Hello Mozillians!
As you may already know, last Friday – September 30th – we held a new Testday event, for Firefox 50 Beta 3.
Thank you all for helping us making Mozilla a better place – Julie Myers, Logicoma, Tayba Wasim, Nagaraj V, Suramya Shah, Iryna Thompson, Moin Shaikh, Dragota Rares, Dan Martin, P Avinash Sharma.
From Bangladesh: Hossain Al Ikram, Azmina Akter Papeya, Nazir Ahmed Sabbir, Saddam Hossain, Aminul Islam Alvi, Raihan Ali, Rezaul Huque Nayeem, Md. Rahimul Islam, Sayed Ibn Masud, Roman Syed, Maruf Rahman, Tovikur Rahman, Md. Rakibul Islam, Siful Islam Joy, Sufi Ahmed Hamim, Md Masudur-Rahman, Niaz Bhuiyan Asif, Akash Kishor Sarker, Mohammad Maruf Islam, MD Maksudur Rahman, M Eftekher Shuvo, Tariqul Islam Chowdhury, Abdullah Al Jaber Hridoy, Md Sajib Mullla, MD. Almas Hossain, Rezwana islam ria, Roy Ayers, Nzmul Hossain, Md. Nafis Fuad, Fahim.
From India: Vibhanshu Chaudhary, Subhrajyoti Sen, Bhuvana Meenakshi K, Paarttipaabhalaji, Nagaraj V, Surentharan.R.A, Rajesh . D, Pavithra.R.
A big thank you goes out to all our active moderators too!
Results:
- there were 7 verified bugs:
- there was 1 new issue found:
- some failures were mentioned in the etherpad; therefore, please add the requested details in the etherpad or, even better, join us on #qa IRC channel and let’s figure them out
https://quality.mozilla.org/2016/10/firefox-50-beta-3-testday-results/
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
News & Blog Posts

 Announcing Rust 1.12.
Announcing Rust 1.12. - Ethereum users are recommended to switch to Parity (an Ethereum client written in Rust) to mitigate ongoing DoS attack. Further reads - out of memory bug in Geth client and next steps against transaction spam attack.
- Optional arguments in Rust 1.12.
- Applying Hoare logic to the Rust MIR. Hoare logic is a formal system with a set of logical rules for reasoning rigorously about the correctness of computer programs (from Wikipedia article).
- Rust as a language for high performance GC implementation.
- How to use Rust code inside Haskell.
- Rusty dynamic loading. How to utilize dynamic libraries to reload code on the fly.
- Safe and efficient bidirectional trees.
- How to implement a new DOM API for Servo.
- Observational equivalence and unsafe code. Observational equivalence is the property of two or more underlying entities being indistinguishable on the basis of their observable implications (from Wikipedia article).
- Distinguishing reuse from override. Follow-up to last week's intersection impls article.
- Even quicker byte count. Follow-up to last week's how to count newlines really fast in Rust.
- Implementing Finite Automata in Rust (Part 1).
- Building personalized IPC debugging tools using Electron and Rust.
- Easier Rust Development on the PJRC Teensy 3. PJRC Teensy is a USB-based microcontroller development system.

If you have worked with data at Mozilla you have likely seen a data dashboard built with it. Re:dash is enabling Mozilla to become a truly data driven organization.
— Roberto Vitillo, Mozilla
In the third quarter, the Mozilla Open Source Support (MOSS) program has made awards to a number of “plumbing” projects – unobtrusive but essential initiatives which are part of the foundation for building software, building businesses and improving accessibility. This quarter, we awarded over $300k to four projects – three on Track 1 Foundational Technology for projects Mozilla already uses or deploys, and one on Track 2 Mission Partners for projects doing work aligned with our mission.
On the Foundational Technology track, we awarded $100,000 to Redash, a tool for building visualizations of data for better decision-making within organizations, and $50,000 to Review Board, software for doing web-based source code review. Both of these pieces of software are in heavy use at Mozilla. We also awarded $100,000 to Kea, the successor to the venerable ISC DHCP codebase, which deals with allocation of IP addresses on a network. Mozilla uses ISC DHCP, which makes funding its replacement a natural move even though we haven’t deployed it yet.

