happy bmo push day (last friday)
(a few things went out on friday because of some API breakage, and didn’t get posted. woops)
the following changes have been pushed to bugzilla.mozilla.org:
Due to a long list of documented issues, Mozilla previously announced our intent to distrust TLS certificates issued by the Symantec Certification Authority, which is now a part of DigiCert. On August 13th, the next phase of distrust was enabled in Firefox Nightly. In this phase, all TLS certificates issued by Symantec (including their GeoTrust, RapidSSL, and Thawte brands) are no longer trusted by Firefox (with a few small exceptions).
In my previous update, I pointed out that many popular sites are still using these certificates. They are apparently unaware of the planned distrust despite DigiCert’s outreach, or are waiting until the release date that was communicated in the consensus plan to finally replace their Symantec certificates. While the situation has been improving steadily, our latest data shows well over 1% of the top 1-million websites are still using a Symantec certificate that will be distrusted.
 Unfortunately, because so many sites have not yet taken action, moving this change from Firefox 63 Nightly into Beta would impact a significant number of our users. It is unfortunate that so many website operators have waited to update their certificates, especially given that DigiCert is providing replacements for free.
Unfortunately, because so many sites have not yet taken action, moving this change from Firefox 63 Nightly into Beta would impact a significant number of our users. It is unfortunate that so many website operators have waited to update their certificates, especially given that DigiCert is providing replacements for free.
We prioritize the safety of our users and recognize the additional risk caused by a delay in the implementation of the distrust plan. However, given the current situation, we believe that delaying the release of this change until later this year when more sites have replaced their Symantec TLS certificates is in the overall best interest of our users. This change will remain enabled in Nightly, and we plan to enable it in Firefox 64 Beta when it ships in mid-October.
We continue to strongly encourage website operators to replace Symantec TLS certificates immediately. Doing so improves the security of their websites and allows the 10’s of thousands of Firefox Nightly users to access them.
The post Delaying Further Symantec TLS Certificate Distrust appeared first on Mozilla Security Blog.
https://blog.mozilla.org/security/2018/10/10/delaying-further-symantec-tls-certificate-distrust/
The Reps program is evolving in order to be aligned with Mozilla’s changes on how we perceive communities. Part of those changes is the Mission Driven Mozillians project, where the Reps are involved.
We (the Reps Council) believe that the Reps program has a natural place inside this project because of the experience, skills and knowledge on leading, growing and helping communities on their daily life.
Based on the work that has been done in the Mission Driven Mozillians project (video: https://discourse.mozilla.org/t/a-quick-video-intro-to-mission-driven-mozillians/25912), two types of volunteer leadership have been identified:
- Volunteers who have been identified inside the community as experts based on their knowledge and skills on a specific functional area – functional area experts
- Volunteers who have been identified as experts based on their ability to coordinate, support and expand communities – community coordinators.
For the first category, functional areas are able to easily identify the right fit for the position based on different knowledge criterias and years of experience in the project. However, for the second category there is not a well defined role nor a set of guidelines for volunteers that were interested in community building. As a result, historically, people from the first category took over the community coordinator roles without necessarily being properly trained for it.
For that reason, the Reps Council has worked on a definition of the community coordinator role, since we believe that the Reps are a natural fit for this role.
Suggested definition of community coordinator role:
Community coordinator volunteers are aligned and committed Mozillians who are interested in:
- finding and connecting new talent with Mozilla projects they are contributing to
- developing communities on a functional and/or local level
- supporting local communities and Mozilla to have an effective and decentralized environment for contribution
- creating collaborations with other local communities in an effort to spread Mozilla’s mission and expand Mozilla’s outreach in the open source ecosystem
In order to be able to describe the responsibilities of the role more, we have specified how the role is going to look like based on the agreements the Mission Driven Mozillians group has crafted.
Where people hold coordinating roles, they should be reviewed regularly
- This creates opportunities for new, diverse leaders to emerge.
- Ensures continuous support from the communities they serve.
- Prevents toxic individuals from maintaining power indefinitely.
- Allows space for individuals to receive feedback and support to better thrive in their role.
What does that mean for Community Experts?
- All Community experts and any volunteers that hold roles within this group have fixed terms and are reviewed regularly. Established processes will help contributors give feedback and review these roles.
Responsibilities should be clearly communicated and distributed
- Creates more opportunities for more people.
- Avoids gatekeeping and power accumulation.
- Reduces burnout and over reliance on an individual by sharing accountability.
- Creates leadership pathways for new people.
- Potentially increases diversity.
- An emphasis on responsibility over title avoids unnecessary “authority labels”.
What does that mean for the Community Experts?
- All Community experts have public role descriptions that articulate clearly their responsibilities and have a culture of delegating them when needed across their co-volunteers.
When people are in a coordinating role, they should abide by standards, and be accountable for fulfilling their responsibilities
- This builds confidence and support for individuals and these roles from community members and staff.
- Ensures that everyone has shared clarity on expectations and success.
- Creates an environment where the CPG is applied consistently.
- Increases the consistency in roles across the organization .
What does that mean for the Community Experts?
