When you use the name localhost in a URL, what does it mean? Where does the network traffic go when you ask curl to download http://localhost ?
Is “localhost” just a name like any other or do you think it infers speaking to your local host on a loopback address?
Previously
curl http://localhost
The name was “resolved” using the standard resolver mechanism into one or more IP addresses and then curl connected to the first one that works and gets the data from there.
The (default) resolving phase there involves asking the getaddrinfo() function about the name. In many systems, it will return the IP address(es) specified in /etc/hosts for the name. In some systems things are a bit more unusually setup and causes a DNS query get sent out over the network to answer the question.
In other words: localhost was not really special and using this name in a URL worked just like any other name in curl. In most cases in most systems it would resolve to 127.0.0.1 and ::1 just fine, but in some cases it would mean something completely different. Often as a complete surprise to the user…
Starting now
curl http://localhost
Starting in commit 1a0ebf6632f8, to be released in curl 7.78.0, curl now treats the host name “localhost” specially and will use an internal “hard-coded” set of addresses for it – the ones we typically use for the loopback device: 127.0.0.1 and ::1. It cannot be modified by /etc/hosts and it cannot be accidentally or deliberately tricked by DNS resolves. localhost will now always resolve to a local address!
Does that kind of mistakes or modifications really happen? Yes they do. We’ve seen it and you can find other projects report it as well.
Who knows, it might even be a few microseconds faster than doing the “full” resolve call.
(You can still build curl without IPv6 support at will and on systems without support, for which the ::1 address of course will not be provided for localhost.)
Specs say we can
The RFC 6761 is titled Special-Use Domain Names and in its section 6.3 it especially allows or even encourages this:
Users are free to use localhost names as they would any other domain names. Users may assume that IPv4 and IPv6 address queries for localhost names will always resolve to the respective IP loopback address.
Followed by
Name resolution APIs and libraries SHOULD recognize localhost names as special and SHOULD always return the IP loopback address for address queries and negative responses for all other query types. Name resolution APIs SHOULD NOT send queries for localhost names to their configured caching DNS server(s).
Mike West at Google also once filed an I-D with even stronger wording suggesting we should always let localhost be local. That wasn’t ever turned into an RFC though but shows a mindset.
(Some) Browsers do it
Chrome has been special-casing localhost this way since 2017, as can be seen in this commit and I think we can safely assume that the other browsers built on their foundation also do this.
Firefox landed their corresponding change during the fall of 2020, as recorded in this bugzilla entry.
Safari (on macOS at least) does however not do this. It rather follows what /etc/hosts says (and presumably DNS of not present in there). I’ve not found any official position on the matter, but I found this source code comment indicating that localhost resolving might change at some point:
// FIXME: Ensure that localhost resolves to the loopback address.
Windows (kind of) does it
Since some time back, Windows already resolves “localhost” internally and it is not present in their /etc/hosts alternative. I believe it is more of a hybrid solution though as I believe you can put localhost into that file and then have that
TenFourFox Feature Parity Release 32 Security Parity Release 1 "32.1" is available for testing (downloads, hashes). There are no changes to the release notes except that Mozilla has lengthened 78ESR by a couple more weeks, so the end of official builds is now extended to October 5, 2021. Assuming no major problems, FPR32.1 will go live Monday evening Pacific time as usual.
http://tenfourfox.blogspot.com/2021/05/tenfourfox-fpr32-spr1-available.html
Advertising is central to the internet economy. It funds many free products and services. But it is also very intrusive. It is powered by ubiquitous surveillance and it is used in ways that harm individuals and society. The advertising ecosystem is fundamentally broken in its current form.
Advertising does not need to harm consumer privacy. As a browser maker and as an ethical company driven by a clear mission, we want to ensure that the interests of users are represented and that privacy is a priority. We also benefit from the advertising ecosystem which gives us a unique perspective on these issues.
Every part of the ecosystem has a role to play in strengthening and improving it. That is why we see potential in the debate happening today about the merits of privacy preserving advertising.
As this debate moves forward, there are two principles that should anchor work on this topic to ensure we deliver a better web to consumers.
