I looked at a number of password manager browser extensions already, and most of them have some obvious issues. Kaspersky Password Manager manages to stand out in the crowd however, the approach taken here is rather unique. You know how browser extensions are rather tough to exploit, with all that sandboxed JavaScript and restrictive default content security policy? Clearly, all that is meant for weaklings who don’t know how to write secure code, not the pros working at Kaspersky.
Kaspersky developers don’t like JavaScript, so they hand over control to their beloved C++ code as soon as possible. No stupid sandboxing, code is running with the privileges of the logged in user. No memory safety, dealing with buffer overflows is up to the developers. How they managed to do it? Browser extensions have that escape hatch called native messaging which allows connecting to an executable running on the user’s system. And that executable is what contains most of the logic in case of the Kaspersky Password Manager, with the browser extension being merely a dumb shell.
The extension uses website events to communicate with itself. As in: code running in the same scope (content script) uses events instead of direct calls. While seemingly pointless, this approach has a crucial advantage: it allows websites to mess with the communication and essentially make calls into the password manager’s executable. Because, if this communication channel weren’t open to websites, how could the developers possibly prove that they are capable of securing their application?
Now I’m pretty bad at reverse engineering binary code. But I managed to identify large chunks of custom-written code that can be triggered by websites more or less directly:
- JSON parser
- HTML parser
- Neuronal network
While the JSON parser is required by the native messaging protocol, you are probably wondering what the other two chunks are doing in the executable. After all, the browser already has a perfectly capable HTML parser. But why rely on it? Analyzing page structure to recognize login forms would have been too easy in the browser. Instead, the browser extension serializes the page back to HTML (with some additional attributes, e.g. to point out whether a particular field is visible) and sends it to the executable. The executable parses it, makes the neuronal network analyze the result and tells the extension which fields need to be filled with what values.
Doesn’t sound like proper attack surface maximization because serialized HTML code will always be well-formed? No problem, the HTML parser has its limitations. For example, it doesn’t know XML processing instructions and will treat them like regular tags. And document.createProcessingInstruction("foo", ">src=x>") is serialized as , so now the HTML parser will be processing HTML code that is no longer well-formed.
This was your quick overview, hope you learned a thing or two about maximizing the attack surface. Of course, you should only do that if you are a real pro and aren’t afraid of hardening your application against attacks!
https://palant.de/2018/11/30/maximizing-password-manager-attack-surface-leaning-from-kaspersky
Summary / TL;DR
–>
| Project | What’s in it? | Status |
| C++17 | See list | Published! |
| C++20 | See below | On track |
| Library Fundamentals TS v3 | See below | Under active development |
| Concepts TS | Constrained templates | Merged into C++20, including (now) abbreviated function templates! |
| Parallelism TS v2 | Task blocks, library vector types and algorithms, and more | Published! |
| Executors | Abstraction for where/how code runs in a concurrent context | Subset headed for C++20, rest in C++23 |
| Concurrency TS v2 | See below | Under development. Depends on Executors. |
| Networking TS | Sockets library based on Boost.ASIO | Published! Not headed for C++20. |
| Ranges TS | Range-based algorithms and views | Merged into C++20! |
| Coroutines TS | Resumable functions, based on Microsoft’s await design |
Published! C++20 merge uncertain |
| Modules v1 | A component system to supersede the textual header file inclusion model | Published as a TS |
| Modules v2 | Improvements to Modules v1, including a better transition path | On track to be merged into C++20 |
| Numerics TS | Various numerical facilities | Under active development |
| Graphics TS | 2D drawing API | Future uncertain |
| Reflection TS | Static code reflection mechanisms | PDTS ballot underway; publication expected in early 2019 |
A few links in this blog post may not resolve until the committee’s post-meeting mailing is published (expected any day now). If you encounter such a link, please check back in a few days.
Introduction
A few weeks ago I attended a meeting of the ISO C++ Standards Committee (also known as WG21) in San Diego, California. This was the third committee meeting in 2018; you can find my reports on preceding meetings here (June 2018, Rapperswil) and here (March 2018, Jacksonville), and earlier ones linked from those. These reports, particularly the Rapperswil one, provide useful context for this post.
This meeting broke records (by a significant margin) for both attendance (~180 people) and number of proposals submitted (~270). I think several factors contributed to this. First, the meeting was in California, for the first time in the five years that I’ve been attending meetings, thus making it easier to attend for Bay Area techies who weren’t up for farther travels. Second, we are at the phase of the C++20 cycle where the door is closing for new proposals targeting to C++20, so for people wanting to get features into C++20, it was now or never. Finally, there has been a general trend of growing interest in participation in C++ standardization, and thus attendance has been rising even independently of other factors.
This meeting was heavily focused on C++20. As discussed in the committee’s standardization schedule document, this was the last meeting to hear new proposals targeting C++20, and the last meeting for language features with significant library impact to gain design approval. A secondary focus was on in-flight Technical Specifications, such as Library Fundamentals v3.
To accommodate the unprecedented volume of new proposals, there has also been a procedural change at this meeting. Two new subgroups were formed: Evolution
I’ve discussed and linked to articles about the advantages of splitting patches into small pieces to the point that I don’t feel the need to reiterate it here. This is a common approach at Mozilla, especially (but not just) in Firefox engineering, something the Engineering Workflow group is always keeping in mind when planning changes and improvements to tools and processes. Many Mozilla engineers have a particular approach to working with small diffs, something, I’ve realized over time, that seems to be pretty uncommon in the industry: the stacking of commits together in a logical series that solves a particular problem or implements a specific feature.

