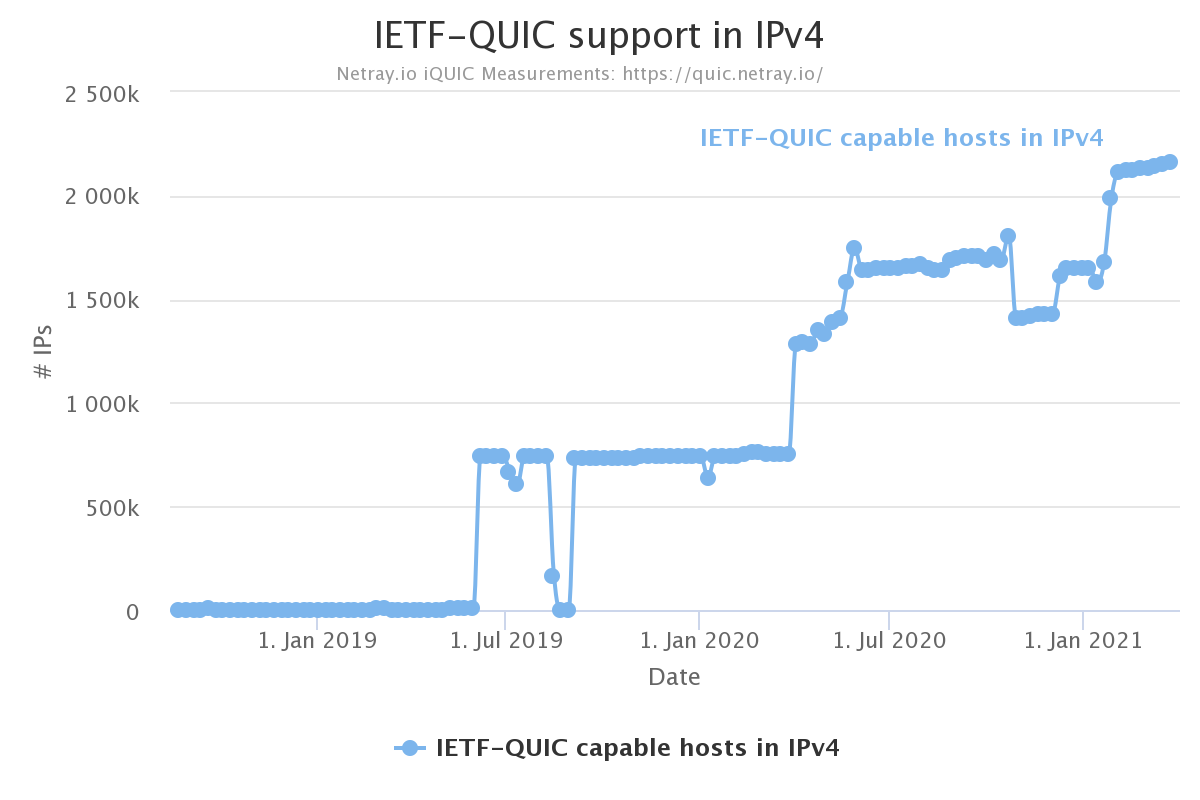
Arguably, the netray number doesn’t say much. Those two million hosts could be very well used or barely used machines.
HTTP/3 by w3techs
w3techs.com has been in the game of scanning web sites for stats purposes for a long time. They scan the top ten million sites and count how large share that runs/supports what technologies and they also check for HTTP/3. In their data they call the old Google QUIC for just “QUIC” which is confusing but that should be seen as the precursor to HTTP/3.
