Written by Amy Lee & Eric Pang
Firefox has a motion team?! Yes we do!
Motion may sometimes feel like an afterthought or worse yet “polish”. For the release of Firefox Quantum (one of our most significant releases to date), we wanted to ensure that motion was not a second class citizen and that it would play an important role in how users perceived performance in the browser.
We (Amy & Eric) make up the UX side of the “motion team” for Firefox. We say this in air quotes because the motion team was essentially formed based on our shared belief that motion design is important in Firefox. With a major release planned, we thought this would be the perfect opportunity to have a team working on motion.
Step 1: Make a Sticker
We made a sticker and started calling ourselves the motion team.

Step 2: Audit Existing Motions
The next plan of action was to audit the existing motions in Firefox across mobile and desktop. We documented them by taking screen recordings and highlighted the areas that needed the most attention.
From this exercise it was clear that consistency and perceived performance were high on our list of improvements.
The next step was to gather inspiration for a mood board. From there, we formed a story that would become the foundation of our motion design language.
During this process, we asked ourselves:
How can we make the browser feel smoother, faster and more responsive?.
Step 3: Defining a Motion Story
With Photon (Firefox’s new design language) stemming from Quantum we knew there was going to be an emphasis on speed in our story. Before starting work on any new motions, we created a motion curve to reflect this. The aim was to have a curve that would be perceived as fast yet still felt smooth and natural when applied to tabs and menu items. Motion should also be informative (i.e showing where your bookmarked item is saved, when your tab is done loading) and lastly, have personality. We defined our story based on these considerations.
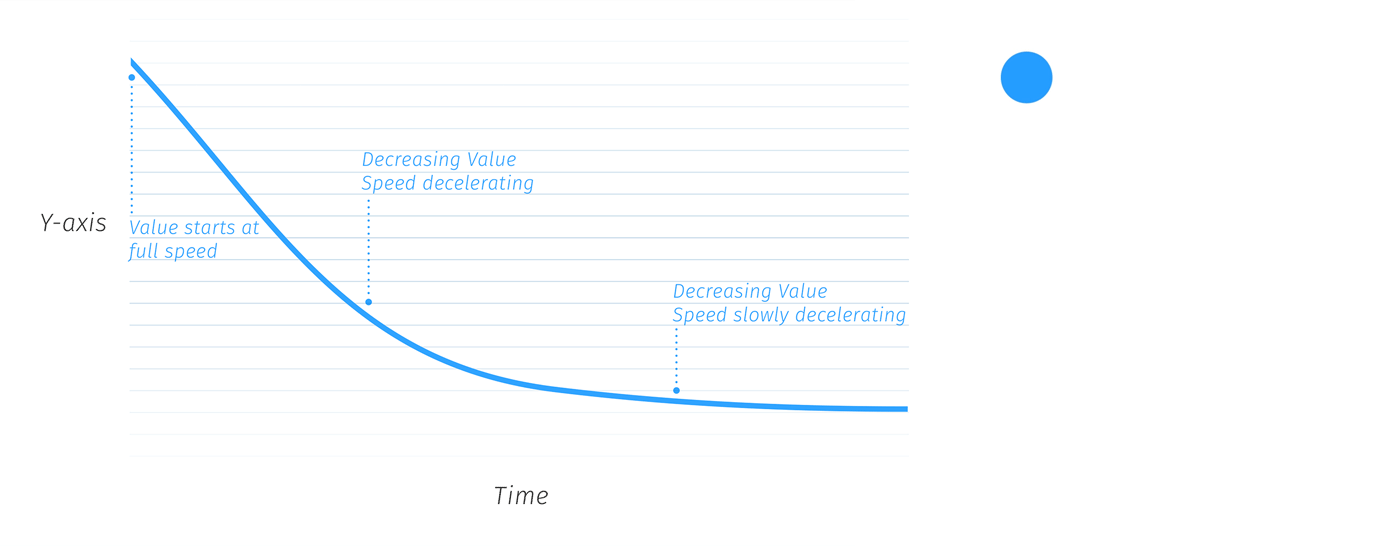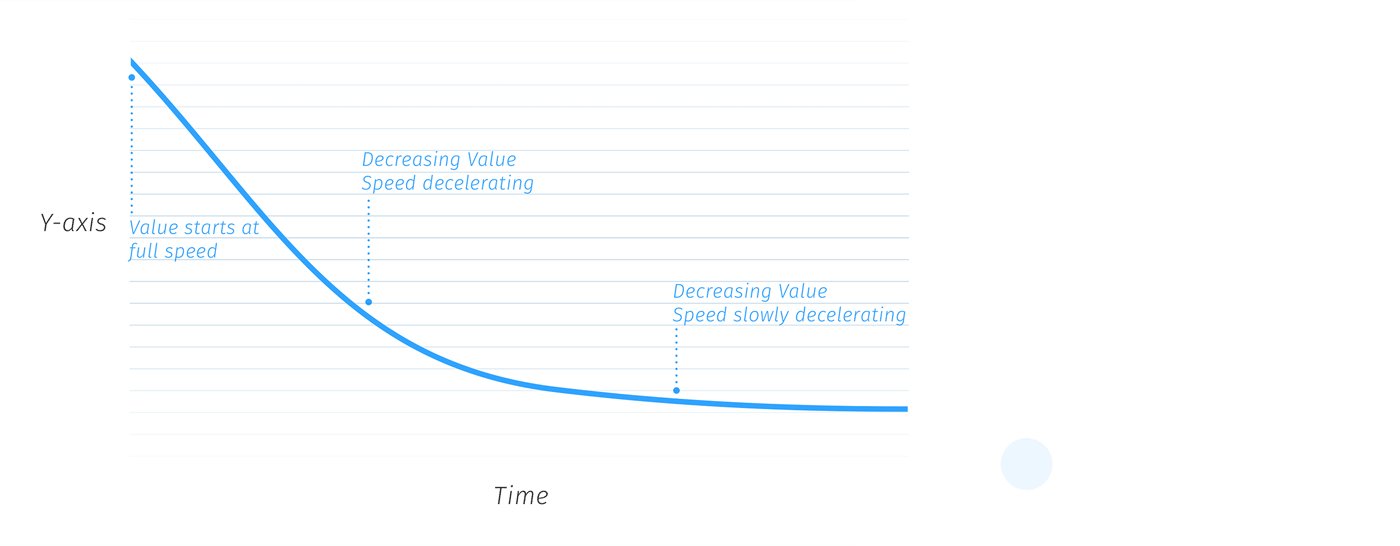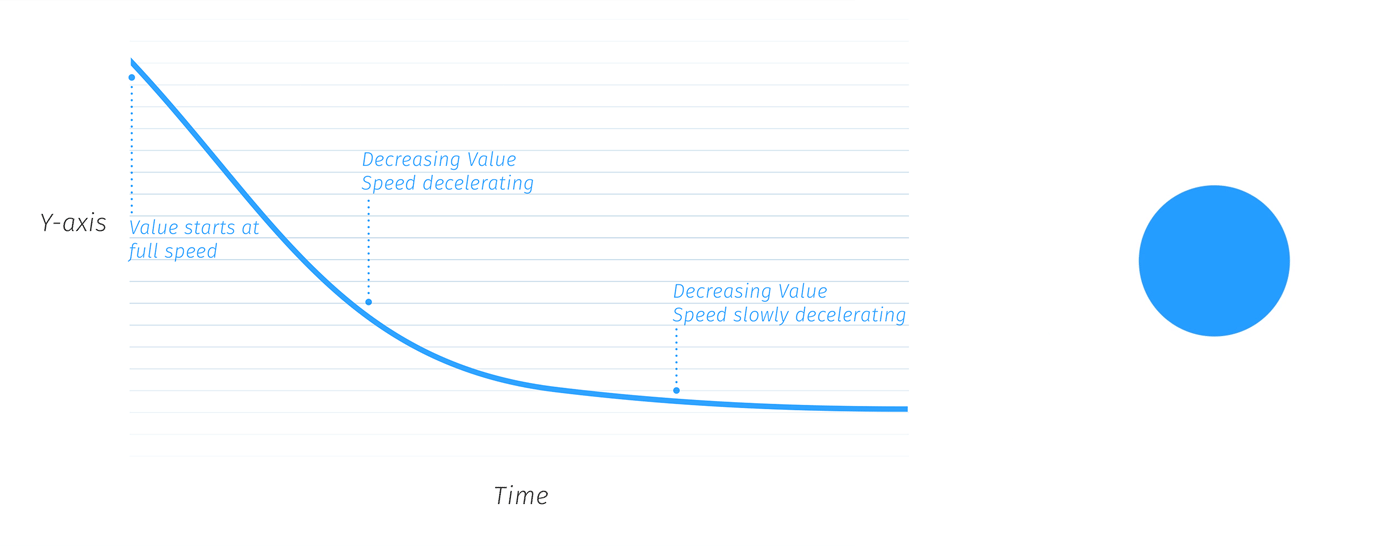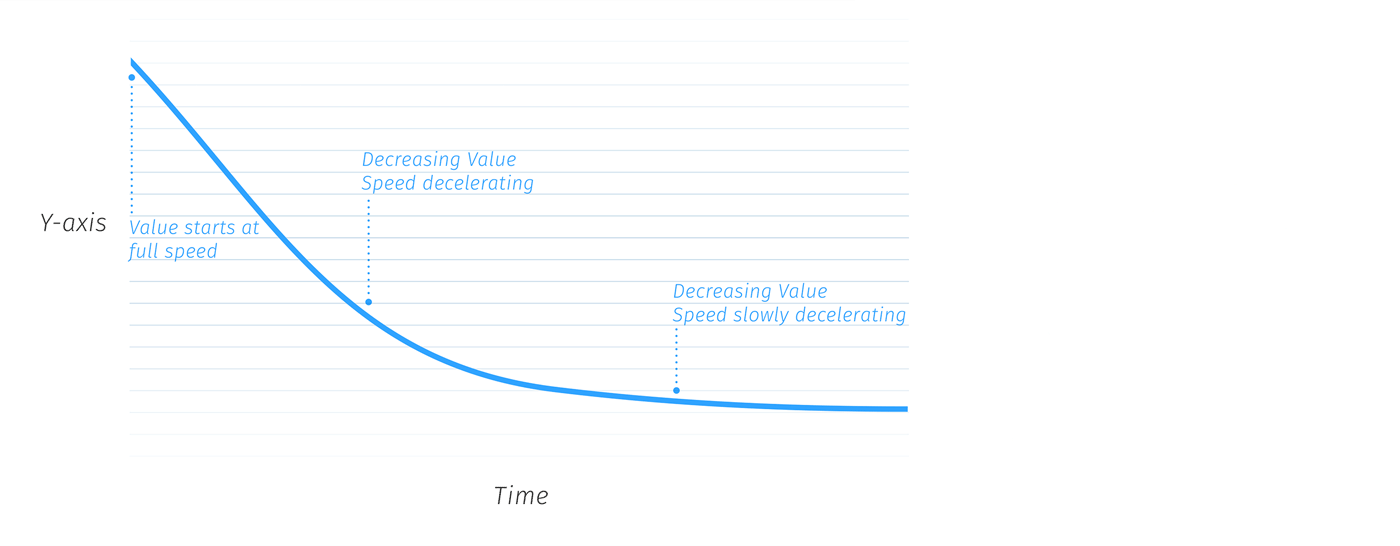
The motion story was presented to the rest of the UX team during a work week held in Toronto (the UX team is distributed across several countries so work weeks are planned for in-person collaboration).
This was our mission statement:
