 Weekly project updates from the Mozilla Connected Devices team.
Weekly project updates from the Mozilla Connected Devices team.
https://air.mozilla.org/connected-devices-weekly-program-update-20161110/
At SmashingConf Freiburg I took some time to interview Sarah Drasner on SVG.
In this interview we covered what SVG can bring, how to use it sensibly and what pitfalls to avoid.
You can see the video and get the audio recording of our chat over at the Decoded blog:

Sarah is a dear friend and a lovely person and knows a lot about animation and SVG.
Here are the questions we covered:
- SVG used to be a major “this is the future of the web” and then it vanished for a while. What is the reason of the new interest in a format that old?
- Tooling in SVG seems to be still lagging behind in what Flash gave us. Are there any good tools that have – for example – a full animation timeline?
- SVG syntax on first glance seems rather complex due to its XML format and lots of shortcut notations. Or is it just a matter of getting used to it?
- Coordinate systems seem to be easy to understand, however when it comes to dynamic coordinate systems and vector basics people get lost much easier. When you teach, is this an issue?
- What about prejudices towards SVG? It is rumoured to be slow and very memory intense. Is this true?
- Presets of tools seem to result in really large SVG files which is why we need extra tools to optimise them. Is this improving with the new-found interest in SVG?
- There seems to be a “war of animation tools”. You can use SVG, CSS Animations, The Web Animation API, or JavaScript libraries. What can developer do about this? Should we learn all of them?
- There are security issues with linking to external SVG files which makes them harder to use than – for example – images. This can be discouraging and scary for implementers, what can we do there?
- Does SVG live in the uncanny valley between development and design?
- Is there one thing you’d love people to stop saying about SVG as it is not true but keeps coming up in conversations?
Desde hace algunos a~nos, todos los que usamos servidores proxy para acceder a Internet mediante Firefox, de una forma u otra alguna vez hemos tenido problemas con la autenticaci'on. Molestas ventanas emergentes pidiendo el usuario y contrase~na saltaban cuando menos te lo imaginabas, y, aunque la p'agina about:config nos permite llevar el nivel de configuraci'on del navegador al m'aximo, estos “trucos” no funcionaban para nada.
Despu'es de esperar un avance palpable en torno a este problema, hace pocos d'ias en Bugzilla actualizaron el estado de los bugs relacionados a RESOLVED FIXED y una agradable sorpresa me he llevado al probar varias veces y comprobar que funciona perfectamente.
Desde aqu'i llegue nuestro m'as sincero agradecimiento a Honza Bambas, Gary Lockyer, Patrick McManus y a todas las personas involucradas que de una forma u otra ayudaron a solucionar este bug.
Este parche se puede encontrar en el canal Nighlty (actualmente 52), invito a todos los interesados a descargar y probar esta versi'on para encontrar posibles errores antes de ser liberada en el canal Release (planificado para marzo de 2017).
Si te ha gustado esta noticia, d'ejanos saber tu opini'on en un comentario ;-).
https://firefoxmania.uci.cu/firefox-no-pedira-nunca-mas-repetidamente-contrasenas/
 This is a weekly call with some of the Reps to discuss all matters about/affecting Reps and invite Reps to share their work with everyone.
This is a weekly call with some of the Reps to discuss all matters about/affecting Reps and invite Reps to share their work with everyone.
Hossain al Ikram is a passionate contributor from Bangladesh community. He is frontrunner for QA community from past two years and has been setting examples of remarkable leadership and value contribution under several functional areas. Ikram has shown great potential and he is proving his mettle at every instance.

He is actively mentoring people from different countries for QA initiative, He recently helped Indian community in setting up QA team. He also organized MozActivate campaign in Bangladesh. Check some examples QA events from Rajshahi, Sylhet, Chittagong , mentoring in Varenda or mentoring in Rajshahi. Also he started a ToT for WebCompat with more editions in November. You can read about his awesome work on his website.
Geraldo has been one of the most active members in Brazilian community over the last 3 months. Helping to coordinate Mozilla presence at FISL (one of the biggest OpenSource events in Brazil), engaging with the community, running events like Sao Paulo workday , or Latinoware, and even assisting to MozFest!