- All Community experts should keep their activities public and visible to everyone
New innovation challenge is looking for an algorithm to automate bug triaging in Bugzilla

We are excited to announce the launch of the Bugzilla Automatic Bug Triaging Challenge, a crowdsourcing competition sponsored by Mozilla and hosted by Topcoder, the world’s largest network of software designers, developers, testers, and data scientists. The goal of the competition is to automate triaging (categorization by products and software components) of new bugs submitted to Bugzilla, Mozilla’s web-based bug tracking system. By cooperating with Topcoder, Mozilla is expanding its open innovation capabilities to include specialized crowdsourcing communities and competition mechanisms.
Mozilla’s Open Innovation strategy is guided by the principle of being Open by Design derived from a comprehensive 2017 review of how Mozilla works with open communities. The strategy sets forth a direction of expanding the organisation’s external outreach beyond its traditional base of core contributors: open source software developers, lead users, and Mozilla volunteers. Our cooperation with Topcoder is an example of reaching out to a global community of data scientists.
Why Bugs?
Mozilla is using crowdsourcing to scale the effort we can bring to our product and technology development through collaborative crowds. Such a “capacity crowdsourcing” has already been successfully applied to the Common Voice project, Mozilla’s initiative to crowdsource a large dataset of human voices for use in speech technology.
However, we know that engaging crowds can have positive impact on other areas of Mozilla product and technology development. In particular, we focus our attention on processes that require large amounts of manual engineering work; automating these processes can result in significant lowering of development and operating cost.
Take, for example, bug triaging in Bugzilla, a manual process of categorization (by products and software components) of hundreds of bugs submitted each month to Mozilla’s web-based bug tracking system. Although the accuracy of the manual bug triaging is very high, it consumes valuable time of experienced engineers, which may otherwise be spent on other high-priority projects.
Why Topcoder?
Over years, the Firefox Test Engineering team responsible for bug triaging has accumulated a lot of data that could potentially be used to automate the process. Working together with the Open Innovation team, the engineers have engaged Topcoder, the world’s largest network of software designers, developers, testers, and data scientists, which many organizations, including NASA, use as a platform to solve complex algorithmic problems.
The result of this collaboration has been the Bugzilla Automatic Bug Triaging Challenge whose objective is to create an algorithm allowing automated bug triaging in Bugzilla with the accuracy comparable to that for the manual process. To select the winners of the competition, the Topcoder architect team has developed a scoring mechanism; to qualify for a prize (ranging between $1,000 and $8,000), any algorithm must reach a certain minimal score. Refer to the Challenge description for more detail.
The Challenge will be open for submissions until October 26. Although Mozilla employees are not allowed to participate, we do encourage all members of Mozilla’s communities to take part in the competition.
Taming triage: Partnering with Topcoder to harness the power of the crowd was originally published in Mozilla Open Innovation on Medium, where people are continuing the conversation by highlighting and responding to this story.
The Responsible Computer Science Challenge — by Omidyar Network, Mozilla, Schmidt Futures, and Craig Newmark Philanthropies — calls on professors to integrate ethics into undergraduate computer science courses
With great code comes great responsibility.
Today, computer scientists wield tremendous power. The code they write can be used by billions of people, and influence everything from what news stories we read, to what personal data companies collect, to who gets parole, insurance or housing loans
Software can empower democracy, heighten opportunity, and connect people continents away. But when it isn’t coupled with responsibility, the results can be drastic. In recent years, we’ve watched biased algorithms and broken recommendation engines radicalize users, promote racism, and spread misinformation.
That’s why Omidyar Network, Mozilla, Schmidt Futures, and Craig Newmark Philanthropies are launching the Responsible Computer Science Challenge: an ambitious initiative to integrate ethics and accountability into undergraduate computer science curricula and pedagogy at U.S. colleges and universities, with up to $3.5 million in prizes.
Says Kathy Pham, computer scientist and Mozilla Fellow co-leading the challenge:
“In a world where software is entwined with much of our lives, it is not enough to simply know what software can do. We must also know what software should and shouldn’t do, and train ourselves to think critically about how our code can be used. Students of computer science go on to be the next leaders and creators in the world, and must understand how code intersects with human behavior, privacy, safety, vulnerability, equality, and many other factors.”
Pham adds: “Just like how algorithms, data structures, and networking are core computer science classes, we are excited to help empower faculty to also teach ethics and responsibility as an integrated core tenet of the curriculum.”
Pham is currently a Senior Fellow and Adjunct Lecturer at Harvard University, and an alum of Google, IBM, and the United States Digital Service at the White House. She will work closely with Responsible Computer Science applicants and winners.
Says Paula Goldman, Global Lead of the Tech and Society Solutions Lab at Omidyar Network: “To ensure technology fulfills its potential as a positive force in the world, we are supporting the growth of a tech movement that is guided by the emerging mantra to move purposefully and fix things. Treating ethical reflection and discernment as an opt-in sends the wrong message to computer science students: that ethical thinking can be an ancillary exploration or an afterthought, that it’s not part and parcel of making code in the first place. Our hope is that this effort helps ensure that the next generation of tech leaders is deeply connected to the societal implications of the products they build.”
Says Craig Newmark, founder of craigslist and Craig Newmark Philanthropies: “As an engineer, when you build something, you can’t predict all of the consequences of what you’ve made; there’s always something. Nowadays, we engineers have to understand the importance and impact of new technologies. We should aspire to create products that are fair to and respectful of people of all backgrounds, products that make life better and do no harm.”