The motion design language in Firefox Quantum is defined by three principles: Quick, Informative and Whimsical. Following these guiding principles, we aim to achieve a cohesive, consistent, and enjoyable experience within the family of Firefox browsers.
Next we presented some preliminary concepts to support these principles:
Quick
Animations should be fast and nimble and never keep the user waiting longer than they need to. The aim is to prioritize user perceived performance over technical benchmarks.

Informative
Motion should help ease the user through the experience. It should aid the flow of actions, giving clear guidance for user orientation: spatial or temporal.

Whimsical
Even though most people would not associate whimsy with a browser, we wanted to incorporate some playful elements as part of Firefox’s personality (and maybe ourselves).
 This is an informational webinar for a global public audience interested in learning more about Mozilla's Creative Media Awards track. This event is being streamed...
This is an informational webinar for a global public audience interested in learning more about Mozilla's Creative Media Awards track. This event is being streamed...
With the upcoming release of Firefox 61, we are pleased to welcome the 59 developers who contributed their first code change to Firefox in this release, 53 of whom were brand new volunteers! Please join us in thanking each of these diligent and enthusiastic individuals, and take a look at their contributions:
- cubouyaka: 1445220
- dora.tokio: 865615
- gilad.bau: 1445895
- kylemsguy: 1442061
- mayank9856: 1442884
- peter.bacalso: 1443292
- ryanro1997: 1445267
- smswessem: 1358240
- Aakanksha: 1444372, 1444853
- Abdoulaye O. LY: 1445732
- Aditya Khadse: 1441433
- Alex Morega: 1393881
- Alvaro Reina: 1440577
- Amin Al Hazwani: 1443771
- Amy Chan: 1444325, 1446975
- Andrei Hajdukewycz: 1458162
- Andrei Lazar: 1355389, 1431329
- Austin Lasher: 1421563
- Bel'en: 1450064, 1454350, 1454895
- Brian: 1442300
- Daniel Almeida: 1447950
- David McCurry: 859051
- Dylan Stokes: 1417883
- EdenChuang: 1440041, 1441709, 1443914
- Eliza Balazs: 1262679
- Igor Oliveira: 1455165
- Issei Horie: 1447941, 1452207, 1455353, 1458398
- Jake Nixon: 1441658
- Jens Hausdorf : 1442442, 1447312
- Jon Kollari: 1441844
- Jordan Hu: 1383793
- Kiran: 1447956
- Lawson C:
Hello Mozillians!