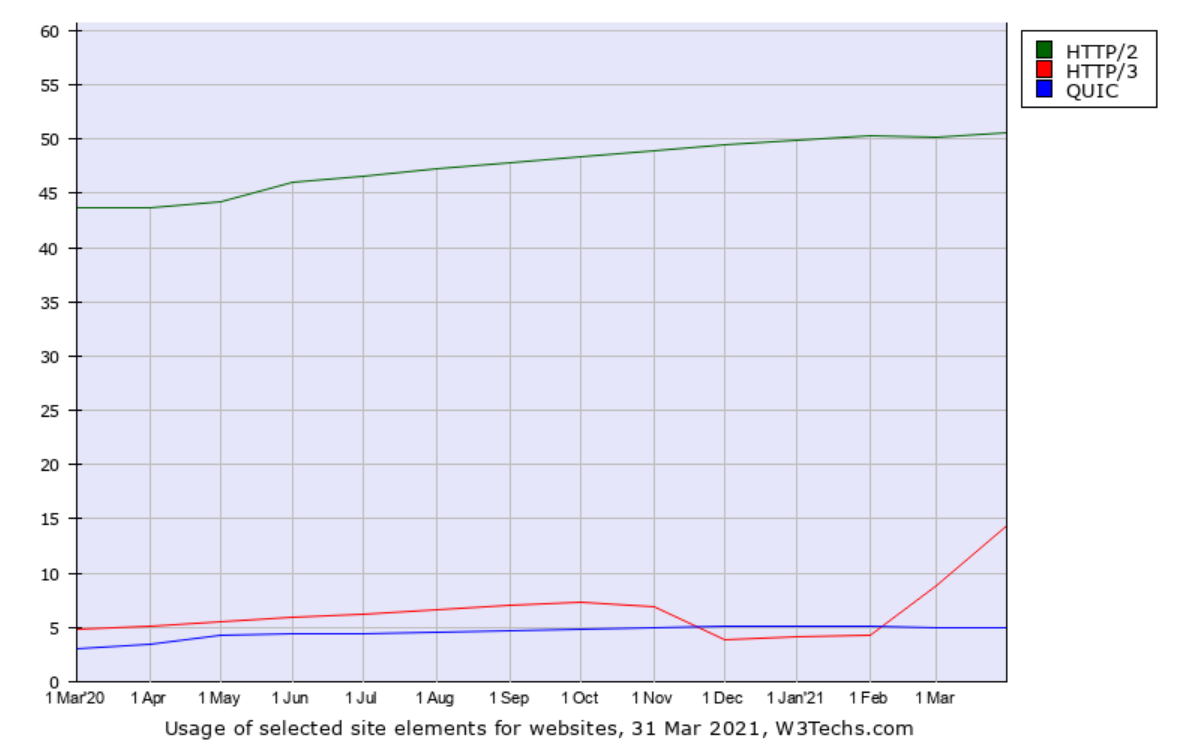
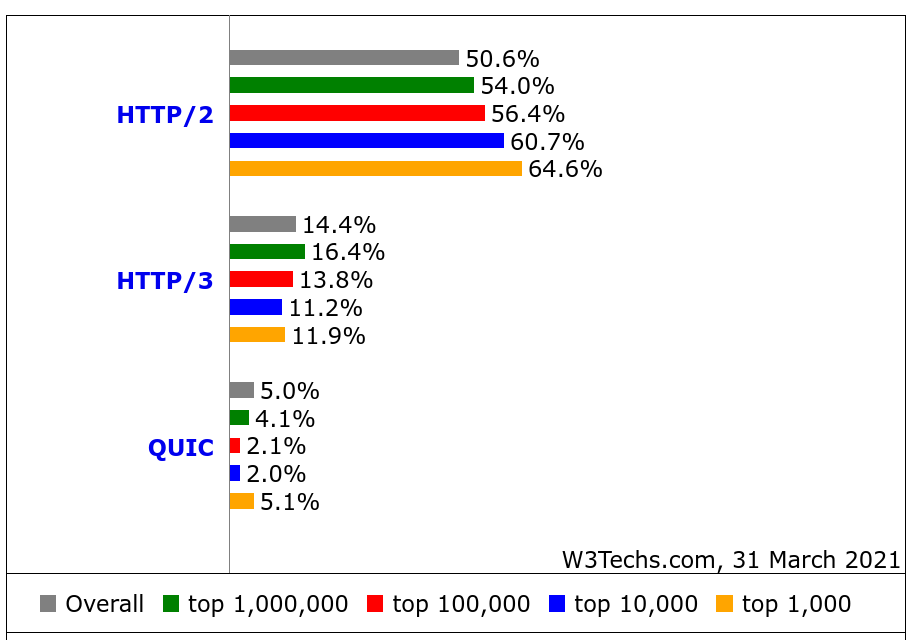
What stands out to me in this data except that the HTTP/3 usage seems very high: the top one-million sites are claimed to have a higher share of HTTP/3 support (16.4%) than the top one-thousand (11.9%)! That’s the reversed for HTTP/2 and not how stats like this tend to look.
