 This is the Sumo weekly call
This is the Sumo weekly call
Highlights
- A reminder that Firefox ESR 52 will be the last version to support WinXP
- past reports that the new permission doorhanger UI has landed!
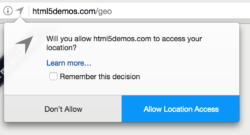
- Permission prompts are no longer accidentally dismissable
- Available actions are more prominent, not just the main one
- Working on followups in mozilla-central. Notice problems? File them blocking this bug.
- ralin reports that the new HTML-based visual video controls have landed!
- florian and MattN report that the insecure password warning in the URL bar will ship in Firefox 51!
- They also note that work on the contextual warning for insecure passwords made great progress and is currently slated for Firefox 52.
- Flip security.insecure_field_warning.contextual.enabled to true and signon.autofillForms.http to false to test the feature.
- kitcambridge wants people to know that a new add-on has been released to let you examine your own Sync data. As always, the source is also available
- He also has a call-to-action to validate your bookmarks data (see this mailing list thread and this follow-up post for how to contribute anonymized validator data)


Contributor(s) of the Week
- Please welcome Joe Hildebrand, who has joined Mozilla as Director of Engineering for the Firefox browsers!
- Resolved bugs (excluding employees): https://mzl.la/2gcieyv
- New Contributors
Project Updates
Add-ons
- The team has published a blog post on what’s new for WebExtensions in Firefox 52
- They’re also testing out chrome.storage.sync and working on getting backend storage into release quality
Electrolysis (e10s)
- Turning on e10s-multi on Nightly (with 2 content processes) is blocked on Talos regressions and a few test failures. This should happen sometime soon during the Nightly 53 cycle (and hold on Nightly)
Firefox Core Engineering
- ddurst reports that there is going to be an aggressive push to update “orphaned” Firefox installs (44-47, inclusive) between now and the end of 2016
- “Orphaned” = not updated since 2 versions back.
- Concerted effort to encourage people to update from 42-47 to current (50). 42-25 isn’t a huge chunk, but this is a much more aggressive push.
- What causes orphans?
- Some are just users being slow to update
- Blocked by security suite. (Avast was trying to update on users’ behalf). Some are worked out with vendors, some are actual problems.
- Some are related to network latency (bugs have been filed and fixed), but ddurst’s team just got a machine that’s not updating and not affected by latency.
- 3.x upgrades
- This is

In the preface to his 2002 book, Small Pieces Loosely Joined Dave Weinberger writes:
What the Web has done to documents it is doing to just about every institution it touches. The Web isn’t primarily about replacing atoms with bits so that we can, for example, shop on line or make our supply chains more efficient. The Web isn’t even simply empowering groups, such as consumers, that have traditionally had the short end of the stick. Rather, the Web is changing our understanding of what puts things together in the first place. We live in a world that works well if the pieces are stable and have predictable effects on one another. We think of complex institutions and organizations as being like well-oiled machines that work reliably and almost serenely so long as their subordinate pieces perform their designated tasks. Then we go on the Web, and the pieces are so loosely joined that frequently the links don’t work; all too often we get the message (to put it palindromically) “404! Page gap! 404!” But, that’s ok because the Web gets its value not from the smoothness of its overall operation but from its abundance of small nuggets that point to more small nuggets. And, most important, the Web is binding not just pages but us human beings in new ways. We are the true “small pieces” of the Web, and we are loosely joining ourselves in ways that we’re still inventing.
In the fourteen years since Weinberger wrote these words, we’ve come to an everyday lived experience of living in a blended physical/digital world where things don’t always have stable, predictable effects.
As a result, those of us with the required mindset to deal with the impermanence of technologies are constantly riding the wave of innovation on the web, experimenting with different facets of our online identities, and learning new skills that may be immediately useful, or perhaps put to work further down the line.
On the other hand, those with the opposite - a deficit mindset tend to flock to places of perceived stability. Places that, in internet terms, have ‘always’ been around. These might be social networking platforms such as Facebook which 'everyone’ uses, search engines like Google, or email providers such as Microsoft. This attitude then seeps into the way we approach our projects at work: we look to either repurpose the platforms with which we’re already familiar, or create a one-stop shop where everything related to the project should reside.
I’d argue that we should use the medium of the web in the way that it works best. That is to go back to the title of Weinberger’s book, as 'small pieces, loosely joined’. Although I don’t claim any originality or credit for doing so, I want to use my own web presence as an example of this approach.
1. Canonical URL
The one thing that those with a deficit mindset do get right is that you should have a single place to point people towards, one place that serves a focus of attention. For me, that’s dougbelshaw.com:

As you can see, at the time of writing, this serves as an introduction to my work, as well as providing links to my other places and accounts online. This approach would work equally well for a project, or for an organisation.