On the Mission Partners track, we awarded $56,000 to Speech Rule Engine, a code library which converts mathematical markup into vocalised form (speech) for the sight-impaired, allowing them to fully appreciate mathematical and scientific content on the web.
In addition to all that, we have completed another two MOSS Track 3 Secure Open Source audits, and have more in the pipeline. The first was for the dnsmasq project. Dnsmasq is another piece of Internet plumbing – an embedded server for the DNS and DHCP protocols, used in all mainstream Linux distros, Android, OpenStack, open router projects like openWRT and DD-WRT, and many commercial routers. We’re pleased to say only four issues were found, none of them severe. The second was for the venerable zlib project, a widely-used compression library, which also passed with flying colors.
Applications for Foundational Technology and Mission Partners remain open, with the next batch deadline being the end of November 2016. Please consider whether a project you know could benefit from a MOSS award, and encourage them to apply. You can also submit a suggestion for a project which might benefit from an SOS audit.
https://blog.mozilla.org/blog/2016/10/03/moss-supports-four-more-open-source-projects-with-300k/
 A presentation of the next round of refined designs for the Mozilla brand identity and a Q & A session about the Open Design process...
A presentation of the next round of refined designs for the Mozilla brand identity and a Q & A session about the Open Design process...
I put a lot of work into my content management system in the last week(s), first because I had the time to work on some ongoing backend rework/improvements (after some design improvements on this blog site and my main site) but then to tackle an issue that has been lingering for a while: the handling of logins for users.
When I first created the system (about 13 years ago), I did put simple user and password input fields into place and yes, I didn't know better (just like many people designing small sites probably did and maybe still do) and made a few mistakes there like storing passwords without enough security precautions or sending them in plaintext to people via email (I know, causes a WTF moment in even myself nowadays but back then I didn't know better).
And I was very happy when the seemingly right solution for this came along: Have really trustworthy people who know how to deal with it store the passwords and delegate the login process to them - ideally in a decentralized way. In other words, I cheered for Mozilla Persona (or the BrowserID protocol) and integrated my code with that system (about 5 years ago), switching most of my small sites in this content management system over to it fully.
Yay, no need to make my system store and handles passwords in a really safe and secure way as it didn't need to store passwords any more at all! Everything is awesome, let's tackle other issues. Or so I thought. But, if you haven't heard of that, Persona is being shut down on November 30, 2016. Bummer.
So what were the alternatives for my small websites?
Well, I could go back to handling passwords myself, with a lot of research into actually secure practices and a lot of coding to get things right, and probably quite a bit of bugfixing afterwards, and ongoing maintenance to keep up with ever-growing security challenges. Not really something I was wanting to go with, also because it may make my server's database more attractive to break into (though there aren't many different people with actual logins).
Another alternative is using delegated login via Facebook, Google, GitHub or others (the big question is who), using the OAuth2 protocol. Now there's two issues there: First, OAuth2 isn't really made for delegated login but for authentication of using some resource (via an API), so it doesn't return a login identifier (e.g. email address) but rather an access token for resources and needs another potentially failure-prone roundtrip to actually get such an identifier - so it's more complicated than e.g. Persona (because using it just for login is basically misusing it). Second, the OAuth2 providers I know of are entities to whom I don't want to tell every login on my content management system, both because their Terms of Service allow them to sell that information to anyone, and second because I don't trust them enough to know about each and every one of those logins.
Firefox Accounts would be an interesting option, given that Mozilla is trustworthy on the side of dealing with password data and wouldn't sell login data or things like that, may support the same BrowserID assertion/verification flow as Persona (which I have implemented already), but it doesn't (yet) support non-Mozilla sites to use it (and given that it's a CMS, I'd have multiple non-Mozilla sites I'd need to use it for). It also seems to support an OAuth2 flow, so may be an option with that as well if it would be open to use at this point - and I need something before Persona goes away, obviously.
Other options, like "passwordless" logins that usually require a roundtrip to your email account or mobile phone on every login sounded too inconvenient for me to use.
That said, I didn't find anything "better" as a Persona replacement than OAuth2, so I took an online course on it, then put a lot of time into implementing it and I have a prototype working with GitHub's implementation (while I don't feel to trust them with all those logins, I felt they are OK enough to use for testing against). That took quite some work as well, but some of the abstraction I did for Persona implementation can be almost or completely reused (in the latter case, I just abstracted things to a level that works for both) - and there's potential in for example getting some more info than an email from the
 The Monday Project Meeting
The Monday Project Meeting
 Summary of View Source 2016 in Berlin
Summary of View Source 2016 in Berlin
Interpr.it is a platform for translating browser extensions that I launched five years ago; it will be shutting down on September 1, 2017. I no longer have the time to maintain it, and since I stopped writing Firefox extensions, I don’t have any skin in the game either.
I’ve notified everyone that uploaded an extension so that they have ample time to download any translations (333 days). It was not a large Bcc list; although nearly six thousand users created an account during the last five years, only about two dozen of those users uploaded an extension. Eight hundred of those six thousand contributed a translation of at least one string.
For anyone interested in improving the browser extension translation process, I’d suggest writing a GlotPress plugin to add support for Firefox and Chrome-style locale files. It’s been on my todo list for so long that I’m sure I will never get to it.
http://www.chrisfinke.com/2016/10/03/interprit-shutting-down/
If you have more or better screenshots, please share!