It has been suggested that the growth starting at Feb 2021 might be explained by Cloudflare’s enabling of HTTP/3 for users also in their free plan.
HTTP/3 by Cloudflare
On radar.cloudflare.com we can see Cloudflare’s view of a lot of Internet and protocol trends over the world.
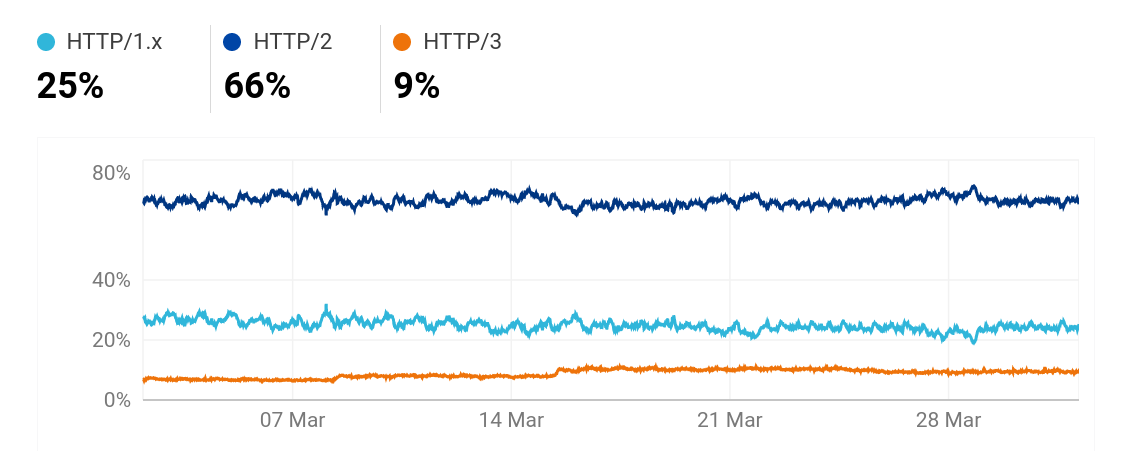
This HTTP/3 number is significantly lower than w3techs’. Presumably because of the differences in how they measure.
Clients
The browsers
All the major browsers have HTTP/3 implementations and most of them allow you to manually enable it if it isn’t already done so. Chrome and Edge have it enabled by default and Firefox will so very soon. The caniuse.com site shows it like this (updated on April 4):

(Earlier versions of this blog post showed the previous and inaccurate data from caniuse.com. Not anymore.)
curl
For the last couple of years, we’ve run the MDN Web Developer Needs Assessment (DNA) Report, which aims to highlight the key issues faced by developers building web sites and applications. This has proved to be an invaluable source of data for browser vendors and other organizations to prioritize improvements to the web platform. This year we did a deep dive into web testing, and we are delighted to be able to announce the publication of this follow-on work, available at our insights.developer.mozilla.org site along with our other Web DNA publications.
Why web testing?
In the Web DNA studies for 2019 and 2020, developers ranked the need “Having to support specific browsers, (e.g., IE11)” as the most frustrating aspect of web development, among 28 needs. The 2nd and 3rd rankings were also related to browser compatibility:
- Avoiding or removing a feature that doesn’t work across browsers
- Making a design look/work the same across browsers
In 2020, we released our browser compatibility research results — a deeper dive into identifying specific issues around browser compatibility and pinpointing what can be done to mitigate these issues.
This year we decided to follow up with another deep dive focused on the 4th most frustrating aspect of developing for the web, “Testing across browsers.” It follows on nicely from the previous deep dive, and also concerns much-sought-after information.
