FSFE has been running the Public Money Public Code (PMPC) campaign for some time now, requesting that software produced with public money be licensed for public use under a free software license. You can request a free box of stickers and posters here (donation optional).
Many non-profits and charitable organizations receive public money directly from public grants and indirectly from the tax deductions given to their supporters. If the PMPC argument is valid for other forms of government expenditure, should it also apply to the expenditures of these organizations too?
Where do we start?
A good place to start could be FSFE itself. Donations to FSFE are tax deductible in Germany, the Netherlands and Switzerland. Therefore, the organization is partially supported by public money.
![]()
Personally, I feel that for an organization like FSFE to be true to its principles and its affiliation with the FSF, it should be run without any non-free software or cloud services.
However, in my role as one of FSFE's fellowship representatives, I proposed a compromise: rather than my preferred option, an immediate and outright ban on non-free software in FSFE, I simply asked the organization to keep a register of dependencies on non-free software and services, by way of a motion at the 2017 general assembly:
The GA recognizes the wide range of opinions in the discussion about non-free software and services. As a first step to resolve this, FSFE will maintain a public inventory on the wiki listing the non-free software and services in use, including details of which people/teams are using them, the extent to which FSFE depends on them, a list of any perceived obstacles within FSFE for replacing/abolishing each of them, and for each of them a link to a community-maintained page or discussion with more details and alternatives. FSFE also asks the community for ideas about how to be more pro-active in spotting any other non-free software or services creeping into our organization in future, such as a bounty program or browser plugins that volunteers and staff can use to monitor their own exposure.
Unfortunately, it failed to receive enough votes (minutes: item 24, votes: 0 for, 21 against, 2 abstentions)
In a blog post on the topic of using proprietary software to promote freedom, FSFE's Executive Director Jonas "Oberg used the metaphor of taking a journey. Isn't a journey more likely to succeed if you know your starting point? Wouldn't it be even better having a map that shows which roads are a dead end?
In any IT project, it is vital to understand your starting point before changes can be made. A register like this would also serve as a good model for other organizations hoping to secure their own freedoms.
For a community organization like FSFE, there is significant goodwill from volunteers and other free software communities. A register of exposure to proprietary software would allow FSFE to crowdsource solutions from the community.
Back in 2018
I'll be proposing the same motion again for the 2018 general assembly meeting in October.
If you can see something wrong with the text of the motion, please help me improve it so it may be more likely to be accepted.
Offering a reward for best practice
I've observed several discussions recently where people have questioned the impact of FSFE's campaigns. How can we measure whether the campaigns are having an impact?
One idea may be to offer an annual award for other non-profit organizations, outside the IT domain, who demonstrate exemplary use of free software in their own organization. An award could also be offered for some of the individuals who have championed free software solutions in the non-profit sector.
An award program like this would help to showcase best practice and provide proof that organizations can run successfully using free software. Seeing compelling examples of success makes it easier for other organizations to believe freedom is not just a pipe dream.
Therefore, I hope to propose an additional motion at the FSFE general assembly this year, calling for an award program to commence in 2019 as a new phase
The recent New York Times report alleging expansive data sharing between Facebook and device makers shows that Facebook has a lot of work to do to come clean with its users and to provide transparency into who has their data. We raised these transparency issues with Facebook in March and those concerns drove our decision to pause our advertising on the platform. Despite congressional testimony and major PR campaigns to the contrary, Facebook apparently has yet to fundamentally address these issues.
In its response, Facebook has argued that device partnerships are somehow special and that the company has strong contracts in place to prevent abuse. While those contracts are important, they don’t remove the need to be transparent with users and to give them control. Suggesting otherwise, as Facebook has done here, indicates the company still has a lot to learn.