Firefox Reality 1.1 is now available for download in the Viveport, Oculus, and Daydream app stores. This release includes some major new features, including localization to seven new languages (including voice search support), a new dedicated theater viewing mode, bookmarks, 360 video support, and significant improvements to the performance and quality of our user interface.
We also continue to expand the Firefox Reality content feed, and are excited to add cult director/designer Keiichi Matsuda’s video series, including his latest creation, Merger.
Keiichi’s work explores how emerging technologies will impact everyday life in the future. His acclaimed 2016 film HYPER-REALITY was a viral success, presenting a provocative and kaleidoscopic vision of the future city saturated in media. It was an extension and re-imagining of his earlier concept films made in 2010, also presented here. His new short film, Merger, is shot in 360 and explores the future of work, automated corporations and the cult of productivity. We follow an elite tele-operator fighting for her economic survival, in search of the ultimate interface.
New Features:
- Improved theater mode with 360 video playback support
- Additional localization: Chinese (Mandarin - simplified and traditional), French, Italian, German, Spanish, Japanese, Korean
- Expanded voice search support to new localized languages above
- Bookmarks
- Automatic search and domain suggestions in URL bar
Improvements/Bug Fixes:
- Improved 2D UI performance
Full release notes can be found in our GitHub repo here.
Looking ahead, we are exploring content sharing and syncing across browsers (including bookmarks), multiple windows, tab support, as well as continuing to invest in baseline features like performance. We appreciate your ongoing feedback and suggestions — please keep it coming!
Firefox Reality is available right now.
Download for Oculus
(supports Oculus Go)
Download for Daydream
(supports all-in-one devices)
Download for Viveport (Search for “Firefox Reality” in Viveport store)
(supports all-in-one devices running VIVE Wave)
https://blog.mozvr.com/firefox-reality-update-supports-360-videos-and-7-additional-languages/
We did another release today.
the following changes have been pushed to bugzilla.mozilla.org:
2018 is the 70th anniversary of the Universal Declaration of Human Rights.

Over the last few days, while attending the UN Forum on Business and Human Rights, I've had various discussions with people about the relationship between software freedom, business and human rights.
In the information age, control of the software, source code and data translates into power and may contribute to inequality. Free software principles are not simply about the cost of the software, they lead to transparency and give people infinitely more choices.
Many people in the free software community have taken a particular interest in privacy, which is Article 12 in the declaration. The modern Internet challenges this right, while projects like TAILS and Tor Browser help to protect it. The UN's 70th anniversary slogan Stand up 4 human rights is a call to help those around us understand these problems and make effective use of the solutions.
We live in a time when human rights face serious challenges. Consider censorship: Saudi Arabia is accused of complicity in the disappearance of columnist Jamal Khashoggi and the White House is accused of using fake allegations to try and banish CNN journalist Jim Acosta. Arjen Kamphuis, co-author of Information Security for Journalists, vanished in mysterious circumstances. The last time I saw Arjen was at OSCAL'18 in Tirana.
For many of us, events like these may leave us feeling powerless. Nothing could be further from the truth. Standing up for human rights starts with looking at our own failures, both as individuals and organizations. For example, have we ever taken offense at something, judged somebody or rushed to make accusations without taking time to check facts and consider all sides of the story? Have we seen somebody we know treated unfairly and remained silent? Sometimes it may be desirable to speak out publicly, sometimes a difficult situation can be resolved by speaking to the person directly or having a meeting with them.
Being at the United Nations provided an acute reminder of these principles. In parallel to the event, the UN were hosting a conference on the mine ban treaty and the conference on Afghanistan, the Afghan president arriving as I walked up the corridor. These events reflect a legacy of hostilities and sincere efforts to come back from the brink.

A wide range of discussions and meetings
There were many opportunities to have discussions with people from all the groups present. Several sessions raised issues that made me reflect on the relationship between corporations and the free software community and the risks for volunteers. At the end of the forum I had a brief discussion with Dante Pesce, Chair of the UN's Business and Human Rights working group.

Best free software resources for human rights?
Many people at the forum asked me how to get started with free software and I promised to keep adding to my blog. What would you regard as the best online resources, including videos and guides, for people with an interest in human rights to get started with free software, solving problems with privacy and equality? Please share them on the Libre Planet mailing list.
Let's not forget animal rights too
Are dogs entitled to danger pay when protecting heads of state?
Virtual reality headsets are one of the hottest gifts of the season, but without an internet browser built for virtual reality the experience could fall flat. Enter, Firefox Reality, an … Read more
The post How to Use Firefox Reality on the Oculus Go VR Headset appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/firefox-reality-oculus-go-vr/
a whole bunch of updates (including last week’s)
Last week’s pushes didn’t get posted because we had a few bug fixes, so below is yesterday’s push + last weeks, in reverse chronological order.
the following changes have been pushed to bugzilla.mozilla.org:
In our first post of this series we introduced why, and a bit of how, we’re applying experience design to our Open Innovation projects and community collaboration. An integral part of experience design is growing an idea from a concept to a full-fledged product or service. In getting from one to the other, thinking and acting prototypically can make a significant difference in overall quality and sets us up for early, consistent feedback. We are then able to continually identify new questions and test our hypotheses with incremental work. So, what do we actually mean by thinking and acting prototypically?