He is a very engaged mozillian, that also helps run events for Webcompat and SUMO hackatons. This November, you will see Geraldo doing more of his stuff in the upcoming events, promoting Mozilla mission, being an awesome Mozilla Club member, and spreading some #mozlove. Be sure to check his Medium account for more news about his work!
Please join us in congratulating them as Reps of the Month for October 2016!
https://blog.mozilla.org/mozillareps/2016/11/10/rep-of-the-month-october-2016/
Firefox crashes sometimes. This bothers users, so a large amount of time, money, and developer effort is devoted to keep it from happening.
That’s why I like that image of Firefox Aurora’s crash rate from my post about Firefox’s release model. It clearly demonstrates the result of those efforts to reduce crash events:
So how do we measure crashes?
That picture I like so much comes from this dashboard I’m developing, and uses a very specific measure of both what a crash is, and what we normalize it by so we can use it as a measure of Firefox’s quality.
Specifically, we count the number of times Firefox or the web page content disappears from the user’s view without warning. Unfortunately, this simple count of crash events doesn’t give us a full picture of Firefox’s quality, unless you think Firefox is miraculously 30% less crashy on weekends:
So we need to normalize it based on some measure of how much Firefox is being used. We choose to normalize it by thousands of “usage hours” where a usage hour is one hour Firefox was open and running for a user without crashing.
Unfortunately, this choice of crashes per thousand usage hours as our metric, and how we collect data to support it, has its problems. Most significant amongst these problems is the delay between when a new build is released and when this measure can tell you if it is a good build or not.
Crashes tend to come in quickly. Generally speaking, when a user’s Firefox disappears out from under them, they are quick to restart it. This means this new Firefox instance is able to send us information about that crash usually within minutes of it happening. So for now, we can ignore the delay between a crash happening and our servers being told about it.
The second part is harder: when should users tell us that everything is fine?
We can introduce code into Firefox that would tell us every minute that nothing bad happened… but could you imagine the bandwidth costs? Even every hour might be too often. Presently we record this information when the user closes their browser (or if the user doesn’t close their browser, at the user’s local midnight).
The difference between the user experiencing an hour of un-crashing Firefox and that data being recorded is recording delay. This tends to not exceed 24 hours.
If the user shuts down their browser for the day, there isn’t an active Firefox instance to send us the data for collection. This means we have to wait for the next time the user starts up Firefox to send us their “usage hours” number. If this was a Friday’s record, it could easily take until Monday to be sent.
The difference between the data being recorded and the data being sent is the submission delay. This can take an arbitrary length of time, but we tend to see a decent chunk of the data within two days’ time.
This data is being sent in throughout each and every day. Somewhere at this very moment (or very soon) a user is starting up Firefox and that Firefox will send us some Telemetry. We have the facilities to calculate at any given time the usage hours and the crash numbers for each and every part of each and every day… but this would be a wasteful approach. Instead, a scheduled task performs an aggregation of crash figures and usage hour records per day. This happens once per day and the result is put in the CrashAggregates dataset.
The difference between a crash or usage hour record being submitted and it being present in this daily derived dataset is aggregation delay. This can be anywhere from 0 to 23 hours.
This dataset is stored in one format (parquet), but queried in another (prestodb fronted by re:dash). This migration task is performed once per day some time after the dataset is derived.
The
Enforcing Content Security Historically

Enforcing Content Security By Default

The Rust team is happy to announce the latest version of Rust, 1.13.0. Rust is a systems programming language focused on safety, speed, and concurrency.
As always, you can install Rust 1.13.0 from the appropriate page on our website, and check out the detailed release notes for 1.13.0 on GitHub. 1448 patches were landed in this release.
It’s been a busy season in Rust. We enjoyed three Rust conferences, RustConf, RustFest, and Rust Belt Rust, in short succession. It was great to see so many Rustaceans in person, some for the first time! We’ve been thinking a lot about the future, developing a roadmap for 2017, and building the tools our users tell us they need.
And even with all that going on, we put together a new release filled with fun new toys.
What’s in 1.13 stable
The 1.13 release includes several extensions to the language, including the
long-awaited ? operator, improvements to compile times, minor feature
additions to cargo and the standard library. This release also includes many
small enhancements to documentation and error reporting, by many contributors,
that are not individually mentioned in the release notes.