The post Facebook Must Do Better appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2018/06/05/facebook-must-do-better/
Exactly 15 years ago at “2003-06-05 09:51:47 PDT” my journey in Bugzilla started. At that time when I created my account I would never have imagined where all these endless hours of community work ended-up. And even now I cannot predict how it will look like in another 15 years…
Here some stats from my activities on Bugzilla:
| Bugs filed | 4690 | |
|---|---|---|
| Comments made | 63947 | |
| Assigned to | 1787 | |
| Commented on | 18579 | |
| QA-Contact | 2767 | |
| Patches submitted | 2629 | |
| Patches reviewed | 3652 |
https://www.hskupin.info/2018/06/05/my-15th-bugzilla-account-anniversary/
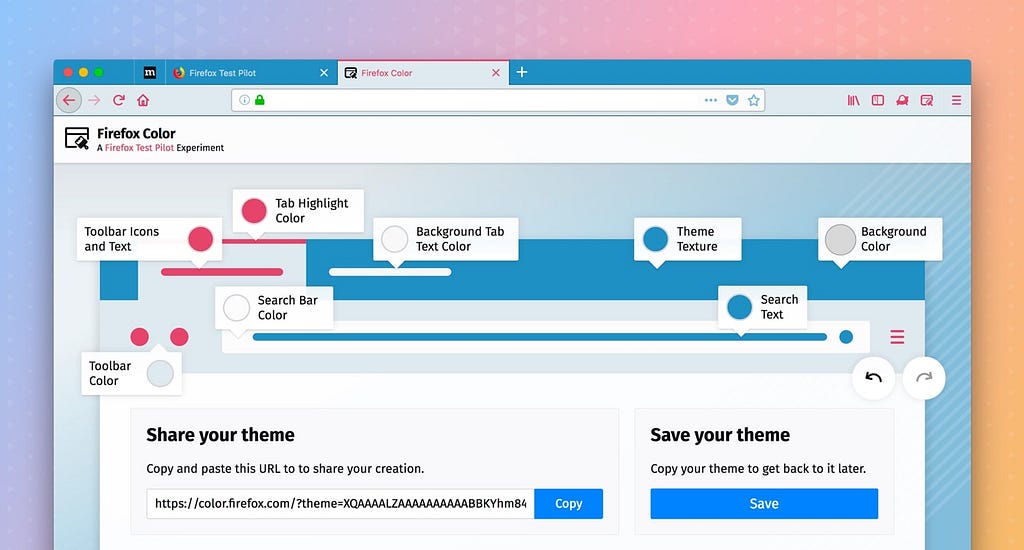
We’re excited to launch two new Test Pilot experiments that add power and style to Firefox.
https://medium.com/media/32dc65c89184767b96c26896efb78323/hrefSide View enables you to multitask with Firefox like never before by letting you keep two websites open side by side in the same window.
https://medium.com/media/66965c47993ec6ef8783ef525951c67d/hrefFirefox Color makes it easy to customize the look and feel of your Firefox browser. With just a few clicks you can create beautiful Firefox themes all your own.
Both experiments are available today from Firefox Test Pilot. Try them out, and don’t forget to give us feedback. You’re helping to shape the future of Firefox!
Introducing Firefox Color and Side View was originally published in Firefox Test Pilot on Medium, where people are continuing the conversation by highlighting and responding to this story.
Remember when you were a kid and wanted to paint your room your favorite color? Or the first time you dyed your hair a different color and couldn’t wait to … Read more
The post Get All the Color, New Firefox Extension Announced appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/get-all-the-color-new-firefox-extension-announced/
Introducing Side View! Side View is a Firefox extension that allows you to view two different browser tabs simultaneously in the same tab, within the same browser window. Firefox Extensions … Read more
The post It’s A New Firefox Multi-tasking Extension: Side View appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/its-a-new-firefox-multi-tasking-extension-side-view/
Before we bring new features to Firefox, we give them a test run to make sure they’re right for our users. To help determine which features we add and how exactly they should work, we created the Test Pilot program.
Since the launch of Test Pilot, we have experimented with 16 different features, and three have graduated to live in Firefox full time: Activity Stream, Containers and Screenshots. Recently, Screenshots surpassed more than 100M+ screenshots since it launched. Thanks to active Firefox users who opt to take part in Test Pilot experiments.
This week, the Test Pilot team is continuing to evolve Firefox features with two new extensions that will offer users a more customizable and productive browsing experience.
Introducing Firefox Color
One of the greatest things about the Test Pilot program is being the first to try new things. Check out this video from one of our favorite extensions we’re hoping you’ll try out:
New Firefox Color extension allows you to customize several different elements of your browser, including background texture, text, icons, the toolbar and highlights.
Color changes update automatically to the browser as you go, so you can mix and match until you find the perfect combo to suit you. Whether you like to update with the seasons, or rep your favorite sports team during playoffs, the new color extension makes it simple to customize your Firefox experience to match anything from your mood or your wardrobe.
You can also save and share your creation with others, or choose from a variety of pre-installed themes.
Introducing Side View
Side View is a great tool for comparison shopping, allowing you to easily scope the best deals on flights or home appliances, and eliminating the need to switch between two separate web pages. It also allows you to easily compare news stories or informational material–perfect for writing a research paper or conducting side-by-side revisions of documents all in one window.
The Side View extension allows you to view two different browser tabs in the same tab, within the same browser window.
You can also opt for Side View to log your recent comparisons, so you can easily access frequently viewed pages.
Join our Test Pilot Program
The Test Pilot program is open to all Firefox users. Your feedback helps us test and evaluate a variety of potential Firefox features. We have more than 100k daily participants, and if you’re interested in helping us build the future of Firefox, visit testpilot.firefox.com to learn more. We’ve made it easy for anyone around the world to join with experiments available in 48 languages.
If you’re familiar with Test Pilot then you know all our projects are experimental, so we’ve made it easy to give us feedback or disable features at any time from testpilot.firefox.com.
Check out the new Color and Side View extensions. We’d love to hear your feedback!
