Presently TenFourFox uses Mozilla Addons as a repository for "legacy" (I prefer "classic" or "can actually do stuff" or "doesn't suck") add-ons that remain compatible with Firefox 45, of which TenFourFox is a forked descendant. Mozilla has now announced these legacy addons will no longer be accessible in October. I don't know if this means that legacy-only addons will no longer be visible, or no longer searchable, or whether older compatible versions of current addons will also be no longer visible, or whatever, or whether everything is going to be deleted and HTH, HAND. The blog post doesn't say. Just assume you may not be able to access them anymore.
This end-of-support is obviously to correlate with the end-of-life of Firefox 52ESR, the last version to support legacy add-ons. That's logical, but it sucks, particularly for people who are stuck on 52ESR (Windows XP and Vista come to mind). Naturally, this also sucks for alternative branches such as Waterfox which split off before WebExtensions became mandatory, and the poor beleaguered remnants of SeaMonkey.
For TenFourFox users, there is an archive available from SourceForge of the last Firefox 45-compatible versions of popular addons, both classic and current. Naturally this archive is not comprehensive and won't ever be, though I'll consider adding other addons I believe are notable. Download and drop the XPI on any open browser window. Other users are welcome to grab stuff from our archives, but I consider 52-compatible versions out of scope, so please don't ask.
For OverbiteFF users, I will probably move it back over to Floodgap's gopher clients page and maintain it there, since if you have an interest in Gopher I can pretty accurately predict you probably don't use a vanilla stock web browser either. However, because OverbiteWX and OverbiteNX are fully compatible with WebExtensions, they will not be affected by this change.
http://tenfourfox.blogspot.com/2018/08/tenfourfox-and-legacy-addons-and-their.html
Mozilla will stop supporting Firefox Extended Support Release (ESR) 52, the final release that is compatible with legacy add-ons, on September 5, 2018.
As no supported versions of Firefox will be compatible with legacy add-ons after this date, we will start the process of disabling legacy add-on versions on addons.mozilla.org (AMO) in September. On September 6, 2018, submissions for new legacy add-on versions will be disabled. All legacy add-on versions will be disabled in early October, 2018. Once this happens, users will no longer be able to find your extension on AMO.
After legacy add-ons are disabled, developers will still be able to port their extensions to the WebExtensions APIs. Once a new version is submitted to AMO, users who have installed the legacy version will automatically receive the update and the add-on’s listing will appear in the gallery.
For more information about porting legacy extensions to the WebExtensions API is available on MDN. We encourage legacy add-on developers to visit our wiki for more information about upcoming development work and ways to get in touch with our team for help.
The post Timeline for disabling legacy add-ons on addons.mozilla.org appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2018/08/21/timeline-for-disabling-legacy-firefox-add-ons/
These technologists, activists, and scientists will spend the next 10 to 12 months creating a more secure, inclusive, and decentralized internet
A neuroscientist building open-source hardware. A competition expert studying net neutrality enforcement in Nigeria. A technologist studying tools that combat disinformation.
These are just three of Mozilla’s latest Fellows — 26 technologists, activists, and scientists from more than 10 countries. Today, we’re announcing our 2018-2019 cohort of Fellows, who begin work on September 1, 2018.
Over the next 10 to 12 months, these Fellows will conduct research, create products, and build communities. In past cohorts, Mozilla Fellows have built secure platforms for LGBTQ individuals in the Middle East; leveraged open-source data and tools to bolster biomedical research across the African continent; and raised awareness about invasive online tracking.
More than ever, we need a movement to ensure the internet remains a force for good. Mozilla Fellows work on the front lines of that movement. Fellows develop new thinking on how to address emerging threats and challenges facing a healthy internet.
Learn more about Mozilla Fellowships, then meet our 2018-2019 Mozilla Fellows below (those fellows who are embedded at host organizations are funded through a joint Mozilla-Ford Foundation investment):
 Andr'e Maia Chagas | UK | As a Mozilla Fellow, Andre will be working on Open Hardware for science, in order to try and map which laboratory equipments are most used and which are lacking across working groups, institutions, and non-academic spaces. Once the mapping is complete, he wants to select one piece of equipment and build it open and collaboratively. He also wants to create tutorials about the basic components of the designs, so that they can be used as starting points for other projects. With this approach, he is hoping to increase access to scientific equipment, allowing institutions and communities to follow their own scientific interests. Before joining Mozilla, Andre worked at the Baden Lab in the University of Sussex, collaborating with Trend in Africa by organizing and executing workshops around Open Source Hardware. He was also maintaining Open Neuroscience, a repository for OS projects related to neuroscience.
Andr'e Maia Chagas | UK | As a Mozilla Fellow, Andre will be working on Open Hardware for science, in order to try and map which laboratory equipments are most used and which are lacking across working groups, institutions, and non-academic spaces. Once the mapping is complete, he wants to select one piece of equipment and build it open and collaboratively. He also wants to create tutorials about the basic components of the designs, so that they can be used as starting points for other projects. With this approach, he is hoping to increase access to scientific equipment, allowing institutions and communities to follow their own scientific interests. Before joining Mozilla, Andre worked at the Baden Lab in the University of Sussex, collaborating with Trend in Africa by organizing and executing workshops around Open Source Hardware. He was also maintaining Open Neuroscience, a repository for OS projects related to neuroscience.