Consumer Privacy First
Improving privacy for everyone must remain the north star for review of proposals, such as Google’s FLoC and Microsoft’s PARAKEET, and parallel proposals from the ad tech industry. At Mozilla, we will be looking at proposals through this lens, which is always a key factor for any decision about what we implement in Firefox. Parties that aren’t interested in protecting user privacy or in advancing a practical vision for a more private web will slow down the innovation that is possible to achieve and necessary for consumers.
Development in the Open
It is important that proposals are transparently debated and collaboratively developed by all stakeholders through formal processes and oversight at open standards development organizations (“SDOs”). Critical elements of online infrastructure should be developed at SDOs to ensure an interoperable and decentralized open internet. Stakeholder commitment to final specifications and timelines is just as important, because without this, the anticipated privacy benefits to consumers cannot materialize.
At its core, the current proposals being debated and their testing plans have important potential to improve how advertising can be delivered but also may raise privacy and centralization issues that need to be addressed. This is why it’s so critical this process plays out in the open at SDOs.
We hope that all stakeholders can commit to these two principles. We have a real opportunity now to improve the privacy properties of online advertising—an industry that hasn’t seen privacy improvement in years. We should not squander this opportunity. We should instead draw on the internet’s founding principles of transparency, public participation and innovation to make progress.
For more on this:
How online advertising works today and Privacy-Preserving Advertising
The post Building a more privacy preserving ads-based ecosystem appeared first on The Mozilla Blog.
https://blog.mozilla.org/en/mozilla/building-a-more-privacy-preserving-ads-based-ecosystem/
The modern web is funded by advertisements. Advertisements pay for all those “free” services you love, as well as many of the products you use on a daily basis — including Firefox. There’s nothing inherently wrong with advertising: Mozilla’s Principle #9 states that “Commercial involvement in the development of the internet brings many benefits.” However, that principle goes on to say that “a balance between commercial profit and public benefit is critical” and that’s where things have gone wrong: advertising on the web in many situations is powered by ubiquitous tracking of people’s activity on the web in a way that is deeply harmful to users and to the web as a whole.
Some Background
The ad tech ecosystem is incredibly complicated, but at its heart, the way that web advertising works is fairly simple. As you browse the web, trackers (mostly, but not exclusively advertisers), follow you around and build up a profile of your browsing history. Then, when you go to a site which wants to show you an ad, that browsing history is used to decide which of the potential ads you might see you actually get shown.
The visible part of web tracking is creepy enough — why are those pants I looked at last week following me around the Internet? — but the invisible part is even worse: hundreds of companies you’ve never heard of follow you around as you browse and then use your data for their own purposes or sell it to other companies you’ve also never heard of.
The primary technical mechanism used by trackers is what’s called “third party cookies”. A good description of third party cookies can be found here, a cookie is a piece of data that a website stores on your browser and can retrieve later. A third party cookie is a cookie which is set by someone other than the page you’re visiting (typically a tracker). The tracker works with the web site to embed some code from the tracker on their page (often this code is also responsible for showing ads) and that code sets a cookie for the tracker. Every time you go to a page the tracker is embedded on, it sees the same cookie and can use that to link up all the sites you go to.
Cookies themselves are an important part of the web — they’re what let you log into sites, maintain your shopping carts, etc. However, third party cookies are used in a way that the designers of the web didn’t really intend and unfortunately, they’re now ubiquitous. While they have some legitimate uses, like federated login, they are mostly used for tracking user behavior.
Obviously, this is bad and it shouldn’t be a surprise to anybody who has followed our work in Firefox that we believe this needs to change. We’ve been working for years to drive the industry in a better direction. In 2015 we launched Tracking Protection, our first major step towards blocking tracking in the browser. In 2019 we turned on a newer version of our anti-tracking technology by default for all of our users. And we’re not the only ones doing this.
We believe all browsers should protect their users from tracking, particularly cookie-based tracking, and should be moving expeditiously to do so.
Privacy Preserving Advertising
Although third-party cookies are bad news, now that they are so baked into the web, it won’t be easy to get rid of them. Because they’re a dual-use technology with some legitimate applications, just turning them off (or doing something more sophisticated like Firefox Total Cookie Protection) can cause some web sites to break for users. Moreover, we have to be constantly on guard against new tracking techniques.