The post Latest Firefox Test Pilot Experiments: Custom Color and Side View appeared first on The Mozilla Blog.
I became a manager of a fantastic team in February. My standard response to a new role is to read many books and talk to a lot of people who are have experience is this area so I have the background to be successful. Nothing can prepare you like doing the actual day to day work of being a manager, but these are some concepts I found helpful from my favourite books on this topic:

- Accelerate: Building and Scaling High Performing Technology Operations by Nicole Forsgren, PhD, Jez Humble and Gene Kim. The main topic of this book is not leadership, but many of the chapters deal with how lead effective teams.
- Lean management practices entail:
- Limiting work in process (WIP) and using these limits to drive process improvement and increase throughput
- Creating and maintain visual displays showing key productivity metrics and the current status of work that are available to both engineers and managers
- Use data from application performance and infrastructure monitoring to make business decisions on a daily basis
- Definition of burnout:
- Lean management practices entail:

- Complex and painful deployment strategies that must be performed out of business hours lead to stress and lack of control, which can increase burnout
- Tips to improve culture and support your teams
- Build trust with counterparts on other teams
- Encourage people to move between departments
- Actively seek, encourage and reward work that facilitates collaboration
- Create a training budget and advocating using it
- Ensure your team has the resources and space to engage in informal learning and explore new ideas
- Make it safe to fail. Many projects fail. Learning from them and holding blameless post-mortems allows people to understand that failure is okay and allows them to feel safe to take risks
- Share information with others
- lighting talks, lunch and learns and demo days allow teams to share their work and celebrate what they have accomplished
- Allow teams to choose their tools
- Make monitoring a priority
- Radical Focus by Christina Wodtke is a book about OKRs and written in a similar fable format to the The Phoenix project is written about DevOps. It’s the story of a struggling startup and how they had to focus on priorities.

- If you were hired as a new CEO, what would you do? Is this a different direction than the current strategy the company is pursuing?
- How to specify OKRs with measurable results
- “You don’t need people to work more, you need people to work on the right things” Look at the work you are doing every week and see how it will impact reaching OKRs.
- OKR fundamentals
- The sentence that describes the Objective should be
- Able to inspire a sense of meaning and purpose. Use the language of your team to write the objective
- Bound by time – able to be completed in a set amount of time, like a month or a quarter
- Accountable by the team independently. Completing it shouldn’t be blocked by the work of another team.
- The sentence that describes the Objective should be
- The Key results answer the question – “How do we know we met our results?”
- Measurable – You can measure opposing forces like growth and performance or revenue and qualify. For instance, a growth metric doesn’t matter if you customers don’t continue to use the product after using it once
- Be the Best Boss Everyone Wants to Work for by William Gentry.

I read this book as part of the management book club we have at Mozilla where we discuss a chapter of a book on management every two weeks.
- The overarching theme of this book is to “flip your mindset”. As an individual contributor, your role was to do your individual work to the best of your abilities.
- As a manager, it’s not about you, it’s about your team. Your role is to make your team the more effective it can be, and help the individual
This research was conducted in partnership with the UCOSP (Undergraduate Capstone Open Source Projects) initiative. UCOSP facilitates open source software development by connecting Canadian undergraduate students with industry mentors to practice distributed development and data projects.
The team consisted of the following Mozilla staff: Martin Lopatka, David Zeber, Sarah Bird, Luke Crouch, Jason Thomas
2017 student interns — crawler implementation and data collection: Ruizhi You, Louis Belleville, Calvin Luo, Zejun (Thomas) Yu
2018 student interns — exploratory data analysis projects: Vivian Jin, Tyler Rubenuik, Kyle Kung, Alex McCallum
As champions of a healthy Internet, we at Mozilla have been increasingly concerned about the current advertisement-centric web content ecosystem. Web-based ad technologies continue to evolve increasingly sophisticated programmatic models for targeting individuals based on their demographic characteristics and interests. The financial underpinnings of the current system incentivise optimizing on engagement above all else. This, in turn, has evolved an insatiable appetite for data among advertisers aggressively iterating on models to drive human clicks.
Most of the content, products, and services we use online, whether provided by media organisations or by technology companies, are funded in whole or in part by advertising and various forms of marketing.
–Timothy Libert and Rasmus Kleis Nielsen [link]
We’ve talked about the potentially adverse effects on the Web’s morphology and how content silos can impede a diversity of viewpoints. Now, the Mozilla Systems Research Group is raising a call to action. Help us search for patterns that describe, expose, and illuminate the complex interactions between people and pages!
Inspired by the Web Census recently published by Steven Englehardt and Arvind Narayanan of Princeton University, we adapted the OpenWPM crawler framework to perform a comparable crawl gathering a rich set of information about the JavaScript execution on various websites. This enables us to delve into further analysis of web tracking, as well as a general exploration of client-page interactions and a survey of different APIs employed on the modern Web.