Note that I control this space. I own (well, rent) it and that I can make this look however I want, rather than having to follow templates from a provider.
2. Horses for courses

This blog post that you’re reading is on a separate blog to my main blog. I use this one for anything relating to digital/new literacies and, as such, provide a way for those interested in this aspect of my work to get a 'clean’ feed, without the 'noise’ of my other work.
While you can get a similar effect by creating categories within, say
When I started making my social media rounds this morning, I came across Jeffrey Zeldman’s call to action for this year’s Blue Beany Day on November 30th. But I respectfully disagree with a number of points he is making in his post about JavaScript frameworks and their accessibility implications.
Frameworks aren’t inaccessible because they’re frameworks
First, I agree that the spreading of new JS frameworks is a temporary problem for accessibility, since many developers who build these frameworks do indeed not know, or take into account, web standards such as the correct HTML semantics, or where these do not work, standards like WAI-ARIA. But if they did, the output those frameworks generated would be just as accessible as plain HTML typed into a plain text editor.
So the problem with inaccessible output is not that they come from frameworks, but that these frameworks are being told the wrong thing. And in my opinion, the solution cannot be to crawl back into a niche and just do plain HTML and CSS and ignore JavaScript. It was invented 18 years ago and is actively being improved to provide better user experiences. Ignoring it would be like going back to Windows 95 and hope the computer still capable of running it will last another month or two.
I strongly believe that this problem can be solved. The solution to this comes in three main parts.
Education
Web standards and their accessibility implications must become part of any and all university curricula that teach web development. A theme that resurfaces at every conversation I have with hiring managers is that engineers fresh from university have never even heard of accessibility.
And guess who those people should be that teach the younger generation these basics? Right, it should be us seasoned accessibility advocates who worked in this field for 15 or 20 years and know this stuff. We must push for many more solutions to this teaching problem than we have in the past.
Fix up frameworks and teach others by doing so
The second angle to attack this problem from is by fixing existing frameworks and pushing those fixes upstream via pull requests or whatever means is used in that particular project’s environment. And be vocal about it. Explain why you’re doing certain things and what the accessibility and usability benefits are. I know a lot of good people who already do this, and successfully, and have helped to make the world a lot better again for many who rely on assistive technologies while accessing web content. And also include those who benefit, but don’t use such assistive technologies.
And even if you’re someone who doesn’t have the coding skills to fix up the frameworks yourself, open pull requests. Describe the issues, maybe link to some resources about web accessibility. And tell others you opened that pull request, so they may become aware and jump in to provide their skills.
But first and foremost, be friendly when you do those things. The framework authors or community aren’t your enemy. They may lack some knowledge, but that is probably just a matter of improper education at their university (see above), or lack of awareness. Both can be changed, and this is only achieved by being friendly, empathic, and not by putting them in a defensive position by being rude.
Push on implementors to improve standards support
A third point that is equally important is to push implementors, in an equally friendly tone, to agree on technical issues in standards bodies and implement better support for new widgets, improve support in existing ones such as styling for form elements, for example, and thus give developers less reason to reinvent the wheel with every framework. The better the browser tooling is, the more accessible the web becomes from this angle, too.
JavaScript is not our enemy
JavaScript or frameworks built with it are not our enemy. They are neither the enemy of accessibility, nor of web standards in general. And neither are the ones who thought up those frameworks to make other developers’ lives easier. They want to do good things for the web just like accessibility advocates do, they just need to work together more.
https://www.marcozehe.de/2016/11/23/javascript-not-enemy-accessibility/
“the overall impression of the state of security and robustness
of the cURL library was positive.”
I asked for, and we were granted a security audit of curl from the Mozilla Secure Open Source program a while ago. This was done by Mozilla getting a 3rd party company involved to do the job and footing the bill for it. The auditing company is called Cure53.
![]() I applied for the security audit because I feel that we’ve had some security related issues lately and I’ve had the feeling that we might be missing something so it would be really good to get some experts’ eyes on the code. Also, as curl is one of the most used software components in the world a serious problem in curl could have a serious impact on tools, devices and applications everywhere. We don’t want that to happen.
I applied for the security audit because I feel that we’ve had some security related issues lately and I’ve had the feeling that we might be missing something so it would be really good to get some experts’ eyes on the code. Also, as curl is one of the most used software components in the world a serious problem in curl could have a serious impact on tools, devices and applications everywhere. We don’t want that to happen.
Scans and tests and all
We run static analyzers on the code frequently with a zero warnings tolerance. The daily clang-analyzer scan hasn’t found a problem in a long time and the Coverity once-every-few-weeks occasionally finds something suspicious but we always fix those immediately.
We have thousands of tests and unit tests that we run non-stop on the code on multiple platforms running multiple build combinations. We also use valgrind when running tests to verify memory use and check for potential memory leaks.