 Ayden F'erdeline | Germany | At Mozilla, Ayden F'erdeline will be researching the ongoing development and harmonization of global privacy standards. He will work to develop an ambitious new toolkit for effectively operationalizing privacy protections online, identifying appropriate regulatory interventions that could incentivize data controllers to adopt higher privacy protections. He is currently a Councilor on the Council of the Generic Names Supporting Organization, the body which sets policy for generic top-level domain names like .com, where he represents the interests of non-commercial users and uses of the Domain Name System. Before joining Mozilla, Ayden F'erdeline supported the Internet Society’s global public policy team and was a researcher for the data and analytics group YouGov. He has previously facilitated workshops at the United Nations Internet Governance Forum, United Nations World Summit on the Information Society, the European Dialogue on Internet Governance, and the Internet Freedom Festival. He is a graduate of the London School of Economics.
Ayden F'erdeline | Germany | At Mozilla, Ayden F'erdeline will be researching the ongoing development and harmonization of global privacy standards. He will work to develop an ambitious new toolkit for effectively operationalizing privacy protections online, identifying appropriate regulatory interventions that could incentivize data controllers to adopt higher privacy protections. He is currently a Councilor on the Council of the Generic Names Supporting Organization, the body which sets policy for generic top-level domain names like .com, where he represents the interests of non-commercial users and uses of the Domain Name System. Before joining Mozilla, Ayden F'erdeline supported the Internet Society’s global public policy team and was a researcher for the data and analytics group YouGov. He has previously facilitated workshops at the United Nations Internet Governance Forum, United Nations World Summit on the Information Society, the European Dialogue on Internet Governance, and the Internet Freedom Festival. He is a graduate of the London School of Economics.
 Kadija Ferryman | U.S. | As a Mozilla Fellow, Kadija Ferryman will be working on an ethnography and history of electronic health records in order to examine the potential and limits of the growing open health data movement. In addition to the Mozilla Fellowship, Kadija Ferryman is a Postdoctoral Scholar at Data & Society Research Institute in New York, and was a public policy researcher at the Urban Institute for six years. She earned degrees in anthropology from Yale (BA) and the New School for Social Research (PhD).
Kadija Ferryman | U.S. | As a Mozilla Fellow, Kadija Ferryman will be working on an ethnography and history of electronic health records in order to examine the potential and limits of the growing open health data movement. In addition to the Mozilla Fellowship, Kadija Ferryman is a Postdoctoral Scholar at Data & Society Research Institute in New York, and was a public policy researcher at the Urban Institute for six years. She earned degrees in anthropology from Yale (BA) and the New School for Social Research (PhD).
 Camille Francois | U.S. | As a
Camille Francois | U.S. | As a
This article appeared originally on Mozilla Marketing Engineering & Operations blog
The Snippets Service allows Mozilla to communicate with Firefox users directly by placing a snippet of text and an image on their new tab page. Snippets share exciting news from the Mozilla World, useful tips and tricks based on user activity and sometimes jokes.
To achieve personalized, activity based messaging in a privacy respecting and efficient manner, the service creates a Bundle of Snippets per locale. Bundles are HTML documents that contain all Snippets targeted to a group of users, including their Style-Sheets, images, metadata and the JS decision engine …
https://giorgos.sealabs.net/using-brotli-compression-to-reduce-cdn-costs.html
Author’s Note: This post imagines a dystopian future for web video, if we continue to rely on patented codecs to transmit media files. What if one company had a perpetual monopoly on those patents? How could it limit our access to media and culture? The premise of this cautionary tale is grounded in fact. However, the future scenario is fiction, and the entities and events portrayed are not intended to represent real people, companies, or events.

Illustration by James Dybvig
This post was originally published on Mozilla's Hacks blog.
The year is 2029. It’s been two years since the start of the Video Wars, and there’s no end in sight. It’s hard to believe how deranged things have become on earth. People are going crazy because they can’t afford web video fees – and there’s not much else to do. The world’s media giants have irrevocably twisted laws and governments to protect their incredibly lucrative franchise: the right to own their intellectual property for all time.
It all started decades ago, with an arcane compression technology and a cartoon mouse. As if we needed any more proof that truth is stranger than fiction.
Adulteration of the U.S. Legal System
In 1998, the U.S. Congress passed the Sonny Bono Copyright Term Extension Act. This new law extended copyrights on corporate works to the author’s lifetime plus 95 years. The effort was driven by the Walt Disney Company, to protect its lucrative retail franchise around the animated character Mickey Mouse. Without this extension, Mickey would have entered the public domain, meaning anyone could create new cartoons and merchandise without fear of being sued by Disney. When the extension passed, it gave Disney another 20 years to profit from Mickey. The news sparked outrage from lawyers and academics at the time, but it was a dull and complex topic that most people didn’t understand or care about.
In 2020, Disney again lobbied to extend the law, so its copyright would last for 10,000 years. Its monopoly on our culture was complete. No art, music, video, or story would pass into the public domain for millennia. All copyrighted ideas would remain the private property of corporations. The quiet strangulation of our collective creativity had begun.