In short, we set out to explore the unseen or otherwise not obvious series of JavaScript execution events that are triggered once a user visits a webpage, and all the first- and third-party events that are set in motion when people retrieve content. To help enable more exploration and analysis, we are providing our full set of data about JavaScript executions open source.
The following sections will introduce the data set, how it was collected and the decisions made along the way. We’ll share examples of insights we’ve discovered and we’ll provide information on how to participate in the associated “Overscripted Web: A Mozilla Data Analysis Challenge”, which we’ve
Help us explore the unseen JavaScript and what this means for the Web

What happens while you are browsing the Web? Mozilla wants to invite data and computer scientists, students and interested communities to join the “Overscripted Web: a Data Analysis Challenge”, and help explore JavaScript running in browsers and what this means for users. We gathered a rich dataset and we are looking for exciting new observations, patterns and research findings that help to better understand the Web. We want to bring the winners to speak at MozFest, our annual festival for the open Internet held in London.
The Dataset
Two cohorts of Canadian Undergraduate interns worked on data collection and subsequent analysis. The Mozilla Systems Research Group is now open sourcing a dataset of publicly available information that was collected by a Web crawl in November 2017. This dataset is currently being used to help inform product teams at Mozilla. The primary analysis from the students focused on:
- Session replay analysis: when do websites replay your behavior in the site
- Eval and dynamically created function calls
- Cryptojacking: websites using user’s computers to mine cryptocurrencies are mainly video streaming sites
Take a look on Mozilla’s Hacks blog for a longer description of the analysis.
The Data Analysis Challenge
We see great potential in this dataset and believe that our analysis has only scratched the surface of the insights it can offer. We want to empower the community to use this data to better understand what is happening on the Web today, which is why Mozilla’s Systems Research Group and Open Innovation team partnered together to launch this challenge.
We have looked at how other organizations enable and speed up scientific discoveries through collaboratively analyzing large datasets. We’d love to follow this exploratory path: We want to encourage the crowd to think outside the proverbial box, get creative, get under the surface. We hope participants get excited to dig into the JavaScript executions data and come up with new observations, patterns, research findings.
To guide thinking, we’re dividing the Challenge into three categories:
- Tracking and Privacy
- Web Technologies and the Shape of the Modern Web
- Equality, Neutrality, and Law
You will find all of the necessary information to join on the Challenge website. The submissions will close on August 31st and the winners will be announced on September 14th. We will bring the winners of the best three analyses (one per category) to MozFest, the world’s leading festival for the open internet movement, taking place in London from October 26th to the 28th 2018. We will cover their airfare, hotel, admission/registration, and if necessary visa fees in accordance to the official rules. We may also invite the winners to do 15-minute presentations of their findings.
We are looking forward to the diverse and innovative approaches from the data science community and we want to specifically encourage young data scientists and students to take a stab at this dataset. It could be the basis for your final university project and analyzing it can grow your data science skills and build your resum'e (and GitHub profile!). The Web gets more complex by the minute, keeping it safe and open can only happen if we work together. Join us!
What is Apple trying to say with macOS Mojave? That it's dusty, dry, substantially devoid of life in many areas, and prone to severe temperature extremes? Oh, it has dark mode. Ohhh, okay. That totally makes up for everything and all the bugs and all the recurrent lack of technical investment. It's like the anti-shiny.
In other news, besides the 32-bit apocalypse, they just deprecated OpenGL and OpenCL in order to make way for all the Metal apps that people have just been lining up to write. Not that this is any surprise, mind you, given how long Apple's implementation of OpenGL has rotted on the vine. It's a good thing they're talking about allowing iOS apps to run, because there may not be any legacy Mac apps compatible when macOS 10.15 "Zzyzx" rolls around.
Yes, looking forward to that Linux ARM laptop when the MacBook Air "Sierra Forever" wears out. I remember when I was excited about Apple's new stuff. Now it's just wondering what they're going to break next.
http://tenfourfox.blogspot.com/2018/06/just-call-it-macos-death-valley-and-get.html
I recently wrote about some work I’ve done to speed up the Rust compiler. Since then I’ve done some more.
rustc-perf improvements
Since my last post, rustc-perf — the benchmark suite, harness and visualizer — has seen some improvements. First, some new benchmarks were added: cargo, ripgrep, sentry-cli, and webrender. Also, the parser benchmark has been removed because it was a toy program and thus not a good benchmark.
Second, I added support for several new profilers: Callgrind, Massif, rustc’s own -Ztime-passes, and the use of ad hoc eprintln! statements added to rustc. (This latter case is more useful than it might sound; in combination with post-processing it can be very helpful, as we will see below.)
Finally, the graphs shown on the website now have better y-axis scaling, which makes many of them easier to read. Also, there is a new dashboard view that shows performance across rustc releases.
