In a Debian server I'm using LVM to create a single logical volume from multiple different volumes. One of the volumes is a loop-back device which refers to a file in another filesystem.
The loop-back device needs to be activated before the LVM service starts or the
later will fail due to missing volumes. To do so a special systemd unit needs to
be created which will not have the default dependencies of units and will get
executed before lvm2-activation-early service.
Systemd will set a number of dependencies for all units by default to bring the system into a usable state before starting most of the units. This behavior is controlled by DefaultDependencies flag. Leaving DefaultDependencies to its default True value creates a dependency loop which systemd will forcefully break to finish booting the system. Obviously this non-deterministic flow can result in different than desired execution order which in turn will fail the LVM volume activation.
Setting DefaultDependencies to False will disable all but essential dependencies and will allow our unit to execute in time. Systemd manual confirms that we can set the option to false:
Generally, only services involved with early boot or late shutdown should set this option to false.
The second is to execute before lvm2-activation-early. This is simply achieved
by setting Before=lvm2-activation-early.
The third and last step is to set the command to execute. In my case it's
/sbin/losetup /dev/loop0 /volume.img as I want to create /dev/loop0 from the
file /volume.img. Set the process type to oneshot so systemd waits for the
process to exit before it starts follow-up units. Again from the systemd manual
Behavior of oneshot is similar to simple; however, it is expected that the process has to exit before systemd starts follow-up units.
Place the unit file in /etc/systemd/system and in the next reboot the
loop-back device should be available to LVM.
Here's the final unit file:
[Unit] Description=Activate loop device DefaultDependencies=no After=systemd-udev-settle.service Before=lvm2-activation-early.service Wants=systemd-udev-settle.service [Service] ExecStart=/sbin/losetup /dev/loop0 /volume.img Type=oneshot [Install] WantedBy=local-fs.target
See also: - Anthony's excellent LVM Loopback How-To
https://giorgos.sealabs.net/systemd-unit-to-activate-loopback-devices-before-lvm.html
Web developers don’t write all their code in just one line of text. They use white space between their HTML elements because it makes markup more readable: spaces, returns, tabs.
In most instances, this white space seems to have no effect and no visual output, but the truth is that when a browser parses HTML it will automatically generate anonymous text nodes for elements not contained in a node. This includes white space (which is, after all a type of text).
If these auto generated text nodes are inline level, browsers will give them a non-zero width and height, and you will find strange gaps between the elements in the context, even if you haven’t set any margin or padding on nearby elements.
This behaviour can be hard to debug, but Firefox DevTools are now able to display these whitespace nodes, so you can quickly spot where do the gaps come from in your markup, and fix the issues.
Demo
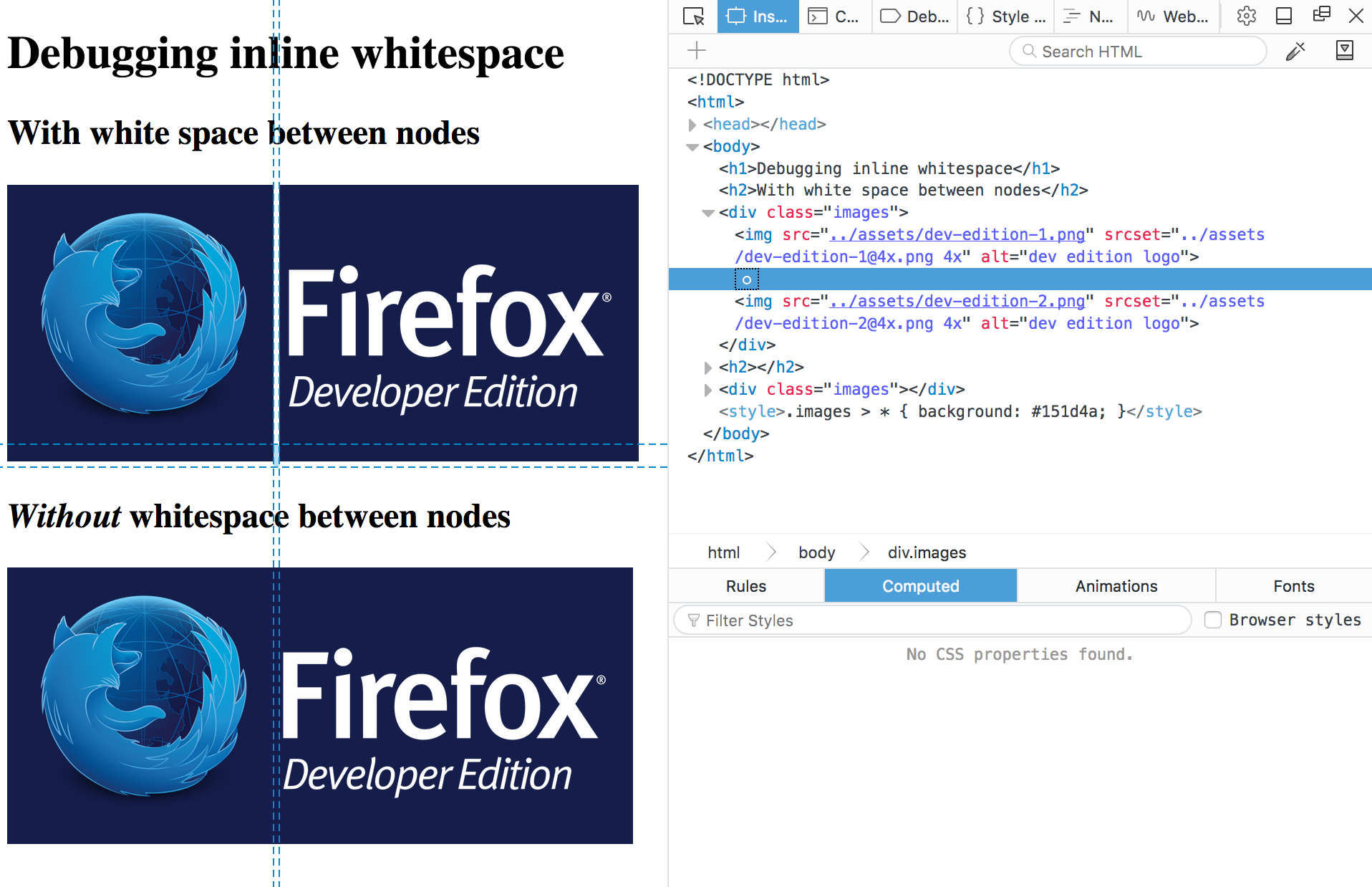
The demo shows two examples with slightly different markup to highlight the differences both in browser rendering and what DevTools are showing.