As you may already know, last Friday – June 15th – we held a new Testday event, for Firefox 61 Beta 14.
Thank you all for helping us make Mozilla a better place!
From India team: Aishwarya Narasimhan, Mohamed Bawas, Surentharan, amirthavenkat, Monisha Ravi
Results:
– several test cases executed for Fluent Migration of Preferences, Accessibility Inspector: Developer Tools and Web Compatibility.
Thanks for another successful testday
https://quality.mozilla.org/2018/06/firefox-61-beta-14-testday-results/
This is a first blog post of a series on Gecko, since I am doing a lot of C++ work in Firefox these days. My current focus is on adding tools in Firefox to try to detect what's going on when something goes rogue in the browser and starts to drain your battery life.
We have many ideas on how to do this at the developer/user level, but in order to do it properly, we need to have accurate ways to measure what's going on when the browser runs.
One thing is I/O activity.
For instance, a WebExtension worker that performs a lot of disk writes is something we want to find out about, and we had nothing to track all I/O activities in Firefox, without running the profiler.
When Firefox OS was developed, a small feature was added in the Gecko network lib, called NetworkActivityMonitor.
That class was hooked as an NSPR layer to send notifications whenever something was sent or received on a socket, and was used to blink the small icon phones usually have to signal that something is being transferred.
After the Firefox OS project was discontinued in Gecko, that class was left in the Gecko tree but not used anymore, even though the option was still there.
Since I needed a way to track all I/O activity (sockets and files), I have refactored that class into a generalised version that can be used to get notified every time data is sent or received in any file or socket.
The way it works is pretty simple: when a file or a socket is created, a new NSPR layer is added so every read or write is recorded and eventually dumped into an XPCOM array that is notified via a timer.
This design makes it possible to track along sockets, any disk file that is accessed by Firefox. For SQLite databases, since there's no way to get all FD handles (theses are kept internal to the sqlite lib), the IOActivityMonitor class provides manual methods to notify when a read or a write happens. And our custom SQLite wrapper in Firefox allowed me to add calls like I would do in NSPR.
It’s landed in Nightly :
- https://searchfox.org/mozilla-central/source/netwerk/base/IOActivityMonitor.h
- https://searchfox.org/mozilla-central/source/netwerk/base/IOActivityMonitor.cpp
And you can see how to use it in its Mochitest
TenFourFox Feature Parity Release 8 beta 1 is now available (downloads, release notes, hashes). There is much less in this release than I wanted because of a family member in the hospital and several technical roadblocks. Of note, I've officially abandoned CSS grid again after an extensive testing period due to the fact that we would need substantial work to get a functional implementation, and a partially functional implementation is worse than none at all (in the latter case, we simply gracefully degrade into block-level s). I also was not able to finish the HTML date picker implementation, though I've managed to still get a fair amount completed of it, and I'll keep working on that for FPR9. The good news is, once the date picker is done, the time picker will use nearly exactly the same internal plumbing and can just be patterned off it in the same way. Unlike Firefox's implementation, as I've previously mentioned our version uses native OS X controls instead of XUL, which also makes it faster. That said, it is a ghastly hack on the Cocoa widget side and required some tricky programming on 10.4 which will be the subject of a later blog post.
That's not to say this is strictly a security patch release (though most of the patches for the final Firefox 52, 52.9, are in this beta). The big feature I did want to get in FPR8 did land and seems to work properly, which is same-site cookie support. Same-site cookie support helps to reduce cross-site request forgeries by advising the browser the cookie in question should only be sent if a request originates from the site that set it. If the host that triggered the request is different than the one appearing in the address bar, the request won't include any of the cookies that are tagged as same-site. For example, say you're logged into your bank, and somehow you end up opening another tab with a malicious site that knows how to manipulate your bank's transfer money function by automatically submitting a hidden POST form. Since you're logged into your bank, unless your bank has CSRF mitigations (and it had better!), the malicious site could impersonate you since the browser will faithfully send your login cookie along with the form. The credential never leaked, so the browser technically didn't malfunction, but the malicious site was still able to impersonate you and steal your money. With same-site cookies, there is a list of declared "safe" operations; POST forms and certain other functions are not on that list and are considered "unsafe." Since the unsafe action didn't originate from the site that set the cookie, the cookie isn't transmitted to your bank, authentication fails and the attack is foiled. If the mode is set to "strict" (as opposed to "lax"), even a "safe" action like clicking a link from an outside site won't send the cookie.
Same-site cookie support was implemented for Firefox 60; our implementation is based on it and should support all the same features. When you start FPR8b1, your cookies database will be transparently upgraded to the new database schema. If you are currently logged into a site that supports same-site cookies, or you are using a foxbox that preserves cookie data, you will need to log out and log back in to ensure your login cookie is upgraded (I just deleted all my cookies and started fresh, which is good to give the web trackers a heart attack anyway). Github and Bugzilla already have support, and I expect to see banks and other high-security sites follow suit. To see if a cookie on a site is same-site, make sure the Storage Inspector is enabled in Developer tools, then go to the Storage tab in the Developer tools on the site of interest and look at the Cookies database. The same-site mode (unset, lax or strict) should be shown as the final column.
FPR8 goes live on June 25th.
http://tenfourfox.blogspot.com/2018/06/tenfourfox-fpr8b1-available.html
You may already be familiar with in-tree actions: they allow you to do things like retrigger, backfill, and cancel Firefox-related tasks
They implement any “action” on a push that occurs after the initial hg push operation.
This article goes into a bit of detail about how this works, and a major change we’re making to that implementation.
History
Until very recently, actions worked like this:
First, the decision task (the task that runs in response to a push and decides what builds, tests, etc. to run) creates an artifact called actions.json.
This artifact contains the list of supported actions and some templates for tasks to implement those actions.
When you click an action button (in Treeherder or the Taskcluster tools, or any UI implementing the actions spec), code running in the browser renders that template and uses it to create a task, using your Taskcluster credentials.