Failures and incompletes
After my last post, multiple people said they would be interested to hear about optimization attempts of mine that failed. So here is an incomplete selection. I suggest that rustc experts read through these, because there is a chance they will be able to identify alternative approaches that I have overlooked.
nearest_common_ancestors 1: I managed to speed up this hot function in a couple of ways, but a third attempt failed. The representation of the scope tree is not done via a typical tree data structure; instead there is a HashMap of child/parent pairs. This means that moving from a child to its parent node requires a HashMap lookup, which is expensive. I spent some time designing and implementing an alternative data structure that stored nodes in a vector and the child-to-parent links were represented as indices to other elements in the vector. This meant that child-to-parent moves only required stepping through the vector. It worked, but the speed-up turned out to be very small, and the new code was significantly more complicated, so I abandoned it.
nearest_common_ancestors 2: A different part of the same function involves storing seen nodes in a vector. Searching this unsorted vector is O(n), so I tried instead keeping it in sorted order and using binary search, which gives O(log n) search. However, this change meant that node insertion changed from amortized O(1) to O(n) — instead of a simple push onto the end of the vector, insertion could be at any point, which which required shifting all subsequent elements along. Overall this change made things slightly worse.
PredicateObligation SmallVec: There is a type Vec that is instantiated frequently, and the vectors often have few elements. I tried using a SmallVec instead, which avoids the heap allocations when the number of elements is below a threshold. (A trick I’ve used multiple times.) But this made things significantly slower! It turns out that these Vecs are copied around quite a bit, and a SmallVec is larger than a Vec because the elements are inline. Furthermore PredicationObligation is a large type, over 100 bytes. So what happened was that memcpy calls were inserted to copy these SmallVecs around. The slowdown from the extra function calls and memory traffic easily outweighed the speedup from avoiding the Vec heap allocations.
SipHasher128: Incremental compilation does a lot of hashing of data structures in order to determine what has changed from previous compilation runs. As a result, the hash function used for this is extremely hot. I tried various things to speed up the hash function, including LEB128-encoding of usize inputs (a trick that worked in the past) but I failed to speed it up.
LEB128 encoding: Speaking of LEB128 encoding, it is used a lot when writing metadata to file. I tried optimizing the LEB128 functions by special-casing the common case where the value is less than 128 and so can be encoded in a single byte. It worked, but gave a negligible improvement, so I decided it wasn’t worth the extra complication.
Token shrinking: A previous PR shrunk the Token type from 32 to 24 bytes, giving a small win. I tried also replacing the Option in Literal with just ast::Name and using an
The Rust team is happy to announce a new version of Rust, 1.26.2. Rust is a systems programming language focused on safety, speed, and concurrency.
If you have a previous version of Rust installed via rustup, getting Rust 1.26.2 is as easy as:
$ rustup update stable
If you don’t have it already, you can get rustup from the
appropriate page on our website, and check out the detailed release notes for
1.26.2 on GitHub.
What’s in 1.26.2 stable
This patch release fixes a bug in the borrow checker verification of match expressions. This bug
was introduced in 1.26.0 with the stabilization of match ergonomics. Specifically, it permitted
code which took two mutable borrows of the bar path at the same time.
let mut foo = Some("foo".to_string());
let bar = &mut foo;
match bar {
Some(baz) => {
bar.take(); // Should not be permitted, as baz has a unique reference to the bar pointer.
},
None => unreachable!(),
}
1.26.2 will reject the above code with this error message:
error[E0499]: cannot borrow `*bar` as mutable more than once at a time
--> src/main.rs:6:9
|
5 | Some(baz) => {
| --- first mutable borrow occurs here
6 | bar.take(); // Should not be permitted, as baz has a ...
| ^^^ second mutable borrow occurs here
...
9 | }
| - first borrow ends here
error: aborting due to previous error
The Core team decided to issue a point release to minimize the window of time in which this bug in the Rust compiler was present in stable compilers.
Easlier this year I had to split a Koa/SPA app into two separate apps. As part of that I switched from webpack to Neutrino.
Through this work I learned a lot about full stack development (frontend, backend and deployments for both). I could write a blog post per item, however, listing it all in here is better than never getting to write a post for any of them.
Note, I’m pointing to commits that I believe have enough information to understand what I learned.
Npm packages to the rescue:
Node/backend notes:
- How to better configure HMR
- Make HMR work by closing the previous server
- Add source-map-support to help development
- Start project on debugging mode (use --inspect rather than inspect)
- How to properly start Neutrino in production
Neutrino has been a great ally to me and here’s some knowledge on how to use it:
- Add PostCss support
- Specify custom env variables to be passed down into the app
- Add a favicon.ico to your app
- Configure Travis to use --inspect with Neutrino after any failures
- Include a custom font to your SPA
- How to properly call Neutrino with Istanbul
Heroku was my tool for deployment and here you have some specific notes:
- Add a postbuild script for Heroku as well as adding a static.json to configure how to server the frontend code
- Tell the server to send all routes from the root (since we use dynamic routing via React-router)
- Same change but for Netlify
- Changes to enable Heroku review apps and configue for SPAs
Mozilla’s latest awards will support people and projects that examine the effects of AI on society
At Mozilla, one way we support a healthy internet is by fueling the people and projects on the front lines — from grants for community technologists in Detroit, to fellowships for online privacy activists in Rio.