Secrecy
The audit itself. The report and the work on fixing the issues were all done on closed mailing lists without revealing to the world what was really going on. All as our fine security process describes.
There are several downsides with fixing things secretly. One of the primary ones is that we get much fewer eyes on the fixes and there aren’t that many people involved when discussing solutions or approaches to the issues at hand. Another is that our test infrastructure is made for and runs only public code so the code can’t really be fully tested until it is merged into the public git repository.
The report
We got the report on September 23, 2016 and it certainly gave us a lot of work.
The audit report has now been made public and is a very interesting work if you’re into security, C code and curl hacking. I find the report very clear, well written and it spells out each problem very accurately and even shows proof of concept code snippets and exploit examples to drive the points home.
Quoted from the report intro:
As for the approach, the test was rooted in the public availability of the source code belonging to the cURL software and the investigation involved five testers of the Cure53 team. The tool was tested over the course of twenty days in August and September of 2016 and main efforts were focused on examining cURL 7.50.1. and later versions of cURL. It has to be noted that rather than employ fuzzing or similar approaches to validate the robustness of the build of the application and library, the latter goal was pursued through a classic source code audit. Sources covering authentication, various protocols, and, partly, SSL/TLS, were analyzed in considerable detail. A rationale behind this type of scoping pointed to these parts of the cURL tool that were most likely to be prone and exposed to real-life attack scenarios. Rounding up the methodology of the classic code audit, Cure53 benefited from certain tools, which included ASAN targeted with detecting memory errors, as well as Helgrind, which was tasked with pinpointing synchronization errors with the threading model.
They identified no less than twenty-three (23) potential problems in the code, out of which nine were deemed security vulnerabilities. But I’d also like to emphasize that they did also actually say this:
At the same time, the overall impression of the state of security and robustness of the cURL library was positive.
Resolving problems
In the curl security team we decided to downgrade one of the 9 vulnerabilities to a “plain bug” since the required attack scenario was very complicated and the risk deemed small, and two of the issues we squashed into treating them as a single one. That left us with 7 security
Heroku is a cloud Platform-as-a-Service (PaaS) we use at Pontoon for over a year and a half now. Despite some specifics that are not particularly suitable for our use case, it has proved to be a very reliable and easy to use deployment model.
Thanks to the amazing Jarek, you can now freely deploy your own Pontoon instance in just a few simple steps, without leaving the web browser and with very little configuration.
To start the setup, click a Deploy to Heroku button in your fork, upstream repository or this blog post. You will need to log in to Heroku or create an account first.

Next, you’ll be presented with the configuration page. All settings are optional, so you can simply scroll to the botton of the page and click Deploy.
Still, I suggest you to set the App Name for an easy to remember URL and Admin email & password, which are required for logging in (instead of Firefox Accounts, custom Heroku deployment uses conventional log in form).
 [показать]
[показать]
When setup completes, you’re ready to View your personal Pontoon instance in your browser or Manage App in the Heroku Dashboard.
[показать]
This method is also pretty convenient to quickly test or demonstrate any Pontoon improvements you might want to provide – without setting the development environment locally. Simply click Deploy to Heroku from the README file in your fork after you have pushed the changes.
If you’re searching for inspiration on what to hack on, we have some ideas!
http://horv.at/blog/set-up-your-own-pontoon-instance-in-5-minutes/
Hacktoberfest is an event organized by DigitalOcean in partnership with GitHub. It encourages contributions to open source projects during the month of October. This year the webextensions-examples project participated.
“webextensions-examples” is a collection of simple but complete and installable WebExtensions, that demonstrate how to use the APIs and provide a starting point for people writing their own WebExtensions.
We had a great response: contributions from 8 new volunteers in October. Contributions included 4 brand-new complete examples:
- emoji-substitution: shows how to use a content script to modify web pages. “emoji-substitution” replaces text in web pages with the corresponding emoji.
- list-cookies: shows how to use the cookies API, by showing a popup that lists all the cookies in the active tab.
- selection-to-clipboard: shows how to copy text to the system clipboard, by injecting a content script into pages that copies the selection to the clipboard on mouse-up events.
- window-manipulator: shows how to use the windows API to manipulate browser windows. It adds options to resize, open, close, and minimize windows.
So thanks to DigitalOcean, to the add-ons team for helping me review PRs, and most of all, to our new contributors:
https://blog.mozilla.org/addons/2016/11/22/webextensions-examples-and-hacktoberfest/
This morning I gave one of two keynotes at the Internet Days in Stockholm, Sweden. Suffice to say, I felt well chuffed to be presenting at such a prestigious event and opening up for a day that will be closed by an interview with Edward Snowden!