The first example has one img per line, so the markup is readable, but the browser renders gaps between the images:

The second example has all the img tags in one line, which makes the markup unreadable, but it also doesn’t have gaps in the output:
If you inspect the nodes in the first example, you’ll find a new whitespace indicator that denotes the text nodes created for the browser for the whitespace in the code. No more guessing! You can even delete the node from the inspector, and see if that removes mysterious gaps you might have in your website.
Apparently World Standards Day is on October 14. Except in the USA it's celebrated on October 27 and in Canada on October 5.
Are they trying to be ironic?
http://robert.ocallahan.org/2016/10/ironic-world-standards-day.html
It's Talos time. You can now plunk down your money for an open, auditable, non-x86 workstation-class computer that doesn't suck. It's PowerPC. It's modern. It's beefy. It's awesome.
Let's not mince words, however: it's also not cheap, and you're gonna plunk down a lot if you want this machine. The board runs $4100 and that's without the CPU, which is pledged for separately though you can group them in the same order (this is a little clunky and I don't know why Raptor did it this way). To be sure, I think we all suspected this would be the case but now it's clear the initial prices were underestimates. Although some car repairs and other things have diminished my budget (I was originally going to get two of these), I still ponied up for a board and for one of the 190W octocore POWER8 CPUs, since this appears to be the sweetspot for those of us planning to use it as a workstation (remember each core has eight threads via SMT for a grand total of 64, and this part has the fastest turbo clock speed at 3.857GHz). That ran me $5340. I think after the RAM, disks, video card, chassis and PSU I'll probably be all in for around $7000.
Too steep? I don't blame you, but you can still help by donating to the project and enable those of us who can afford to jump in first to smoothe the way out for you. Frankly, this is the first machine I consider a meaningful successor to the Quad G5 (the AmigaOne series isn't quite there yet). Non-x86 doesn't have the economies of scale of your typical soulless Chipzilla craptop or beige box, but if we can collectively help Raptor get this project off the ground you'll finally have an option for your next big machine when you need something free, open and unchained -- and there's a lot of chains in modern PCs that you don't control. You can donate as little as $10 and get this party started, or donate $250 and get to play with one remotely for a few months. Call it a rental if you like. No, I don't get a piece of this, I don't have stock in Raptor and I don't owe them a favour. I simply want this project to succeed. And if you're reading this blog, odds are you want that too.
The campaign ends December 15. Donate, buy, whatever. Let's do this.
My plans are, even though I confess I'll be running it little-endian (since unfortunately I don't think we have much choice nowadays), to make it as much a true successor to the last Power Mac as possible. Yes, I'll be sinking time into a JIT for it, which should fully support asm.js to truly run those monster applications we're seeing more and more of, porting over our AltiVec code with an endian shift (since the POWER8 has VMX), and working on a viable and fast way of running legacy Power Mac software on it, either through KVM or QEMU or whatever turns out to be the best option. If this baby gets off the ground, you have my promise that doing so will be my first priority, because this is what I wanted the project for in the first place. We have a chance to resurrect the Power Mac, folks, and in a form that truly kicks ass. Don't waste the opportunity.
Now, having said all that, I do think Raptor has made a couple tactical errors. Neither are fatal, but neither are small.
First, there needs to be an intermediate pledge level between the bare board and the $18,000 (!!!!) Warren Buffett edition. I have no doubt the $18,000 machine will be the Cadillac of this line, but like Cadillacs, there isn't $18,000 worth of parts in it (maybe, maybe, $10K), and this project already has a bad case of sticker shock without slapping people around with that particular dead fish. Raptor needs to slot something in the middle that isn't quite as wtf-inducing and I'll bet they'll be appealing to those people willing to spend a little more to get a fully configured box. (I might have been one of those people, but I won't have the chance now.)
Second, the pledge threshold of $3.7 million is not ludicrous when you consider what has to happen to manufacture these things, but it sure seems that way. Given that this can only be considered a boutique system at this stage, it's going to take a lot of punters like yours truly to cross that point, which is why your donations even if you're not willing to buy right now are
Here’s the state of the add-ons world this month.
The Review Queues
In the past month, 1,755 listed add-on submissions were reviewed:
- 1,438 (82%) were reviewed in fewer than 5 days.
- 119 (7%) were reviewed between 5 and 10 days.
- 198 (11%) were reviewed after more than 10 days.
There are 223 listed add-ons awaiting review.
If you’re an add-on developer and are looking for contribution opportunities, please consider joining us. Add-on reviewers are critical for our success, and can earn cool gear for their work. Visit our wiki page for more information.
Compatibility
The compatibility blog post for Firefox 50 is up, and the bulk validation was run recently. The compatibility blog post for Firefox 51 has published yesterday. It’s worth pointing out that the Firefox 50 cycle will be twice as long, so 51 won’t be released until January 24th, 2017.
Multiprocess Firefox is now enabled for users without add-ons, and add-ons will be gradually phased in, so make sure you’ve tested your add-on and either use WebExtensions or set the multiprocess compatible flag in your add-on manifest.
As always, we recommend that you test your add-ons on Beta and Firefox Developer Edition to make sure that they continue to work correctly. End users can install the Add-on Compatibility Reporter to identify and report any add-ons that aren’t working anymore.
Recognition
We would like to thank Atique Ahmed Ziad, Surya Prashanth, freaktechnik, shubheksha, bjdixon, zombie, berraknil, Krizzu, rackstar17, paenglab, and Trishul Goel (long list!) for their recent contributions to the add-ons world. You can read more about their work in our recognition page.
https://blog.mozilla.org/addons/2016/10/14/add-ons-update-88/
Thursday, September 22nd 2016. An email popped up in my inbox.