Today, we are opening applications for a new round of Mozilla awards. We’re awarding $225,000 to technologists and media makers who help the public understand how threats to a healthy internet affect their everyday lives.
Specifically, we’re seeking projects that explore artificial intelligence and machine learning. In a world where biased algorithms, skewed data sets, and broken recommendation engines can radicalize YouTube users, promote racism, and spread fake news, it’s more important than ever to support artwork and advocacy work that educates and engages internet users.
These awards are part of the NetGain Partnership, a collaboration between Mozilla, Ford Foundation, Knight Foundation, MacArthur Foundation, and the Open Society Foundation. The goal of this philanthropic collaboration is to advance the public interest in the digital age.
What we’re seeking
We’re seeking projects that are accessible to broad audiences and native to the internet, from videos and games to browser extensions and data visualizations.
We will consider projects that are at either the conceptual or prototype phases. All projects must be freely available online and suitable for a non-expert audience. Projects must also respect users’ privacy.
In the past, Mozilla has supported creative media projects like:
Data Selfie, an open-source browser add-on that simulates how Facebook interprets users’ data.
Chupadados, a mix of art and journalism that examines how women and non-binary individuals are tracked and surveilled online.
Paperstorm, a web-based advocacy game that lets users drop digital leaflets on cities — and, in the process, tweet messages to lawmakers.
Codemoji, a tool for encoding messages with emoji and teaching the basics of encryption.
*Privacy Not Included, a holiday shopping guide that assesses the latest gadgets’ privacy and security features.
Details and how to apply
Mozilla is awarding a total of $225,000, with individual awards ranging up to $50,000. Final award amounts are at the discretion of award reviewers and Mozilla staff, but it is currently anticipated that the following awards will be made:
Two $50,000 total prize packages ($47,500 award + $2,500 MozFest travel stipend)
Five $25,000 total prize packages ($22,500 award + $2,500 MozFest travel stipend)
Awardees are selected based on quantitative scoring of their applications by a review committee and a qualitative discussion at a review committee meeting. Committee members include Mozilla staff, current and alumni Mozilla Fellows, and — as available — outside experts. Selection criteria are designed to evaluate the merits of the proposed approach. Diversity in applicant background, past work, and medium are also considered.
Mozilla will accept applications through August 1, 2018, and notify winners by September 15, 2018. Winners will be publicly announced on or around MozFest, which is held October 26-28, 2018.
After the excitement of OSCAL in Tirana, I travelled up to Prishtina, Kosovo, with some of Debian's new GSoC students. We don't always have so many students participating in the same location. Being able to meet with all of them for a coffee each morning gave some interesting insights into the challenges people face in these projects and things that communities can do to help new contributors.
On the evening of 23 May, I attended a meeting at the Prishtina hackerspace where a wide range of topics, including future events, were discussed. There are many people who would like to repeat the successful Mini DebConf and Fedora Women's Day events from 2017. A wiki page has been created for planning but no date has been confirmed yet.
On the following evening, 24 May, we had a joint meeting with SHRAK, the ham radio society of Kosovo, at the hackerspace. Acting director Vjollca Caka gave an introduction to the state of ham radio in the country and then we set up a joint demonstration using the equipment I brought for OSCAL.

On my final night in Prishtina, we had a small gathering for dinner: Debian's three GSoC students, Elena, Enkelena and Diellza, Renata Gegaj, who completed Outreachy with the GNOME community and Qendresa Hoti, one of the organizers of last year's very successful hackathon for women in Prizren.
Promoting free software at Doku:tech, Prishtina, 9-10 June 2018
One of the largest technology events in Kosovo, Doku:tech, will take place on 9-10 June. It is not too late for people from other free software communities to get involved, please contact the FLOSSK or Open Labs communities in the region if you have questions about how you can participate. A number of budget airlines, including WizzAir and Easyjet, now have regular flights to Kosovo and many larger free software organizations will consider requests for a travel grant.
https://danielpocock.com/free-software-ham-radio-gsoc-in-kosovo-2018-05

Your eyes do not deceive you -- this is QEMU running Tiger with full virtualization on the Talos II. For proof, look at my QEMU command line in the Terminal window. I've just turned my POWER9 into a G4.