Frankly, I freaked out and wanted to do something special. So, instead of doing a “state of the web” talk or some “here is what’s amazing right now”, I thought it would be fun to analyse how the web is doing. As such, I pretended to be a psychiatrist who interviews a slightly depressed internet on the verge of a midlife crisis.

The keynote is already available on YouTube.
The slides are on Slideshare:
Here is the script, which – of course – I failed to stick to. The bits in strong are my questions, the rest the answers of a slightly depressed internet.
Hello again, Internet. How are we doing today?
Not good, and I don’t quite know why.
It’s not that you feel threatened again, is it?
No, no, that’s a thing of the past. It was a bit scary for a while when the tech press gave up on me and everybody talked to those other guys: Apps.
But it seems that this is well over. People don’t download apps anymore. I think the reason is that they were too pushy. Deep down, people don’t want to be locked in. They don’t want to have to deal with software issues all the time. A lot of apps felt like very needy Tamagochi – always wanting huge updates and asking for access to all kind of data. Others even flat out told you you’re in the wrong country or the phone you spent $500 on last month is not good enough any longer.
No, I really think people are coming back to me.
That’s a good thing, isn’t it?
Yes, I suppose. But, I feel bad. I don’t think I make a difference any longer. People see me as a given. They see me as plumbing and aren’t interested in how I work. They don’t see me as someone to talk to and create things with me. They just want to consume what others do. And – much like running clear water – they don’t understand that it isn’t a normal thing for everybody. It is actually a privilege to be able to talk to me freely. And I feel people are not using this privilege.
I want to matter, I want to be known as a great person to talk to.
Oh dear, this sounds like you’re heading into a midlife crisis. Promise me you won’t do something stupid like buying a fancy sports car to feel better…
It’s funny you say that. I don’t want to, but I have no choice. People keep pushing me into things. Things I never thought I needed to be in.
But, surely that must feel good. Change is good, right?
Yes, and no. Of course it feels great that people realise I’m flexible enough to power whatever. But there are a few issues with that. First of all, I don’t want to power things that don’t solve issues but are blatant consumerism. When people talk about “internet of things” it is mostly about solving inconveniences of the rich and bored -instead of solving real problems. There are a few things that I love to power. I’m great at monitoring things and telling you if something is prone to breaking before it does. But these are rare. Most things I am pushed into are borderline silly and made to break. Consume more, do less. Constant accumulation of data with no real insight or outcome. Someone wants that data. It doesn’t go back to the owner of the things in most cases – or only a small part of it as a cute graph. I don’t keep that data either. But I get dizzy with the amount of traffic I need to deal with.
And the worst is that people connect things to me without considering the consequences. Just lately a lot of these things ganged up on me and took down a large bit of me
We build a lot of code at Mozilla. Every time someone pushes changes to the code that makes up Firefox we build the application on multiple platforms in a variety of build configurations. This means that we’re constantly looking for ways to make the build faster–to get faster results from our builds and tests and to use less machine time so that we can use fewer machines for builds and save money.
A few years ago my colleague Mike Hommey did some work to see if we could deploy a shared compiler cache. We had been using ccache for many of our builds, but since we use ephemeral build machines in AWS and we also have a large pool of build machines, it doesn’t help as much as it does on a developer’s local machine. If you’re interested in the details, I’d recommend you go read his series of blog posts: Shared compilation cache experiment, Shared compilation cache experiment, part 2, Testing shared cache on try and Analyzing shared cache on try. The short version is that the project (which he named sccache) was extremely successful and improved our build times in automation quite a bit. Another nice win was that he added support for Microsoft Visual C++ in sccache, which is not supported by ccache, so we were finally able to use a compiler cache on our Windows builds.
This year we started a concerted effort to drive build times down even more, and we’ve made some great headway. Some of the ideas for improvement we came up with would involve changes to sccache. I started looking at making changes to the existing Python sccache codebase and got a bit frustrated. This is not to say that Mike wrote bad code, he does fantastic work! By nature of the sccache design it is doing a lot of concurrent work and Python just does not excel at that workload. After talking with Mike he mentioned that he had originally planned to write sccache in Rust, but at the time Rust had not had its 1.0 release and the ecosystem just wasn’t ready for the work he needed to do. I had spent several months learning Rust after attending an “introduction to Rust” training session and I thought it’d be a good time to revisit that choice. (I went back and looked at some meeting notes and in late April I wrote a bullet point “Got distracted and started rewriting sccache in Rust”.)
As with all good software rewrites, the reality of things made it into a much longer project than anticipated. (In fairness to myself, I did set it aside for a few months to spend time on another project.) After seven months of part-time work on the project it’s finally gotten to the point where I’m ready to put it into production usage, replacing the existing Python tool. I did a series of builds on our Try server to compare performance of the existing sccache and the new version, mostly to make sure that I wasn’t going to cause regressions in build time. I was pleasantly surprised to find that the Rust version gave us a noticeable improvement in build times! I hadn’t done any explicit work on optimizing it, but some of the improvements are likely due to the process startup overhead being much lower for a Rust binary than a Python script. It actually lowered the time we spent running our configure script by about 40% on our Linux builds and 20% on our OS X builds, which makes some sense because configure invokes the compiler quite a few times, and when using ccache or sccache it will invoke the compiler using that tool.