I talk a lot about functionality being in-tree. Actions are yet another example. Actions are defined in-tree, using some pretty straightforward Python code. That means any engineer who wants to change or add an action can do so – no need to ask permission, no need to rely on another engineer’s attention (aside from review, of course).
There’s Always a Catch: Security
Since the beginning, Taskcluster has operated on a fairly simple model: if you can accomplish something by pushing to a repository, then you can accomplish the same directly. At Mozilla, the core source-code security model is the SCM level: try-like repositories are at level 1, project (twice) repositories at level 2, and release-train repositories (autoland, central, beta, etc.) are at level 3. Similarly, LDAP users may have permisison to push to level 1, 2, or 3 repositories. The current configuration of Taskcluster assigns the same scopes to users at a particular level as it does to repositories.
If you have such permission, check out your scopes in the Taskcluster credentials tool (after signing in). You’ll see a lot of scopes there.
The Release Engineering team has made release promotion an action. This is not something that every user who can push to level-3 repository – hundreds of people – should be able to do! Since it involves signing releases, this means that every user who can push to a level-3 repository has scopes involved in signing a Firefox release. It’s not quite as bad as it seems: there are lots of additional safeguards in place, not least of which is the “Chain of Trust” that cryptographically verifies the origin of artifacts before signing.
All the same, this is something we (and the Firefox operations security team) would like to fix.
In the new model, users will not have the same scopes as the repositories they can push to. Instead, they will have scopes to trigger specific actions on task-graphs at specific levels. Some of those scopes will be available to everyone at that level, while others will be available only to more limited groups. For example, release promotion would be available to the Release Management team.
Hooks
This makes actions a kind of privilege escalation: something a particular user can cause to occur, but could not do themselves.
The Taskcluster-Hooks service provides just this sort of functionality:
a hook creates a task using scopes assiged by a role, without requiring the user calling triggerHook to have those scopes.
The user must merely have the appropriate hooks:trigger-hook:.. scope.
So, we have added a “hook” kind to the action spec.
The difference from the original “task” kind is that actions.json specifies a hook to execute, along with well-defined inputs to that hook.
The user invoking the action must have the hooks:trigger-hook:.. scope for the indicated hook.
We have also included some protection against clickjacking, preventing someone with permission to execute a hook being tricked into executing one maliciously.
Generic Hooks
There are three things we may wish to vary for an action:
- who can invoke the action;
- the scopes with which the action executes; and
- the allowable inputs to the action.
Most of these are configured within the hooks service (using automation, of course). If every action is configured uniquely within the hooks service, then the self-service nature of actions would be lost: any
I've recently landed changes on mozilla-central to provide initial support for in-tree annotations of third-party code. (Bug 1454868, D1208, r5df5e745ce6e).
Why
- Provide consistency and discoverability to third-party code, its origin (repository, version, SHA, etc), and Mozilla-local modifications
- Simplify the process for auditing vendorerd versions and licenses
- Establish a structure which allows automation to drive vendoring
How
- Using the example
moz.yamlfrom the top ofmoz_yaml.plcreate amoz.yamlin the top level of third-party code - Verify the manifest with
mach vendor manifest --verify path/to/moz.yaml
Next
- We will be creating
moz.yamlfiles in-tree (help here is appreciated!) - Add tests to ensure
moz.yamlfiles remain valid - At some point we'll add automation-driven vendoring to simplify and standardise the process of updating vendored code
moz.yaml Template
From python/mozbuild/mozbuild/moz_yaml.py#l50
---
# Third-Party Library Template
# All fields are mandatory unless otherwise noted
# Version of this schema
schema: 1
bugzilla:
# Bugzilla product and component for this directory and subdirectories
product: product name
component: component name
# Document the source of externally hosted code
origin:
# Short name of the package/library
name: name of the package
description: short (one line) description
# Full URL for the package's homepage/etc
# Usually different from repository url
url: package's homepage url
# Human-readable identifier for this version/release
# Generally "version NNN", "tag SSS", "bookmark SSS"
release: identifier
# The package's license, where possible using the mnemonic from
# https://spdx.org/licenses/
# Multiple licenses can be specified (as a YAML list)
# A "LICENSE" file must exist containing the full license text
license: MPL-2.0
# Configuration for the automated vendoring system.
# Files are always vendored into a directory structure that matches the source
# repository, into the same directory as the moz.yaml file
# optional
vendoring:
# Repository URL to vendor from
# eg. https://github.com/kinetiknz/nestegg.git
# Any repository host can be specified here, however initially we'll only
# support automated vendoring from selected sources initiall.
url: source url (generally repository clone url)
# Revision to pull in
# Must be a long or short commit SHA (long preferred)
revision: sha
# List of patch files to apply after vendoring. Applied in the order
# specified, and alphabetically if globbing is used. Patches must apply
# cleanly before changes are pushed
# All patch files are implicitly added to the keep file list.
# optional
patches:
- file
- path/to/file
- path/*.patch
# List of files that are not deleted while vendoring
# Implicitly contains "moz.yaml", any files referenced as patches
# optional
keep:
- file
- path/to/file
- another/path
- *.mozilla
# Files/paths that will not be vendored from source repository
# Implicitly contains ".git", and ".gitignore"
# optional
exclude:
- file
- path/to/file
- another/path
- docs
- src/*.test
# Files/paths that will always be vendored, even if they would
# otherwise be excluded by "exclude".
# optional
include:
- file
- path/to/file
- another/path
- docs/LICENSE.*
# If neither "exclude" or "include" are set, all files will be vendored
# Files/paths in "include" will always be vendored, even if excluded
# eg. excluding "docs/" then including "docs/LICENSE" will vendor just the
# LICENSE file from the docs directory
# All three file/path parameters ("keep", "exclude", and "include") support
# filenames, directory names, and globs/wildcards.
# In-tree scripts to be executed after vendoring but before pushing.
# optional
run_after:
- script
- another script
As the last man standing as a fellowship representative in FSFE, I propose to give a report at the community meeting at RMLL.
I'm keen to get feedback from the wider community as well, including former fellows, volunteers and anybody else who has come into contact with FSFE.
It is important for me to understand the topics you want me to cover as so many things have happened in free software and in FSFE in recent times.

Some of the things people already asked me about:
- the status of the fellowship and the membership status of fellows
- use of non-free software and cloud services in FSFE, deviating from the philosophy that people associate with the FSF / FSFE family
- measuring both the impact and cost of campaigns, to see if we get value for money (a high level view of expenditure is here)
What are the issues you would like me to address? Please feel free to email me privately or publicly. If I don't have answers immediately I would seek to get them for you as I prepare my report. Without your support and feedback, I don't have a mandate to pursue these issues on your behalf so if you have any concerns, please reply.