One idea that has gotten a lot of attention recently is what’s called “Privacy Preserving Advertising” (PPA) . The basic idea has a long history with systems such as Adnostic, PrivAd, and AdScale but has lately been reborn with proposals from Google,
Other titles:
- The impact of internet use and what we might do about it?
- Opportunities for powering more internet use with renewables
- I want this thing, but not until later
- A story of demand-side prioritization, scheduling and negotiation to take advantage of a fluxuating energy supply.
I recently got interested in how renewable power generation plays into the carbon footprint of internet usage. We need power to run and charge the devices we use to consume internet content, to run the networks that deliver that content to us, and to power the servers and data centers that house those servers.
Powering the internet eats up energy. The power necessary to serve up the files, do the computation, encode and package it all up to send it down the wire to each of the billions of devices making those requests consumes energy on an enormous scale. The process of hosting and delivering content is so power hungry, the industry is driven to large extent by the cost and availability of electricity. Data centers are even described in terms of the power they consume - as a reasonable proxy for the capacity they can supply.
One of the problems we hear about constantly is that the intermittent and relatively unpredicatable nature of wind and solar energy means it can only ever make up a portion of a region’s electricity generation capacity. There’s an expectation of always-on power availability; regardles of the weather or time of day, a factory must run, a building must be lit, and if a device requests some internet resource the request must be met immediately. So, we need reliable base load generation to meet most energy demands. Today, that means coal, natural gas, nuclear and hydro generation plants - which can be depended on to supply energy day and night, all year round. Nuclear and hydro are low-carbon, but they can also be expensive and problematic to develop. Wind and solar are much less so, but as long as their output is intermittent they can only form part of the solution for de-carbonizing electricity grids across the world - as long as demand not supply is king.
There are lots of approaches to tackling this. Better storage options (PDF) smooth out the intermittency of wind and solar - day to day if not seasonally. Carbon capture and sequestration lower the carbon footprint of fossil fuel power generation - but raise the cost. What if that on-demand, constant availability of those data centers’ capacity was itself a variable? Suppose the client device issuing the request had a way to indicate priority and expected delivery time, would that change the dynamic?
Wind power tends to peak early in the morning, solar in the afternoon. Internet traffic is at its highest during the day and evening, and some - most - is necessarily real-time. But if I’m watching a series on Netflix, the next episode could be downloaded at anytime, as long as its available by the next evening when I sit down to watch it. And for computational tasks - like compiling some code, running an automated test suite, or encoding video - sometimes you need it as soon as possible, other times its less urgent. Communicating priority and scheduling requirements (a.k.a Quality of Service) from the client through to the infrastructure used to fullfill a request would allow smarter balancing of demand and resources. It would open up the door to better use of less constant (non-baseload) energy sources. The server could defer on some tasks when power is least available or most expensive, and process them later when for example the sun comes up, or the wind blows. Smoothing out spikes in demand would also reduce the need for so-called “peaker” plants - typically natural gas power plants that are spun up to meet excess energy demand.
“Kestler: While intermittent power is a challenge for data center operations, the development of sensors, software tools and network capabilities will be at the forefront of advancing the deployment of renewables across the globe. The modernization of the grid will be dependent on large power consumers being capable of operating in a less stable flow of electrons.
Thanks to funding by ISRG (via Google), we merged the hyper powered HTTP back-end into curl earlier this year as an alternative HTTP/1 and HTTP/2 implementation. Previously, there was only one way to do HTTP/1 and 2 in curl.
Backends
Core libcurl functionality can be powered by optional and alternative backends in a way that doesn’t change the API or directly affect the application. This is done by featuring internal APIs that can be implemented by independent components. See the illustration below (click for higher resolution).

This is a slide from Daniel’s libcurl under the hood presentation.
curl 7.75.0 became the first curl release that could be built with hyper. The support for it was labeled “experimental” as while most of all common and basic use cases were supported, we still couldn’t run the full test suite when built with it and some edge cases even crashed.