Says Thomas Kalil, Chief Innovation Officer at Schmidt Futures: “Information and communication technologies are transforming our economy, society, politics, and culture. It is critical that we equip the next generation of computer scientists with the tools to advance the responsible development of these powerful technologies – both to maximize the upside and understand and manage the risks.”
Says Mary L. Gray, a Responsible Computer Science Challenge judge: “Computer science and engineering have deep domain expertise in securing and protecting data. But when it comes to drawing on theories and methods that attend to people’s ethical rights and social needs, CS and engineering programs are just getting started. This challenge will help the disciplines of CS and engineering identify the best ways to teach the next generation of technologists what they need to know to build more socially responsible and equitable technologies for the future.”
(Gray is senior researcher at Microsoft Research; fellow at Harvard University’s Berkman Klein Center for Internet & Society; and associate professor in the
Using Bookmarks in Firefox for iOS is relatively simple. When visiting a page, you can add it to your bookmarks list. When you pull up your list, the page title will appear as one of the list items. In some cases, the page title or URL may not be exactly what you want to bookmark. For example, if I go to Dark Sky and bookmark it, the bookmark URL will include my current GPS coordinates, and the bookmark title will include my current address.
But I don’t want the bookmark to be specific to my location! In Firefox for iOS, there doesn’t appear to be a way to edit the bookmark title and URL…or is there?
To edit Firefox for iOS bookmarks, you’ll need to edit them on the Windows/Mac/Linux version (aka Desktop).
- If you don’t already have a Firefox account set up, set it up and sync your bookmarks to the desktop version of Firefox.
- Open Firefox on your desktop and open the Library window.
Click the Library button , then go to Bookmarks and click Show All Bookmarks.
, then go to Bookmarks and click Show All Bookmarks. - In the sidebar, select Mobile Bookmarks. It should be the last item in the list. That folder contains your Firefox for iOS bookmarks.
- Edit your mobile bookmarks. You can even add folders!
Your bookmarks in Firefox for iOS should be automatically updated.

http://ilias.ca/blog/2018/10/how-to-edit-firefox-for-ios-bookmarks/
Providing a web browser that you can depend on year after year is one of the core tenet of the Firefox security strategy. We put a lot of time and energy into making sure that the software you run has not been tampered with while being delivered to you.
In an effort to increase trust in Firefox, we regularly partner with external firms to verify the security of our products. Earlier this year, we hired X41 D-SEC Gmbh to audit the mechanism by which Firefox ships updates, known internally as AUS for Application Update Service. Today, we are releasing their report.
Four researchers spent a total of 27 days running a technical security review of both the backend service that manages updates (Balrog) and the client code that updates your browser. The scope of the audit included a cryptographic review of the update signing protocol, fuzzing of the client code, pentesting of the backend and manual code review of all components.
Mozilla Security continuously reviews and tests the security of Firefox, but external verification is a critical part of our operations security strategy. We are glad to say that X41 did not find any critical flaw in AUS, but they did find various issues ranking from low to high, as well as 21 side findings.
X41 D-Sec GmbH found the security level of AUS to be good. No critical vulnerabilities have been identified in any of the components. The most serious vulnerabilities that were discovered are a Cross-Site Request Forgery (CSRF) vulnerability in the administration web application interface that might allow attackers to trigger unintended administrative actions under certain conditions. Other vulnerabilities identified were memory corruption issues, insecure handling of untrusted data, and stability issues (Denial of Service (DoS)). Most of these issues were constrained by requiring to bypass cryptographic signatures.
Three vulnerabilities ranked as high, and all of them were located in the administration console of Balrog, the backend service of Firefox AUS, which is protected behind multiple factors of authentication inside our internal network. The extra layers of security effectively lower the risk of the vulnerabilities found by X41, but we fixed the issues they found regardless.
X41 found a handful of bugs in the C code that handles update files. Thankfully, the cryptographic signatures prevent a bad actor from crafting an update file that could impact Firefox. Here again, designing our systems with multiple layers of security has proven useful.
Today, we are making the full report accessible to everyone in an effort to keep Firefox open and transparent. We are also opening up our bug tracker so you can follow our progress in mitigating the issues and side findings identified in the report.
Finally, we’d like to thank X41 for their high quality work on conducting this security audit. And, as always, we invite you to help us keep Firefox secure by reporting issues through our bug bounty program.
The post Trusting the delivery of Firefox Updates appeared first on Mozilla Security Blog.
https://blog.mozilla.org/security/2018/10/09/trusting-the-delivery-of-firefox-updates/
TenFourFox Feature Parity 10 beta 1 is now available (downloads, hashes, release notes). This version is mostly about expanded functionality, adding several new DOM and JavaScript ES6 features, and security changes to match current versions of Firefox. Not everything I wanted to get done for this release got done, particularly on the JavaScript side (only one of the ES6 well-known symbols updates was finished in time), but with Firefox 63 due on the 22nd we'll need this period for sufficient beta testing, so here it is.