This shot is taken from the ending sequence of the PC version of the game Grand Theft Auto V. 44 minutes in! See the youtube version.

Sky HD is a satellite TV box.

This is a Philips TV. The added use of c-ares I consider a bonus!

The infotainment display of a BMW car.

Playstation 4 lists open source products it uses.

This is a screenshot from an Iphone open source license view. The iOS 10 screen however, looks like this:

curl in iOS 10 with an older year span than in the much older screenshot?

Instagram on an Iphone.

Spotify on an Iphone.

Virtualbox (thanks to Anders Nilsson)

Battle.net (thanks Anders Nilsson)

Freebox (thanks Alexis La Goutte)

The Youtube app on Android. (Thanks Ray Satiro)

The Youtube app on iOS (Thanks Anthony Bryan)
https://daniel.haxx.se/blog/2016/10/03/screenshotted-curl-credits/
The other day I've stumbled on a reddit comment on Twitter about micro-services. It really nailed down the best practices around building web services, and I wanted to use it as a basis to write down a blog post. So all the credits go to rdsubhas for this post :)
Web Services in 2016
The notion of micro-service rose in the past 5 years, to describe the fact that our applications are getting splitted into smaller pieces that need to interact to provide the same service that what we use to do with monolothic apps.
Splitting an app in smaller micro services is not always the best design decision in particular when you own all the pieces. Adding more interactions to serve a request just makes things more complex and when something goes wrong you're just dealing with a more complex system.
Peope often think that it's easier to scale an app built with smaller blocks, but it's often not the case, and sometimes you just end up with a slower, over-engineered solution.
So why are we building micro-services ?
What really happened I think is that most people moved their apps to cloud providers and started to use the provider services, like centralized loggers, distributed databases and all the fancy services that you can use in Amazon, Rackspace or other places.
In the LAMP architecture, we're now building just one piece of the P and configuring up to 20 services that interact with it.
A good chunk of our daily jobs now is to figure out how to deploy apps, and even if some tools like Kubertenes gives us the promise of an abstraction on the top of cloud providers, the reality is that you have to learn how AWS or another provider works to built something that works well.
Understanding how multi-zone replication works in RDS is mandatory to make sure you control your application behavior.
Because no matter how fancy and reliable, all those services are, the quality of your application will be tighted to its ability to deal with problems like network splits or timeouts etc.
That's where the shift in bests practices is: when something goes wrong, it's harder just to tail your postgres logs and your Python app and see what's going on. You have to deal with many parts.
Best Practices
I can't find the original post on Reddit, so I am just going to copy it here and curate it with my own opinions and with the tools we use at Mozilla. I've also removed what I see as redundant tips.
Basic monitoring, instrumentation, health check
We use statsd everywhere and services like Datadog to see what's going on in our services.
We also have two standard heartbeat endpoints that are used to monitor the services. One is a simple round trip where the service just sends back a 200, and one is more of a smoke test, where the service tries to use all of its own backends to make sure it can reach them and read/write into them.
We're doing this distinction because the simple round trip health check is being hit very often, and the one that calls all the services the service use, less often to avoid doing too much traffic and load.
Distributed logging, tracing
Most of our apps are in Python, and we use Sentry to collect tracebacks and sometimes New Relic to detect problems we could not reproduce in a dev environment.
Isolation of the whole build+test+package+promote for every service.
We use Travis-CI to trigger most of our builds, tests and packages. Having reproducible steps made in an isolated environment like a CI gives us good confidence on the fact that the service is not spaghetti-ed with other services.
The bottom line is that "gill pull & make test" should work in Travis no matter what, without calling an external service. The travis YML file, the Makefile and all the mocks in the tests are rhoughly our 3 gates to the outside world. That's as far as we go in term of build standards.
Maintain backward compatibility as much as possible
The initial tip included forward compatibility. I've removed it, because I don't think it's really a thing when you build web services. Forward compatibility means that an older version of your service can accept requests from newer version of the client side. But I think it should just be a deployment issue and an error management on the client side, so you don't bend your data design just so it works with older service versions.
For backward compatibility though, I think it's mandatory to make sure that you know how to interact with older clients, whatever happens.
As a way to amplify the Participation’s team focused support to communities, we have created a project called Regional Coaches.
Reps Regional coaches project aims to bring support to all Mozilla local communities around the world thanks to a group of excellent core contributors who will be talking with these communities and coordinating with the Reps program and the Participation team.
We divided the world into 10 regions, and selected 2 regional coaches to take care of the countries in these regions.
- Region 1: USA, Canada
- Region 2: Mexico, El Salvador, Costa Rica, Panama, Nicaragua, Venezuela, Colombia, Ecuador, Peru, Bolivia, Brazil, Paraguay, Chile, Argentina, Cuba