You can download this report directly — see the Web Testing Report (PDF, 0.6MB).
A new question for 2020
Based on the 2019 ranking of “testing across browsers”, we introduced a new question to the DNA survey in 2020: “What are the biggest pain points for you when it comes to web testing?” We wanted to understand more about this need and what some of the underlying issues are.
Respondents could choose one or more of the following answers:
- Time spent on manual testing (e.g. due to lack of automation).
- Slow-running tests.
- Running tests across multiple browsers.
- Test failures are hard to debug or reproduce.
- Lack of debug tooling support (browser dev tools or IDE integration).
- Difficulty diagnosing performance issues.
- Tests are difficult to write.
- Difficult to set up an adequate test environment.
- No pain points.
- Other.
Results summary
7.5% of respondents (out of 6,645) said they don’t have pain points with web testing. For those who did, the biggest pain point is the time spent on manual testing.
To better understand the nuances behind these results, we ran a qualitative study on web testing. The study consisted of twenty one-hour interviews with web developers who took the 2020 DNA survey and agreed to participate in follow-up research.
The results will help browser vendors understand whether to accelerate work on WebDriver Bidirectional Protocol (BiDi) or if the unmet needs lie elsewhere. Our analysis on WebDriver BiDi is based on the assumption that the feature gap between single-browser test tooling and cross-browser test tooling is a source of pain. Future research on the struggles developers have will be able to focus the priorities and technical design of that specification to address the pain points.
Key Takeaways
- In the 2020 Web DNA report, we included the results of a segmentation study. One of the seven segments that emerged was “Testing Technicians”. The name implies that the segment does testing and therefore finds frustration while doing tests. This is correct, but what’s also true is that developers commonly see a high entry barrier to testing, which contributes to their frustration.
- Defining a testing workflow, choosing tools, writing tests, and running tests all take time. Many developers face pressure to develop and launch products under tight deadlines. Testing or not testing is a tradeoff between the perceived value that testing adds compared to the time it will take to implement.
- Some developers are aware of testing but limited by their lack of knowledge in the area. This lack of knowledge is a barrier to successfully implementing a testing strategy. Other developers are aware of what testing is and how to do it, but they still consider it
Git-cinnabar is a git remote helper to interact with mercurial repositories. It allows to clone, pull and push from/to mercurial remote repositories, using git.
These release notes are also available on the git-cinnabar wiki.
What’s new since 0.5.6?
- Updated git to 2.31.1 for the helper.
- When using git >= 2.31.0,
git -c config=value ...works again. - Minor fixes.
tl;dr: Happy 23rd birthday, Mozilla. And for the question: yes.
Here's a bit more rambling on this topic...
First of all, the Mozilla project was officially started on March 31, 1998, which is 23 years ago today. Happy birthday to my favorite "dino" out there! For more background, take a look at my Mozilla History talk from this year's FOSDEM, and/or watch the "Code Rush" documentary that conserved that moment in time so well and also gives nice insight into late-90's Silicon Valley culture.
Now, while Mozilla initially was there to "act as the virtual meeting place for the Mozilla code" as Netscape was still there with the target to win back the browser market that was slipping over to Micosoft. The revolutionary stance to develop a large consumer application in the open along with the marketing of "hack - this technology could fall into the right hands" as well as the general novenly of the open-source movement back then - and last not least a very friendly community (as I could find out myself) made this young project grow fast to be more than a development vehicle for AOL/Netscape, though. And in 2003, a mission to "preserve choice and innovation on the Internet" was set up for the project, shortly after backed by a non-profit Mozilla Foundation, and then with an independently developed Firefox browser, implementing "the idea [...] to design the best web browser for most people" - and starting to take back the web from the stagnation and lack of choice represented by >95% of the landscape being dominated by Microsoft Internet Explorer.
The exact phrasing of Mozilla's mission has been massages a few times, but from the view of the core contributors, it always meant the same thing, it currently reads:
So, if we think about the question whether we still need Mozilla nowadays, we should take a look if moving in that direction is still required and helpful, and if Mozilla is still able and willing to push those principles forward.