The security changes include giving document-level (i.e., docshell) data: URIs unique origins to reduce cross-site scripting attack surface (for more info, see this Mozilla blog post from Fx57). This middle ground should reduce issues with the older codebase and add-on compatibility problems, but it is possible some historical add-ons may be affected by this and some sites may behave differently. However, many sites now assume this protection, so it is important that we do the same. If you believe a site is behaving differently because of this, toggle the setting security.data_uri.unique_opaque_origin to false and restart the browser. If the behaviour changes, then this was the cause and you should report it in the comments. This covers most of the known exploits of the old Firefox behaviour and I'll be looking at possibly locking this down further in future releases.
The other notable security change is support for noopener, but using the soon-to-be-current implementation in Firefox 63. This feature prevents new windows (that were presumably unwittingly) opened to a malicious page from that page then trying to manipulate the page that opened it, and many sites already support it.
This release also now prefs MSE (and VP9) to on by default, since YouTube seems to require it. We do have AltiVec acceleration for VP9 (compare with libvpx for Chromium on little-endian PowerPC), but VP9 is a heavier codec than VP8, and G4 and low-end G5 systems will not perform as well. You can still turn it off for sites that seem to do better with it disabled.
There are two known broken major sites: the Facebook display glitch (worse on 10.5 than 10.4, for reasons as yet unexplained), and Citibank does not load account information. Facebook can be worked around by disabling Ion JavaScript acceleration, but I don't advise this because of the profound performance impact and I suspect it's actually just fixing a symptom because backing out multiple changes in JavaScript didn't seem to make any difference. As usual, if you can stand Facebook Basic, it really works a lot better on low-power systems like ours. Unfortunately, Citibank has no such workaround; changing various settings or even user agents doesn't make any difference. Citibank does not work in versions prior to Fx51, so the needful could be any combination of features newly landed in the timeframe up to that point. This is a yuuuge range to review and very slow going. I don't have a fix yet for either of these problems, nor an ETA, and I'm not likely to until I better understand what's wrong. Debugging Facebook in particular is typically an exercise in forcible hair removal because of their multiple dependencies and heavy minification, and their developer account has never replied to my queries to get non-minified sources.
So, in the absence of a clear problem to repair, my plan for FPR11 is to try to get additional well-known symbols supported (which should be doable) and further expand our JavaScript ES6/ES7 support in general. Unfortunately for that last, I'm hitting the wall on two very intractable features because of their size which are starting to become important for continued compatibility. In general my preference is to implement new features in as compartmentalized a fashion as possible and preferably in a small number of commits that can be backed out without affecting too much else. These features, however, are enormous in scope and changes, and depend on many other smaller changes we either don't need, don't
After a diligent analysis of the test cases and our existing code, TenFourFox is not known to be vulnerable to the exploits repaired in Firefox 62.0.3/60ESR. Even if the flaws in question actually existed as such in our code, they would require a PowerPC-specific exploit due to some architecture-dependent aspects of the attacks.
http://tenfourfox.blogspot.com/2018/10/tenfourfox-and-hack2win.html

In many user experience (UX) studies, the researchers give the participants a task and then observe what happens next. Most research participants are earnest and usually attempt to follow instructions. However, in this study, research participants mostly ignored instructions and just started goofing off with each other once they entered the immersive space and testing the limits of embodiment.
The goal of this blog post is to share insights from Hubs by Mozilla usability study that other XR creators could apply to building a multi-user space.
The Extended Mind recruited pairs of people who communicate online with each other every day, which led to testing Hubs with people who have very close connections. There were three romantic partners in the study, one pair of roommates, and one set of high school BFFs. The reason that The Extended Mind recruited relatively intimate pairs of people is because they wanted to understand the potential for Hubs as a communication platform for people who already have good relationships. They also believe that they got more insights about how people would use Hubs in a natural environment rather than bringing in one person at a time and asking that person to hang out in VR with a stranger who they just met.
The two key insights that this blog post will cover are the ease of conversation that people had in Hubs and the playfulness that they embodied when using it.
Conversation Felt Natural
When people enter Hubs, the first thing they would do would be to look around to find the other person in the space. Regardless of if they were on mobile, laptop, tablet or in a VR headset, their primary goal was to connect. Once they located the other person, they immediately gave their impressions of the other person’s avatar and asked what they looked like to their companion. There was an element of fun in finding the other person and then discussing avatar appearances. Including one romantic partner sincerely telling his companion:
“You are adorable,”
…which indicates that his warm feelings for her in the real world easily translated to her avatar.
The researchers created conversational prompts for all of the research participants such as “Plan a potential vacation together,” but participants ignored the instructions and just talked about whatever caught their attention. Mostly people were self-directed in exploring their capabilities in the environment and wanted to communicate with their companion. They relished having visual cues from the other person and experiencing embodiment:
“Having a hand to move around felt more connected. Especially when we both had hands.”
“It felt like we were next to each other.”
The youngest participants in the study were in their early twenties and stated that they avoided making phone calls. They rated Hubs more highly than a phone conversation due to the improved sense of connection it gave them.
[Hubs is] “better than a phone call.”
Some even considered it superior to texting for self-expression:
“Texting doesn’t capture our full [expression]”
The data from this study shows that communication using 2D devices and VR headsets has strong potential for personal conversation among friends and partners. People appeared to feel strong connections with their partners in the space. They wanted to revisit the space in the future with groups of close friends and share it with them as well.