My next steps are to tackle the improvements that were initially discussed. Making sccache usable for local developers is one thing, since Windows developers can’t use ccache currently this should help quite a bit there. We also want to make it possible for developers to use sccache and get cache hits from the builds that our automation has already done. I’d also like to spend some time polishing the tool a bit so that it’s usable to a wider audience outside of Mozilla. It solves real problems that I’m sure other organizations face as well and it’d be
 The Monday Project Meeting
The Monday Project Meeting
Swagger has come a long way. The project got renamed ("Open API") and it seems to have a vibrant community.
If you are not familiar with it, it's a specification to describe your HTTP endpoints (spec here) that has been around since a few years now ~ and it seems to be getting really mature at this point.
I was surprised to find out how many available tools they are now. The dedicated page has a serious lists of tools.
There's even a Flask-based framework used by Zalando to build microservices.
Using Swagger makes a lot of sense for improving the discoverability and documentation of JSON web services. But in my experience, with these kind of specs it's always the same issue: unless it provides a real advantage for developers, they are not maintained and eventually removed from projects.
So that's what I am experimenting on right now.
One use case that interests me the most is to see whether we can automate part of the testing we're doing at Mozilla on our web services by using Swagger specs.
That's why I've started to introduce Swagger on a handful of projects, so we can experiment on tools around that spec.
One project I am experimenting on is called Smwogger, a silly contraction of Swagger and Smoke (I am a specialist of stupid project names.)
The plan is to see if we can fully automate smoke tests against our APIs. That is, a very simple test scenario against a deployment, to make sure everything looks OK.
In order to do this, I have added an extension to the spec, called x-smoke-test, where developers can describe a simple scenario to test the API with a couple of assertions. There are a couple of tools like that already, but I wanted to see whether we could have one that could be 100% based on the spec file and not require any extra coding.
Since every endpoint has an operation identifier, it's easy enough to describe it and have a script (==Smwogger) that plays it.
Here's my first shot at it... The project is at https://github.com/tarekziade/smwogger and below is an extract from its README
Running Smwogger
To add a smoke test for you API, add an x-smoke-test section in your YAML or JSON file, describing your smoke test scenario.
Then, you can run the test by pointing the Swagger spec URL (or path to a file):
$ bin/smwogger smwogger/tests/shavar.yaml
Scanning spec... OK
This is project 'Shavar Service'
Mozilla's implementation of the Safe Browsing protocol
Version 0.7.0
Running Scenario
1:getHeartbeat... OK
2:getDownloads... OK
3:getDownloads... OK
If you need to get details about the requests and responses sent, you can use the -v option:
$ bin/smwogger -v smwogger/tests/shavar.yaml
Scanning spec... OK
This is project 'Shavar Service'
Mozilla's implementation of the Safe Browsing protocol
Version 0.7.0
Running Scenario
1:getHeartbeat...
GET https://shavar.somwehere.com/__heartbeat__
>>>
HTTP/1.1 200 OK
Content-Type: text/plain; charset=UTF-8
Date: Mon, 21 Nov 2016 14:03:19 GMT
Content-Length: 2
Connection: keep-alive
OK
<<<
OK
2:getDownloads...
POST https://shavar.somwehere.com/downloads
Content-Length: 30
moztestpub-track-digest256;a:1
>>>
HTTP/1.1 200 OK
Content-Type: application/octet-stream
Date: Mon, 21 Nov 2016 14:03:23 GMT
Content-Length: 118
Connection: keep-alive
n:3600
i:moztestpub-track-digest256
ad:1
u:tracking-protection.somwehere.com/moztestpub-track-digest256/1469223014
<<<
OK
3:getDownloads...
POST https://shavar.somwehere.com/downloads
Content-Length: 35
moztestpub-trackwhite-digest256;a:1
>>>
HTTP/1.1 200 OK
Content-Type: application/octet-stream
Date: Mon, 21 Nov 2016 14:03:23 GMT
Content-Length: 128
Connection: keep-alive
n:3600
i:moztestpub-trackwhite-digest256
ad:1
u:tracking-protection.somwehere.com/moztestpub-trackwhite-digest256/1469551567
<<<
OK
Scenario
A scenario is described by providing a sequence of operations to perform, given their operationId.
For each operation, you can make some assertions on the response by providing values for the status code and some headers.