Your fellowship representative
https://danielpocock.com/the-questions-you-really-want-fsfe-to-answer
Last week I tweeted "What do you think are the most interesting/exciting projects using Rust? (No self-promotion :-) )". The response was awesome! Jonathan Turner suggested I write up the responses as a blog post, and here we are.
I'm just going to list the suggestions, crediting is difficult because often multiple people suggested the same projects, follow the Twitter thread if you're interested:
- Atom/X-ray - experimental text editor (next-gen Atom)
- Servo - experimental web browser
- Fuchsia - operating system
- TiKV - key/value store
- Xi - text editor
- Conduit - service mesh
- Mononoke - Mercurial implementation
- Lyon - GPU path rendering
- Pathfinder - GPU rasterizer
- Amethyst - game engine
- GFX - graphics library
- Rayon - data parallelism library
- fd - next-gen find
- libpnet - low-level networking library
- Ripgrep - Next-gen grep
- Sled - database
- Nebulet - microkernal
- Timely-dataflow - dataflow model
- Citybound - game
- Trust-dns - DNS
- Witchbrook - game
- Rusoto - AWS library
- Actix-web - web framework
- Alacritty - terminal
- Rocket - web framework
- Pijul - distributed version control
- Redox - operating system
- Cretonne - compiler backend
- Pikelet - programming language
- svd2rust - generates register maps
- embedded-hal - hardware abstraction layer
- raft-rs - distributed consensus algorithm
- FeL4 - seL4 for Rust
- Nom - parser combinator library
- Intermezzos - operating system
- Waycooler - Wayland compositor
- Tock - operating system
- Mentat - database
- Firefox - web browser
- Three-rs - 3D library
- Cernan - telemetry server
- xsv - CSV command line toolkit
- Amber - code search and replace
- Tokei - code stats
Virtual Reality (VR) content has arrived on the web, with help from the WebVR API. It’s a huge inflection point for a medium that has struggled for decades to reach a wide audience. Now, anyone with access to an internet-enabled computer or smartphone can enjoy VR experiences, no headset required. A good place to start? WITHIN’s freshly launched VR website.
From gamers to filmmakers, VR is the bleeding edge of self-expression for the next generation. It gives content creators the opportunity to tell stories in new ways, using audience participation, parallel narratives, and social interaction in ever-changing virtual spaces. With its immersive, 360-degree audio and visuals, VR has outsized power to activate our emotions and to put us in the center of the action.
WITHIN is at the forefront of this shift toward interactive filmmaking and storytelling. The company was one of the first to launch a VR distribution platform that showcases best-in-class VR content with high production values.

“Film is this incredible medium. It allows us to feel empathy for people that are very different from us, in worlds completely foreign to our own,” said Chris Milk, co-founder of WITHIN, in a Ted Talk. “I started thinking, is there a way I could use modern and developing technologies to tell stories in different ways, and tell different kinds of stories that maybe I couldn’t tell using the traditional tools of filmmaking that we’ve been using for 100 years?”
Simple to use
WITHIN’s approach is to bring curated and original VR experiences directly to viewers for free, rather than trying to gain visibility for their content through existing channels. Until now, VR content was mostly presented to headset users via the manufacturer’s store websites. So if you shelled out hundreds of dollars for an Oculus Rift or HTC Vive, you would see a library of content when you fired up your rig.
 With its new site, WITHIN is making VR content accessible to everyone, whether they’re watching on a laptop, mobile phone, or headset. The company produces immersive VR experiences with high-profile partners like the band OK Go and Tyler Hurd. It also distributes top-tier VR experiences, like family-friendly animation and nature shows, with 360-degree visuals and stereoscopic sound.
With its new site, WITHIN is making VR content accessible to everyone, whether they’re watching on a laptop, mobile phone, or headset. The company produces immersive VR experiences with high-profile partners like the band OK Go and Tyler Hurd. It also distributes top-tier VR experiences, like family-friendly animation and nature shows, with 360-degree visuals and stereoscopic sound.
“We aim to make it as easy as possible for fans to discover and share truly great VR experiences,” said Jon Rittenberg, Content Launch Manager at WITHIN.
WebVR JavaScript API
The key to reaching a vast potential audience of newcomers is to make a platform that is simple to use and easy to explore. Most importantly, it should work without exposing visitors to technical hurdles. That’s a challenge for two reasons.
First, the web is famously democratic. Companies like WITHIN have no control over who comes to their site, what device they’re on, what operating system that device runs, or how much bandwidth they have. Second, the web is still immature as a VR platform, with a growing but limited number of tools.
 To build a platform that ‘just works’, the engineers at WITHIN turned to the WebVR API. Mozilla engineers built the foundation for the WebVR API with a goal to give companies like WITHIN a simpler way to support a range of viewing options without having to rewrite their code for each platform. WebVR provides support for exposing VR devices and headsets to web apps, enabling developers to translate position and movement information from the display into movement around a 3D scene.
To build a platform that ‘just works’, the engineers at WITHIN turned to the WebVR API. Mozilla engineers built the foundation for the WebVR API with a goal to give companies like WITHIN a simpler way to support a range of viewing options without having to rewrite their code for each platform. WebVR provides support for exposing VR devices and headsets to web apps, enabling developers to translate position and movement information from the display into movement around a 3D scene.
Adapting content to devices
Using the WebVR specification, the company built its WITHIN WebVR site so it could adapt to dozens of factors and give new viewers a consistently great experience. In an amazing proof-of-concept for VR on the web, the company
This year, 670 individuals spent some of their valuable time on our survey and filled in answers that help us guide what to do next. What's good, what's bad, what to remove and where to emphasize efforts more.
It's taken me a good while to write up this analysis but hopefully the results here can be used all through the year as a reminder what people actually think and how they use curl and libcurl.
A new question this yeas was in which continent the respondent lives, which ended up with an unexpectedly strong Euro focus:

What didn't trigger any surprises though was the question of what protocols users are using, which basically identically mirrored previous years' surveys. HTTP and HTTPS are the king duo by far.
Read the full 34 page analysis PDF.
Some other interesting take-aways:
- One person claims to use curl to handle 19 protocols! (out of 23)
- One person claims to use curl on 11 different platforms!
- Over 5% of the users argue for a rewrite in rust.
- Windows is now the second most common platform to use curl on.
https://daniel.haxx.se/blog/2018/06/12/curl-survey-2018-analysis/
Today, we’re announcing new features in Firefox for iOS to make your life easier. Whether you’re a multi-tasker or someone who doesn’t want to waste time, we’re rolling out new features to up your productivity game.
Taking your file downloads on the go
For those times when you need to leave the office but want to read that file during your commute or at a later time, we now provide support for downloading files to your mobile devices. First download them to your device, then access and share it in the main menu where you’ll find a folder with all your downloads.