Participants Had Fun
Due to participants feeling comfortable in the space and confident in their ability to express themselves, they relaxed during the testing session and let their sense of humor show through.
The researchers observed a lot of joke-telling and goofiness from people. A consequence of feeling embodied in the VR headset was acting in ways to entertain their companion:
“Physical humor works here.”
Users also discovered that Hubs has a rubber duck mascot that will quack when it is clicked and it will replicate itself. Playing with the duck was very popular.
“The duck makes a delightful sound.”
“Having things to play with is good.”
Here's one image to illustrate the rubber ducks multiplying quickly:
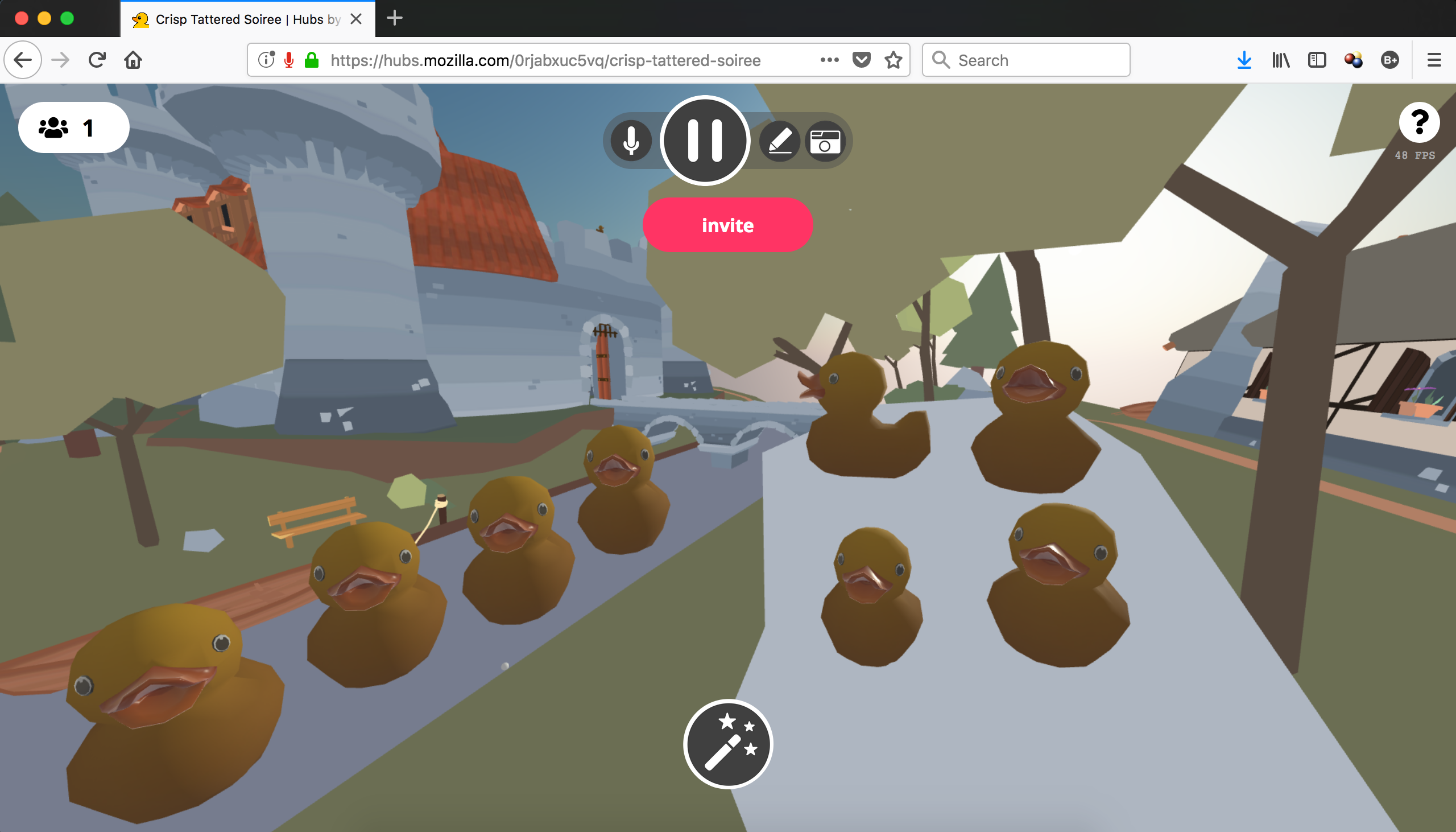
It could be a future research question to determine exactly what is the balance of giving people something like the duck as a fidget activity versus a formal board game or card game. The lack of formality in

As we covered in our last update, we recently added the ability for you to bring images, videos, and 3D models into the rooms you create in Hubs. This is a great way to bring content to view together in your virtual space, and it all works right in your browser.
We’re excited to announce two new features today that will further enrich the ways you can connect and collaborate in rooms you create in Hubs: drawing and easy photo uploads.
Hubs now has a pen tool you can use at any time to start drawing in 3D space. This is a great way to express ideas, spark your creativity, or just doodle around. You can draw by holding the pen in your hand if you are in Mixed Reality, or draw using your PC’s mouse or trackpad.
The new pen tool shines when combined with our media support. You can draw on images together or make a 3D sketch on top of a model from Sketchfab. You can also draw all over the walls if you want!