Example in YAML
x-smoke-test:
scenario:
- getSomething:
response:
status: 200
headers:
Content-Type: application/json
- getSomethingElse
response:
status: 200
- getSomething
response:
status: 200
If a response does not match, an
This is the second post in a series on memory segmentation. It covers working with static and dynamic libraries in Linux and OSX. Make sure to check out the first on object files and symbols.
Let’s say we wanted to reuse some of the code from our previous project in our next one. We could continue to copy around object files, but let’s say we have a bunch and it’s hard to keep track of all of them. Let’s combine multiple object files into an archive or static library. Similar to a more conventional zip file or “compressed archive,” our static library will be an uncompressed archive.
We can use the ar command to create and manipulate a static archive.
1 2 | |
The -r flag will create the archive named libhello.a and add the files
x.o and y.o to its index. I like to add the -v flag for verbose output.
Then we can use the familiar nm tool I introduced in the
previous post
to examine the content of the archives and their symbols.
1 2 3 4 5 6 7 8 9 10 11 | |
Some other useful flags for ar are -d to delete an object file, ex. ar -d
libhello.a y.o and -u to update existing members of the archive when their
source and object files are updated. Not only can we run nm on our archive,
otool and objdump both work.
Now that we have our static library, we can statically link it to our program
and see the resulting symbols. The .a suffix is typical on both OSX and
Linux for archive files.
1 2 3 4 5 6 | |
Our compiler understands how to index into archive files and pull out the functions it needs to combine into the final executable. If we use a static library to statically link all functions required, we can have one binary with no dependencies. This can make deployment of binaries simple, but also greatly increase their size. Upgrading large binaries incrementally becomes more costly in terms of space.
While static libraries allowed us to reuse source code, static linkage does not allow us to reuse memory for executable code between different processes. I really want to put off talking about memory benefits until the next post, but know that the solution to this problem lies in “dynamic libraries.”
While having a single binary file keeps things simple, it can really hamper memory sharing and incremental relinking. For example, if you have multiple executables that are all built with the same static library, unless your OS is really smart about copy-on-write page sharing, then you’re likely loading multiple copies of the same exact code into memory! What a waste! Also, when you want to rebuild or update your binary, you spend time performing relocation again and again with static libraries. What if we could set aside object files that we could share amongst multiple instances of the same or even different processes, and perform relocation at runtime?
The solution is known as dynamic libraries. If static libraries and static linkage were Atari controllers, dynamic libraries and dynamic linkage are Steel Battalion controllers. We’ll show how to work with them in the rest of this post, but I’ll prove how memory is saved in a later post.
Let’s say we
The Changelog has just published an episode about Servo. It covers the motivations and goals of the project, some aspects of Servo performance and use of the Rust language, and even has a bit about our wonderful community. If your curious about why Servo exists, how we plan to ship it to real users, or what it was like to use Rust before it was stable, I recommend giving it a listen.
https://metajack.im/2016/11/21/servo-interview-on-the-changelog/
Three years ago (2013-324) we held the first Homebrew Website Club meetup at Mozilla San Francisco.

In the tradition of the Homebrew Computer Club, I wrote up the Homebrew Website Club Newsletter Volume 1 Issue 1 which has been largely replaced by Kevin Marks's excellent live-tweeting and summary postings after each San Francisco meetup.
Since then Homebrew Website Clubs have sprung up in over a dozen cities world wide and continue regularly (fortnightly or monthly) in nine cities across four time zones and three countries, six of which started in 2016!
New Homebrew Website Club cities this year, along with their start dates and a subsequent photo from one of their meetups this year:
- 2016-01-13: Los Angeles, California
[показать]
- 2016-05-25: N"urnberg, GERMANY

- 2016-06-15: Bellingham, Washington

- 2016-09-21: Baltimore, Maryland

- 2016-10-05: Birmingham, ENGLAND - no photo! (yet) Hope to see one soon!
- 2016-06-15: London, ENGLAND

We have also seen a surge in cities with folks that are interested in starting up a Homebrew Website Club. Many existing cities started with just two people and grew slowly and steadily over time. All it takes is two individuals, committed to supporting each other in a fortnightly (or monthly) gathering to share what they have done recently on their personal websites, and they aspire to create next.
Find your city on this wiki page and add yourself! Then hop in the #indieweb chat channel and say hi!
- indieweb.org/Homebrew_Website_Club#Getting_Started_or_Need_Restarting
- #indieweb chat on the Freenode IRC network
- Tips on how to organize and run a Homebrew Website Club
Pick a venue, talk about all things independent web, take a fun photo like the N"urnberg animate GIF above, or like this recent one in San Francisco and post it on the wiki page for the event.

Remember to keep it fun as well as productive. Even if all you do is get together and finish writing a blog post and posting it on your indieweb site, that’s a good thing. Especially these days, the more people we can encourage to write authentic content and publish on their own sites,
Hey there, SUMO Nation!