We’ve subsequently fixed a few of the worst flaws so the Hyper powered curl has gradually and slowly improved since then.
Going further
Our best friends at ISRG has now once again put up funding and I’ll spend more work hours on making sure that more (preferably all) tests can run with hyper.
I’ve already started. Right now I’m sitting and staring at test case 154 which is doing a HTTP PUT using Digest authentication and an Expect: 100-continue header and this test case currently doesn’t work correctly when built to use Hyper. I’ll report back in a few weeks and let you know how it goes – and then I don’t mean with just test 154!
Consider yourself invited to join the #curl IRC channel and chat if you want live reports or want to help out!
Fund
You too can fund me to do curl work. Get in touch!
https://daniel.haxx.se/blog/2021/05/28/taking-hyper-curl-further/
Part 1. The beginning. (There will be at least one more part later on following up the progress.)
On May 18, 2021 I posted a tweet that I was giving away curl stickers for free to anyone who’d submit their address to me. It looked like this:

Everyone once in a while when I post a photo that involves curl stickers, a few people ask me where they can get hold of such. I figured it was about time I properly offered “the world” some. I expected maybe 50 or a 100 people would take me up on this offer.
The response was totally overwhelming and immediate. Within the first hour 270 persons had already requested stickers. After 24 hours when I closed the form again, 1003 addresses had been submitted. To countries all around the globe. Quite the avalanche.
Assessing the damage
This level of interest put up some challenges I hadn’t planned for. Do I have stickers enough? Now suddenly doing 3 or 5 stickers per parcel will have a major impact. Getting envelops and addresses onto them for a thousand deliveries is quite a job! Not to mention the cost. A “standard mail” to outside Sweden using the regular postal service is 24 SEK. That’s ~2.9 USD. Per parcel. Add the extra expenses and we’re at an adventure north of 3,000 USD.
For this kind of volume, I can get a better rate by registering as a “company customer”. It adds some extra work for me though but I haven’t worked out the details around this yet.
Let me be clear: I already from the beginning planned to ask for reimbursement from the curl fund for my expenses for this stunt. I would mostly add my work on this for free. Maybe “hire” my daughter for an extra set of hands.
Donations
During the time the form was up, we also received 51 donations to Open Collective (as the form mentioned that, and I also mentioned it on Twitter several times). The donated total was 943 USD. The average donation was 18 USD, the largest ones (2) were at 100 USD and the smallest was 2 USD.
Of course some donations might not be related to this and some donations may very well arrive after this form was closed again.
Cleaning up
If I had thought this through better at the beginning, I would not have asked for the address using a free text field like this. People clearly don’t have the same idea of how to do this as I do.
I had to manually go through the addresses to insert newlines, add country names and remove obviously broken addresses. For example, a common pattern was addresses added with only a 6-8 digit number? I think over 20 addresses were specified like that!
Clearly there’s a lesson to be had there.
After removing obviously bad and broken addresses there were 978 addresses left.
Countries
I got postal addresses to 65 different countries. A surprisingly diverse collection I think. The top 10 countries were:
| USA | 174 |
| Sweden | 103 |
| Germany | 93 |
| India | 92 |
| UK | 64 |
| France | 56 |
| Spain | 31 |
| Brazil | 31 |
| The Netherlands | 24 |
| Switzerland | 20 |
Countries that were only entered once: Dubai, Iran, Japan, Latvia, Morocco, Nicaragua, Philippines, Romania, Serbia, Thailand, Tunisia, UAE, Ukraine, Uruguay, Zimbabwe
Figuring out the process
While I explicitly said I wouldn’t guarantee that everyone gets stickers, I want to do my best in delivering a few to every single one who asked for them.
Volunteers
I have the best community. Without me saying a word or asking for it, several people raised their hands and volunteered to offload the sending to their countries. I could send one big batch to them and they redistribute within their countries. They would handle US, Czechia, Denmark and Switzerland for me.