- Region 3: Ireland, UK, France, Belgium, Netherlands, Germany, Poland, Sweden, Lithuania, Portugal, Spain, Italy, Switzerland, Austria, Slovenia, Czech Republic.
- Region 4: Hungary, Albania, Kosovo, Serbia, Bulgaria, Macedonia, Greece, Romania, Croatia, Bosnia, Montenegro, Ukraine, Russia, Israel
- Region 5: Algeria, Tunisia, Egypt, Jordan, Turkey, Palestine, Azerbaijan, Armenia, Iran, Morocco
- Region 6: Cameroon, Nigeria, Burkina Faso, Senegal, Ivory Coast, Ghana
- Region 7: Uganda, Kenya, Rwanda, Madagascar, Mauritius, Zimbabwe, Botswana
- Region 8: China, Taiwan, Bangladesh, Japan
- Region 9: India, Nepal, Pakistan, Sri Lanka, Myanmar
- Region 10: Thailand, Cambodia, Malaysia, Singapore, Philippines, Indonesia, Vietnam, Australia, New Zealand.
These regional coaches are not a power structure nor a decision maker, they are there to listen to the communities and establish a 2-way communication to:
- Develop a clear view of local communities status, problems, needs.
- Help local communities surface any issues or concerns.
- Provide guidance/coaching on Mozilla’s goals to local communities.
- Run regular check-ins with communities and volunteers in the region.
- Coordinate with the rest of regional coaches on a common protocol, best practices.
- Be a bridge between communities in the same region.
We want communities to be better integrated with the rest of the org, not just to be aligned with the current organizational needs but also to allow them to be more involved in shaping the strategy and vision for Mozilla and work together with staff as a team, as One Mozilla.
We would like to ask all Reps and mozillians to support our Regional Coaches, helping them to meet communities and work with them. This project is key for bringing support to everyone, amplifying the strategy, vision and work that we have been doing from the Reps program and the Participation team.
Current status
 [600x336]We have on-boarded 18 regional coaches to bring support to 87 countries (wow!) around the world. Currently they have started to contact local communities and hold video meetings with all of them.
[600x336]We have on-boarded 18 regional coaches to bring support to 87 countries (wow!) around the world. Currently they have started to contact local communities and hold video meetings with all of them.
What have we learned so far?
Mozilla communities are very diverse, and their structure and activity status is very different. Also, there is a need for alignment with the current projects and focus activities around Mozilla and work to encourage mozillians to get involved in shaping the future.
In region 1, there are no big formal communities and mozillians are working as individuals or city-level groups. The challenge here is to get everyone together.
In region 2 there are a lot of communities, some of them currently re-inventing themselves to align better with focus initiatives. There is a huge potential here.
Region 3 is where the oldest communities started, and there is big difference between the old and the emerging ones. The challenge is to get the old ones to the same level of diverse activity and alignment as the new ones.
In region 4 the challenge is to re-activate or start communities in small countries.
Region 5 has been active for a long time, focused mainly in localization. How to align with new emerging focus
In my previous post, I explained how the Participation staff team was going to work with a clear focus, and today I want to explain how we are going to amplify this support to all local communities thanks to a project inside the Reps program called Regional Coaches.
Reps Regional coaches project aims to bring support to all Mozilla local communities around the world thanks to a group of excellent core contributors who will be talking with these communities and coordinating with the Reps program and the Participation team.
We divided the world into 10 regions, and selected 2 regional coaches to take care of the countries in these regions.
- Region 1: USA, Canada
- Region 2: Mexico, El Salvador, Costa Rica, Panama, Nicaragua, Venezuela, Colombia, Ecuador, Peru, Bolivia, Brazil, Paraguay, Chile, Argentina, Cuba
- Region 3: Ireland, UK, France, Belgium, Netherlands, Germany, Poland, Sweden, Lithuania, Portugal, Spain, Italy, Switzerland, Austria, Slovenia, Czech Republic.
- Region 4: Hungary, Albania, Kosovo, Serbia, Bulgaria, Macedonia, Greece, Romania, Croatia, Bosnia, Montenegro, Ukraine, Russia, Israel
- Region 5: Algeria, Tunisia, Egypt, Jordan, Turkey, Palestine, Azerbaijan, Armenia, Iran, Morocco
- Region 6: Cameroon, Nigeria, Burkina Faso, Senegal, Ivory Coast, Ghana
- Region 7: Uganda, Kenya, Rwanda, Madagascar, Mauritius, Zimbabwe, Botswana
- Region 8: China, Taiwan, Bangladesh, Japan
- Region 9: India, Nepal, Pakistan, Sri Lanka, Myanmar
- Region 10: Thailand, Cambodia, Malaysia, Singapore, Philippines, Indonesia, Vietnam, Australia, New Zealand.
These regional coaches are not a power structure nor a decision maker, they are there to listen to the communities and establish a 2-way communication to:
- Develop a clear view of local communities status, problems, needs.
- Help local communities surface any issues or concerns.
- Provide guidance/coaching on Mozilla’s goals to local communities.
- Run regular check-ins with communities and volunteers in the region.
- Coordinate with the rest of regional coaches on a common protocol, best practices.
- Be a bridge between communities in the same region.
We want communities to be better integrated with the rest of the org, not just to be aligned with the current organizational needs but also to allow them to be more involved in shaping the strategy and vision for Mozilla and work together with staff as a team, as One Mozilla.
I would like to ask all mozillians to support our Regional Coaches, helping them to meet communities and work with them. This project is key for bringing support to everyone, amplifying the strategy, vision and work that we have been doing from the Reps program and the Participation team.
Current status