Subject: ares_create_query OOB write
As one of the maintainers of the c-ares project I’m receiving mails for suspected security problems in c-ares and this was such a one. In this case, the email with said subject came from an individual who had reported a ChromeOS exploit to Google.
It turned out that this particular c-ares flaw was one important step in a sequence of necessary procedures that when followed could let the user execute code on ChromeOS from JavaScript – as the root user. I suspect that is pretty much the worst possible exploit of ChromeOS that can be done. I presume the reporter will get a fair amount of bug bounty reward for this.
The setup and explanation on how this was accomplished is very complicated and I am deeply impressed by how this was figured out, tracked down and eventually exploited in a repeatable fashion. But bear with me. Here comes a very simplified explanation on how a single byte buffer overwrite with a fixed value could end up aiding running exploit code as root.
The main Google bug for this problem is still not open since they still have pending mitigations to perform, but since the c-ares issue has been fixed I’ve been told that it is fine to talk about this publicly.
c-ares writes a 1 outside its buffer
c-ares has a function called ares_create_query. It was added in 1.10 (released in May 2013) as an updated version of the older function ares_mkquery. This detail is mostly interesting because Google uses an older version than 1.10 of c-ares so in their case the flaw is in the old function. This is the two functions that contain the problem we’re discussing today. It used to be in the ares_mkquery function but was moved over to ares_create_query a few years ago (and the new function got an additional argument). The code was mostly unchanged in the move so the bug was just carried over. This bug was actually already present in the original ares project that I forked and created c-ares from, back in October 2003. It just took this long for someone to figure it out and report it!
I won’t bore you with exactly what these functions do, but we can stick to the simple fact that they take a name string as input, allocate a memory area for the outgoing packet with DNS protocol data and return that newly allocated memory area and its length.
Due to a logic mistake in the function, you could trick the function to allocate a too short buffer by passing in a string with an escaped trailing dot. An input string like “one.two.three\.” would then cause the allocated memory area to be one byte too small and the last byte would be written outside of the allocated memory area. A buffer overflow if you want. The single byte written outside of the memory area is most commonly a 1 due to how the DNS protocol data is laid out in that packet.
This flaw was given the name CVE-2016-5180 and was fixed and announced to the world in the end of September 2016 when c-ares 1.12.0 shipped. The actual commit that fixed it is here.
What to do with a 1?
Ok, so a function can be made to write a single byte to the value of 1 outside of its allocated buffer. How do you turn that into your advantage?
The Redhat security team deemed this problem to be of “Moderate security impact” so they clearly do not think you can do a lot of harm with it. But behold, with the right amount of imagination and luck you certainly can!
Back to ChromeOS we go.
First, we need to know that ChromeOS runs an internal HTTP proxy which is very liberal in what it accepts – this is the software that uses c-ares. This proxy is a key component that the attacker needed to tickle really badly. So by figuring out how you can send the correctly crafted request to the proxy, it would send the right string to c-ares and write a 1 outside its heap buffer.
ChromeOS uses dlmalloc for managing the heap memory. Each time the program allocates memory, it will get a pointer back to the request memory region, and dlmalloc will put a small header of its own just before that memory region for
TL;DR: JavaScript is too great an opportunity to build accessible, easy-to-use and flexible solutions for the web to not use it. It fills the gaps years of backwards-compatibility focus created. It helps with the problems of the now and the future that HTML and CSS alone can’t cover reliably. We shouldn’t blindly rely on it – we should own the responsibility to work around its flaky nature and reliability issues.

Right now, there is a lot of noise in our world about JavaScript, Progressive Enhancement and reliance on technology and processes. I’m in the middle of that. I have quite a few interviews with stakeholders in the pipeline and I’m working on some talks on the subject.
A lot of the chatter that’s happening right now seems to be circular:
- Somebody makes a blanket statement about the state of the web and technologies to rely on
- This ruffles the feathers of a few others. They point out the danger of these technologies and that it violates best practices
- The original writer accuses the people reacting of having limited and anachronistic views
- Stakeholders of frameworks that promise to make the life of developers a breeze chime in and point out that their way is the only true solution
- 62 blog posts and 5212 tweets later we find consensus and all is good again
Except, it isn’t. The web is in a terrible state and the average web site is slow, punishes our computers with slow running code and has no grace in trying to keep users interacting with it. Ads spy on us, scripts inject malware and it is taxing to find content in a mess of modals and overly complex interfaces.
It is high time we, the community that survived the first browser wars and made standards-driven development our goal, start facing facts. We failed to update our message of a usable and maintainable web to be relevant to the current market and a new generation of developers.
We once fixed the web and paved the way forward
Our “best development practices” stem from a time when we had bad browsers on desktop computers. We had OK connectivity – it wasn’t fast, but it was at least reliable. We also created documents and enhanced them to become applications or get some interactivity later.
The holy trinity was and is:
- Semantic HTML for structure
- CSS for styling
- JavaScript for some extra behaviour
That’s the message we like to tell. It is also largely a product of fiction. We defined these as best practices and followed them as much as we could, but a huge part of the web back then was done with WYSIWYG editors, CMS-driven or built with server-side frameworks. As such, the HTML was a mess, styles were an afterthought and JavaScript riddled with browser-sniffing or lots of document.write nasties. We pretended this wasn’t a problem and people who really care would never stoop down to creating terrible things like that.
There is no “the good old standards based web”. It was always a professional, craftsmanship view and ideal we tried to create. Fact is, we always hacked around issues with short-term solutions.
We had a clear goal and enemy – one we lost now
Browsers back then were not standards-aware and the browser wars raged. Having a different functionality than other browsers was a market advantage. This was bad for developers as we had to repeat all of our work for different browsers. The big skill was to know which browser messed up in which way. This was our clear target: to replace terrible web sites that only worked in IE6. The ones that were not maintainable unless you also had access to the CMS code or whatever language the framework was written in. We wanted to undo this mess by explaining what web standards are good for.