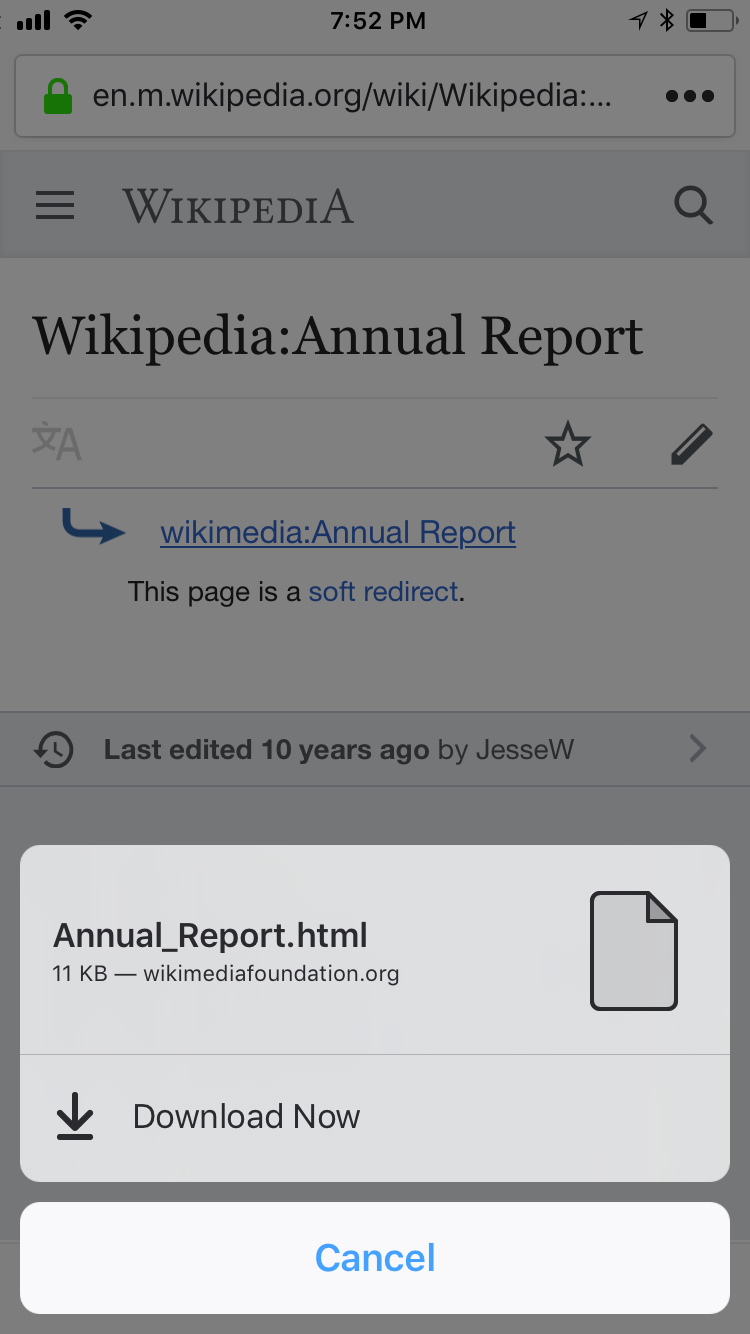
Easy to download

A folder with your downloads
One-Stop Place for Saving your Links
Did you ever come across an article that catches your eye but don’t have time to read it right away? We’ve added a one-stop menu to give you choices on what to do with the link. You can open it directly in Firefox, add it to your bookmark or reading list to peruse at your convenience, or send it to another device that’s linked to your Firefox account.
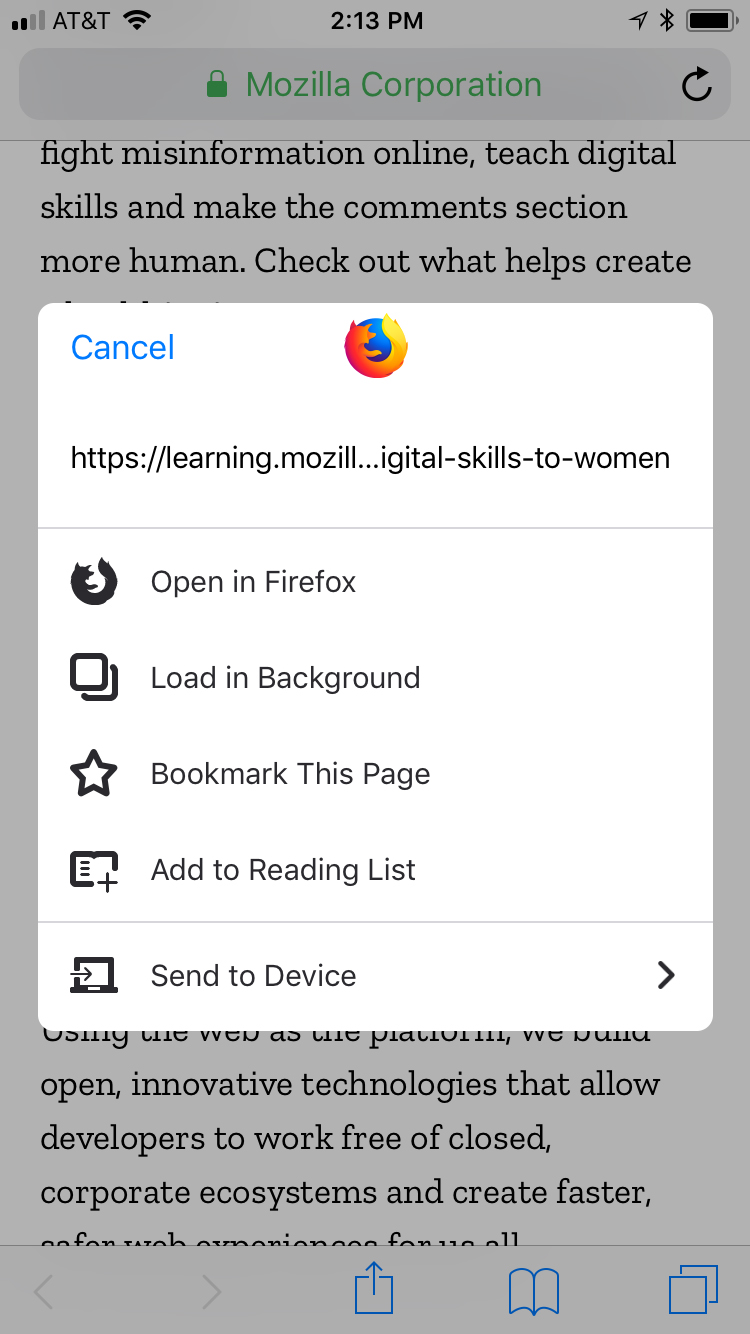
A one-stop menu with choices
Are you Synced?