We have on-boarded 18 regional coaches to bring support to 87 countries (wow!) around the world. Currently they have started to contact local communities and hold video meetings with all of them.
What have we learned so far?
Mozilla communities are very diverse, and their structure and activity status is very different. Also, there is a need for alignment with the current projects and focus activities around Mozilla and work to encourage mozillians to get involved in shaping the future.
In region 1, there are no big formal communities and mozillians are working as individuals or city-level groups. The challenge here is to get everyone together.
In region 2 there are a lot of communities, some of them currently re-inventing themselves to align better with focus initiatives. There is a huge potential here.
Region 3 is where the oldest communities started, and there is big difference between the old and the emerging ones. The challenge is to get the old ones to the same level of diverse activity and alignment as the new ones.
In region 4 the challenge is to re-activate or start communities in small countries.
Region
As is fortnightly tradition, the Firefox Desktop team rallied together last Tuesday to share notes and ramblings on things that are going on. Here are some hand-picked, artisinal updates from your friendly neighbourhood Firefox team:
Highlights
- With Firefox 49 (and 49.0.1) out the door, e10s has now been enabled for users that have WebExtensions enabled and the add-ons on this list only.
- e10s has been temporarily disabled for users with a ru-* locale due to bug 1294719
- The e10s team is investigating reports of users on the release channel seeing many occurrences of the tab switch spinner. Investigation is being tracked in this bug. The e10s roll-out system add-on is being modified to disable e10s for users that see the spinner too often
- mconley added a new API for system add-ons to prompt the user for permissions.
- Did you know that you can still use your own Sync server? And now tcsc has made it even easier to configure Firefox to use it!
- WillWang has a plan to not show the Save As / Preview dialog if a clicked link is not previewable
- seanlee put together a cheat sheet for folks who want to contribute to Firefox who are more comfortable with Git than Mercurial
Contributor(s) of the Week
- Filipe removed Cortana support from Firefox, since Microsoft has hard-coded Cortana to only open links in Edge
- adamg2 helped clean up part of the Telemetry API
- kxnikx helped to make some of our arrow panel CSS variables more clear
- Amal Santosh helped to fix an error in the CSS for about:networking
Project Updates
Add-ons
Context Graph
- The Context Graph team is working on prototyping a new mobile experience
- Keep an eye on this wiki page if you’re curious about what the Context Graph team is up to
Firefox Core Engineering
Form Auto-fill
- The system add-on stub for the Form Auto-fill project has landed
- The team no longer plans on using a bootstrap.js/WebExt hybrid because the only thing we were hoping to use WebExtensions for isn’t yet supported
- The Form Auto-fill Team had a kick-off workweek was last week in Taipei. Here’s a summary on their shiny new mailing list, which you should totally subscribe to!
Privacy / Security
- florian has a work-in-progres patch that will show a preview in the screen sharing permission prompt
Quality of Experience
- Gijs is running an experiment on to see how auto-migration works in the wild on both the beta channel and on a subset of our release population
Earlier this year we submitted the paper Lightweight User-Space Record And Replay to an academic conference. Reviews were all over the map, but ultimately the paper was rejected, mainly on the contention that most of the key techniques have (individually) been presented in other papers. Anyway, it's probably the best introduction to how rr works and how it performs that we currently have, so I want to make it available now in the hope that it's interesting to people.
http://robert.ocallahan.org/2016/10/rr-paper-lightweight-user-space-record.html
I spent a really interesting day last week at Northeastern University.
First, I saw a fun talk by Philip Haller covering LaCasa, which is a
set of extensions to Scala that enable it to track ownership. Many of
the techniques reminded me very much of Rust (e.g., the use of
spores
, which are closures that can limit the types of things they
close over); if I have time, I’ll try to write up a more detailed
comparison in some later post.
Next, I met with Amal Ahmed and her group to discuss the process of crafting unsafe code guidelines for Rust. This is one very impressive group. It’s this last meeting that I wanted to write about now. The conversation helped me quite a bit to more cleanly separate two distinct concepts in my mind.
The TL;DR of this post is that I think we can limit the capabilities
of unsafe code to be things you could have written using the safe
code plus a core set of unsafe abstractions
(ignoring the fact that
the safe implementation would be unusably slow or consume ridiculous
amounts of memory). This is a helpful and important thing to be able
to nail down.
Background: observational equivalence
One of the things that we talked about was observational
equivalence and how it relates to the unsafe code guidelines. The
notion of observational equivalence is really pretty simple: basically