HTML describes a small use case
HTML describes linked documents with a few interactive elements. As quality oriented developers we started with an HTML document and we got a kick out of structuring it sensibly, adding just the right amount of CSS, adding some JavaScript to make it more interactive and release the thing. This was cool and is still very much possible. However, with the web being a main-stream medium these days, it isn’t quite how people work. We got used to things working in browsers differently, many of these patterns requiring JavaScript.
We got used to a higher level of interactivity as browser makers spend a lot of time ensuring compatibilty with another. We also
The Test Pilot 2016 Q4 OKRs are published. Primarily we'll be focused on continued growth of users (our overall 2016 goal). We deprioritized localization last quarter and over-rotated on publishing experiments by launching four when we were only aiming for one. This quarter we'll turn that knob back down (we're aiming for two new experiments) and get localization done.
We also failed to graduate any experiments last quarter -- arguably the most important part of our entire process since it includes drawing conclusions and publishing our results. This quarter we'll graduate three experiments from Test Pilot, publish our findings so we can improve Firefox, and clear out space in Test Pilot for the next big ideas.
http://micropipes.com/blog//2016/10/14/test-pilot-2016-q4-okrs/
Rust is a great language, and Mozilla plans to use it extensively in Firefox. However, the Rust compiler (rustc) is quite slow and compile times are a pain point for many Rust users. Recently I’ve been working on improving that. This post covers how I’ve done this, and should be of interest to anybody else who wants to help speed up the Rust compiler. Although I’ve done all this work on Linux it should be mostly applicable to other platforms as well.
Getting the code
The first step is to get the rustc code. First, I fork the main Rust repository on GitHub. Then I make two local clones: a base clone that I won’t modify, which serves as a stable comparison point (rust0), and a second clone where I make my modifications (rust1). I use commands something like this:
user=nnethercote for r in rust0 rust1 ; do cd ~/moz git clone https://github.com/$user/rust $r cd $r git remote add upstream https://github.com/rust-lang/rust git remote set-url origin git@github.com:$user/rust done
Building the Rust compiler
Within the two repositories, I first configure:
./configure --enable-optimize --enable-debuginfo
I configure with optimizations enabled because that matches release versions of rustc. And I configure with debug info enabled so that I get good information from profilers.
Then I build:
RUSTFLAGS='-Ccodegen-units=8' make -j8
The -Ccodegen-units=8/-j8 combination speeds up the build process significantly; I’m taking it on faith that it doesn’t affecting the accuracy of subsequent profiling information.
That does a full build, which does the following:
- Downloads a stage0 compiler, which will be used to build the stage1 local compiler.
- Builds LLVM, which will become part of the local compilers.
- Builds the stage1 compiler with the stage0 compiler.
- Builds the stage2 compiler with the stage1 compiler.
It can be mind-bending to grok all the stages, especially with regards to how libraries work. (One notable example: the stage1 compiler uses the system allocator, but the stage2 compiler uses jemalloc.) I’ve found that the stage1 and stage2 compilers have similar performance. Therefore, I mostly measure the stage1 compiler because it’s much faster to just build the stage1 compiler, which I do with the following command.
RUSTFLAGS='-Ccodegen-units=8' make -j8 rustc-stage1
Building the compiler takes a while, which isn’t surprising. What is more surprising is that rebuilding the compiler after a small change also takes a while. That’s because a lot of code gets recompiled after any change. There are two reasons for this.
- Rust’s unit of compilation is the crate. Each crate can consist of multiple files. If you modify a crate, the whole crate must be rebuilt. This isn’t surprising.
- rustc’s dependency checking is very coarse. If you modify a crate, every other crate that depends on it will also be rebuilt, no matter how trivial the modification. This surprised me greatly. For example, any modification to the parser (which is in a crate called libsyntax) causes multiple other crates to be recompiled, a process which takes 6 minutes on my fast desktop machine. Almost any change to the compiler will result in a rebuild that takes at least 2 or 3 minutes.
Incremental compilation should greatly improve the dependency situation, but it’s still in an experimental state and I haven’t tried it yet.
To run all the tests I do this (after a full build):
ulimit -c 0 && make check
The checking aborts if you don’t do the ulimit, because the tests produces lots of core files and it doesn’t want to swamp your disk.
The build system is complex, with lots of options. This command gives a nice overview of some common invocations:
make tips
Basic profiling
The next step is to do some basic profiling. I like to be careful about which rustc I am invoking at any time, especially if there’s a system-wide version installed, so I avoid relying on PATH and instead define some environment variables like this:
export RUSTC01="$HOME/moz/rust0/x86_64-unknown-linux-gnu/stage1/bin/rustc" export RUSTC02="$HOME/moz/rust0/x86_64-unknown-linux-gnu/stage2/bin/rustc" export RUSTC11="$HOME/moz/rust1/x86_64-unknown-linux-gnu/stage1/bin/rustc" export RUSTC12="$HOME/moz/rust1/x86_64-unknown-linux-gnu/stage2/bin/rustc"
In the examples that follow I will use
Firefox 51 will be released on January 24th. Note that the scheduled release on December 13th is a point release, not a major release, hence the much longer cycle. Here’s the list of changes that went into this version that can affect add-on compatibility. There is more information available in Firefox 51 for Developers, so you should also give it a look.
General
- Let accel-click and middle-click on the new tab button open a new tab next to the current one. This changes the behavior of the new tab button and removes the
BrowserOpenNewTabOrWindowfunction. - Code executed in wrong order with
setTimeoutafter alert. This changes the behavior of theonButtonClickfunction to make it async. - Drop the prefixed version of visibility API. This removes
mozVisibilityStateandmozHidden. - Don’t dispatch close event, and remove onclose. This applies to Workers.
- Prevent installation of an extension when “*” is used as part of
strict_min_versionin a WebExtensionmanifest.json). Minimum versions should always be specific versions, rather than a mask. - Loaded-as-data XML documents should not generate
XPCOM and Modules
Default to the NullPrincipal rather than SystemPrincipal for Favicons. This changes the functionssetAndFetchFaviconForPageandreplaceFaviconDataFromDataURL. The principal should generally be passed as an argument.- Upload setting wrong Content-Type for files if you downloaded from a server that provided the wrong Content-Type. As explained in comment #36, the way add-ons change the MIME type mappings is now different, via a category rather than directly changing
mimeTypes.rdf. - Remove the last references to
Actor/FrontClass. While both of these still work for add-ons, they should be considered as deprecated.