This release contains important security updates to Cargo, which depends on curl and OpenSSL, which both published security updates recently. For more information see the respective announcements for curl 7.51.0 and OpenSSL 1.0.2j.
The ? operator
Rust has gained a new operator, ?, that makes error handling more pleasant by
reducing the visual noise involved. It does this by solving one simple
problem. To illustrate, imagine we had some code to read some data from a file:
fn read_username_from_file() -> Result<String, io::Error> {
let f = File::open("username.txt");
let mut f = match f {
Ok(file) => file,
Err(e) => return Err(e),
};
let mut s = String::new();
match f.read_to_string(&mut s) {
Ok(_) => Ok(s),
Err(e) => Err(e),
}
}
This code has two paths that can fail, opening the file and reading the data
from it. If either of these fail to work, we’d like to return an error from
read_username_from_file. Doing so involves matching on the result of the I/O
operations. In simple cases like this though, where we are only propagating
errors up the call stack, the matching is just boilerplate - seeing it written
out, in the same pattern every time, doesn’t provide the reader with a great
deal of useful information.
With ?, the above code looks like this:
fn read_username_from_file() -> Result<String, io::Error> {
let I got to attend RustConf in September1, and felt these talks in particular may interest someone working on FxA2:
- The keynote isn’t too important to watch if you’re not that involved in Rust. It’s mostly talking about the 2017 plan. But, worth mentioning, is that part of that plan for 2017 is to target and improve Rust libraries for writing server software. A small piece of that is hyper, a Rust HTTP library I work on. Maybe we can start to consider writing some of our software in Rust in 2017.
Futures - The Rust community has been working rapidly on a very promising concept to write asynchronous code in Rust. You likely are pretty comfortable with how Promises work in JavaScript. The Futures library in Rust feels very similar to JavaScript Promises, but! But! They compile down to an optimized state machine, without the need to allocate a whole bunch of closures like JavaScript does.
On top of the Futures library, the community is working on a library that is “futures + network IO”, and that’s tokio. It’s a framework designed to help anyone build a network protocol library. A big user of this is hyper. The examples in hyper show how expressive this pattern can be, while still being super fast.
How to do community RFCs - Rust has a method for the community to suggest improvements to the language, which they call RFCs. These are very similar in practice to Python’s PEPs. It’s been quite successful, and other notable projects have adopted it as well, such as Ember.js. In fact, the RFC process from Rust is what I looked at when we were adjusting how to do our FxA Features. This talk showed how truly impressive it is that the community can work together at designing a better feature.
Rust is a great way to learn how to do systems programming - This was a really special talk about how someone who may be scared of the ominous “systems programming” can actually dive right in without worrying about blowing off a (computer’s) leg. If you’ve mostly used “higher level” languages, and wondered how in the world to dive in, Julia has a great message for you.
If you don’t check out any other talk, at least look at this one. If videos aren’t your thing, try the written article form instead.
 mconley livehacks on real Firefox bugs while thinking aloud.
mconley livehacks on real Firefox bugs while thinking aloud.
https://air.mozilla.org:443/the-joy-of-coding-episode-78-20161109/
Un d'ia como hoy, pero 12 a~nos atr'as fue liberada de forma oficial Firefox 1.0, un navegador diferente y alternativo al IE de aquellos tiempos.
Desde aquel glorioso 9 de noviembre de 2004, Firefox ha incluido funcionalidades que han revolucionado la web, sorteado problemas y navegado con astucia para convertirse en unos de los proyectos de software libre m'as importantes del mundo. Sin dudas debemos sentirnos felices por eso.
Solo nos queda desear muchas felicidades y muchos a~nos m'as de vida a Firefox y a la Comunidad Mozilla por mantenerlo.

Un fondo de escritorio para la ocasi'on.

Los dejo con algunas fotos de nuestras anteriores celebraciones.









 This is the sumo weekly call
This is the sumo weekly call
I travel reasonably often as part of my work. One trend I’ve noticed recently is for hotels to provide unsecured wifi, without even so much as a landing page. While this means a ‘frictionless’ experience for guests connecting to the internet, it’s also extremely bad practice from a security point of view.