But why stop at those four? In my next step I put up a public plea for more volunteers on Twitter and man, I got myself a busy evening and after a few hours I had friends signed up from over 20 countries offering to redistributed stickers within the respective countries. This way, we share the expenses and the work load, and mailing out many smaller parcels within countries is also a lot cheaper than me sending them all individually from Sweden.
After a lot of communications I had an army of helpers lined up.
28
If you’re like me, first of all, very sorry to hear that, but you are probably spending your Friday morning wondering what the meaning of 537.36 is in the Chromium User-Agent string. It appears in two places: AppleWebKit/537.36 and Safari/537.36.
As any serious researcher does, the first place I went to for answers was numeroscop.net, to check out the “Angel Number Spiritual Meaning”.
(I enjoy a good data-collection-scheme-disguised-as-fortune-telling site as much as anyone else, don’t judge me.)

537 means:
“Positive changes in the material aspect will be an extra confirmation that you have made the right choice of a life partner”
And 36 means:
“[Y]es, you are doing everything right, but you are not doing everything that you could do”.
Angels probably use PHP, so let’s assume “.” is the string concatenation operator. Mashing those together, a meaning emerges: “537.36” represents the last shipping version of WebKit before the Blink fork.
Back in 2013 (right after the fork announcement), Ojan Vafai wrote,
“In the short-term we have no plans of changing the UA string. The only thing that will change is the Chrome version number.”
Darin Fisher (former engineering lead for the Chrome Web Platform Team) said the same in the recorded Q&A video (linked from the Developer FAQ).
Assuming Wikipedia is as trustworthy as that “why did I give the Angel Numerology site my email, birthdate, relationship status, and name, and why am I getting so many ads on other sites about healing crystals and clearance specials on hydroxychloroquine??” site, Chrome 27.0.1453 was the last version of Chrome shipping WebKit, which was at 537.36, and Chrome 28.0.1500 was the first version of stable channel release shipping the Blink engine.
So that’s why those numbers are in the User-Agent string. For obvious compatibility reasons, you can’t just remove strings like AppleWebKit/537.36 and Safari/537.36. And that’s why we’ll keep them there, likely frozen forever.
https://miketaylr.com/posts/2021/05/webkit-537-36-meaning.html
The official publication date of the relevant QUIC specifications is: May 27, 2021.

I’ve done many presentations about HTTP and related technologies over the years. HTTP/2 had only just shipped when the QUIC working group had been formed in the IETF and I started to mention and describe what was being done there.
I’ve explained HTTP/3
I started writing the document HTTP/3 explained in February 2018 before the protocol was even called HTTP/3 (and yeah the document itself was also called something else at first). The HTTP protocol for QUIC was just called “HTTP over QUIC” in the beginning and it took until November 2018 before it got the name HTTP/3. I did my first presentation using HTTP/3 in the title and on slides in early December 2018, My first recorded HTTP/3 presentation was in January 2019 (in Stockholm, Sweden).
In that talk I mentioned that the protocol would be “live” by the summer of 2019, which was an optimistic estimate based on the then current milestones set out by the IETF working group.
I think my optimism regarding the release schedule has kept up but as time progressed I’ve updated that estimation many times…
HTTP/3 – not yet
The first four RFC documentations to be ratified and published only concern QUIC, the transport protocol, and not the HTTP/3 parts. The two HTTP/3 documents are also in queue but are slightly delayed as they await some other prerequisite (“generic” HTTP update) documents to ship first, then the HTTP/3 ones can ship and refer to those other documents.
QUIC
QUIC is a new transport protocol. It is done over UDP and can be described as being something of a TCP + TLS replacement, merged into a single protocol.
Okay, the title of this blog is misleading. QUIC is actually documented in four different RFCs:
RFC 8999 – Version-Independent Properties of QUIC
RFC 9000 – QUIC: A UDP-Based Multiplexed and Secure Transport
RFC 9001 – Using TLS to Secure QUIC
RFC 9002 – QUIC Loss Detection and Congestion Control
My role: I’m just a bystander
I initially wanted to keep up closely with the working group and follow what happened and participate on the meetings and interims etc. It turned out to be too difficult for me to do that so I had to lower my ambitions and I’ve mostly had a casual observing role. I just couldn’t muster the energy and spend the time necessary to do it properly.