Recall last entry that there was a problem using virtualization to run Power Mac operating systems on the T2 because the necessary KVM module, KVM-PR, doesn't load on bare-metal POWER9 systems (the T2 is PowerNV, so it's bare-metal). That means you'd have to run your Mac operating systems under pure emulation, which eked out something equivalent to a 1GHz G4 in System Profiler but was still a drag. With some minimal tweaks to KVM-PR, I was able to coax Tiger to start up under virtualization, increasing the apparent CPU speed to over 2GHz. Hardly a Quad G5, but that's the fastest Power Mac G4 you'll ever see with the fastest front-side bus on a G4 you'll ever see. Ever. Maximum effort.
The issue on POWER9 is actually a little more complex than I described it (thanks to Paul Mackerras at IBM OzLabs for pointing me in the right direction), so let me give you a little background first. To turn a virtual address into an actual real address, PowerPC and POWER processors prior to POWER9 exclusively used a hash table of page table entries (PTEs or HPTEs, depending on who's writing) to find the correct location in memory. The process in a simplified fashion is thus: given a virtual address, the processor translates it into a key for that block of memory using the segment lookaside buffer (SLB), and then hashes that key and part of the address to narrow it down to two page table entry groups (PTEGs), each containing eight PTEs. The processor then checks those 16 entries for a match. If it's there, it continues, or else it sends a page fault to the operating system to map the memory.
The first problem is that the format of HPTEs changed slightly in POWER9, so this needs to be accommodated if the host CPU does lookups of its own (it does in KVM-HV, but this was already converted for the new POWER9 and thus works already).
The bigger problem, though, is that hash tables can be complex to manage and in the worst case could require a lot of searches to map a page. POWER8 and earlier reduce this cost with the translation lookaside buffer (TLB), used to cache a PTE once it's found. However, the POWER9 has another option called the radix MMU. In this scheme (read the patent if you're bored), the SLB entry for that block of memory now has a radix page table pointer, or RPTP. The RPTP in turn points to a chain of hierarchical translation tables ("radix tree") that through a series of cascading lookups build the real address for that page of RAM. This is fast and flexible, and particularly well-suited to discontinuous tracts of addressing space. However, as an implementational detail, a guest operating system running in user mode (i.e., KVM-PR) on a radix host has limitations on so-called quadrant 3 (memory in the 0xc... range). This isn't a problem for a VM that can execute supervisor instructions (i.e., KVM-HV) because it can just remap as necessary, but KVM-HV can't emulate a G3 or G4 on a POWER9; only KVM-PR can do that.
Fortunately, the POWER9 still can support the HPT and turn the radix MMU off by booting the kernel with disable_radix. That gets around the second problem. As it turns out, the first problem actually isn't a problem for booting OS X on KVM once radix mode is off, assuming you hack the KVM-PR kernel module to handle a couple extra interrupt types and remove the lockout on POWER9. And here we are.(*)
Anyway, you lot will be wanting the Geekbench numbers, won't you? Such a competitive bunch, always demanding to know the score. Let's set two baselines. First, my trusty backup workstation, the 1GHz iMac G4: It's not very fast and it has no L3 cache, which makes it worse, but the arm is great, the form-factor has never been equaled, I love the screen and it fits very well on a desk. That gets a fairly weak 580 Geekbench (Geekbench 2.2 on 10.4, integer 693, floating point 581, memory 500, stream 347). For the second baseline, I'll use my trusty Quad G5, but I left it in Reduced power mode since
DNS over HTTPS (DOH) is a feature where a client shortcuts the standard native resolver and instead asks a dedicated DOH server to resolve names.
Compared to regular unprotected DNS lookups done over UDP or TCP, DOH increases privacy, security and sometimes even performance. It also makes it easy to use a name server of your choice for a particular application instead of the one configured globally (often by someone else) for your entire system.
DNS over HTTPS is quite simply the same regular DNS packets (RFC 1035 style) normally sent in clear-text over UDP or TCP but instead sent with HTTPS requests. Your typical DNS server provider (like your ISP) might not support this yet.
To get the finer details of this concept, check out Lin Clark's awesome cartoon explanation of DNS and DOH.
This new Firefox feature is planned to get ready and ship in Firefox release 62 (early September 2018). You can test it already now in Firefox Nightly by setting preferences manually as described below.
This article will explain some of the tweaks, inner details and the finer workings of the Firefox TRR implementation (TRR == Trusted Recursive Resolver) that speaks DOH.
Preferences
All preferences (go to "about:config") for this functionality are located under the "network.trr" prefix.
network.trr.mode - set which resolver mode you want.
0 - Off (default). use standard native resolving only (don't use TRR at all)
1 - Race native against TRR. Do them both in parallel and go with the one that returns a result first.
2 - TRR first. Use TRR first, and only if the name resolve fails use the native resolver as a fallback.
3 - TRR only. Only use TRR. Never use the native (after the initial setup).
4 - Shadow mode. Runs the TRR resolves in parallel with the native for timing and measurements but uses only the native resolver results.