A small but powerful corporate collective called MalCorp took note of Disney’s success. Backed by deep-pocketed investors, MalCorp had quietly started buying the technology patents that made video streaming work over the internet. It revealed itself in 2021 as a protector of innovation. But its true goal was to create a monopoly on video streaming technology that would last forever, to shunt profits to its already wealthy investors. It was purely an instrument of greed.
Better Compression for Free
Now, there were some good guys in this story. As early as 2007, prescient tech companies wanted the web platform to remain free and open to all – especially for video. Companies like Cisco, Mozilla, Google, and others worked on new video codecs that could replace the patented, ubiquitous H.264 codec. They even combined their efforts in 2015 to create a royalty-free codec called AV1 that anyone could use free of charge.
AV1 was notable in that it offered better compression, and therefore better video quality, than any other codec of its time. But just as the free contender was getting off the ground, the video streaming industry was thrown into turmoil. Browser companies backed different codecs, and the market fragmented. Adoption stalled, and for years the streaming industry continued paying licensing fees for subpar codecs, even though better options were available.
The End of Shared Innovation
Meanwhile MalCorp found a way to tweak the law so its patents would never expire. It proposed a special amendment, just for patent pools, that said: Any time any part of any patent changes, the entire pool is treated as a new invention under U.S. law. With its deep pockets, MalCorp was able to buy the votes needed to get its law passed.
MalCorp’s patents would not expire. Not in 20 years. Not
Thousands of volunteers around the world contribute to Mozilla projects in a variety of capacities, and extension review is one of them. Reviewers check extensions submitted to addons.mozilla.org (AMO) for their safety, security, and adherence to Mozilla’s Add-on Policies.
Last year, we paused onboarding new volunteer extension reviewers while we updated the add-on policies and review processes to address changes introduced by the transition to the WebExtensions API and the new post-review process.
Now that the policies, processes and guidelines have been refreshed, we are re-opening applications for our volunteer reviewer program. If you are a skilled JavaScript developer, have experience developing browser extensions, and are interested in helping to keep the extension ecosystem safe and healthy, please consider contributing as a volunteer reviewer. You can learn more about the add-on reviewer program here.
If you are interested, please check out our wiki to learn how to apply. We will follow up with applicants shortly.
The post Volunteer Add-on Reviewer Applications Open appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2018/08/20/volunteer-add-on-reviewer-applications-open/
Today, Mozilla is filing our brief in Mozilla v. FCC – alongside other companies, trade groups, states, and organizations – to defend net neutrality rules against the FCC’s rollback that went into effect early this year. For the first time in the history of the public internet, the FCC has disavowed interest and authority to protect users from ISPs, who have both the incentives and means to interfere with how we access online content.
We are proud to be a leader in the fight for net neutrality both through our legal challenge in Mozilla v. FCC and through our deep work in education and advocacy for an open, equal, accessible internet. Users need to know that their access to the internet is not being blocked, throttled, or discriminated against. That means that the FCC needs to accept statutory responsibility in protecting those user rights — a responsibility that every previous FCC has supported until now. That’s why we’re suing to stop them from abdicating their regulatory role in protecting the qualities that have made the internet the most important communications platform in history.
This case is about your rights to access content and services online without your ISP blocking, throttling, or discriminating against your favorite services. Unfortunately, the FCC made this a political issue and followed party-lines rather than protecting your right to an open internet in the US. Our brief highlights how this decision is just completely flawed:
– The FCC order fundamentally mischaracterizes how internet access works. Whether based on semantic contortions or simply an inherent lack of understanding, the FCC asserts that ISPs simply don’t need to deliver websites you request without interference.
– The FCC completely renounces its enforcement ability and tries to delegate that authority to other agencies but only Congress can grant that authority, the FCC can’t decide it’s just not its job to regulate telecommunications services and promote competition.
– The FCC ignored the requirement to engage in a “reasoned decision making” process, ignoring much of the public record as well as their own data showing that consumers lack competitive choices for internet access, which gives ISPs the means to harm access to content and services online.
Additional Mozilla v. FCC briefs will be filed by various parties who are intervening or friends of the court through November. After that process is complete, oral arguments will take place and the court will rule.
Mozilla has been defending users’ access to the internet without interference from gatekeepers for almost a decade, both in the US and globally. Net neutrality is a core characteristic of the internet as we know it, and crucial for the economy and everyday lives. It is imperative that all internet traffic be treated equally, without discrimination against content or type of traffic — that’s how the internet was built and what has made it one of the greatest inventions of all time.
Brief below:
(As filed) Initial NG Petitioners Brief – Mozilla v FCC 20Aug2018
The post Mozilla files arguments against the FCC – latest step in fight to save net neutrality appeared first on The Mozilla Blog.
The current version of the Rust Language Server (RLS), 0.130.5, is the first 1.0 release candidate. It is available on nightly and beta channels, and from the 3rd September will be available with stable Rust.
1.0 for the RLS is a somewhat arbitrary milestone. We think the RLS can handle most small and medium size projects (notable, it doesn't work with Rust itself, but that is large and has a very complex build system), and we think it is release quality. However there are certainly limitations and many planned improvements.