You’ll get the answer quickly now that we’ve made it easier to see whether your mobile device is connected to all your devices where you use Firefox. Click on the menu button listed prominently at the top of the application menu. From there, you’ll see if you’re synced, and if you aren’t you’ll have the option to do so. If you don’t have a Firefox Account, you can sign up directly here.
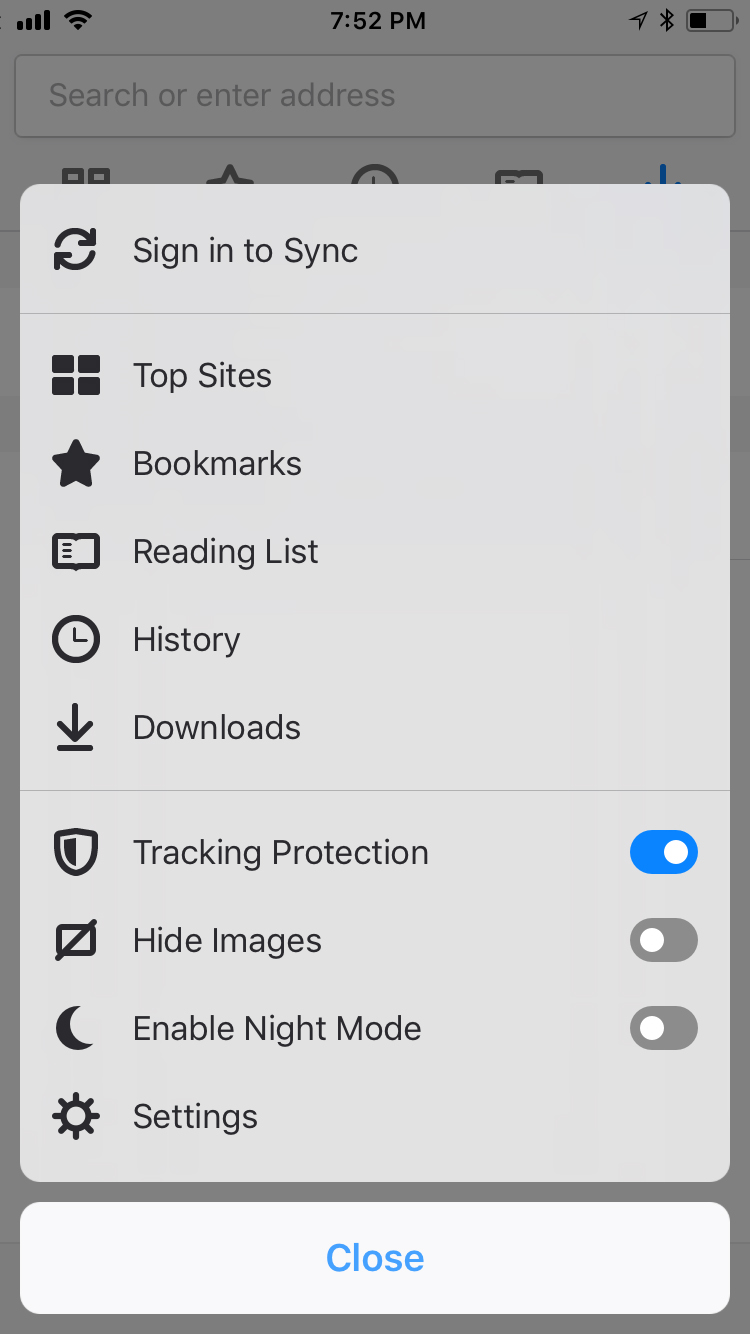
From the top of the app menu you’ll see if you’re synced or not
Firefox continues to bring convenience to iOS users. To get the latest version of Firefox for iOS, visit the App Store.
The post Level Up with New Productivity Features in Firefox for iOS appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2018/06/12/level-up-with-new-productivity-features-in-firefox-for-ios/
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
News & Blog Posts
- Understanding the difference between
Box,&Trait,impl Trait, anddyn Trait. - varkor joins the Compiler Team!
- First screenshot of Dota2 running on gfx-portabilty with Metal backend.
- Actix – an actor framework for Rust.
- Migrating to Actix from Rocket.
- A Rust-based unikernel: First version of a Rust-based libOS.
- Where do Rust threads come from?
- To do a Rust GUI.
- Integrating QML and Rust: Creating a QMetaObject at compile time.
- crates.rs: An alternative to crates.io.
- nphysics: A Physics engine in Rust now has 3D demos running in modern browsers.
- [podcast] Rusty Spike Podcast - episode 32. 1.26.2 release, the arch (video and site), compiler speed-ups, crates.rs, and more thoughts on the Rust design process.
Crate of the Week
This week's crate is clap-verbosity-flag, a small crate to easily add a verbosity setting to Rust command line applications. Thanks to Yoshuawuyts for the suggestion!
Submit your suggestions and votes for next week!
Call for Participation
Always wanted to contribute to open-source projects but didn't know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
- Sponsor work on Rust!
- wasm-pack has several open good first issues available to new contributors.
- Get started with these beginner-friendly issues.
If you are a Rust project owner and are looking for contributors, please submit tasks here.
Updates from Rust Core
110 pull requests were merged in the last week
- Keyword unreservations (pure, sizeof, alignof, offsetof) (RFC #2421)
- parser: split
+=into+and=where+is
Over the last three months, Mozilla has been a vocal critic of Facebook’s practices with respect to its lack of user transparency. Throughout this time we’ve engaged with Facebook directly about this and have continued to comment publicly as the story about Facebook’s data practices evolves.
Mozilla Corporation recently received two termination notices from Facebook about work that we did with them in the past. These appear to be part of Facebook’s broader effort to clean up its third-party developer ecosystem. This is good – we suspect that we weren’t the only ones receiving these notices. Still, the notices, and recent reporting of Facebook data sharing with device makers, prompted us to take a closer look at our past relationships with the company and we think it is important to talk about what we found.
At a high level we found that Mozilla Corporation had two agreements with Facebook initiated in 2012 and 2013 respectively. No information from Facebook was transferred to Mozilla Corporation in either situation but there were permissions granted to Mozilla Corporation in the agreements with respect to user data. In fact, in one case, our engineers noticed the overly broad access and requested that Facebook limit it. Here are some additional details:
In 2012, Mozilla Corporation had an agreement with Facebook that was intended to make it easier for individuals using Facebook through the Firefox browser to interface with the Facebook application. The relationship was part of our work on the Social API, an effort to integrate social experiences more seamlessly into the browser. As part of that agreement, Facebook was able to display web pages, including users’ data appearing on those pages, in specialized locations in the Firefox browser. This means that data was sent directly to the browser client, and none of the users’ Facebook information was shared with Mozilla Corporation. You can find more publicly available information about this integration here.