You can easily change the size and color of your pen strokes. You can write out text or even model out a rough 3D sketch.

If you’re using a phone, we’ve also added an easy way to quickly upload photos or take a snapshot with your phone’s camera. Just tap the photos button at the bottom of the screen to jump right into a photo picker.

This is a great way to share photos from your library or take a quick picture of something nearby. Selfies can be fun too, but don’t be surprised if people draw on your photo!
We hope you have fun with these new features. As always, please join us in the #social channel on the WebVR Slack or file a GitHub issue if you have feedback!
Monday is Thanksgiving in Canada[1], so please excuse your Canadian colleagues for not being in the office.
We’ll likely be spending the day wondering. We’ll be wondering how family could make such a mess, wondering why we ate so much pie, wondering if it’s okay to eat turkey for breakfast, wondering if pie can be a meal and dessert at the same time, wondering how we fit the leftovers in the fridge, wondering why we bothered hosting this year, wondering whose sock that is by the stairs, wondering when the snow will melt[2] or start to fall[3].
We’ll also be wondering who started the family tradition of having cornbread instead of buttered rolls, wondering where the harvest tradition began, wondering about what all goes into harvesting our food, wondering what it means to be thankful, wondering what we are thankful for, wondering why we ate the evening meal at 4pm, wondering whether 4pm is too late to have a nap.
With heads full of wondering and bellies full of food, we wish you a wonderful Thanksgiving. We’ll be back to work, if not our normal shapes, on Tuesday.
:chutten
PS: Canadian Pro-tip: Leftover food often turns into regret – but this regret can turn back into food if you leave it in the fridge for a little while!
[1]: https://mana.mozilla.org/wiki/display/PR/Holidays%3A+Canada
[2]: Calgary had a (record) snowfall of 32.8cm (1’1'') on Oct 2: https://www.cbc.ca/news/canada/calgary/calgary-october-snow-day-two-1.4848394
[3]: Snow’s a-coming, already or eventually: https://weather.gc.ca/canada_e.html
In various free software communities, I've come across incidents where people have been criticized inappropriately when they couldn't attend an event or didn't meet other people's expectations. This has happened to me a few times and I've seen it happen to other people too.
As it turns out, this is an incredibly bad thing to do. I'm not writing about this to criticize any one person or group in return. Rather, it is written in the hope that people who are still holding grudges like this might finally put them aside and also to reassure other volunteers that you don't have to accept this type of criticism.
Here are some of the comments I received personally:
"Last year, you signed up for the conference but didn't attend, cancelling on the last minute, when you had already been ..."
"says the person who didn't attend any of the two ... he was invited to, because, well, he had no time"
"you didn't stayed at the booth enough at ..., never showed up at the booth at the ... and never joined ..."
Having seen this in multiple places, I don't want this blog to focus on any one organization, person or event.
In all these cases, the emails were sent to large groups on CC, one of them appeared on a public list. Nobody else stepped in to point out how wrong this is.
Out of these three incidents, one of them subsequently apologized and I sincerely thank him for that.
The emails these were taken from were quite negative and accusatory. In two of these cases, the accusation was being made after almost a year had passed. It leaves me wondering how many people in the free software community are holding grudges like this and for how long.
Personally, going to an event usually means giving talks and workshops. Where possible, I try to involve other people in my presentations too and may disappear for an hour or skip a social gathering while we review slides. Every volunteer, whether they are speakers, organizers or whatever else usually knows the most important place where they should be at any moment and it isn't helpful to criticize them months later without even asking, for example, about what they were doing rather than what they weren't doing.
Think about some of the cases where a volunteer might cancel their trip or leave an event early:
- At the last minute they decided to go to the pub instead.
- They never intended to go in the first place and wanted to waste your time.
- They are not completely comfortable telling you their reason because they haven't got to know you well enough or they don't want to put it in an email.
- There is some incredibly difficult personal issue that may well be impossible for them to tell you about because it is uncomfortable or has privacy implications. Imagine if a sibling commits suicide, somebody or their spouse has a miscarriage, a child with a mental health issue or a developer who is simply burnt out. A lot of people wouldn't tell you about tragedies in this category and they are entitled to their privacy.
When you think about it, the first two cases are actually really unlikely. You don't do that yourself, so why do you assume or imply that any other member of the community would behave that way?
So it comes down to the fact that when something like this happens, it is probably one of the latter two cases.
Even if it really was one of the first two cases, criticizing them won't make them more likely to show up next time, it has no positive consequences.
In the third case, if the person doesn't trust you well enough to tell you the reason they changed their plans, they are going to trust you even less after this criticism.
In the fourth case, your criticism is going to be extraordinarily hurtful for them. Blaming them, criticizing them, stigmatizing them and even punishing them and impeding their future participation will appear incredibly cruel from the perspective of anybody who has suffered from some serious tragedy: yet these things have happened right under our noses in respected free software projects.
What is more, the way the subconscious mind works and makes associations, they are going to be reminded about that tragedy or crisis when they see you (or one of your emails) in future. They may become quite brisk in dealing with you or go out of their way to avoid you.