It would be really useful if you could help us test the release candidate! Please report any crashes, or projects where the RLS gives no information or any bugs where it gives incorrect information.
The easiest way to install the RLS is to install an extension for your favourite editor, for example:
For most editors you will only need to have Rustup installed and the editor will install the rest.
What to expect
Syntax highlighting
Each editor does its own syntax highlighting
Code completion
Code completion is syntactic, performed by Racer. Because it is syntactic there are many instances where it is incomplete or incorrect. However, we believe it is useful.
Errors and warnings
Errors and other diagnostics are displayed inline. Exactly how the errors are presented depends on the editor.
Formatting
By Rustfmt (which is also at the 1.0 release candidate stage).
Clippy
Clippy is installed as part of the RLS. You can turn it on with a setting in your editor or with the usual crate attribute.
Code intelligence
The RLS can do the following:
- type and docs on hover (and sometimes signature info)
- goto definition
- find all references
- find all implementations for traits and concrete types
- find all symbols in the file/project
- renaming (this will not work where a renaming would cause an error, such as where the field initialisation syntax is used)
- change glob imports to list imports
These features will work for most identifiers, but won't work where identifiers are defined in a macro (and sometimes when used in a macro use). They also won't work for identifiers in module paths, except for the last part, e.g., in foo::bar::baz, the RLS has information about baz, but not foo or bar.
 Over time, we've slowly been adjusting the curl project and its documentation so that we might at some point actually qualify to the CII open source Best Practices at silver level.
Over time, we've slowly been adjusting the curl project and its documentation so that we might at some point actually qualify to the CII open source Best Practices at silver level.
We qualified at the base level a while ago as one of the first projects which did that.
Recently, one of those issues we fixed was documenting the governance of the curl project. How exactly the curl project is run, what the key roles are and how decisions are made. That document is now in our git repo.
curl
The curl project is what I would call a fairly typical smallish open source project with a quite active and present project leader (me). We have a small set of maintainers who independently are allowed to and will merge commits to git (via pull-requests).
Any decision or any code change that was done or is about to be done can be brought up for questioning or discussion on the mailing list. Nothing is ever really seriously written in stone (except our backwards compatible API). If we did the wrong decision in the past, we should reconsider now.
Oh right, we also don't have any legal entity. There's no company or organization behind this or holding any particular rights. We're not part of any umbrella organization. We're all just individuals distributed over the globe.
Contributors
No active contributor or maintainer (that I know of) gets paid to work on curl regularly. No company has any particular say or weight to decide where the project goes next.
Contributors fix bugs and add features as part of our daily jobs or in their spare time. We get code submissions for well over a hundred unique authors every year.
Dictator
As a founder of the project and author of more than half of all commits, I am what others call, a Benevolent Dictator. I can veto things and I can merge things in spite of objections, although I avoid that as far as possible.
I feel that I generally have people's trust and that the community expects me to be able to take decisions and drive this project in an appropriate direction, in a fashion that has worked out fine for the past twenty years.
I post all my patches (except occasional minuscule changes) as pull-requests on github before merge, to allow comments, discussions, reviews and to make sure they don't break any tests.
I announce and ask for feedback for changes or larger things that I want to do, on the mailing list for wider attention. To bring up discussions and fish for additional ideas or for people to point out obvious mistakes. May times, my calls for opinions or objections are met with silence and I will then take that as "no objections" and more forward in a way I deem sensible.
Every now and then I blog about specific curl features or changes we work on, to highlight them and help out the user community "out there" to discover and learn what curl can do, or might be able to do soon.
I'm doing this primarily on my spare time. My employer also lets me spend some work hours on curl.
Long-term
One of the prime factors that has made curl and libcurl successful and end up one of the world's most widely used software components, I'm convinced, is that we don't break stuff.
By this I mean that once we've introduced functionality, we struggle hard to maintain that functionality from that point on and into the future. When we accept code and features into the project, we do this knowing that the code will likely remain in our code for decades to come. Once we've accepted the code, it becomes our responsibility and now we'll care for it dearly for a long time forward.
Since we're so few developers and maintainers in the project, I can also add that I'm very much aware that in many cases adopting code and merging patches mean that I will have to fix the remaining bugs and generally care for the code the coming years.
Changing governance?
I'm dictator of the curl project for practical reasons, not because I consider it an ideal way to run projects. If there were more people involved who cared enough about what and how we're doing things we could also change how we run the project.
But until I sense such an interest, I don't think the current model is bad - and our conquering the world over the recent years could also be seen as a proof that the project at least sometimes also goes in a direction that users approve
Bitslicing, in cryptography, is the technique of converting arbitrary functions into logic circuits, thereby enabling fast, constant-time implementations of cryptographic algorithms immune to cache and timing-related side channel attacks.
My last post Bitslicing, An Introduction showed how to convert an S-box function into truth tables, then into a tree of multiplexers, and finally how to find the lowest possible gate count through manual optimization.
Today’s post will focus on a simpler and faster method. Karnaugh maps help simplifying Boolean algebra expressions by taking advantage of humans’ pattern-recognition capability. In short, we’ll bitslice an S-box using K-maps.