I’ve participated in many of the meetings, I’ve been present in the QUIC implementers slack, I’ve followed lots of design and architectural discussions on the mailing list and in GitHub issues. I’ve worked on implementing support for QUIC and h3 in curl and thanks to that helped out iron issues and glitches in various implementations, but the now published RFCs have virtually no traces of me or my feedback in them.
The lines between online life and real life practically disappeared in 2020 when the COVID-19 pandemic forced us to replace social platforms and video apps for human contact.
As part of our mental health awareness month coverage this May, we are talking to people about how their online lives impact their mental health. We connected with Zeke Smith, the comedy writer who was known to fans of CBS’s Survivor as “the goofy guy with the mustache and the Hawaiian shirt” over two seasons of the show until another contestant outed Smith as a trans man. Smith found himself suddenly in the spotlight as an activist and voice of an often-invisible community.
Smith talked to us about how to think about online haters, when it’s time to log off and why a puppy pic is usually more useful than a hot take.
It’s been 15 months since the world came to a halt. How are you doing?
I’ve been fully vaccinated for about five weeks at this point, and it has been a game changer. During the pandemic my boyfriend [actor Nico Santos (Crazy Rich Asians, Superstore)] and I have been slowly having friends, vaccinated friends, over and just being able to see and talk to people who are not my boyfriend or are not on a computer screen has been great. I’m probably like 60 percent introverted, 40 percent extroverted and that 40 percent of me has not been getting fed at all.
Were you replacing in-person with online interaction?
Yeah I was, and I don’t think that’s a good place for anybody to be getting their social interaction. But it’s just been me and my boyfriend the whole time and I found myself feeling lonely and going on Twitter and being like, alright well what are my Twitter friends doing? What are they reading? What podcasts have they just been on?
The hardest part about interacting with people online — and I’m guilty of this as well — is that nobody’s willing to listen, everyone just wants to say their opinion and mic drop and walk away. And I feel like conversations where you have them in person over coffee or cocktails or whatever, where people listen and engage with you, you can’t do that online, because, in my opinion, people are only looking to be validated in their current beliefs.
There is a pull you feel in your career with your aspirations and your life and activism toward social media. Some of this, you have to do, right?
There is a significant portion of our culture that is happening online via various social media platforms and if you live in a major city, particularly if you’re in entertainment, it’s the equivalent of reading the newspaper. You have to sort of be where trends are found and grown, and that’s how you keep up. I think, for me, the quarantine has both accelerated and also troubled this conversation of “Have we reached peak social media?” Because we’ve realized that it’s not good for anyone’s mental health.
It’s bad for our eyes and it’s bad for our sleep to be looking at screens all the time. And it has created really toxic ripples in our culture on both social and political levels.
How do you know it’s time to log off?
When [Harry Potter author] JK Rowling came out as a TERF (trans-exclusionary radical feminist) this summer, I was trying to engage with her and it brought out all of these trans-phobic feminists. I’m making a very well-reasoned argument and then more and more trash comes at you, and it makes you very angry, because you feel threatened.
And when you’re at a moment where all of your notifications on Twitter are just someone yelling at you or saying mean things about you, or trying to undermine something very fundamental about you, it does make you feel very lonely. It does make you feel very defeated.
Those are moments when I have to catch myself because I won’t be able to focus on other things. I’ll just be thinking about a response to what that person said, and those are the moments where I’m like, “Okay, we are deleting the apps off the phone. We are logging out on the browser. We need to take a step back and reset.”
Speaking of how online interactions will never replace the real, lived experience… I think this very much ties into one of the things that’s been on your mind lately: that there aren’t any trans men that we know of working in writers rooms for television. Why does that real-life experience matter?
There was a time not too long ago, and it still exists today, where the only people writing television were straight, cisgender, white guys. The reason why stereotypes develop in television is because they’re written by people who do not have a particular experience.