it means two bits of code do the same thing, as far as you can tell
.
I think it’s easiest to think of it in terms of an API. So, for
example, consider the HashMap and BTreeMap types in the Rust
standard library. Imagine I have some code using a HashMap
that only invokes the basic map operations – e.g., new, get, and
insert. I would expect to be able to change that code to use a
BTreeMap and have it keep working. This is because HashMap
and BTreeMap, at least with respect to i32 keys and
new/get/insert, are observationally equivalent.
If I expand the set of API routines that I use, however, this
equivalence goes away. For example, if I iterate over the map, then a
BTreeMap gives me an ordering guarantee, whereas HashMap doesn’t.
Note that the speed and memory use will definitely change as I shift
from one to the other, but I still consider them observationally
equivalent. This is because I consider such changes unobservable
, at
least in this setting (crypto code might beg to differ).
Composing unsafe abstractions
One thing that I’ve been kind of wrestling with in the unsafe code
guidelines is how to break it up. A lot of the attention has gone into
thinking about some very low-level decisions: for example, if I make a
*mut pointer and an &mut reference, when can they legally alias?
But there are some bigger picture questions that are also equally
interesting: what kinds of things can unsafe code even do in the
first place, whatever types it uses?
One example that I often give has to do with the infamous
setjmp/longjmp in C. These are some routines that let you
implement a poor man’s exception handling. You call setjmp at one
stack frame and then, down the stack, you call longjmp. This will
cause all the intermediate stack frames to be popped (with no
unwinding or other cleanup) and control to resume from the point where
you called setjmp. You can use this to model exceptions (a la
Objective C),
build coroutines, and of
course – this is C – to shoot yourself in the foot (for example,
by invoking longjmp when the stack frame that called setjmp has
already returned).
So you can imagine someone writing a Rust wrapper for
setjmp/longjmp. You could easily guarantee that people use the API
in a correct way: e.g., that you when you call longjmp, the setjmp
frame is still on the stack, but does that make it safe?
One concern is that setjmp/longjmp do not do any form of
unwinding. This means that all of the intermediate stack frames are
going to be popped and none of the destructors for their local
variables will run. This certainly means that memory will leak, but it
can have
Weekly post already? But it seems like the last one was just the other day! It’s true, it has been less than a week since the last one, but I feel like the weekend is a good time for me to write these so you’re getting another update. This post is going to be very tech heavy. So I’m going to put the less tech heavy stuff in the next couple paragraph or so, then I’m going to explain my implementation for educational purposes.
I’m currently reading Game Engine Architecture by Jason Gregory and one of the early chapters focused on development tools and how important they are. My previous full time job was building development tools for web developers so I’ve already developed an appreciation for having them. Also, you may remember my last post where I talked about debugging tools I’ve added to my game.
Games require a lot of thought and consideration to the performance of the code that is written and one of the primary metrics that the game industry uses is FPS, or Frames Per Second. This is the number of times the full screen is rendered to the screen per second. A common standard for this is 60FPS which is what most “high definition” monitors and TVs can produce. Because the frames need to be roughly evenly spaced it means that each frame gets about 16.6 milliseconds to be fully calculated and rendered.
So, I built a tool to let me analyze the amount of time each frame took to render. I knew I’d want to graph the data, and I didn’t have the ability to make graphs using my game engine. I don’t even have the ability to display text. So I went with a setup called Electron to let me use the sort of code and techniques I use for web development and am very familiar with. And this screenshot is the results:
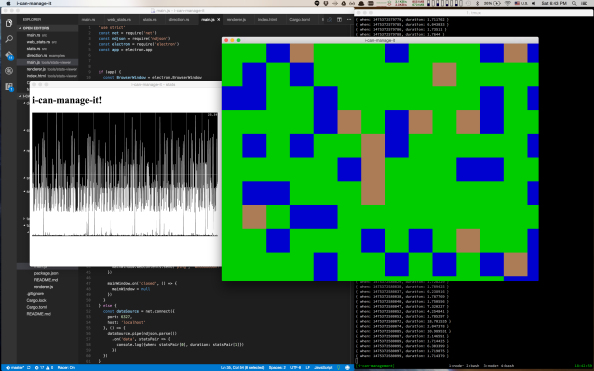
In the background is my text editor with some code, and a bunch of debug information in my terminal. On the right with the pretty colors is my game. It is over there rendering about 400-450 FPS on my mac. On the left in the black and white is my stats viewer. Right now it just shows the duration of every frame. The graph dynamically sizes itself, but at the moment it was showing 2ms-25ms range. Interesting things to note is that I’m averaging 400FPS but I have spikes that take over 16.6ms, so the frames are not evenly spaced and it looks like ~58FPS.
Ok, that’s the tool I built and a brief explanation. Next, I’m going to go into the socket server I wrote to have the apps communicate. This is the very tech heavy part so friends just reading along because they want to see what I’m up to, but aren’t programmers, this is the time to hit the eject button if you find that stuff boring and you kinda wish I’d just shut up sometimes.