A tiny S-box
Here again is the 3-to-2-bit S-box function from the previous post.
uint8_t SBOX[] = { 1, 0, 3, 1, 2, 2, 3, 0 };
An AES-inspired S-box that interprets three input bits as a polynomial in GF(23) and computes its inverse mod P(x) = x3 + x2 + 1, with 0-1 := 0. The result plus (x2 + 1) is converted back into bits and the MSB is dropped.
This S-box can be represented as a function of three Boolean variables, where f(0,0,0) = 0b01, f(0,0,1) = 0b00, f(0,1,0) = 0b11, etc. Each output bit can be represented by its own Boolean function where fL(0,0,0) = 0 and fR(0,0,0) = 1, fL(0,0,1) = 0 and fR(0,0,1) = 0, …
A truth table per output bit
Each output bit has its own Boolean function, and therefore also its own thruth table. Here are the truth tables for the Boolean functions fL(a,b,c) and fR(a,b,c):
abc | SBOX abc | f_L() abc | f_R() -----|------ -----|------- -----|------- 000 | 01 000 | 0 000 | 1 001 | 00 001 | 0 001 | 0 010 | 11 010 | 1 010 | 1 011 | 01 ---> 011 | 0 + 011 | 1 100 | 10 100 | 1 100 | 0 101 | 10 101 | 1 101 | 0 110 | 11 110 | 1 110 | 1 111 | 00 111 | 0 111 | 0
Whereas previously at this point we built a tree of multiplexers out of each truth table, we’ll now build a Karnaugh map (K-map) per output bit.
Karnaugh Maps
The values of fL(a,b,c) and fR(a,b,c) are transferred onto a two-dimensional grid with the cells ordered in Gray code. Each cell position represents one possible combination of input bits, while each cell value represents the value of the output bit.

The row and column indices (a) and (b || c) are ordered in Gray code rather than

It's mostly more bug fixes this week, and starting on some cool new features, but first we want to tell you about an exciting competition that launched this week.
On Monday Andrzej Mazur launched the 2018 edition of the JS13KGames competition. As the name suggests, you have to create a game using only thirteen kilobytes of Javascript (zipped) or less. Check out some of last year's winners to see what is possible in 13k.
This year Mozilla is sponsoring the new WebXR category, which lets you use A-Frame or Babylon.js without counting towards the 13k. See the full rules for details. Prizes this year includes the Oculus Go for the top three champions.
Browsers
We demoed Firefox Reality at the Mozilla Gigabit event in Mountain View on 8/15. The Mozilla Gigabit Community Fund provides grant funding in select U.S. communities to support pilot tests of gigabit technologies such as virtual reality, 4K video, artificial intelligence, and their related curricula.
The GeckoView team added APIs for overriding screen size and display DPI, which will enable more UI customization in the future. We also did more work to improve model load times, plus general performance fixes.
Did you know you can see everything that goes into Firefox Reality in the Github? Every bug and commit is available for you to see.
Social
Tons of bug fixes for stability, performance, and fixes of the drawing tool.
See you next week!
Sometimes, the exact layout of objects in memory becomes very important. Some situations you may encounter: When overlaying different types as “views” of the same memory location, perhaps via reinterpret_cast, unions, or void*-casting. You want to know where the field in one view lands in another. When examining a struct layout’s packing, to see if […]
https://blog.mozilla.org/sfink/2018/08/17/type-examination-in-gdb/
WeTransfer offers a simple, extensions-based file transferring solution.
When we want to share digital files, most people think of popular file hosting services like Box or Dropbox, or other common methods such as email and messaging apps. But did you know there are easier—and more privacy-focused—ways to do it with extensions? WeTransfer and Fire File Sender are two intriguing extension options.
WeTransfer allows you to send files up to 2GB in size with a link that expires seven days from upload. It’s really simple to use—just click the toolbar icon and a small pop-up appears inviting you to upload files and copy links for sharing. WeTransfer uses the highest security standards and is compliant with EU privacy laws. Better still, recipients downloading files sent through WeTransfer won’t get bombarded with advertisements; rather, they’ll see beautiful wallpapers picked by the WeTransfer editorial team. If you’re interested in additional eye-pleasing backgrounds, check out WeTransfer Moment.
Fire File Sender allows you to send files up to 4GB each. Once the file is successfully uploaded, a link and a six-digit code is generated for you to share. The link and code will expire 10 minutes after upload or after one download—whichever occurs first. Also, within the 10-minute time frame, you have the ability to stop sharing the file. Fire File Sender uses the browser sidebar for the uploading and downloading of files through Send Anywhere APIs.
Best of all, neither WeTransfer, nor Fire File Sender require an account to use their service. The enhanced anonymity of the file exchange, plus the automatic deletion of files (Dropbox and Google require manual deletion), make these extensions strong choices for privacy-minded folks.