Many organizations have adopted codes of conduct recently. In Debian, it calls on us to assume good faith. The implication is that if somebody doesn't behave the way you hope or expect, or if somebody tells you there is a personal problem without giving you any details, the safest thing to do and the only thing to do is to assume it is something in the
First, some updates on TenFourFox FPR10. There are a couple of security related changes, some DOM updates and some JavaScript ES6 compatibility updates which should fix a few site glitches. However, I'm also trying to track down a debug-only regression in layout present in at least FPR9 and possibly earlier, and there are at least two major sites broken that I do not have a clear understanding of why (and are not regressions). Unfortunately, it is unlikely there will be a solution in time since FPR10 is timed to come out with the next Firefox on October 23ish.
New information came to light recently regarding Fruitfly, also detected by some antivirus systems as Quimitchin, which was discovered quietly infecting machines in January 2017. An unusual Mac-specific APT that later was found to have Windows variants (PDF), Fruitfly was able to capture screenshots, keystrokes, images from the webcam and system information from infected machines. At that time it was believed it was at most a decade old, placing the earliest possible infections in that timeline around 2007 and thus after the Intel transition. The author, 28-year-old Phillip Durachinsky, was eventually charged in January of this year with various crimes linked to its creation and deployment.
Late last month, however, court documents demonstrated that Durachinsky actually created the first versions of Fruitfly when he was 14 years old, i.e., 2003. This indicates there must be a PowerPC-compatible variant which can infect systems going back to at least Panther and probably Jaguar, and squares well with contemporary analyses that found Fruitfly had "ancient" system calls in its code, including, incredibly, GWorld and QuickDraw ones.
The history the FBI relates suggests that early infections were initiated manually by him, largely for the purpose of catching compromising webcam pictures and intercepting screenshots and logins when users entered keystrokes suggesting sexual content. If you have an iSight with the iris closed, though, there was no way he could trigger that because of the hardware cutoff, another benefit of having an actual switch on our computer cameras (except the iMac G5, which was a bag of hurt anyway and one of the few Power Macs I don't care for).
Fruitfly spreads by attacking weak passwords for AFP (Apple Filing Protocol) servers, as well as RDP, VNC, SSH and (on later Macs) Back to My Mac. Fortunately, however, it doesn't seem to get its hooks very deep into the OS. It can be relatively easily found by looking for a suspicious launch agent in ~/Library/LaunchAgents (a Power Mac would undoubtedly be affected by variant A, so check ~/Library/LaunchAgents/com.client.client.plist first), and if this file is present, launchctl unload it, delete it, and delete either ~/.client or ~/fpsaud depending on the variant the system was infected with. After that, change all your passwords and make sure you're not exposing those services where you oughtn't anymore!
For the very early pre-Tiger versions, however, assuming they exist, no one seems to know how currently those might have been kicked off because those systems lack launchd. It's possible it could have insinuated itself as a login item or into the system startup scripts, or potentially the Library/StartupItems folder, but it's probable we'll never know for sure because whatever infected systems dated from that time period have either been junked or paved over. Nevertheless, if you find a file named ~/.client on your system regardless of version that you didn't put there, assume you are infected and proceed accordingly.
http://tenfourfox.blogspot.com/2018/10/fruitfly-and-power-mac.html
The first phase of the Dublin project was recently completed: wifi, a toilet and half a kitchen. An overhaul of the heating and hot water infrastructure and energy efficiency improvements are coming next.

The Irish state provides a range of Government grants for energy efficiency and renewable energy sources (not free as in freedom, but free as in cash).
The Potterton boiler is the type of dinosaur this funding is supposed to nudge into extinction. Nonetheless, it has recently passed another safety inspection:

Not so smart
This relic has already had a date with the skip, making way for smart controls:

Renewable energy
Given the size of the property and the funding possibilities, I'm keen to fully explore options for things like heat pumps and domestic thermal stores.
Has anybody selected and managed this type of infrastructure using entirely free solutions, for example, Domoticz or Home Assistant? Please let me know, I'm keen to try these things, contribute improvements and blog about the results.
Next project: intrusion detection
With neighbours like these, who needs cat burglars? Builders assure me he has been visiting on a daily basis and checking their work.

Time for a smart dog to stand up to this trespasser?
WebPush does more than let you know you’ve got an upcoming calendar appointment or bug you about subscribing to a site’s newsletter (particularly one you just visited and have zero interest in doing). Turns out that WebPush is a pretty good way for us to do a number of things as well. Things like let you send tabs from one install of Firefox to another, or push out important certificate updates. We’ll talk about those more when we get ready to roll them out, but for now, we need to know if some of the key bits work.
One of the things we need to test is if our WebPush servers are up to the job of handling traffic, or if there might be any weird issue we might not have thought of. We’ve run tests, we’ve simulated loads, but honestly, nothing compares to real life for this sort of thing.
In the coming weeks, we’re going to be running an experiment. We’ll be using the Shield service to have your browser set up a web push connection. No data will go over that connection aside from the minimal communication that we need. It shouldn’t impact how you use Firefox, or annoy you with pop-ups. Chances are, you won’t even notice we’re doing this.
Why are we telling you if it something you wouldn’t notice? We like to be open and clear about things. You might see a reference to “dom.push.alwaysConnect” in about:config and wonder what it might mean. Shield lets us flip that switch and gives us control over how many folks at any given time hit our servers. That’s important when you want to test your server and things don’t go as planned.