New!
- Embedded WebExtensions. You can now embed a WebExtension into any restartless add-on, allowing you to gradually migrate your code to the new platform, or transition any data you store to a format that works with WebExtensions.
- WebExtension Experiments. This is a mechanism that allows us (and you!) to prototype new WebExtensions APIs.
Let me know in the comments if there’s anything missing or incorrect on these lists. If your add-on breaks on Firefox 51, I’d like to know.
The automatic compatibility validation and upgrade for add-ons on AMO will happen in a few weeks, so keep an eye on your email if you have an add-on listed on our site with its compatibility set to Firefox 50.
https://blog.mozilla.org/addons/2016/10/13/compatibility-for-firefox-51/
Announcing Mozilla’s Equal Rating Innovation Challenge, a $250,000 contest including expert mentorship to spark new ways to connect everyone to the Internet.
At Mozilla, we believe the Internet is most powerful when anyone – regardless of gender, income, or geography – can participate equally. However the digital divide remains a clear and persistent reality. Today more than 4 billion people are still not online, according to the World Economic Forum. That is greater than 55% of the global population. Some, who live in poor or rural areas, lack the infrastructure. Fast wired and wireless connectivity only reaches 30% of rural areas. Other people don’t connect because they don’t believe there is enough relevant digital content in their language. Women are also less likely to access and use the Internet; only 37% access the Internet versus 59% of men, according to surveys by the World Wide Web Foundation.
Access alone, however, is not sufficient. Pre-selected content and walled gardens powered by specific providers subvert the participatory and democratic nature of the Internet that makes it such a powerful platform. Mitchell Baker coined the term equal rating in a 2015 blog post. Mozilla successfully took part in shaping pro-net neutrality legislation in the US, Europe and India. Today, Mozilla’s Open Innovation Team wants to inject practical, action-oriented, new thinking into these efforts.
This is why we are very excited to launch our global Equal Rating Innovation Challenge. This challenge is designed to spur innovations for bringing the members of the Next Billion online. The Equal Rating Innovation Challenge is focused on identifying creative new solutions to connect the unconnected. These solutions may range from consumer products and novel mobile services to new business models and infrastructure proposals. Mozilla will award US$250,000 in funding and provide expert mentorship to bring these solutions to the market.
![]() We seek to engage entrepreneurs, designers, researchers, and innovators all over the world to propose creative, engaging and scalable ideas that cultivate digital literacy and provide affordable access to the full diversity of the open Internet. In particular, we welcome proposals that build on local knowledge and expertise. Our aim is to entertain applications from all over the globe.
We seek to engage entrepreneurs, designers, researchers, and innovators all over the world to propose creative, engaging and scalable ideas that cultivate digital literacy and provide affordable access to the full diversity of the open Internet. In particular, we welcome proposals that build on local knowledge and expertise. Our aim is to entertain applications from all over the globe.
The US$250,000 in prize monies will be split in three categories:
- Best Overall (key metric: scalability)
- Best Overall Runner-up
- Most Novel Solution (key metric: experimental with potential high reward)
This level of funding may be everything a team needs to go to market with a consumer product, or it may provide enough support to unlock further funding for an infrastructure project.
The official submission period will run from 1 November to 6 January. All submissions will be judged by a group of external experts by mid January. The selected semifinalists will receive mentorship for their projects before they demo their ideas in early March. The winners will be announced at the end of March 2017.
We have also launched www.equalrating.com, a website offering educational content and background information to support the challenge. On the site, you will find the 3 key frameworks that may be useful for building understanding of the different aspects of this topic. You can read important statistics that humanize this issue, and see how connectivity influences gender dynamics,
Announcing Mozilla’s Equal Rating Innovation Challenge, a $250,000 contest including expert mentorship to spark new ways to connect everyone to the Internet.
At Mozilla, we believe the Internet is most powerful when anyone — regardless of gender, income, or geography — can participate equally. However the digital divide remains a clear and persistent reality. Today more than 4 billion people are still not online, according to the World Economic Forum. That is greater than 55% of the global population. Some, who live in poor or rural areas, lack the infrastructure. Fast wired and wireless connectivity only reaches 30% of rural areas. Other people don’t connect because they don’t believe there is enough relevant digital content in their language. Women are also less likely to access and use the Internet; only 37% access the Internet versus 59% of men, according to surveys by the World Wide Web Foundation.
Access alone, however, is not sufficient. Pre-selected content and walled gardens powered by specific providers subvert the participatory and democratic nature of the Internet that makes it such a powerful platform. Mitchell Baker coined the term equal rating in a 2015 blog post. Mozilla successfully took part in shaping pro-net neutrality legislation in the US, Europe and India. Today, Mozilla’s Open Innovation Team wants to inject practical, action-oriented, new thinking into these efforts.
This is why we are very excited to launch our global Equal Rating Innovation Challenge. This challenge is designed to spur innovations for bringing the members of the Next Billion online. The Equal Rating Innovation Challenge is focused on identifying creative new solutions to connect the unconnected. These solutions may range from consumer products and novel mobile services to new business models and infrastructure proposals. Mozilla will award US$250,000 in funding and provide expert mentorship to bring these solutions to the market.

We seek to engage entrepreneurs, designers, researchers, and innovators all over the world to propose creative, engaging and scalable ideas that cultivate digital literacy and provide affordable access to the full diversity of the open Internet. In particular, we welcome proposals that build on local knowledge and expertise. Our aim is to entertain applications from all over the globe.
The US$250,000 in prize monies will be split in three categories:
- Best Overall (key metric: scalability)
- Best Overall Runner-up
- Most Novel Solution (key metric: experimental with potential high reward)
This level of funding may be everything a team needs to go to market with a consumer product, or it may provide enough support to unlock further funding for an infrastructure project.
The official submission period will run from 1 November to 6 January. All submissions will be judged by a group of external experts by mid January. The selected semifinalists will receive mentorship for their projects before they demo their ideas in early March. The winners will be announced at the end of March 2017.