To start with, this gist has the full code that I’ll be talking about here. I’m going to try to use snippets cut up with text from that, so you can refer to that gist for context if needed. This is a very simple socket server I wrote to export a few numbers out of my engine. I expect to expand this and make it more featureful as well as bidirectional so I can opt in or out of debugging stuff or tweak settings.
Lets first look at the imports, I say as if that’s interesting, but one thing to note is I’m not using anything outside of std for my stats collection and socket server. Keep in mind this is a proof of concept, not something that will need to work for hundreds of thousands of users per second or anything.
use std::io::Write;
use std::net::TcpListener;
use std::sync::mpsc::{channel, Receiver, Sender};
use std::thread;
I’ve pulled in the Write trait from std::io so I can write to the sockets that connect. Next up is TcpListener which is the way in the standard library to listen for new socket connections. Then we have channels for communicating across threads easily. Speaking of threads, I pull in that module as well.
Ok, so now that we know the pieces we’re working with, lets talk design. I wanted to have my stats display work by a single initializing call, then sending data over a channel to a stats collection thread. Because channels in rust are MPSC channels, or Multiple Producer Single Consumer channels, they can have many areas sending data, but only 1 thing consuming data. This is what lead to the interesting design of the initializing function seen below:
pub fn run_stats_server () -> Sender{ let (stats_tx, stats_rx) = channel(); thread::Builder::new() .name("Stats:Collector".into()) .spawn(move || { let new_socket_rx =
Back when I started on addons.mozilla.org (AMO) there was a suggestion lurking in the background... "what if I wanted to run my own copy of addons.mozilla.org"?
I'm never been quite sure if that would be something someone would actually want to do, but people kept mentioning it. I think for a while for some associated Mozilla projects might have tried it, but in the six years of the project I've seen zero bugs about anyone actually doing it. Just some talk of "well if you wanted to do it...".
I think we can finally lay to rest that while AMO is an open source project (and long may it stay it that way) and running your own version is technically possible, it's not something Mozilla should worry about or support.
This decision is bolstered by a couple of things that happened in the add-ons community recently: add-on signing, which means that Mozilla can be the only one to sign add-ons for Firefox and the use of Firefox Accounts for authentication.
These are things you can work around or re-purpose, but in the end you'll probably find that these things are not worth the effort when it comes down to it.
From a contribution point of view AMO is very easy to set up and install these days. Pull down the docker containers, run them and you are going. You'll have a setup that is really similar to production in a few minutes. As an aside: development and production actually use slightly different docker containers, but that will be merged in the future.
From a development point of view, knowing that AMO is only ever deployed in one way makes life so very much easier. We don't have to support multiple OS's, environments or combinations that will never happen in production.
Recently we've started to move to API driven site and that means that all the data in AMO is now exposed through an API. So if you want to do something with AMO data, the best thing to do is start playing with the API to grab some data and remix that add-on data as much as you'd like (example).
So AMO is still open source and remain so, it just won't support every single option in its development and I think that's a good thing.
I just pushed out the release of rr 4.4.0. It's mostly the usual reliability and syscall coverage improvements. There are a few highlights:
- Releases are now built with CMAKE_BUILD_TYPE=Release. This significantly improves performance on some workloads.
- We support recording and replaying Chromium-based applications, e.g. chromium-browser and google-chrome. One significant issue was that Chromium (via SQLite) requires writes performed by syscalls to be synced automatically with memory-maps of the same file, even though this is technically not required by POSIX. Another significant issue is that Chromium spawns a Linux task with an invalid TLS area, so we had to ensure rr's injected preload library does not depend on working glibc TLS.
- We support Linux 4.8 kernels. This was a significant amount of work because in 4.8, PTRACE_SYSCALL notifications moved to being delivered before seccomp notifications instead of afterward. (It's a good change, though, because as well as fixing a security hole, it also improves rr recording performance; the number of ptrace notifications for each ptrace-recorded syscall decreases from 3 to 2.) This also uncovered a serious (to rr) kernel bug with missing PTRACE_EVENT_EXIT notifications, which fortunately we were able to get fixed upstream (thanks to Kees Cook).
- Keno Fischer contributed some nice performance improvements to the "slow path" where we are forced to context-switch between tracees and rr.
- Tom Tromey contributed support for accessing thread-local variables while debugging during replay. This is notable because the "API" glibc exports for this is ghastly.