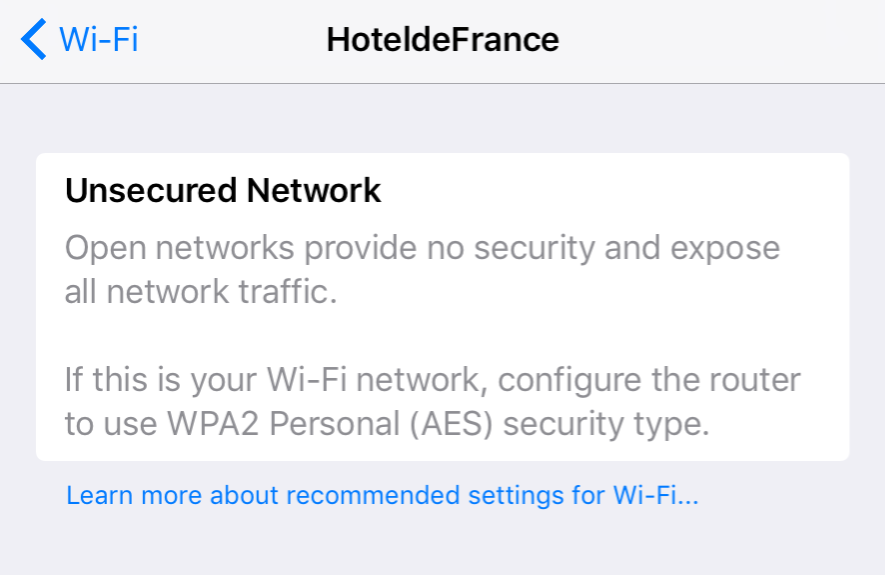
Unless you know and trust the person or organisation providing your internet connection, you should proceed with caution. Your data are valuable - the business model of Facebook is testament to that! Protect your digital identity.
A Virtual Private Network (VPN) is a way to route your traffic through a trusted server. You could run your own, but the usual way is to pay for this kind of service to ensure there are no bandwidth bottlenecks. A nice little bonus to using VPNs is the ability to make it look like you are based in another country, meaning you get access to content that might be restricted in your own country.
I’m still a fan of iPREDator but it can be cumbersome to set up. That’s why I’m currently using TunnelBear as it’s super-simple to configure, works across all of my devices, and they promise not to keep any logs of your activity (which could be shared with the authorities, etc.)
Getting started on iOS
I’m not going to screenshot every step, but I’m sure you can figure it out.
1) Download TunnelBear from the App Store.

2) Open the app and sign up for a new account. You could use a throwaway email account like Mailinator if you’re willing to keep setting up new accounts, I guess.
3) Allow TunnelBear to change the VPN settings for your device.
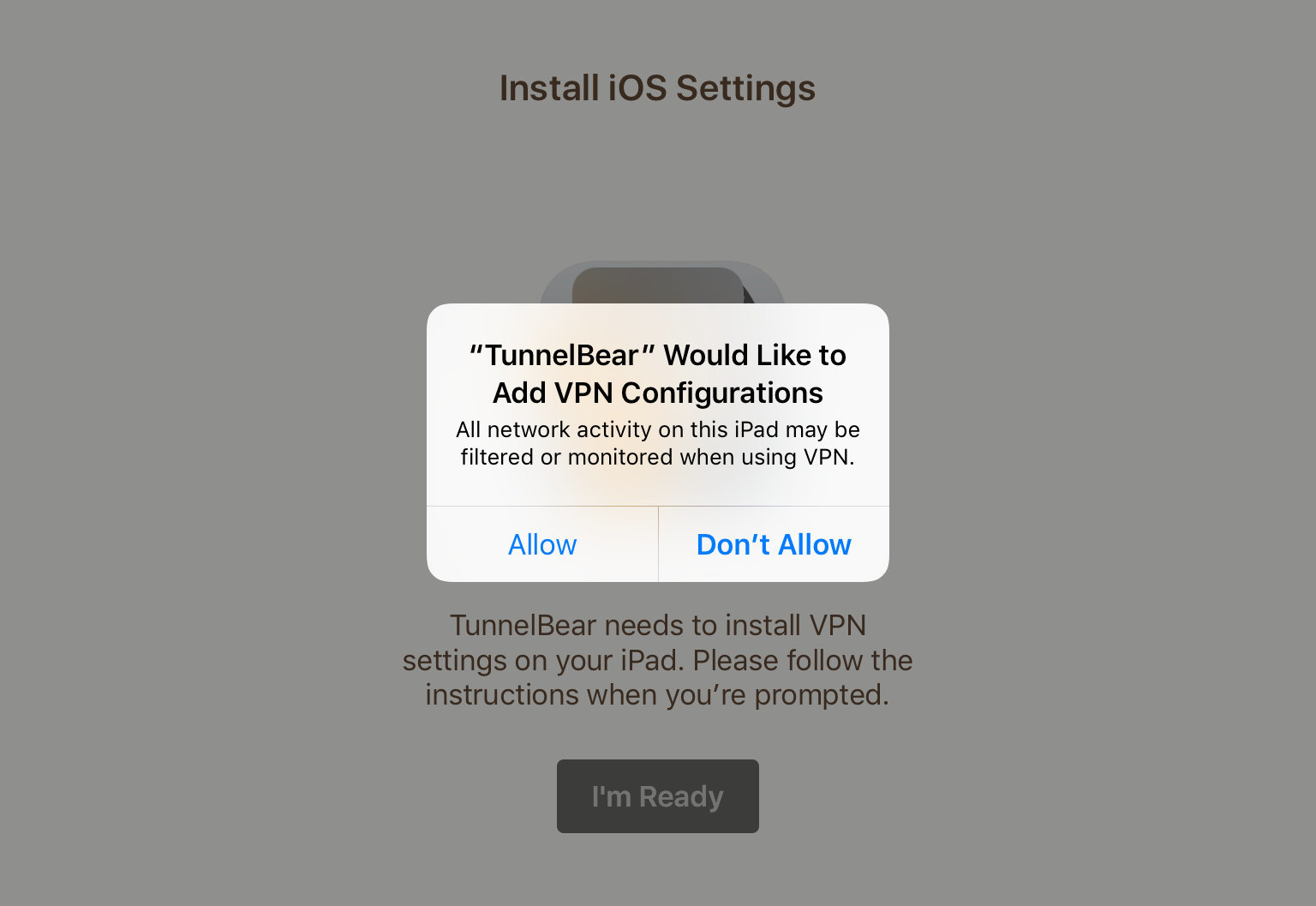
4) Once these VPN settings are installed, you don’t actually have to use the app, as you can connect by going to Settings -> General -> VPN and toggling the switch to ON.