We have also launched www.equalrating.com, a website offering educational content and background information to support the challenge. On the site, you will find the 3 key frameworks that may be useful for building understanding of the different aspects of this topic. You can read important statistics that humanize this issue, and see how connectivity influences gender dynamics, education, economics, and a myriad of other social issues. The reports section provides further depth to the different positions of the
Tl;dr: I just shipped scriptworker 0.8.0 (changelog) (RTD) (github) (pypi).
This is a non-backwards-compatible release.
background
By design, taskcluster workers are very flexible and user-input-driven. This allows us to put CI task logic in-tree, which means developers can modify that logic as part of a try push or a code commit. This allows for a smoother, self-serve CI workflow that can ride the trains like any other change.
However, a secure release workflow requires certain tasks to be less permissive and more auditable. If the logic behind code signing or pushing updates to our users is purely in-tree, and the related checks and balances are also in-tree, the possibility of a malicious or accidental change being pushed live increases.
Enter scriptworker. Scriptworker is a limited-purpose taskcluster worker type: each instance can only perform one type of task, and validates its restricted inputs before launching any task logic. The scriptworker instances are maintained by Release Engineering, rather than the Taskcluster team. This separates roles between teams, which limits damage should any one user's credentials become compromised.
scriptworker 0.8.0
The past several releases have included changes involving the chain of trust. Scriptworker 0.8.0 is the first release that enables gpg key management and chain of trust signing.
An upcoming scriptworker release will enable upstream chain of trust validation. Once enabled, scriptworker will fail fast on any task or graph that doesn't pass the validation tests.
 Weekly project updates from the Mozilla Connected Devices team.
Weekly project updates from the Mozilla Connected Devices team.
https://air.mozilla.org/connected-devices-weekly-program-update-20161013/
 This is a weekly call with some of the Reps to discuss all matters about/affecting Reps and invite Reps to share their work with everyone.
This is a weekly call with some of the Reps to discuss all matters about/affecting Reps and invite Reps to share their work with everyone.
The presence and participation of women in STEM is on the rise thanks to the efforts of many across the globe, but still has many...
https://air.mozilla.org/mozilla-learning-science-community-call-2016-10-13/
So, Aria Stewart tweeted two questions and statement the other day:
Programmers: can you describe change over time in a system? How completely?
Practice this.
— Aria Stewart (@aredridel) October 10, 2016
I wanted to discuss this idea as it pertains to debugging and strategies I’ve been employing more often lately. But lets examine the topic at face value first, describing change over time in a system. The abstract “system” is where a lot of the depth in this question comes from. It could be talking about the computer you’re on, the code base you work in, data moving through your application, an organization of people, many things fall into a system of some sort, and time acts upon them all. I’m going to choose the data moving through a system as the primary topic, but also talk about code bases over time.
Another part of the question that keeps it quite open is the lack of “why”, “what”, or “how” in it. This means we could discuss why the data needs to be transformed in various ways, why we added a feature or change some code, why an organization is investing in writing software at all. We could talk about what change at each step in a data pipeline, what changes have happened in a given commit, or what goals were accomplished each month by some folks. Or, the topic could be how a compiler changes the data as it passes through, how a programmer sets about making changes to a code base, or how an organization made its decisions to go in the directions it did. All quite valid and this is but a fraction of the depth in this simple question.
Let’s talk about systems a bit. At work, we have a number of services talking via a messaging system and a relational database. The current buzz phrase for this is “micro services” but we also called them “service oriented architectures” in the past. My previous job, I worked in a much smaller system that had many components for gathering data, as well as a few components for processing that data and sending it back to the servers. Both of these systems shared common attributes which most other systems also must cope with: events that provide data to be processed happen in functionally random order, that data is fed into processors who then stage data to be consumed by other parts of the system.
When problems arise in systems like these, it can be difficult to tell what piece is causing disruption. The point where the data changes from healthy to problematic may be a few steps removed from the layer that the problem is detected in. Also, sometimes the data is good enough to only cause subtle problems. At the start of the investigation, all you might know is something bad happened in the past. It is especially at these points when we need the description of the change that should happen to our data over time, hopefully with as much detail as possible.
The more snarky among us will point out the source code is what is running so why would you need some other description? The problem often isn’t that a given developer can’t understand code as they read it, though that may be the case. Rather, I find the problem is that code is meant to handle so many different cases and scenarios that the exact slice that I care about is often hard to track. Luckily our brains are build up these mental models that we can use to traverse our code, eliminating blocks of code because we intuitively “know” the problem couldn’t be in them, because we have an idea of how our code should work. Unfortunately, it is often at the mental model part where problems arise. The same tricks we use to read faster and then miss errors in our own writing are what can cause problems when understanding why a system is working in some way we didn’t expect.
Mental models are often incomplete due to using libraries, having multiple developers on a project, and the ravages of time clawing away at our memory. In some cases the mental model is just wrong. You may have intended to make a change but forgot to actually do it, maybe you read some documentation in a different way than intended, possibly you made a mistake while writing the code such as a copy/paste error or off by 1 in a loop. It doesn’t really matter the source of the flaw though, because when we’re hunting a bug. The goal is to find what the flaw in both the code and the mental model are so it can be corrected, then we can try to identify why the model got out of wack in the first place.
Can we describe change in a system over time? Probably to some reasonable degree of accuracy, but likely not completely. How does all of this tie into debugging? The strategy I’ve been practicing when I hit these situations is particularly geared around the idea that my mental model and the
In Q3 the MozReview team started to focus on tackling various usability issues. We started off with a targetted effort on the “Finish Review” dialog, which was not only visually unappealing but difficult to use. The talented David Walsh compressed the nearly full-screen dialog into a dropdown expanded from the draft banner, and he changed button names to clarify their purpose. We have some ideas for further improvements as well.