It is with great joy that I present to you a guest post by one of the most involved people I’ve met in my (still relatively short) time at SUMO. Seburo has been a core contributor in the community from his first day on board, and I can only hope we get to enjoy his presence among us in the future. He is one of those people whose photo could be put under “Mozillian” in the encyclopedias of this world… But, let’s not dawdle and move on to his words…
This is the outline of a presentation given at the London All-Hands as part of a session where the SUMO contributors had the opportunity to talk about the work that they have been involved in.
Towards the end of 2015, I noticed that we were getting an increasing number of requests on the SUMO Support Forum questioning how users could put Firefox for Android (Fennec, the small fox of this tale) on their Amazon Kindle Fire tablet (the big river). At first it was just one or two questions, but the more I saw the more I realised that there were some key facts driving the questions:
- We know that users like using Firefox for Android on their mobile devices. It enables them to use Firefox as their user agent on the web when they are away from their laptop or desktop.
- We know that people like using Android, possibly the worlds most popular operating system. People recognise and take comfort from the little green Android logo when they see it alongside a device they wish to purchase and they appreciate the ease of use and depth of support at a lower price point than its competitors.
- With a little research, it became clear why people have the Kindle Fire tablet – the price point. In the UK at the time it was retailing for lb60, almost half the price of a comparative device from the big name brand leader.
What was confusing and confounding users was that having purchased a device at a great price, that uses an operating system they know, they could not find Firefox for Android in the Amazon app store. SUMO does not support such a configuration, but with the number of questions coming through, I realised that there must be something we could do.
I started helping some users side load Firefox for Android onto their devices and through answering questions I soon found myself using a fairly standard text that users found solved their problem. As I refined it, it made sense for this to be included within the SUMO Knowledge Base, the user facing guide to using Mozilla software. But before I could do this, there was one key issue for which I needed the help of the truly amazing Firefox Mobile team…which version of Firefox for Android to use.
Whilst Firefox and Firefox Beta are seen as the best product versions, I was advised they they would only get updates through Google Play – not ideal if the user in on the Amazon variant of Android. I was advised that Aurora was the version to use as it would get important security updates and pointed in the direction of the site where it could be downloaded from. In addition to this, the Firefox Mobile team helped shape some of the language I was going to use and helped check my draft article (I did say that they are amazing…!).
Whilst there is no change to our support of the Kindle platform (the article carries a “health warning” to that effect), I think of this work as a great example of how several different teams, both staff and contributors, can come together to help find a user focussed solution.
Thank you for sharing your story, Seburo. An inspiring tale of initiating on a positive change that affects many users and makes Firefox more available as a result.
Do you have a story you would like to share with us? Let us know in the comments!
https://blog.mozilla.org/sumo/2016/11/19/sumo-show-and-tell-a-small-fox-on-a-big-river/
I just got back from a children's sports club dinner where I hardly knew anyone and apparently I was seated with the other social leftovers. It turned out the woman next to me was very nice and we had a long conversation. She was excited to hear that I do computer science and software development, and mentioned that her daughter is starting university next year and strongly considering CS. I gave my standard pitch about why CS is a wonderful career path --- hope I didn't lay it on too thick. The daughter apparently is interested in computers and good at maths, and her teachers think she has a "logical mind", so that all sounded promising and I said so. But then the mother started talking about how that "logical mind" wasn't really a girly thing and asking whether the daughter might be better doing something softer like design. I pushed back and asked her not to make assumptions about what women and men might enjoy or be capable of, and mentioned a few of the women I've known who are extremely capable at hard-core CS. I pointed out that while CS isn't for everyone and I think people should try to find work they're passionate about, the demand and rewards are often greater for people in more technical roles.
This isn't the first time I've encountered mothers to a greater or lesser extent steering their daughters away from more technical roles. I've done a fair number of talks in high schools promoting CS careers, but at least for girls maybe targeting their parents somehow would also be worth doing.
I'll send this family some links to Playcanvas and other programming resources and hope that they, plus my sales pitch, will make a difference. One of the difficulties here is that you never know or find out whether what you did matters.
http://robert.ocallahan.org/2016/11/overcoming-stereotypes-one-parent-at.html
One of bugzilla.mozilla.org's (BMO) many features I love is needinfo. Rather than assigning a bug to someone to get more information (as one would do in JIRA,) one sets the needinfo flag on the person you need to ask. That way you don't have to unassign and reassign a bug, and you can have multiple needinfo requests in-flight (like when I ask platform engineers about who should be recommended reviewers in their components.)
Nathan Froyd found a great feature I had not known about in BMO. If you are needinfo'ed, but not the person with the answer, you can redirect the request so that it's transparent to the person asking.
I'm a little embarrassed that I didn't know this feature, but I'll be adding it to future BMO trainings I give.