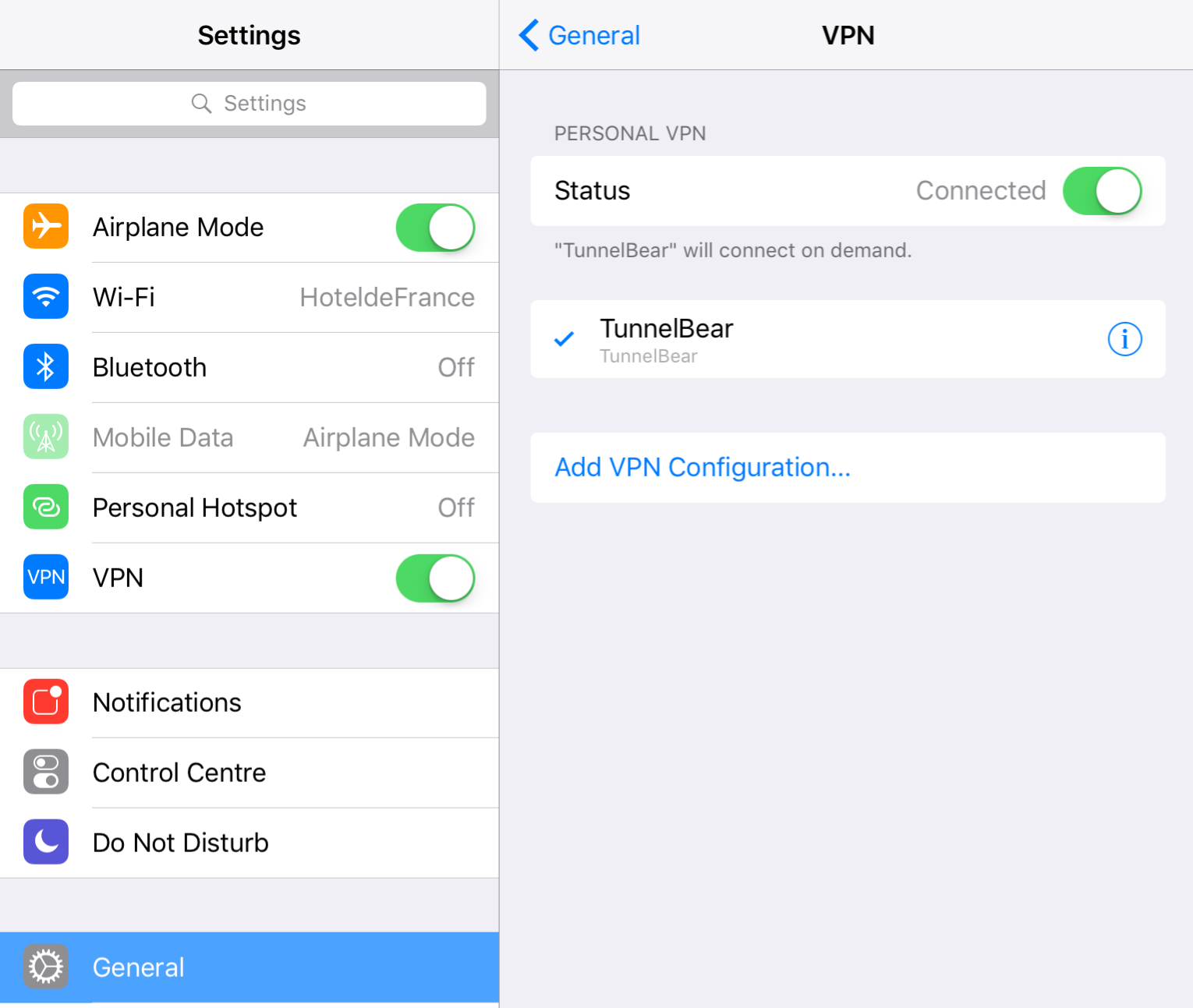
When this toggle switch is on, all of your traffic is being routed through the VPN.
There’s also TunnelBear apps for Mac and Windows, and a one-click install process for Chrome and Opera web browsers. This is great news for users of Chromebooks (like me!)

I’d recommend setting up TunnelBear (or whatever VPN you choose) before travelling. That way, you don’t have to connect to an unsecured wifi network at all. For more advanced users, there’s Tor and the Tor browser, based on Firefox. This works slightly differently, bouncing your traffic around the internet, and is actually what I use on Android for private browsing.
Comments? Questions? I’m @dajbelshaw or you can email me: hello@dynamicskillset.com
When it was revealed that every Government in the world was using technology to spy unlawfully on every other country, there was an arugment that this was acceptable "as long as you have nothing to hide". That argument is, of course, complete rubbish and individual freedoms and rights to privacy are extremely important.
But we've just witnessed in the US another problem with this argument. It's acceptable "as long as you have nothing to hide from every single government and authority that is going to possibly come after". For example, the current Canadian Liberal government might be "ok", but who's going to get elected next. And next? What happens if one of those governments is like the one coming into the US?
There is a chilling example of this in history. In the Netherlands they recorded peoples information in a census and that included peoples religion. In 1941 there were about 140,000 Dutch Jews living in the Netherlands. After the Nazi invasion there were an estimated 35,000 left. Because the Government had census data for them, it was easy for the Nazis to find and eliminate them using that data.
Some 75% of the Dutch-Jewish population perished, an unusually high percentage compared with other occupied countries in western Europe.
As Cory Doctrow said today:
All those times we said, "When you build mass surveillance, you don't just put power in the hands of those you trust, but also the next guy"
— Cory Doctorow (@doctorow) November 9, 2016
Most of my (admittedly small) readership lives in North America or Europe. That means there's likely a Government surveillance operation monitoring you. It could be internal (in my case CSIS) or external (in my case the NSA). Even worse, they share their information with each other through Five Eyes to get around laws. There is a:
"supra-national intelligence organisation that doesn't answer to the known laws of its own countries"
Edward Snowden, via Wikipedia
The US has just elected someone who repeatedly spews lies, rascism, sexism, hatred and profiling and has said he will go after his enemies [1]. That person will soon oversee the largest surveillance operation in the history of mankind. A surveillance operation that spys on the majority of people reading this blog. That should worry you.