In this case “dom.push.alwaysConnect” will ask your browser to open a connection to our servers. This is so we can test if our servers can handle the load. Why do it this way instead of a load test? Turns out that trying to effectively load test this is problematic. It’s hard to duplicate “real world” load and all the issues that come with it. This test will help us make sure that things don’t fall over when we make this a full feature. When that configuration flag is set to “true” your browser will try to connect to our push servers.
You can always opt out of the study, if you want, but we hope that you don’t mind being part of this. The more folks we have, and the more diverse the group, the more certain we can be that our servers are up for the challenge of keeping you safer and more in control.
https://blog.mozilla.org/services/2018/10/03/upcoming-push-shield-study/
Starting this week, some visitors may notice something new on the MDN Web Docs site, the comprehensive resource for information about developing on the open web.
We are launching an experiment on MDN Web Docs, seeking direct support from our users in order to accelerate growth of our content and platform. Not only has our user base grown exponentially in the last few years (with corresponding platform maintenance costs), we also have a large list of cool new content, features, and programs we’d like to create that our current funding doesn’t fully cover.
In 2015, on our tenth anniversary (read about MDN’s evolution in the 10-year anniversary post), MDN had four million active monthly users. Now, just three years later, we have 12 million. Our last big platform update was in 2013. By asking for, and hopefully receiving, financial assistance from our users – which will be reinvested directly into MDN – we aim to speed up the modernization of MDN’s platform and offer more of what you love: content, features, and integration with the tools you use every day (like VS Code, Dev Tools, and others), plus better support for the 1,000+ volunteers contributing content, edits, tooling, and coding to MDN each month.
Currently, MDN is wholly funded by Mozilla Corporation, and has been since its inception in 2005. The MDN Product Advisory Board, formed in 2017, provides guidance and advice but not funding. The MDN board will never be pay-to-play, and although member companies may choose to sponsor events or other activities, sponsorship will never be a requirement for participation. This payment experiment was discussed at the last MDN board meeting and received approval from members.
Starting this week, approximately 1% of MDN users, chosen at random, will see a promotional box in the footer of MDN asking them to support MDN through a one-time payment.

Banner placement on MDN
Clicking on the “Support MDN” button will open the banner and allow you to enter payment information.

Payment page on MDN
If you don’t see the promotional banner on MDN, and want to express your support, or read the FAQ’s, you can go directly to the payment page.
Because we want to keep things fully transparent, we’ll report how we spend the money on a monthly basis on MDN, so you can see what your support is paying for. We hope that, through this program, we will create a tighter, healthier loop between our audience (you), our content (written for and by you), and our supporters (also, you, again).
Throughout the next couple months, and into 2019, we plan to roll out additional ways for you to engage with and support MDN. We will never put the existing MDN Web Docs site behind a paywall. We recognize the importance of this resource for the web and the people who work on it.
The post A New Way to Support MDN appeared first on Mozilla Hacks - the Web developer blog.
What is it?
Bleach is a Python library for sanitizing and linkifying text from untrusted sources for safe usage in HTML.
Bleach v3.0.0 released!
Bleach 3.0.0 focused on easing the problems with the html5lib dependency and fixing regressions created in the Bleach 2.0 rewrite
For the first, I vendored html5lib 1.0.1 into Bleach and wrote a shim module. Bleach code uses things in the shim module which import things from html5lib. In this way I:
- keep the two separated to some exten
- the shim is easy to test on its own
- it shouldn't be too hard to update html5lib versions
- we don't have to test Bleach against multiple versions of html5lib (which took a lot of time)
- no one has to deal with Bleach requiring one version of html5lib and other libraries requiring other versions
I think this is a big win for all of us.
The second was tricky. The Bleach 2.0 rewrite changed clean and linkify from running in the tokenizing step of HTML parsing to running after parsing is done. The parser (un)helpfully would clean up the HTML before passing it to Bleach. Because of that, the cleaned text would end up with all this extra stuff.
For example, with Bleach 2.1.4, you'd have this:
>>> import bleach
>>> bleach.clean('This is terrible.')
'This is terrible.<sarcasm></sarcasm>'
The tokenizer would parse out things that looked like HTML tags, the parser, would see an end tag that didn't have a start tag and would add the start tag, then clean would escape the start and end tags because they weren't in the list of allowed tags. Blech.
Bleach 3.0.0 fixes that by tweaking the tokenizer to know about the list of allowed tags. With this knowledge, it can see a start, end, or empty tag and strip or escape it during tokenization. Then the parser doesn't try to fix anything.
With Bleach 3.0.0, we get this:
>>> import bleach
>>> bleach.clean('This is terrible.')
'This is terrible.<sarcasm>'
What I could use help with
I could use help with improving the documentation. I think it's dense and all over the place focus-wise. I find it difficult to read.
If you're good with documentation, I sure could use your help. See issue 397 for more.
Where to go for more
For more specifics on this release, see here: https://bleach.readthedocs.io/en/latest/changes.html#version-3-0-0-october-3rd-2018
Documentation and quickstart here: https://bleach.readthedocs.io/en/latest/
Source code and issue tracker here: https://github.com/mozilla/bleach