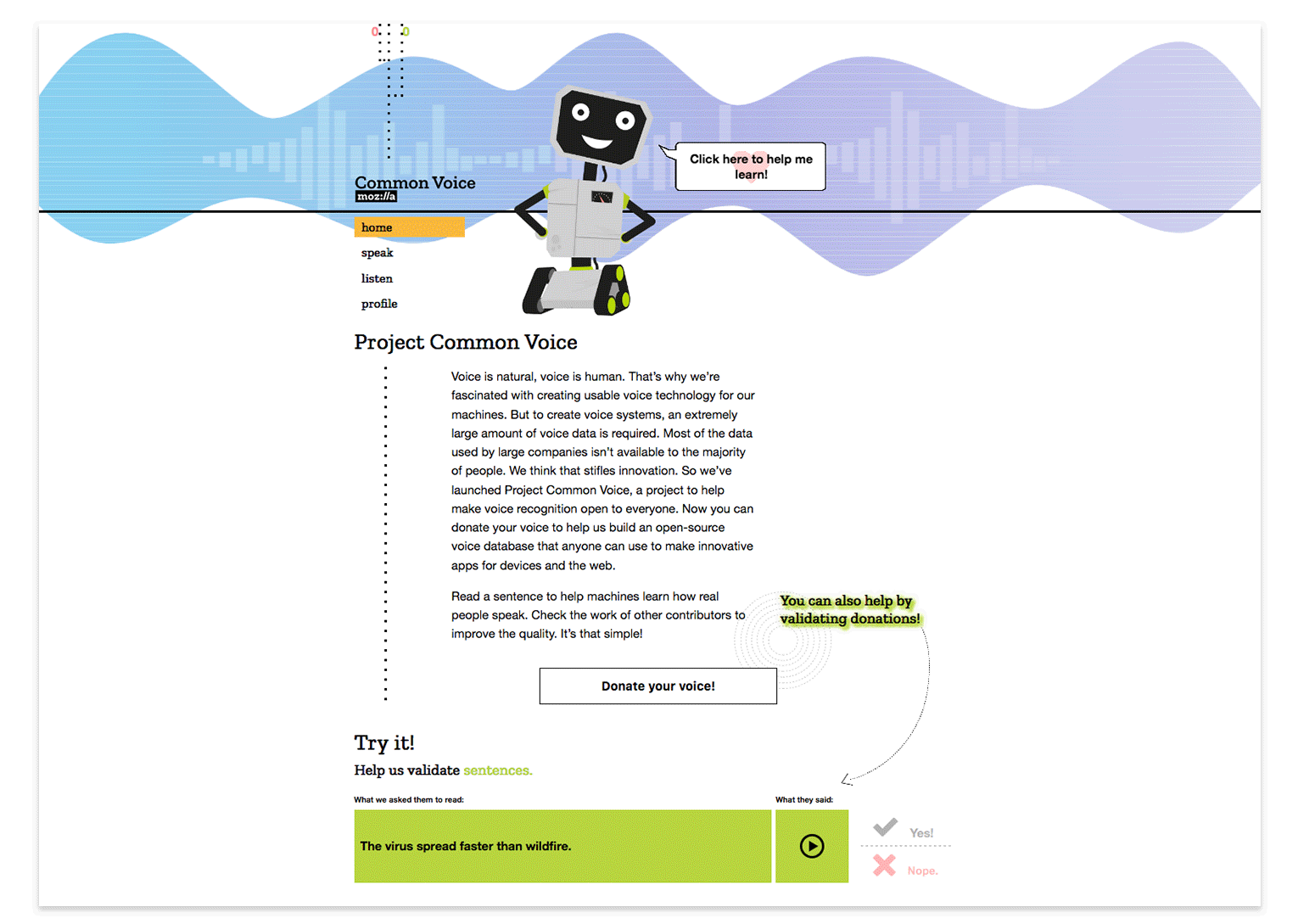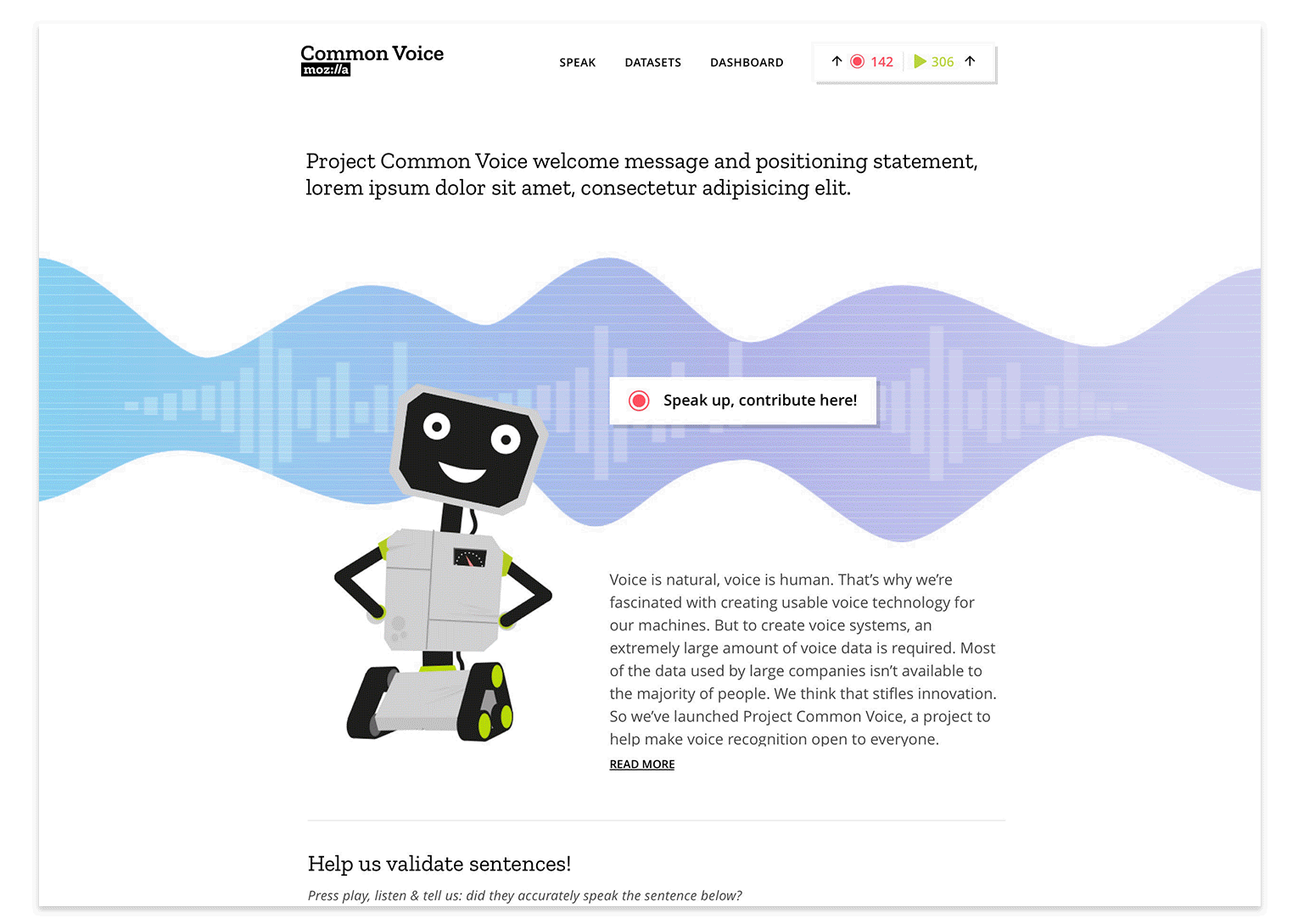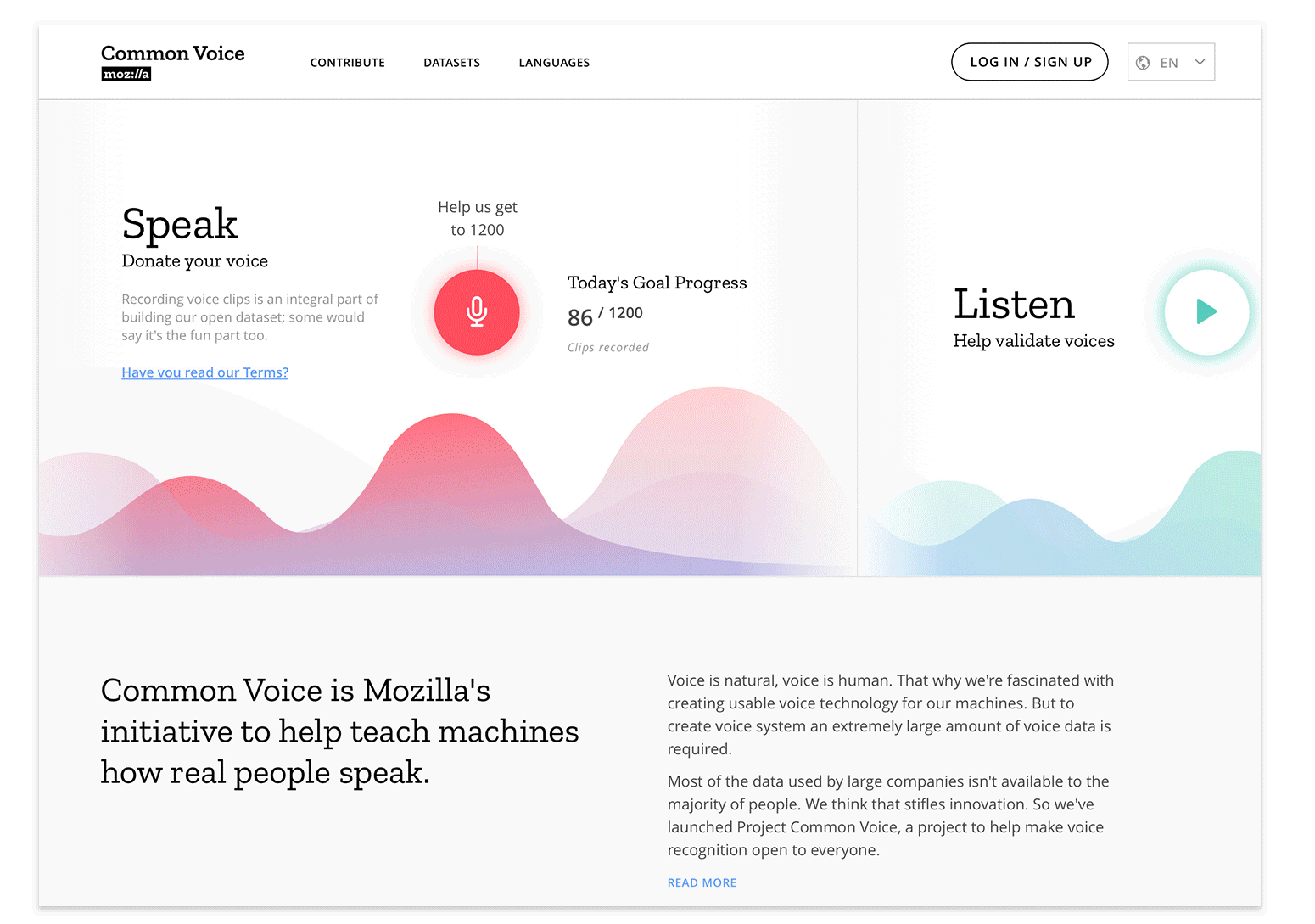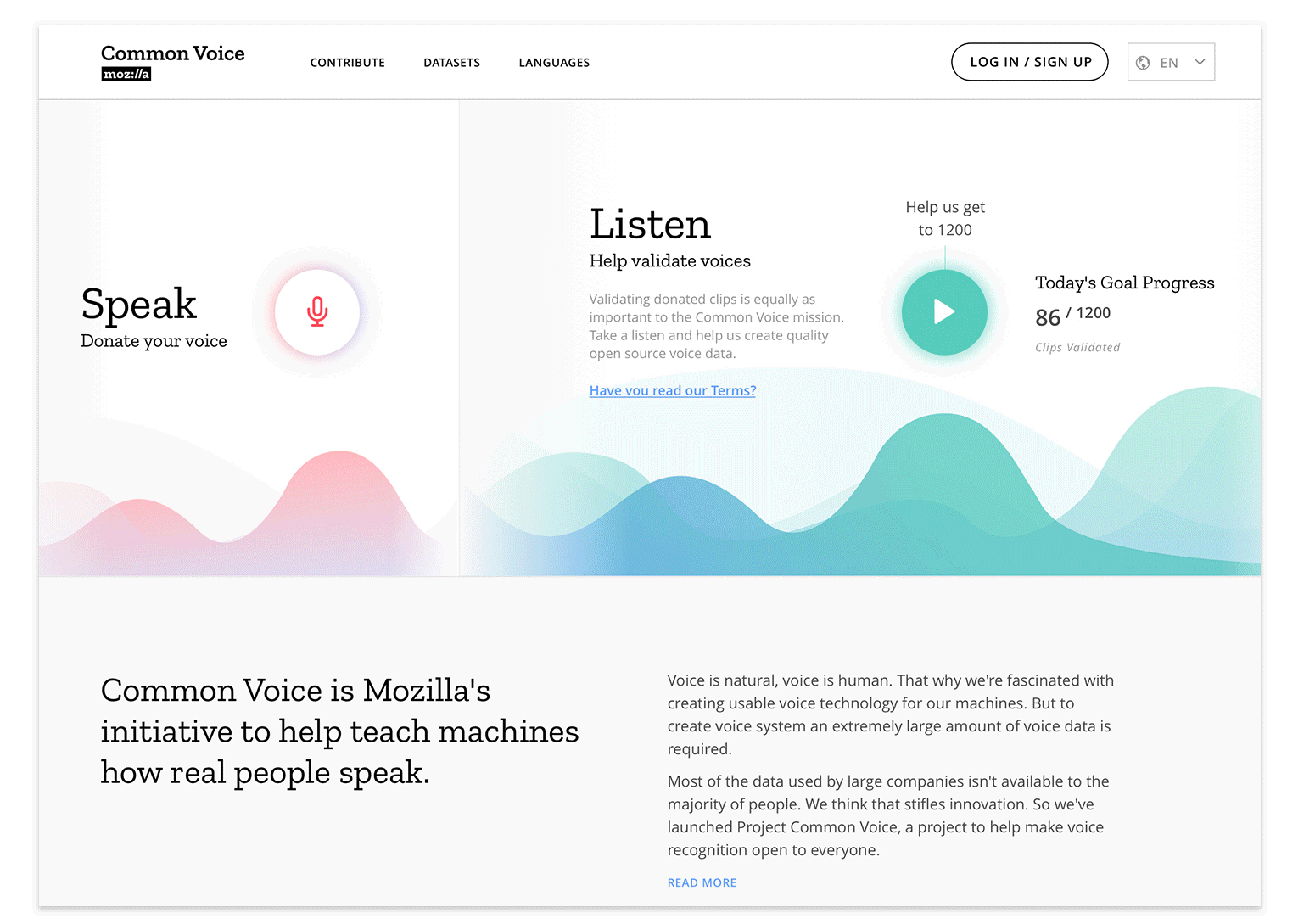
Be Open to Change
At the start of any project our Open Innovation team concepts with the intention that things will change. Whether it be wireframe prototypes or coded experiments, iteration is inevitable. First ideas are often far from perfect… it’s with help from new or returning contributors and collaborating project teams that we’re able to refine initial ideas more readily and efficiently. How? Through feedback loops designed with tools such as Discourse, GitHub, contact forms, on-site surveys and remote testing. Our overall goal being: Release assumptions early and learn from those engaging with the concept. In this way we set our experiences up for incremental, data influenced iteration.

To continue with our example of Common Voice, we see that this approach was applied in moving from paper prototype to first production prototype. The learnings and feedback from the design sprint exercises helped us realize the need for storytelling and a human interaction experience that would resonate with, well, humans. To achieve this we set out over a 6 week phase to create the experience via wireframes, basic UI design and code implementation. With the help of our community members we were gratefully able to QA the experience as we released it.
Iterate Consistently and Incrementally
With a working prototype out in the wild our team sets their focus on observing and gathering info about performance and usability. In addition to 250+ technical contributors that file issues with feature requests and bug fixes, for Common Voice, our team made time to evaluate the prototype from a usability perspective.