[1] By enemies, that's the press, women who accuse him of doing the things he says he does and so on. But you know all this right?
This post is a continuation of my posts discussing the topic of associated type constructors (ATC) and higher-kinded types (HKT):
- The first post focused on introducing the basic idea of ATC, as well as introducing some background material.
- The second post showed how we can use ATC to model HKT, via the “family” pattern.
- The third post did some exploration into what it would mean to support HKT directly in the language, instead of modeling them via the family pattern.
- This post considers what it might mean if we had both ATC and HKT in the language: in particular, whether those two concepts can be unified, and at what cost.
Unifying HKT and ATC
So far we have seen “associated-type constructors” and “higher-kinded types” as two distinct concepts. The question is, would it make sense to try and unify these two, and what would that even mean?
Consider this trait definition:
trait Iterable {
type Iter<'a>: Iterator<Item=Self::Item>;
type Item;
fn iter<'a>(&'a self) -> Self::Iter<'a>;
}
In the ATC world-view, this trait definition would mean that you can now specify a type like the following
::Iter<'a>
Depending on what the type T and lifetime 'a are, this might get
“normalized”. Normalization basically means to expand an associated
type reference using the types given in the appropriate impl. For
example, we might have an impl like the following:
impl<A> Iterable for Vec<A> {
type Item = A;
type Iter<'a> = std::vec::Iter<'a, A>;
fn iter<'a>(&'a self) -> Self::Iter<'a> {
self.clone()
}
}
In that case, as Iterable>::Iter<'x> could be normalized
to std::vec::Iter<'x, Foo>. This is basically exactly the same way
that associated type normalization works now, except that we have
additional type/lifetime parameters that are placed on the associated
item itself, rather than having all the parameters come from the trait
reference.
Associated type constructors as functions
Another way to view an ATC is as a kind of function, where the
normalization process plays the role of evaluating the function when
applied to various arguments. In that light, as
Iterable>::Iter could be viewed as a “type function” with a signature
like lifetime -> type; that is, a function which, given a type and a
lifetime, produces a type:
as Iterable>::Iter<'x>
^^^^^^^^^^^^^^^^^^^^^^^^^^^^ ^^
function argument
When I write it this way, it’s natural to ask how such a function is
related to a higher-kinded type. After all, lifetime -> type could
also be a kind, right? So perhaps we should think of as
Iterable>::Iter as a
 Reuni'on bi-semanal para hablar sobre el estado de Mozilla, la comunidad y sus proyectos. Bi-weekly meeting to talk (in Spanish) about Mozilla status, community and...
Reuni'on bi-semanal para hablar sobre el estado de Mozilla, la comunidad y sus proyectos. Bi-weekly meeting to talk (in Spanish) about Mozilla status, community and...
Today's the American election and no matter what, some of you are going to be delighted, some of you are going to be disappointed, and a few of you are going to be really steamed. But no matter what your perspective, we can all agree it's a good thing today is the sixth anniversary of TenFourFox's first beta release, 4.0b7, on the 8th of November 2010. Yes, we're six years old today! And by golly, we act like it!
Hail to the Chief!
http://tenfourfox.blogspot.com/2016/11/happy-6th-birthday-tenfourfox.html
My ‘Essential Elements of Digital Literacies’ (thesis / book) looks like this:

Unlike some other people who seemed to need a subject for their latest blog post or journal article, this wasn’t something I just sat down and thought about for half an hour. This was the result of a few years worth of work, and a large meta-analysis of theory and practice.
The elements that most people seem to take issue with when looking at the above diagram are 'Confident’ and 'Civic’. The top row, the four 'skillsets’ seem to pose no problem, but people wonder how they can teach the bottom four 'mindsets’ - particularly the two just highlighted.
The latest episode of the Techgypsies podcast by Audrey Watters and Kin Lane does a great job of explaining the Civic element of digital literacies. I’ve embedded the player below, or click here. Listen to the whole thing as it’s fascinating, but the bit that we’re interested here starts at about the 20-minute mark.
Audrey and Kin use the 'scandal’ around Hillary Clinton’s private email server as a lens to show how poor our understanding of everyday tech actually is. What I thought was particularly enlightening was their likening the 'learn to code’ movement to standard IT practices. In other words: “oh, this is too hard for you? well, just leave it to us and we’ll sort it out for you”. In other words, passive, uncritical use of technology is fine unless, you know, you’re a 'techie’.