ETA I'm looking at bug 1287461 and this may not be working as intended; investigating.
Red Hat is taking nominations for the Women in Open Source award, with USD 2,500 for the winner.
Nominations are due by the Friday after USA Thanksgiving (November 23rd,) so if you or people you know would benefit from the recognition of this award, consider nominating yourself or them.
The rules say the award is open to "an individual who identifies gender as female" so I don't know if they are inclusive of non-binary/genderqueer open source contributors. If you, dear reader, can clarify that, please do in the comments.
Firefox 52 landed in Developer Edition this week, so we have another update on WebExtensions for you. WebExtensions are becoming the standard for add-on development in Firefox.
API Parity
The sessions API was added to Firefox, with sessions.getRecentlyClosed and sessions.restore APIs. These allow you to query for recently closed tabs and windows and then restore them.
The topSites API was added to Firefox. This allows extensions to query the top sites visited by the browser.
The omnibox API was added to Firefox. Although in Firefox the omnibox is called the Awesome Bar, we’ve kept the naming the same so that extensions can easily port between Chrome and Firefox. The API allows extensions to register a unique keyword for providing their own suggestions to the Awesome Bar. The extension will be able to provide suggestions whenever its registered keyword is typed into the Awesome Bar.

Screenshot of an extension which registered the keyword ‘dxr’ for searching the Firefox source code.
The storage.sync API is now ready for testing, but not yet ready for full deployment. This API relies on a back-end service provided by Mozilla to sync add-on data between devices or re-installs. It is most commonly used to store add-on preferences that should be preserved.
Until the main production service is set up, you can test out storage.sync by making a few preference changes. To sync add-on data, a user will need to be logged into a Firefox Account. There is a limit of 100KB in the amount of data that can be stored. Before data is stored on our server, all data is encrypted in the client. By the time Firefox 52 goes into Beta we plan to have a production service ready to go. At that point we hope to remove the need to set preferences and switch users to the new servers.
Some existing APIs have also been improved. Some of the more significant bugs include:
- The addition of
browser.runtime.onInstalledandbrowser.runtime.onStartupwhich are commonly used to initialize data or provide the user with more information about the extension. - You can now match and attach content scripts to iframes with about:blank source, which are often used for inserting ads around the web.
- The manifest file now supports developer information and falls back to the author if appropriate.
- The commands API now supports
_execute_browser_action, which allows you to easily map a command to synthesize a click on your browser action. - Bookmark events have been implemented, providing the
onRemoved,onMoved,onCreatedandonChangedevents.
New APIs
Recently, contextual identities were added to Firefox, and these are now exposed to WebExtensions as well, in the tabs and cookie APIs. As an example, the following will query every tab in the current window and then open up a new tab at the same URL with the same contextual identity:
let tabs = browser.tabs.query({currentWindow: There is a lot of activity in the neural network hardware space. Intel just bought Nervana for $400m and Movidius for an undisclosed amount. Both make dedicated silicon to run and train neural networks. Most other chipset vendors I have talked to are similarly interested in adding direct support for neural networks to future chips. I think there is some risk in this approach. Here is why.
Most of the time executing a neural network is spent in massive matrix operations such as convolution and matrix multiplication. The state of the art is to use GPUs to do these operations because GPUs have a lot of ALUs and are well optimized for massively data parallel tasks. If you spent time optimizing neural networks for GPUs (we do!), you probably know that a well optimized engine achieves about 40-90% efficiency (ALU utilization). Dedicated neural network silicon aims to raise that to 100%, which is great, but in the end a 2x speedup only.
The problematic part is that chipset changes have a long lead time (2-3 years), and you have to commit today to the architectures of tomorrow. And thats where things get tricky. A paper published earlier this year showed that neural networks can be binarized, which reduces the precision of weights to 1 bit (-1, 1). Slow and energy inefficient floating point math turns into very efficient binary math (XNOR), which speeds up the network on existing commodity silicon by 400% with a very small loss in precision. Commodity GPUs support this because they are relatively general purpose computers. Dedicated neural network silicon is much more likely designed for a specific compute mode.
In the last 12 months or so alone we have seen dramatic advances in our understanding how to train and evaluate neural networks. Binarization is just one of them, and its fair to expect that over the next 2-3 years similarly impactful advances will be published. Committing to hardware designs based on today’s understanding of neural networks is ill advised in my opinion. My recommendation to chipset vendors is to beef up their GPUs and DSPs, and support a wide range of fixed point and floating point resolutions in a fairly generic manner. Its more likely that that will cover what we’ll want from silicon over the next 2-3 years.
Filed under: Silk Labs
[показать] [показать] [показать] [показать] [показать] [показать] [показать] https://andreasgal.com/2016/11/18/ai-silicon-vs-ai-software/