I should also mention Firefox Send, though it’s a web service and not an extension. Firefox Send is Mozilla’s home-grown solution to file sharing. Created by the Mozilla Test Pilot team, Firefox Send allows you to securely share files up to 1GB in size directly from your browser. Any links generated will either expire after one download or 24 hours, whichever comes first. Taking privacy matters even further, files distributed through Firefox Send are encrypted directly in the browser and then uploaded to Mozilla. Mozilla does not have the ability to access the content of the encrypted file. (The Test Pilot team constantly strives to improve on their project; its development progress can be viewed on GitHub.)
The post Share files easily with extensions appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2018/08/17/share-files-easily-with-extensions/
AddressSanitizer has worked in rr for a while. I just found that LeakSanitizer wasn't working and landed a fix for that. This means you can record an ASAN build and if there's an ASAN error, or LSAN finds a leak, you can replay it in rr knowing the exact addresses of the data that leaked — along with the usual rr goodness of reverse execution, watchpoints, etc. Well, hopefully. Report an issue if you find more problems.
Interestingly, LSAN doesn't work under gdb, but it does work under rr! LSAN uses the ptrace() API to examine threads when it looks for leaks, and it can't ptrace a thread that gdb is already ptracing (the ptrace design deeply relies on there being only one ptracer per thread). rr uses ptrace too, but when one rr tracee thread tries to ptrace another rr tracee thread, rr emulates the ptrace calls so that they work as if rr wasn't present.
http://robert.ocallahan.org/2018/08/asan-and-lsan-work-in-rr.html
Step 0: Have a current working build environment for building Firefox for Android for a recent checkout of mozilla-central.
Step 1: Figure out when the revision you are interested in was checked in. hg log -r will give you a date of the checkin.
Step 2: Check the revision history of the Simple Firefox for Android build guide you want to find a revision slightly before the date from step 1. At the bottom of the page “Required Android SDK and NDK versions” use this section as a reference for the next several steps.
Step 3. Install the version of the Android SDK Platform listed on the DevMo page. Via Android Studio’s SDK manager. Tools -> SDK Manager -> SDK Platforms -> mark the API version you need -> click apply
Step 4. Install the SDK build tools using Android Studio’s SDK manager. Tools -> SDK Manager -> SDK Tools -> mark the SDK build tools version you need -> click apply
Step 5. Get the correct NDK from Google’s archives. Then extract it to where you store your NDKs. $HOME/.mozbuild is the default.
Step 6. Get the Android SDK tools. This can be a real pain as Google does not have links to download this. You will need to craft your own version of the URL. The URL format is https://dl.google.com/android/repository/tools_r Where version matches the “Android SDK Tools” line from DevMo and operating system is macosx or linux. Example https://dl.google.com/android/repository/tools_r23.0.1-linux.zip
Step 7. Create a copy of the SDK, delete the tools directory and place the folder from the Android SDK Tools download step 6 above in that folder. Example $HOME/.mozbuild/android-sdk-linux-23.0.1/
Step 8. Update your .mozconfig to point to the older NDK and SDK versions
# Build Firefox for Android:
ac_add_options --enable-application=mobile/android
ac_add_options --target=arm-linux-androideabi
# With the following Android SDK and NDK:
ac_add_options --with-android-sdk="/absolute/path/to/android-sdk-linux-23.0.1"
ac_add_options --with-android-ndk="/absolute/path/to/android-ndk-r11c"
Step 9. ./mach build
./mach package
./mach install
./mach run
Brazil’s newly passed data protection law is a huge step forward in the protection of user privacy. It’s great to see Brazil, long a champion of digital rights, join the ranks of countries with data protection laws on the books. We are concerned, however, about President Temer’s veto of several provisions, including the Data Protection Authority. We urge the President and Brazilian policymakers to swiftly advance new legislation or policies to ensure effective enforcement of the law.
The post Brazilian data protection is strong step forward, action needed on enforcement appeared first on Open Policy & Advocacy.
[ https://www.youtube.com/embed/JEpsKnWZrJ8 ]
I riffed on this a bit over at twitter some time ago; this has been sitting in the drafts folder for too long, and it’s incomplete, but I might as well get it out the door. Feel free to suggest additions or corrections if you’re so inclined.
You may have seen this list of latency numbers every programmer should know, and I trust we’ve all seen Grace Hopper’s classic description of a nanosecond at the top of this page, but I thought it might be a bit more accessible to talk about CPU-scale events in human-scale transactional terms. So: if a single CPU cycle on a modern computer was stretched out as long as one of our absurdly tedious human seconds, how long do other computing transactions take?
If a CPU cycle is 1 second long, then:
- Getting data out of L1 cache is about the same as getting your data out of your wallet; about 3 seconds.
- At 9 to 10 seconds, getting data from L2 cache is roughly like asking your friend across the table for it.
- Fetching data from the L3 cache takes a bit longer – it’s roughly as fast as having an Olympic sprinter bring you your data from 400 meters away.
- If your data is in RAM you can get it in about the time it takes to brew a pot of coffee; this is how long it would take a world-class athlete to run a mile to bring you your data, if they were running backwards.
- If your data is on an SSD, though, you can have it six to eight days, equivalent to having it delivered from the far side of the continental U.S. by bicycle, about as fast as that has ever been done.
- In comparison, platter disks are delivering your data by horse-drawn wagon, over the full length of the Oregon Trail. Something like six to twelve months, give or take.