5 - Explicitly off. Also off, but selected off by choice and not default.
network.trr.uri - (default: none) set the URI for your DOH server. That's the URL Firefox will issue its HTTP request to. It must be a HTTPS URL (non-HTTPS URIs will simply be ignored). If "useGET" is enabled, Firefox will append "?ct&dns=...." to the URI when it makes its HTTP requests. For the default POST requests, they will be issued to exactly the specified URI.
"mode" and "uri" are the only two prefs required to set to activate TRR. The rest of them listed below are for tweaking behavior.
We list some publicly known DOH servers here. If you prefer to, it is easy to setup and run your own.
network.trr.credentials - (default: none) set credentials that will be used in the HTTP requests to the DOH end-point. It is the right side content, the value, sent in the Authorization: request header. Handy if you for example want to run your own public server and yet limit who can use it.
network.trr.wait-for-portal - (default: true) this boolean tells Firefox to first wait for the captive portal detection to signal "okay" before TRR is used.
network.trr.allow-rfc1918 - (default: false) set this to true to allow RFC 1918 private addresses in TRR responses. When set false, any such response will be considered a wrong response that won't be used.
network.trr.useGET - (default: false) When the browser issues a request to the DOH server to resolve host names, it can do that using POST or GET. By default Firefox will use POST, but by toggling this you can enforce GET to be used instead. The DOH spec says a server MUST support both methods.
network.trr.confirmationNS - (default: example.com) At startup, Firefox will first check an NS entry to verify that TRR works, before it gets enabled for real
ccache, the compiler cache, is a fantastic way to speed up build times for C and C++ code that I previously recommended. Recently, I was playing around with trying to get it to speed up my Linux kernel builds, but wasn’t seeing any benefit. Usually when this happens with ccache, there’s something non-deterministic about the builds that prevents cache hits.
Turns out someone asked this exact question on the ccache mailing list back in 2014, and a teammate from my Android days supposed a timestamp was the culprit. That, and this LKML post from the KBUILD maintainer in 2011 about determinism helped me find commit 87c94bfb8ad35 (“kbuild: override build timestamp & version”) that introduced manually overriding part of the version string that contains the build timestamp that can be seen from:
1 2 3 4 5 | |
With ccache, we can check the cache hit/miss stats with -s, clear the cache
with -C, and clear the stats with -z. We can tell ccache explicitly which
compiler to fall back to as its first argument (not strictly necessary). For
KBUILD, we can swap our compiler by using CC= arg.
Let’s see what happens to our build time for subsequent builds with a hot cache:
No Cache
1 2 3 4 | |
Cold Cache
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | |
A secret project has been brewing for JSConf EU, and this weekend is the big reveal…
The Arch is a larger-than-life experience that uses 30,000 colored LEDs to create a canvas for light animations.
And you can take charge of this space. Using modules, you can create a light animation.
But even though this is JSConf, these animations aren’t just powered by JavaScript modules. In fact, we hope you will try something new… Rust + WebAssembly.

Why this project?
One of the hardest problems when you’re learning a new programming language is finding a project that can teach you the basics, but that’s still fun enough to keep you learning more. And “Hello World” is only fun your first few times… it has no real world impact.
But what if your Hello World could have an impact on the real world? What if it could control a structure like this one?
So let’s get started on baby’s first Rust to WebAssembly module.

And in a way, this the perfect project for your first WebAssembly project… but not because this is the kind of project that you’d use WebAssembly for.
People usually use WebAssembly because they want to supercharge their application and make it run faster. Or because they want to use the same code across both the web and different devices, with their different operating systems.
This project doesn’t do either of those.

The reason this is a good project for getting started with WebAssembly is not because this is what you would use WebAssembly for.
Instead, it’s useful because it gives you a mental model of how JavaScript and WebAssembly work together. So let’s look at what we need to do to take control of this space with WebAssembly. And then I’ll explain why this makes it a good mental model for how WebAssembly and JavaScript work together.
The space/time continuum as bytes
What we have here is a 3D space. Or really, if you think about it, it’s more like a four dimensional space, because we’re going through time as well.

The computer can’t think in these four dimensions, though. So how do we make these four dimensions make sense to the computer? Let’s start with the fourth dimension and collapse down from there.
You’re probably familiar with the way that we make time the fourth dimension make sense to computers. That’s by using these things called frames.
The screen is kind of like a flipbook. And each frame is like a page in that flip book.

On the web, we talk about having 60 frames per second. That’s what you need to have smooth animations across the screen. What that really means is that you have 60 different snapshots of the screen… of what the animation should look like at each of those 60 points during the second.
In our case, the snapshot is a snapshot of what the lights on the space should look like.
So that brings us down to a sequence of snapshots of the space. A sequence of 3D representations of the space.

Now we want to go from 3D to 2D. And in this case, it is pretty easy. All we need to do is take the space and flatten it out into basically a big sheet of graph paper.

So now we’re down to 2D. We just need to collapse this one more time.
We can do