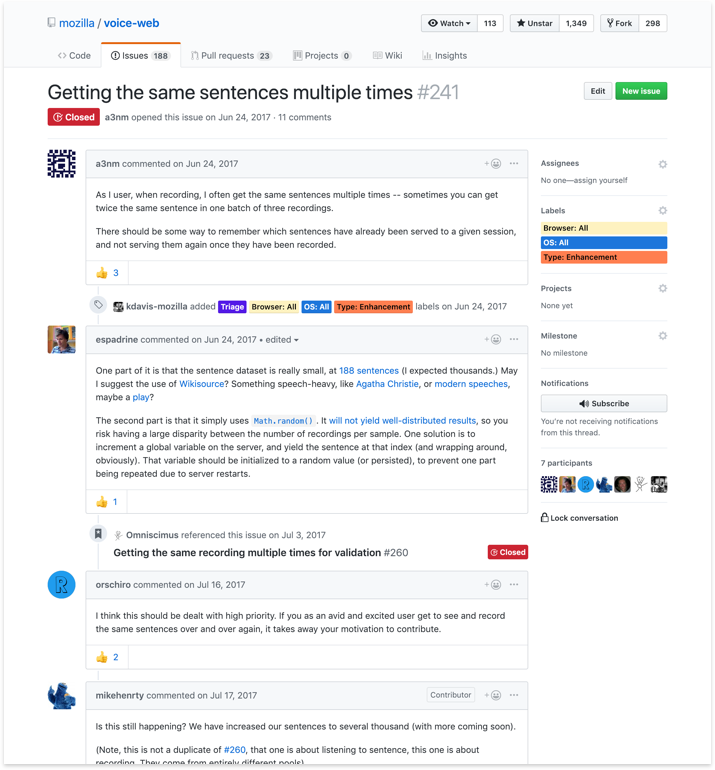
About three months in we performed a UX assessment reviewing initial prototype designs against what actually made it to production code. Comparing this against feature requests from product stakeholders and contributors, our experience design goal was to understand changes most needed to improve usability and engagement across the site.
This assessment information, combined with usability testing, supported decisions for improvements such as:
- Adding keyboard shortcuts to the contribution experience
- Improving prompts and progress counters when recording and listening to sentences
- Site navigation layout from sidebar to top header
- Optimization for responsiveness across viewports
- Providing clear calls to action for contribution on the homepage

Workshop New Questions
Completing the
the following changes have been pushed to bugzilla.mozilla.org:
- [1505793] Add triage owner in /rest/bug
- [1506754] Group Membership report “include disabled users” doesn’t seem to work
- [1328665] Two issues with Project Review form for RRAs
- [1505050] make the request nagging script more robust
- [1504325] Mozilla Gear Request form broken: The requested format gear does not exist with a…
Hey there! Did you hear this? Me neither. The 32nd episode of WebRender’s newsletter made its way to your screen without a sound. In the previous episode, nic4r asked in the comments section a lot of technical and interesting questions. There is a lot to cover so I’ll start by answering a couple here by way of introduction and will go through the other questions in later posts.
How do the strategies for OMTP and WebRender relate? Would OMTP have benefits for expensive blob rasterization since that used Skia?
OMTP, for off-main-thread painting, is a project completely separate from WebRender that was implemented by Ryan. Without WebRender, painting used to happen on the main thread (the thread that runs the JS event loop). Since this thread is often the busiest, moving things out of it, for example painting, is a nice win for multi core processors since the main thread gets to go back to working on JS more quickly while painting is carried out in parallel. This work is pretty much done now and Ryan is working on project Fission.
What about WebRender? WebRender moved all of painting off of the main thread by default. The main thread translates Gecko’s displaylist into a WebRender displaylist which is sent to the GPU process and the latter renders everything. So WebRender and OMTP, while independent projects both fulfill the goal of OMTP which was to remove work from the main thread. OMTP can be seen as a very nice performance win while waiting for WebRender.
Expensive blob rasterization is already carried out asynchronously by the scene builder thread (helped by a thread pool) which means we get with blob rasterization the same property that OMTP provides. This is a good segue to another question:
How do APZ and async scene building tie together?
APZ (for Asynchronous Panning and Zooming) refers to how we organize the rendering architecture in such a way that panning and zooming can happen at a frame rate that is decoupled from the expensive parts of the rendering pipeline. This is important because the perceived performance of the browser largely relies on quickly and smoothly reacting to some basic interactions such as scrolling.
With WebRender there are some operations that can cost more than our frame budget such as scene building and blob image rasterization. In order to keep the nice and smooth feel of APZ we made these asynchronous. In practice this means that when layout changes happen, we re-build the scene and perform the rasterization of blob images on the side while still responding to input events so that we can continue scrolling the previous version of the scene until the new one is ready. I hope this answers the question. Async scene building is one of the ways we “preserve APZ” so to speak with WebRender.
Notable WebRender and Gecko changes
- Jeff improved performance when rendering text by caching nsFontMetrics references.
- Jeff removed some heap allocations when creating clip chains.
- Jeff wrote a tool to find large memcpys generated by rustc.
- Dan continued working on scene building performance.
- Kats is helping with the AMI upgrade for Windows.
- Kats Fixed crashes due to large draw target allocations.
- Kats Got captures to work on Android.
- Kvark removed non-zero origin of reference frames stacking contexts and iframes.
- Kvark made a couple of memcpy optimizations.
- Kvark fixed replaying a release capture with a debug version of wrench.
- Kvark prevented tiled blob images from making captures unusable.
- Matt Improved the performance of displaylist building.
- Andrew fixed a rendering issue with animated images.
- Andrew fixed a crash.