David has now embarked on a larger mission: reworking the main review-request UI to improve clarity and discoverability. He came up with some initial designs and discussed them with a few MozReview users, and here’s the result of that conversation:
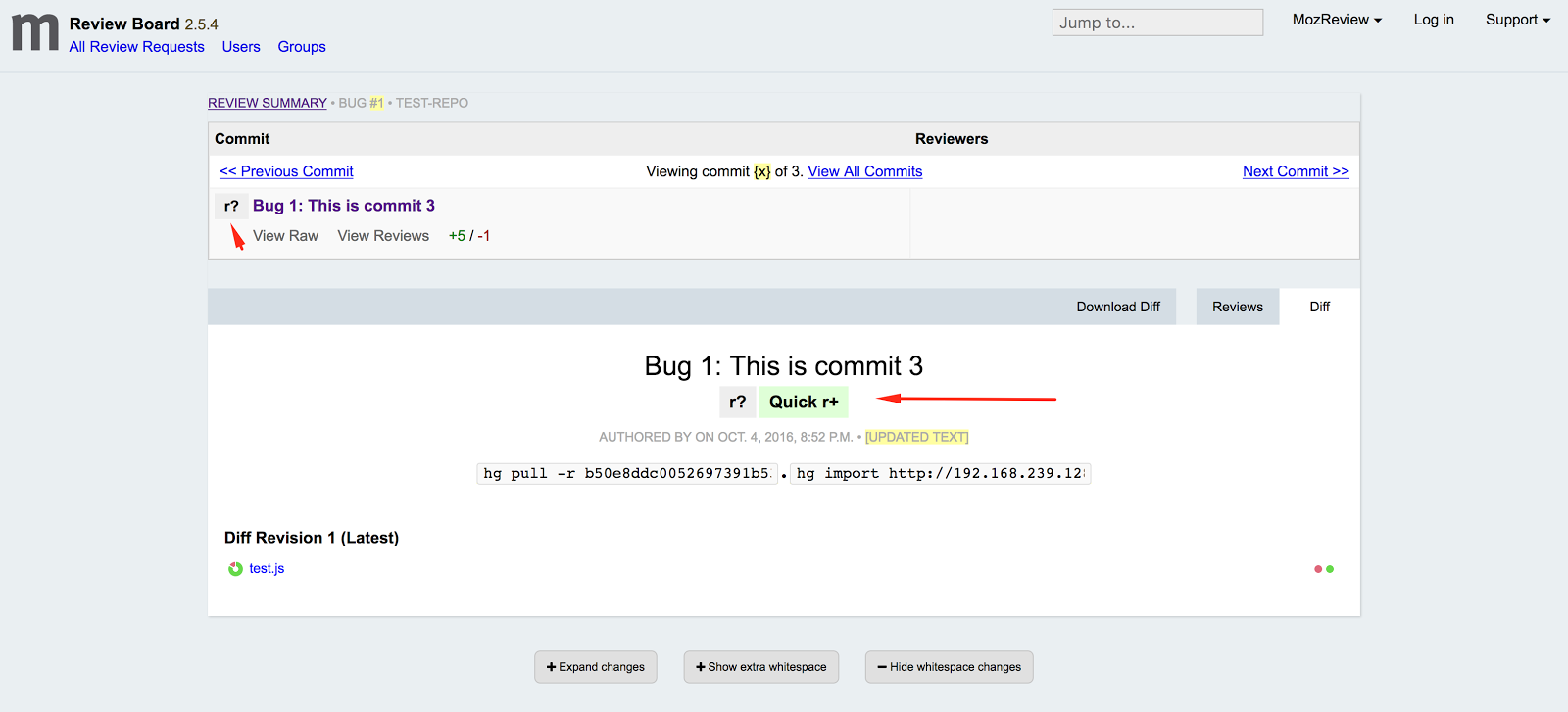
This design provides some immediate benefits, and it sets us up for some future improvements. Here are the thoughts behind the changes:
The commits table, which was one of the first things we added to stock Review Board, was never in the right place. All the surrounding text and controls reflect just the commit you are looking at right now. Moving the table to a separate panel above the commit metadata is a better, and hopefully more intuitive, representation of the hierarchical relationship between commit series and individual commit.
The second obvious change is that the commit table is now collapsed to show only the commit you are currently looking at, along with its position (e.g. “commit 3 of 5”) and navigation links to previous and next commits. This places the emphasis on the selected commit, while still conveying the fact that it is part of a series of commits. (Even if that series is actually only one commit, it is still important to show that MozReview is designed to operate on series.) To address feedback from people who like always seeing the entire series, it will be possible to expand the table and set that as a preference.
The commit title is still redundant, but removing it from the second panel left the rest of the information there looking rather abandoned and confusing. I’m not sure if there is a good fix for this.
The last functional change is the addition of a “Quick r+” button. This fixes the annoying process of having to select “Finish Review”, set the dropdown to “r+”, and then publish. It also removes the need for the somewhat redundant and confusing “Finish Review” button, since for anything other than an r+ a reviewer will most likely want to leave one or more comments explaining their action. The “Quick r+” button will probably be added after the other changes are deployed, in part because we’re not completely satisfied with its look and position.
The other changes are cosmetic, but they make various data and controls look much slicker while also being more compact.