Yesterday Let's Encrypt reached a new milestone: the unique set of all fully-qualified domain names in the currently-unexpired certificates issued by Let's Encrypt is now 10,022,446.
This data is coming from the same source as my previous posts: my CT box which is maintaining a state of Censys.io and Certificate Transparency using github.com/jcjones/ct-sql and a much-abused MariaDB server.
Let's Encrypt Growth Timeline

You can take a look at the graph in live-form, as well as some of the datasets coming from it at ct.tacticalsecret.com.
This is the future of the Let's Encrypt Statistics page on letsencrypt.org. The current graphs on LE's site are my doing, and they were 20 minutes of work late one night just to get something out there (We've all done that, right?). Of course, they've stayed online as "the" stats for far longer than I had ever intended. Doubly-problematic, those graphs' queries look like they show data all the way back to first issuance, but they actually don't - there's some LIMIT statements which are there because the queries were fast and ugly.
The update to the Let's Encrypt website to use these new datasets is live as PR #61 on the LE Website repo, awaiting @LetsEncrypt_Ops time to set up the cron job. In the meanwhile, enjoy ct.tacticalsecret.com as the demo and the bleeding-edge site.
https://tacticalsecret.com/lets-encrypts-growth-to-10m-fqdns/
 Digital Economy Board of Advisors (DEBA) 2016
Digital Economy Board of Advisors (DEBA) 2016