- Glenn landed all of the primitive interning and picture caching patches, will probably enable
It’s been a year here on the internet, to say the least. We’ve landed in a place where misinformation—something we fought hard to combat—is the word of the year, where … Read more
The post Firefox fights for you appeared first on The Firefox Frontier.
We’re happy to announce the recipients for the 2018 H2 round of Mozilla Research Grants. In this tightly focused round, we awarded grants to support research in four areas: Web of the Things, Core Web Technologies, Voice/Language/Speech, and Mixed Reality. These projects support Mozilla’s mission to ensure the Internet is a global public resource, open and accessible to all.
Web of Things
We are funding University of Washington to support Assistant Professor of Interaction Design Audrey Desjardins in the School of Art + Art History + Design. Her project, titled (In)Visible Data: How home dwellers engage with domestic Web of Things data, will provide a detailed qualitative description of current practices of data engagement with the Web of Things in the home, and offer an exploration of novel areas of interest that are diverse, personal, and meaningful for future WoT data in the home.
Core Web Technologies
Mozilla has been deeply involved in creating and releasing AV1: an open and royalty-free video encoding format. We are funding the Department of Control and Computer Engineering at Politecnico di Torino. This grant will support the research of Assistant Professor Luca Ardito and his project Algorithms clarity in Rust: advanced rate control and multi-thread support in rav1e. This project aims to understand how the Rust programming language improves the maintainability of code while implementing complex algorithms.
Voice, language and speech
We are funding Indiana University Bloomington to support Suraj Chiplunkar’s project Uncovering Effective Auditory Feedback Methods to Promote Relevance Scanning and Acoustic Interactivity for Users with Visual Impairments. This project explores better ways to allow people to listen to the web. Suraj Chiplunkar is a graduate student in the Human-Computer Interaction Design program as part of the School of Informatics, Computing, and Engineering, and is working with Professor Jeffrey Bardzell.
Mixed Reality
Mozilla has a strong commitment to open standards in virtual and augmented reality, as evidenced by our browser, Firefox Reality. We’re happy to support the work of Assistant Professor Michael Nebeling at the University of Michigan’s School of Information and his project Rethinking the Web Browser as an Augmented Reality Application Delivery Platform. This project explores the possibilities for displaying elements from multiple augmented reality apps at once, pointing the way to a vibrant, open mixed reality ecosystem.
The Mozilla Research Grants program is part of Mozilla’s Emerging Technologies commitment to being a world-class example of inclusive innovation and impact culture, and reflects Mozilla’s commitment to open innovation, continuously exploring new possibilities with and for diverse communities. We plan to open the 2019H1 round in Spring 2019: see our Research Grant webpage for more details and to sign up to be notified when applications open.
Congratulations to all of our applicants!
Thumbnail image by Audrey Dejardins
The post Mozilla Funds Research Grants in Four Areas appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2018/11/28/mozilla-funds-research-grants-in-four-areas/
Color of Change is one of the leading civil rights organizations of our time, and we at Mozilla have been immensely privileged to collaborate with them on the Ford-Mozilla Open Web Fellows initiative and on a number of areas around internet health.
Their work is pioneering, inspiring, and has been crucial for representing the voices of a key community in debates about the internet. As a technology community, we need more and diverse voices in the work to make the internet open, accessible, and safe for all.
Recently, some concerning allegations regarding practices by Facebook have been raised in high-profile media coverage, including a New York Times article. We are pleased that Facebook is meeting with Color of Change to discuss these issues. We hope Facebook and Color of Change can identify ways that we, as a tech community, can work together to address the biggest challenges facing the internet.
The post A Statement About Facebook and Color of Change appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2018/11/28/a-statement-about-facebook-and-color-of-change/
BugBountyNotes is quickly becoming a great resource for security researches. Their challenges in particular are a fun way of learning ways to exploit vulnerable code. So a month ago I decided to contribute and created two challenges: A properly secured parameter (easy) and Exploiting a static page (medium). Unlike most other challenges, these don’t really have any hidden parts. Pretty much everything going on there is visible, yet exploiting the vulnerabilities still requires some thinking. So if you haven’t looked at these challenges, feel free to stop reading at this point and go try it out. You won’t be able to submit your answer any more, but as both are about exploiting XSS vulnerabilities you will know yourself when you are there. Of course, you can also participate in any of the ongoing challenges as well.
Still here? Ok, I’m going to explain these challenges then.
What’s up with that parameter?
We’ll start with the easier challenge first, dedicated to all the custom URL parsers that developers seem to be very fond of for some reason. The client-side code makes it very obvious that the “message” parameter is vulnerable. With the parameter value being passed to innerHTML, we would want to pass something like innerHTML won’t execute
Kevin Williamson writes an ode to the benefits of competition and capitalism, one of his themes being the changing fortunes of Apple and Microsoft over the last two decades. I'm mostly sympathetic, but in a hurry to decry "government intervention in and regulation of the part of our economy that is, at the moment, working best", he forgets or neglects to mention the antitrust actions brought by the US government against Microsoft in the mid-to-late 1990s. Without those actions, there is a high chance things could have turned out very differently for Apple. At the very least, we do not know what would have happened without those actions, and no-one should use the Apple/Microsoft rivalry as an example of glorious laissez-faire capitalism that negates the arguments of those calling for antitrust action today.