In learning organisations, in businesses, and in families, there are practices built upon technologies that need to be learned. As Audrey and Kin outline, although it’s entirely unsexy, an understanding of difference between POP, SMTP, and IMAP would have meant people could have seen the email 'scandal’ as entirely a non-event.
What I really appreciated was Audrey’s reframing of this kind of thing as a social studies issue. We shouldn’t have to have separate classes for this kind of thing any more. Instead, our society should have a baseline understanding of how the tech we use every day works. That also applies to web domains, and to the way that data flows around the web.
Of course, a lot of this is covered in Mozilla’s Web Literacy Map. Not all of what we need to know pertains to the 'web’, of course - which is where the Essential Elements of Digital Literacies come in. They’re plural, context-dependent, and should be co-defined in your community. As well as raising awareness of the latest shiny technologies (e.g. blockchain, AI) we should be ensuring people are comfortable with the tech they’re using right now.
Questions? Comments? I’m @dajbelshaw or you can email me: hello@dynamicskillset.com
I wrote this post on the Servo wiki to help beginners getting started with rebasing and squashing, two of the most terrifying operations you’ll face if you are not familiar with git. I’m cross posting this here for people working on other projects.
Big thanks to Wafflespeanut who proofread the post, any error you found here is my own.
Suppose you’ve created a pull request following the checklist, but the reviewer ask you to fix something, do a rebase or squash your commits, how exactly do you do that? If you have some experience with git, you might want to check the GitHub workflow for a quick overview. But if you are not familiar with git enough, we’ll teach you how to do these common operations in detail.
Suppose you’ve created a pull request following the checklist, but the reviewer asks you to fix something, do a rebase or squash your commits, how exactly do you do that? If you have some experience with git, you might want to check the GitHub workflow for a quick overview. But if you are not familiar with git enough, we’ll teach you how to do these common operations in detail.
Fixing review comments
Once you reviewer reviewed your patch, he/she might leave some comments asking you to fix something. So you edit the source code, then you will probably do something like this.
git addthengit commit, write a commit message telling people what you’ve fixed. (You might also check out the--fixupoption forgit commitin the workflow doc.)- Simply
git pushto the same remote branch which you’ve created the PR with. The GitHub pull request page will pick up your changes, and hide those review comments you’ve fixed.
If your fix is trivial, and you have a single commit ready for merge, then you can consider using git commit --amend to add the change directly to your last commit. Then, all you need to do is git push -f to force push to the branch at your fork.
Rebasing
Sometimes, if someone merged new code while your patch is still in review, git might not be able to figure out how to apply your patch on top of the new code. In this case, our bors-servo bot will notify you with a helpful message:
https://shinglyu.github.io/web/2016/11/08/servo-rebase-and-squash-guide.html
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
Blog Posts
- Associated type constructors, part 1: basic concepts and introduction.
- Associated type constructors, part 2: family traits.
- Associated type constructors, part 3: What higher-kinded types might look like.
- Rust and Vala.
- Rust and GObject.
- Actually using Iron.
- Falling for Rust. Why Clever Cloud is betting on Rust for the future.
- Cross-platform development on Windows is suddenly awesome. Using Rust on WSL (Windows Subsystem for Linux).
- Rust performance testing on Travis CI.
- Introducing a Rust actor library.
News & Project Updates
- Refactoring std for ultimate portability.
- Crates.io expiry postmortem (2016-11-07).
- Rust and GNOME meeting notes.
- 2016 Rust Commercial User Survey results.
- rustup 0.6.5 is released with new build of curl that fixes security issues.
Other Weeklies from Rust Community
- This week in Rust docs 29. Updates from the Rust documentation team.
- These weeks in Servo 82. Servo is a prototype web browser engine written in Rust.
- This week in Ruru 4. Ruru lets you write native Ruby extensions in Rust.
- What's coming up in imag 19. imag is a text based personal information management suite.
- This week in TiKV 2016-11-07. TiKV is a distributed Key-Value database.
- PlanetKit week 3: hexagons! PlanetKit generates colorful blobs that might one day resemble planets. (Week 1 introduces PlanetKit and week 2 is about creating basic terrain).