When quite a few communities I'm part of - or would like to be part of - are moving to Discord or are adding it as an additional option to Facebook groups, and I read the Terms of Services of those two tightly closed and privacy-unfriendly services, I have to conclude that the current Internet is not open, not putting people first, and I don't feel neither empowered, safe or independent in that space. When YouTube selects recommendations so I live in a weird bubble that pulls me into conspiracies and negativity pretty fast, I don't feel like individuals can shape their own experience. When watching videos stored on certain sites is cheaper or less throttled than other sources with any new data plan I can get for my phone, or when geoblocking hinders me from watching even a trailer of my favorite series, I don't feel like the Internet is equally accessible to all. Neither do I when political misinformation is targeted at certain groups of users in election ads on social networks without any transparency to the public. But I would long for that all to be different, and to follow the principles I talked of above. So, I'd say those are still required, and would be helpful to push for.
It all feels like we need someone to unfck the Internet right now more than ever. We need someone to collect info on what's wrong and how it could get better there. We need someone to educate users, companies and politicians alike on where the dangers are and how we can improve the digital space. We need someone who
Firefox gained a way to trigger chardetng from the Text Encoding menu in Firefox 86. In this post, I examine both telemetry from Firefox 86 related to the Text Encoding menu and telemetry related to chardetng running automatically (without the menu).
The questions I’d like to answer are:
Can we replace the Text Encoding menu with a single menu item that performs the function currently performed by the item Automatic in the Text Encoding menu?
Does chardetng have to revise its guess often? (That is, is the guess made at one kilobyte typically the same as the guess made at the end of the stream? If not, there’s a reload.)
Does the top-level domain affect the guess often? (If yes, maybe it’s worthwhile to tune this area.)
Is unlabeled UTF-8 so common as to warrant further action to support it?
Is the unlabeled UTF-8 situation different enough for text/html and text/plain to warrant different treatment of text/plain?
The failure mode of decoding according to the wrong encoding is very different for the Latin script and for non-Latin scripts. Also, there are historical differences in UTF-8 adoption and encoding labeling in different language contexts. For example, UTF-8 adoption happened sooner for the Arabic script and for Vietnamese while Web developers in Poland and Japan had different attitudes towards encoding labeling early on. For this reason, it’s not enough to look at the global aggregation of data alone.
Since Firefox’s encoding behavior no longer depends on the UI locale and a substantial number of users use the en-US localization in non-U.S. contexts, I use geographic location rather than the UI locale as a proxy for the legacy encoding family of the Web content primary being read.
The geographical breakdown of telemetry is presented in the tables by ISO 3166-1 alpha-2 code. The code is deduced from the source IP addresses of the telemetry submissions at the time of ingestion after which the IP address itself is discarded. As another point relevant to make about privacy, the measurements below referring to the .jp, .in, and .lk TLDs is not an indication of URL collection. The split into four coarse categories, .jp, .in+.lk, other ccTLD, and non-ccTLD, was done on the client side as a side effect of these four TLD categories getting technically different detection treatment: .jp has a dedicated detector, .in and .lk don’t run detection at all, for other ccTLDs the TLD is one signal taken into account, and for other TLDs the detection is based on the content only. (It’s imaginable that there could be regional differences in how willing users are to participate in telemetry collection, but I don’t know if there actually are regional differences.)
Menu Usage
Starting with 86, Firefox has a probe that measures if the item “Automatic” in the Text Encoding menu has been used at least once in a given subsession. It also has another probe measuring whether any of the other (manual) items in the Text Encoding menu has been used at least once in a given subsession.
Both the manual selection and the automatic selection are used at the highest rate in Japan. The places with the next-highest usage rates are Hong Kong and Taiwan. The manual selection is still used in more sessions that the automatic selection. In Japan and Hong Kong, the factor is less than 2. In Taiwan, it’s less than 3. In places where the dominant script is the Cyrillic script, manual selection is relatively even more popular. This is understandable, considering that the automatic option is a new piece of UI that users probably haven’t gotten used to, yet.
All in all, the menu is used rarely relative to the total number of subsessions, but I assume the usage rate in Japan still makes the menu worth keeping considering how