We are also noodling around with a further enhancement:
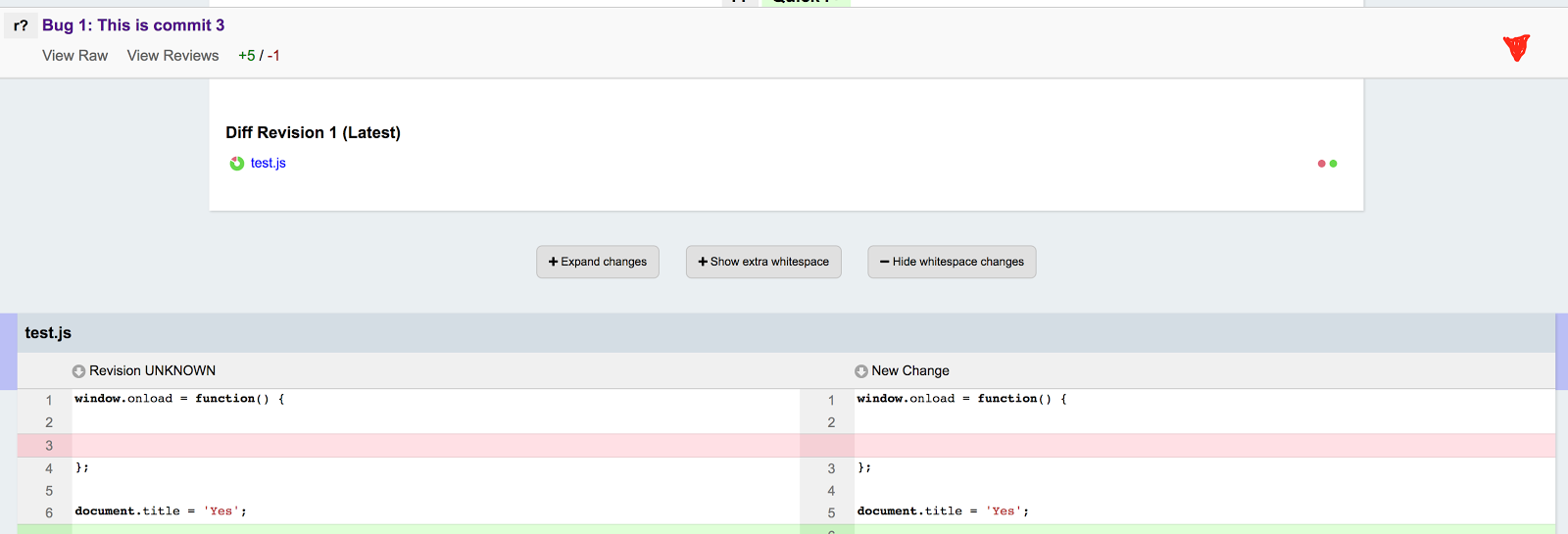
This is a banner containing data about the current commit, which will appear when the user scrolls past the commits table. It provides a constant reminder of the current commit, and we may put in a way to skip up to the commits table and/or navigate between commits. We may also fold the draft/“Finish Review” banner into this as well, although we’re still working out what that would look like. In any case, this should help avoid unnecessary scrolling while also presenting a “you are here” signpost.
As I mentioned, these changes are part of an on-going effort to improve general usability. This refactoring gets us into position to tackle more issues:
Since the commits table will be clearly separated from the commit metadata, we can move the controls that affect the whole series (e.g. autoland) up to the first panel, and leave controls that affect only the current commit (right now, only “Finish Review”/“Quick r+”) with the second panel. Again this should make things more intuitive.
Similarly, this gives us a better mechanism for moving the remaining controls that exist only on the parent review request (“Review Summary”/“Complete Diff”) onto the individual commit review requests, alongside the other series controls. This in turns means that we’ll be able to do away with the parent review request, or at least make some radical changes to it.
MozReview usage is slowly ticking upwards, as more and more Mozillians are seeing the value of splitting their work up into a series of small, atomic commits; appreciating the smooth flow of pushing commits up for review; and especially digging the autoland functionality. We’re now hard at work to make the whole experience delightful.
Cross post from: The Mozilla Blog.
Mozilla’s annual celebration of making online is challenging outdated copyright law in the EU. Here’s how you can participate.
It’s that time of year: Maker Party.
Each year, Mozilla hosts a global celebration to inspire learning and making online. Individuals from around the world are invited. It’s an opportunity for artists to connect with educators; for activists to trade ideas with coders; and for entrepreneurs to chat with makers.
This year, we’re coming together with that same spirit, and also with a mission: To challenge outdated copyright laws in the European Union. EU copyright laws are at odds with learning and making online. Their restrictive nature undermines creativity, imagination, and free expression across the continent. Mozilla’s Denelle Dixon-Thayer wrote about the details in her recent blog post.
By educating and inspiring more people to take action, we can update EU copyright law for the 21st century.
Over the past few months, everyday internet users have signed our petition and watched our videos to push for copyright reform. Now, we’re sharing copyright reform activities for your very own Maker Party.
Want to join in? Maker Party officially kicks-off today.
Here are activities for your own Maker Party:
Be a #cczero Hero
In addition to all the amazing live events you can host or attend, we wanted to create a way for our global digital community to participate.
We’re planning a global contribute-a-thon to unite Mozillians around the world and grow the number of images in the public domain. We want to showcase what the open internet movement is capable of. And we’re making a statement when we do it: Public domain content helps the open internet thrive.
Check out our #cczero hero event page and instructions on contributing. You should be the owner of the copyright in the work. It can be fun, serious, artistic — whatever you’d like. Get started.
For more information on how to submit your work to the public domain or to Creative Commons, click here.

Post Crimes
Mozilla has created an app to highlight the outdated nature of some of the EU’s copyright laws, like the absurdity that photos of public landmarks can be unlawful. Try the Post Crimes web app: Take a selfie in front of the Eiffel Tower’s night-time light display, or the Little Mermaid in Denmark.
Then, send your selfie as a postcard to your Member of the European Parliament (MEP). Show European policymakers how outdated copyright laws are, and encourage them to forge reform. Get started.
Meme School
It’s absurd, but it’s true: Making memes may be technically illegal in some parts of the EU. Why? Exceptions for parody or quotation are not uniformly required by the present Copyright Directive.
Help Mozilla stand up for creativity, wit, and whimsy through memes! In this Maker Party activity, you and your friends will learn and discuss how complicated copyright law can be. Get started.

We can’t wait to see what you create this Maker Party. When you participate, you’re standing up for copyright reform. You’re also standing up for innovation, creativity, and opportunity online.
https://blog.mozilla.org/community/2016/10/12/maker-party-2016-stand-up-for-a-better-internet/
![[Monthly Speaker Series] Metadata is the new data… and why that matters, with Harlo Holmes.](https://air.cdn.mozilla.net/media/cache/5b/cb/5bcb94566ef574e7cd9c8fa2ad9d5313.jpg) Today's proliferation of mobile devices and platforms such as Google and Facebook has exacerbated an extensive, prolific sharing about users and their behaviors in ways...
Today's proliferation of mobile devices and platforms such as Google and Facebook has exacerbated an extensive, prolific sharing about users and their behaviors in ways...
https://air.mozilla.org/monthly-speaker-series-metadata-with-harlo-holmes-2016-10-12/