- Network transactions are interesting – platter disk performance is so poor that fetching data from your ISP’s local cache is often faster than getting it from your platter disks; at two to three months, your data is being delivered to New York from Beijing, via container ship and then truck.
- In contrast, a packet requested from a server on the far side of an ocean might as well have been requested from the surface of the moon, at the dawn of the space program – about eight years, from the beginning of the Apollo program to Armstrong, Aldrin and Collin’s successful return to earth.
- If your data is in a VM, things start to get difficult – a virtualized OS reboot takes about the same amount of time as has passed between the Renaissance and now, so you would need to ask Leonardo Da Vinci to secretly encode your information in one of his notebooks, and have Dan Brown somehow decode it for you in the present? I don’t know how reliable that guy is, so I hope you’re using ECC.
- That’s all if things go well, of course: a network timeout is roughly comparable to the elapsed time between the dawn of the Sumerian Empire and the present day.
- In the worst case, if a CPU cycle is 1 second, cold booting a racked server takes approximately all of recorded human history, from the earliest Indonesian cave paintings to now.
Highlights
- New Onboarding experience in Firefox 62 currently only as an experiment.
-
Totally adorable onboarding critters (Scientific name: Totes Adorbs Familiaris)
-
- The new about:policies helps administrators verify if they have configured policies correctly, learn more about the different policies, and resolve errors.
-
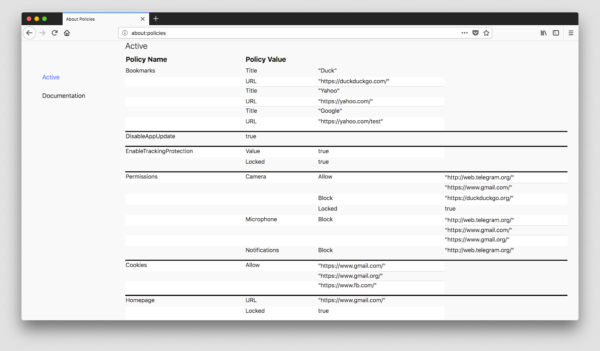
about:policies, coming soon!
-
- About:performance UI is currently being updated, currently behind a pref more details in the bug 1477677
-
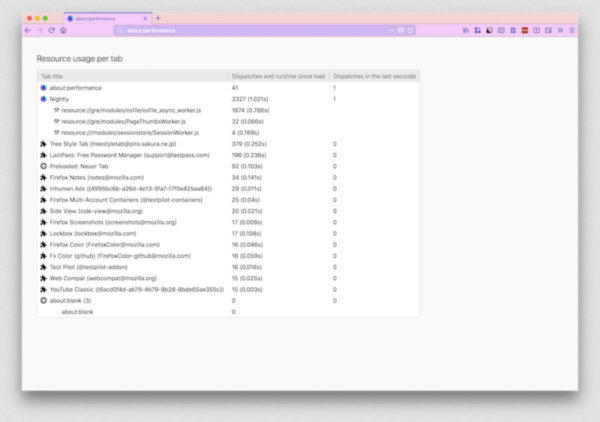
The new about:performance will show you what pages are draining your system resources
-
- Doug Thayer pushed the ClientStorage work through the finish line! This should improve responsiveness and (maybe) power usage on macOS. This should also allow tab warming to ride to release on macOS!



Project Updates
Add-ons / Web Extensions
- Kris fixed an issue with starting extensions while a content process is hung and a crash from webRequest stream filters.
- Luca did further work on migrating the storage API to IndexedDB.
- Oriol fixed several issues with extension icons.
- Tim fixed themes on Android.
Browser Architecture
- XUL/XBL Replacement Newsletter #6 posted.
- Browser console is now loaded as a html document.
- getElementsByAttribute[NS] now works on (chrome) HTML documents.
- Added document.createXULElement. No namespace funkiness!
- Working on a plan to either remove broadcaster/observers or support them in HTML.
- Investigating feasibility of landing rkv as NPOTB so potential consumers can investigate it for suitability to their use cases (bug 1445451).
Lint
- We are switching most ChromeUtils.import calls to be treated as explicit variable declarations by ESLint. This has the advantage of triggering no-unused-vars more often (especially in jsm files), to find unused imports.
In this series we are covering projects that explore what is possible when the web becomes decentralized or distributed. These projects aren’t affiliated with Mozilla, and some of them rewrite the rules of how we think about a web browser. What they have in common: These projects are open source, and open for participation, and share Mozilla’s mission to keep the web open and accessible for all.
The web is healthy when the financial cost of self-expression isn’t a barrier. In this installment of the Dweb series we’ll learn about WebTorrent – an implementation of the BitTorrent protocol that runs in web browsers. This approach to serving files means that websites can scale with as many users as are simultaneously viewing the website – removing the cost of running centralized servers at data centers. The post is written by Feross Aboukhadijeh, the creator of WebTorrent, co-founder of PeerCDN and a prolific NPM module author… 225 modules at last count! –Dietrich Ayala
What is WebTorrent?
WebTorrent is the first torrent client that works in the browser. It’s written completely in JavaScript – the language of the web – and uses WebRTC for true peer-to-peer transport. No browser plugin, extension, or installation is required.