The 2013 agreement related to our now-defunct mobile operating system, Firefox OS. When users began using a Firefox OS device, they were given the explicit option of importing their Facebook contacts onto that device. Again, none of the users’ Facebook information was shared with Mozilla. When users disconnected their Facebook account, they were given the option of removing their Facebook data from the device. You can see in our public bug tracker that our team actually asked Facebook to remove some data access permissions because “we shouldn’t request permissions we don’t need.”
While these agreements have remained in effect, the work on these projects had already ended. We finished deprecating the Social API in 2017. Mozilla stopped development of Firefox OS in 2015, although any Firefox OS devices still in use today may retain access until Facebook shuts down that access in accordance with their termination notice.
We are bringing this to your attention because we want to be clear that our products technically had access to Facebook’s APIs and because we want to explain what was done with that access. We encourage other companies to review their relationships with Facebook and to be transparent about what those involved. That level of transparency is what is needed today to build a healthier, more trustworthy Internet that puts users first.
The post Our past work with Facebook appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2018/06/11/our-past-work-with-facebook/
Today, from across the world, Mozillians are gathering in San Francisco for our six-monthly All Hands. For obvious reasons, I won’t be able to be there, so I want to wish all the best to everyone, and I am confident that more awesome ideas for rocking the free web will emerge from their deliberations. Each year brings different grey clouds to the sky, and requires us to adjust our strategy and tactics to deal with new threats. Some we win and a few we lose, but it’s clear that the world and the web are much better places with Mozilla in them fighting for what is right.
http://feedproxy.google.com/~r/HackingForChrist/~3/2w52hc1X-NQ/
I'm on my way to San Francisco for a guest visit to the Mozilla All Hands ... thanks, Mozilla!
After that, I'll be taking a break for a few days and going hiking with some friends. Then I'll spending a week or so visiting more people to talk about rr and Pernosco. Looking forward to all of it!

WebExtensions (there is no XUL) took over with a thud seven months ago, which was felt as a great disturbance in the Force by most of us who wrote Firefox add-ons that, you know, actually did stuff. Many promises were made for APIs to allow us to do the stuff we did before. Some of these promises were kept and these APIs have actually been implemented, and credit where credit is due. But there are many that have not (that metabug is not exhaustive). More to the point, there are many for which people have offered to write code and are motivated to write code, but we have no parameters for what would be acceptable, possibly because any spec would end up stuck in a "boil the ocean" problem, possibly because it's low priority, or possibly because someone gave other someones the impression such an API would be acceptable and hasn't actually told them it isn't. The best way to get contribution is to allow people to scratch their own itches, but the urgency to overcome the (largely unintentional) institutional roadblocks has faded now that there is somewhat less outrage, and we are still left with a disordered collection of APIs that extends Firefox relatively little and a very slow road to do otherwise.
Or perhaps we don't have to actually rely on what's in Firefox to scratch our itch, at least in many cases. In a potentially strategically unwise decision, WebExtensions allows native code execution in the form of "native messaging" -- that is, you can write a native component, tell Firefox about it and who can talk to it, and then have that native component do what Firefox don't. At that point, the problem then becomes more one of packaging. If the functionality you require isn't primarily limited by the browser UI, then this might be a way around the La Brea triage tarpit.
Does this sound suspiciously familiar to anyone like some other historical browser-manipulated blobs of native code? Hang on, it's coming back to me. I remember something like this. I remember now. I remember them!
If you've been under a rock until Firefox 52, let me remind you that plugins were globs of native code that gave the browser wonderful additional capabilities such as playing different types of video, Flash and Shockwave games and DRM management, as well as other incredibly useful features such as potential exploitation, instability and sometimes outright crashes. Here in TenFourFox, for a variety of reasons I officially removed support for plugins in version 6 and completely removed the code with TenFourFox 19. Plugins served a historic purpose which are now better met by any number of appropriate browser and HTML5 APIs, and their disadvantages now in general outweigh their advantages.
Mozilla agrees with this, sort of. Starting with 52 many, though not all, plugins won't run. The remaining lucky few are Flash, Widevine and OpenH264. If you type about:plugins into Firefox, you'll still see them unless you're like me and you're running it on a POWER9 Talos II or some other hyper-free OS. There's a little bit of hypocrisy here in the name of utilitarianism, but I think it's pretty clear there would be a pretty high bar to adding a new plugin to this whitelist. Pithily, Mozilla has concluded regardless of any residual utility that plugins kill kittens.
It wasn't just plugins, either. Mozilla really doesn't like native
Back in January of 2014, I wrote a blog post called Hacking a Pellet Stove to Work with Nest. It was a narrative about trying to use the advanced features of the Nest learning thermostat to control a pellet stove in the volatile temperature environment of a yurt.

While the solution worked, it didn't work well enough. The Nest thermostat, when perceiving that the yurt needed heat, would turn the pellet stove onto low. If, after twenty minutes or so, the yurt hadn't sufficiently heated, the Nest thermostat would advance the pellet stove to medium. It repeated that cycle to eventually advance to high. The meant that when the yurt was cold, it would take more than forty minutes to provide "room temperature". Once it did achieve room temperature, the thermostat would just turn the pellet stove off.

Rather than slowly advancing through the levels, I needed the stove to start on high and then back down through the levels on shutdown. I call this a "lingering shutdown". My original solution was based on a logic table that did not have to deal with past state; the Nest thermostat handled the progression through states. To implement the lingering shutdown, I'd instead need a finite state machine that took into account previous state and have an external timing trigger. That lead to a ridiculous logic table and I abandoned that path.
I eventually dropped the exclusively electromechanical aspect of this solution and wrote software running on a Raspberry Pi to do the interface. Relays were still used, but only for electrical isolation of the components. This software was problematic, too, but in a different way. The UX wasn't very good: to change the timing of the lingering shutdown levels required opening an ssh session and manually setting configuration values (yes Socorro people, complex configuration bit my ass here, too). It was just never critical enough to justify the effort of writing a UI the whole family could use.
That changed when Things Gateway with the Things Framework, was released. I could now create a program that could mediate between the Nest and the thermostat and, without additional effort, have a Web accessible user interface. Further, it enables a rule system that can adjust the behavior of the stove based on any device the Things Gateway can use: temperature sensors, wind sensors, etc. In fact, it is likely that I can just write the Nest thermostat entirely out of the system. One less cloud dependent service is a win.
The previous iteration of my software had already figured out how to get real world information in and out of the Raspberry Pi using the GPIO pins. I configured one GPIO pin as input and three GPIO pins as output.