Would Microsoft have invested $150M to save Apple in 1997 if they hadn't been under antitrust pressure since 1992? In 1994 Microsoft settled with the Department of Justice, agreeing to refrain from tying the sale of other Microsoft products to the sale of Windows. It is reasonable to assume that the demise of Apple, Microsoft's only significant competitor in desktop computer operating systems, would have increased the antitrust scrutiny on Microsoft. At that point Microsoft's market cap was $150B vs Apple's $2B, so $150M seems like a cheap and low-risk investment by Gates to keep the US government off his back. I do not know of any other rational justification for that investment. Without it, Apple would very likely have gone bankrupt.
In a world where the United States v. Microsoft Corporation (2001) antitrust lawsuit didn't happen, would the iPhone have been as successful? In 1999 I was so concerned about the potential domination of Microsoft over the World Wide Web that I started making volunteer contributions to (what became) Firefox (which drew me into working for Mozilla until 2016). At that time Microsoft was crushing Netscape with superior engineering, lowering the price of the browser to zero, bundling IE with Windows and other hardball tactics that had conquered all previous would-be Microsoft competitors. With total domination of the browser market, Microsoft would be able to take control of Web standards and lead Web developers to rely on Microsoft-only features like ActiveX (or later Avalon/WPF), making it practically impossible for anyone but Microsoft to create a browser that could view the bulk of the Web. Web browsing was an important feature for the first release of the iPhone in 2007; indeed for the first year, before the App Store launched, it was the only way to do anything on the phone other than use the built-in apps. We'll never know how successful the iPhone would have been without a viable Web browser, but it might have changed the competitive landscape significantly. Thankfully Mozilla managed to turn the tide to prevent Microsoft's total browser domination. As a participant in that battle, I'm convinced that the 2001 antitrust lawsuit played a big part in restraining Microsoft's worst behavior, creating space (along with Microsoft blunders) for Firefox to compete successfully during a narrow window of opportunity when creating a viable alternative browser was still possible. (It's also interesting to consider what Microsoft could have done to Google with complete browser domination and no antitrust concerns.)
We can't be sure what the no-antitrust world would have been like, but those who argue that Apple/Microsoft shows antitrust action was not needed bear the burden of showing that their counterfactual world is compelling.
http://robert.ocallahan.org/2018/11/capitalism-competition-and-microsoft.html
Over the past few months, Mozilla has experimented with DNS-over-HTTPS (DoH). The intention is to fix a part of a DNS ecosystem that simply isn’t up to the modern, secure standards that every Internet user should expect. Today, we want to let you know about our next test of the feature.
Our initial tests of DoH studied the time it takes to get a response from Cloudflare’s DoH resolver. The results were very positive – the slowest users show a huge performance improvement. A recent test in our Beta channel confirmed that DoH is fast and isn’t causing problems for our users. However, those tests only measure the DNS operation itself, which isn’t the whole story.
Content Delivery Networks (CDNs) provide localized DNS responses depending on where you are in the network, with the goal being to send you to a host which is near you on the network and therefore will give you the best performance. However, because of the way that Cloudflare resolves names [technical note: it’s a centralized resolver without EDNS Client Subnet], this process works less well when you are using DoH with Firefox.
The result is that the user might get less well-localized results that could result in a slow user experience even if the resolver itself is accurate and fast.
This is something we can test. We are going to study the total time it takes to get a response from the resolver and fetch a web page. To do that, we’re working with Akamai to help us understand more about the performance impact. Firefox users enrolled in the study will automatically fetch data once a day from four test web pages hosted by Akamai, collect information about how long it took to look up DNS and then send that performance information to Firefox engineers for analysis. These test pages aren’t ones that the user would automatically retrieve and just contain dummy content.
A soft rollout to a small portion of users in our Release channel in the United States will begin this week and end next week. As before, this study will use Cloudflare’s DNS-over-HTTPS service and will continue to provide in-browser notifications about the experiment so that everyone is fully informed and has a chance to decline participation in this particular experiment. Moving forward, we are working to build a larger ecosystem of trusted DoH providers, and we hope to be able to experiment with other providers soon.
We don’t yet have a date for the full release of this feature. We will give you a readout of the result of this test and will let you know our future plans at that time. So stay tuned.
The post Next Steps in DNS-over-HTTPS Testing appeared first on Future Releases.
https://blog.mozilla.org/futurereleases/2018/11/27/next-steps-in-dns-over-https-testing/
The State of Mozilla annual report for 2017 is now available here.
The new report outlines how Mozilla operates, provides key information on the ways in which we’ve made an impact, and includes details from our financial reports for 2017. The State of Mozilla report release is timed to coincide with when we submit the Mozilla non-profit tax filing for the previous calendar year.
Mozilla is unique. We were founded nearly 20 years ago with the mission to ensure the internet is a global public resource that is open and accessible to all. That mission is as important now as it has ever been.
The demand to keep the internet transparent and accessible to all, while preserving user control of their data, has always been an imperative for us and it’s increasingly become one for consumers. From internet health to digital rights to open source — the movement of people working on internet issues is growing — and Mozilla is at the forefront of the fight.
We measure our success not only by the adoption of our products, but also by our ability to increase the control people have in their online lives, our impact on the internet, our contribution to standards, and how we work to protect the overall health of the web.
As we look ahead, we know that leading the charge in changing the culture of the internet will mean doing more to develop the direct relationships that will make the Firefox and Mozilla experiences fully responsive to the needs of consumers today.
We’re glad not to be at this alone. None of the work we do or the impact we have would be possible without the dedication of our global community of contributors and loyal Firefox users. We are incredibly grateful for the support and we will continue to fight for the open internet.
We encourage you to get involved to help protect the future of the internet, join Mozilla.
The post State of Mozilla 2017: Annual Report appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2018/11/27/state-of-mozilla-2017-annual-report/