Using open web standards, WebTorrent connects website users together to form a distributed, decentralized browser-to-browser network for efficient file transfer. The more people use a WebTorrent-powered website, the faster and more resilient it becomes.

Architecture
The WebTorrent protocol works just like BitTorrent protocol, except it uses WebRTC instead of TCP or uTP as the transport protocol.
In order to support WebRTC’s connection model, we made a few changes to the tracker protocol. Therefore, a browser-based WebTorrent client or “web peer” can only connect to other clients that support WebTorrent/WebRTC.
Once peers are connected, the wire protocol used to communicate is exactly the same as in normal BitTorrent. This should make it easy for existing popular torrent clients like Transmission, and uTorrent to add support for WebTorrent. Vuze already has support for WebTorrent!

Getting Started
It only takes a few lines of code to download a torrent in the browser!
To start using WebTorrent, simply include the webtorrent.min.js script on your page. You can download the script from the WebTorrent website or link to the CDN copy.
This provides a WebTorrent function on the window object. There is also an
npm package available.
var client = new WebTorrent()
// Sintel, a free, Creative Commons movie
var torrentId = 'magnet:...' // Real torrent ids are much longer.
var torrent = client.add(torrentId)
torrent.on('ready', () => {
// Torrents can contain many files. Let's use the .mp4 file
var file = torrent.files.find(file => file.name.endsWith('.mp4'))
// Display the file by adding it to the DOM.
// Supports video, audio, image files, and more!
file.appendTo('body')
})
That’s it! Now you’ll see the torrent streaming into a tag in the webpage!
Learn more
You can learn more at webtorrent.io, or by asking a question in #webtorrent on Freenode IRC or on Gitter. We’re looking for more people who can answer questions and help people with issues on the GitHub issue tracker. If you’re a friendly, helpful person and want an excuse to dig deeper into the torrent protocol or WebRTC, then this is your chance!
Bitslicing (in software) is an implementation strategy enabling fast, constant-time implementations of cryptographic algorithms immune to cache and timing-related side channel attacks.
This post intends to give a brief overview of the general technique, not requiring much of a cryptographic background. It will demonstrate bitslicing a small S-box, talk about multiplexers, LUTs, Boolean functions, and minimal forms.
What is bitslicing?
Matthew Kwan coined the term about 20 years ago after seeing Eli Biham present his paper A Fast New DES Implementation in Software. He later published Reducing the Gate Count of Bitslice DES showing an even faster DES building on Biham’s ideas.
The basic concept is to express a function in terms of single-bit logical operations – AND, XOR, OR, NOT, etc. – as if you were implementing a logic circuit in hardware. These operations are then carried out for multiple instances of the function in parallel, using bitwise operations on a CPU.
In a bitsliced implementation, instead of having a single variable storing a, say, 8-bit number, you have eight variables (slices). The first storing the left-most bit of the number, the next storing the second bit from the left, and so on. The parallelism is bounded only by the target architecture’s register width.
What’s it good for?
Biham applied bitslicing to DES, a cipher designed to be fast in hardware. It uses eight different S-boxes, that were usually implemented as lookup tables. Table lookups in DES however are rather inefficient, since one has to collect six bits from different words, combine them, and afterwards put each of the four resulting bits in a different word.
Speed
In classical implementations, these bit permutations would be implemented with a combination of shifts and masks. In a bitslice representation though, permuting bits really just means using the “right” variables in the next step; this is mere data routing, which is resolved at compile-time, with no cost at runtime.
Additionally, the code is extremely linear so that it usually runs well on heavily pipelined modern CPUs. It tends to have a low risk of pipeline stalls, as it’s unlikely to suffer from branch misprediction, and plenty of opportunities for optimal instruction reordering for efficient scheduling of data accesses.
Parallelization
With a register width of n bits, as long as the bitsliced implementation is no more than n times slower to run a single instance of the cipher, you end up with a net gain in throughput. This only applies to workloads that allow for parallelization. CTR and ECB mode always benefit, CBC and CFB mode only when decrypting.
Constant execution time
Constant-time, secret independent computation is all the rage in modern applied cryptography. Bitslicing is interesting because by using only single-bit logical operations the resulting code is immune to cache and timing-related side channel attacks.
Fully Homomorphic Encryption
The last decade brought great advances in the field of Fully Homomorphic Encryption (FHE), i.e. computation on ciphertexts. If you have a secure crypto scheme and an efficient NAND gate you can use bitslicing to compute arbitrary functions of encrypted data.
Bitslicing a small S-box
Let’s work through a small example to see how one could go about converting arbitrary functions into a bunch of Boolean gates.
Imagine a 3-to-2-bit S-box function, a
component found in many symmetric encryption algorithms. Naively, this would be
represented by a lookup table with eight entries, e.g. SBOX[0b000] = 0b01,
SBOX[0b001] = 0b00, etc.
uint8_t SBOX[] = { 1, 0, 3, 1, 2, 2, 3, 0 };
This AES-inspired S-box interprets three input bits as a polynomial in GF(23) and computes its inverse mod P(x) = x3 + x2 +