In the trans context, people who don’t know trans people intimately probably think lives revolve a lot around bathrooms and saying our
At Mozilla we believe that greater transparency in the online advertising ecosystem can empower individuals, safeguard advertisers’ interests, and address systemic harms. It’s something we care passionately about, and it’s an ethos that runs through our own marketing work. Indeed, our recent decision to resume advertising on Instagram is underpinned by a commitment to transparency. Yet we also recognise that this issue is a structural one, and that regulation and public policy has an important role to play in improving the health of the ecosystem. In this post, we give an update on our efforts to advance system-level change, focusing on the ongoing discussions on this topic in the EU.
In December 2020 the European Commission unveiled the Digital Services Act, a draft law that seeks to usher in a new regulatory standard for content responsibility by platforms. A focus on systemic transparency is at the core of the DSA, including in the context of online advertising. The DSA’s approach to ad transparency mandates disclosure well above the voluntary standard that we see today (and mirrors the ethos of our new Instagram advertising strategy).
Under the DSA’s approach, so-called ‘Very Large Online Platforms’ must:
- Disclose the content of all advertisements that run on their services;
- Disclose the key targeting parameters that are associated with each advertisement; and,
- Make this disclosure through publicly-available ad archives (our recommendations on how these ad archives should operate can be found here).
The DSA’s ad transparency approach will give researchers, regulators, and advertisers greater insight into the platform-mediated advertising ecosystem, providing a crucial means of understanding and detecting hidden harms. Harms fester when they happen in the dark, and so meaningful transparency in and of the ecosystem can help mitigate them.
Yet at the same time, transparency is rarely an end in itself. And we’re humble enough to know that we don’t have all the answers to the challenges holding back the internet from what it should be. Fortunately, another crucial benefit of advertising transparency frameworks is that they can provide us with the prerequisite insight and evidence-base that is essential for effective policy solutions, in the EU and beyond.
Although the EU DSA is trending in a positive direction, we’re not resting on our laurels. The draft law still has some way to go in the legislative mark-up phase. We’ll continue to advocate for thoughtful and effective policy approaches for advertising transparency, and prototype these approaches in our own marketing work.
The post Advancing system-level change with ad transparency in the EU DSA appeared first on Open Policy & Advocacy.
Two years ago, Google proposed Manifest v3, a number of foundational changes to the Chrome extension framework. Many of these changes introduce new incompatibilities between Firefox and Chrome. As we previously wrote, we want to maintain a high degree of compatibility to support cross-browser development. We will introduce Manifest v3 support for Firefox extensions. However, we will diverge from Chrome’s implementation where we think it matters and our values point to a different solution.
For the last few months, we have consulted with extension developers and Firefox’s engineering leadership about our approach to Manifest v3. The following is an overview of our plan to move forward, which is based on those conversations.
High level changes
-
In our initial response to the Manifest v3 proposal, we committed to implementing cross-origin protections. Some of this work is underway as part of Site Isolation, a larger reworking of Firefox’s architecture to isolate sites from each other. You can test how your extension performs in site isolation on the Nightly pre-release channel by going to about:preferences#experimental and enabling Fission (Site Isolation). This feature will be gradually enabled by default on Firefox Beta in the upcoming months and will start rolling out a small percentage of release users in Q3 2021.
Cross-origin requests in content scripts already encounter restrictions by advances of the web platform (e.g. SameSite cookies, CORP) and privacy features of Firefox (e.g. state partitioning). To support extensions, we are allowing extension scripts with sufficient host permissions to be exempted from these policies. Content scripts won’t benefit from these improvements, and will eventually have the same kind of permissions as regular web pages (bug 1578405). We will continue to develop APIs to enable extensions to perform cross-origin requests that respect the user’s privacy choices (e.g. bug 1670278, bug 1698863).
- Background pages will be replaced by background service workers (bug 1578286). This is a substantial change and will continue to be developed over the next few months. We will make a new announcement once we have something that can be tested in Nightly.
- Promise-based APIs: Our APIs have been Promise-based since their inception using the browser.* namespace and we published a polyfill to offer consistent behavior across browsers that only support the chrome.* namespace. For Manifest v3, we will enable Promise-based APIs in the chrome.* namespace as well.
- Host permission controls (bug 1711787): Chrome has shipped a feature that gives users control over which sites extensions are allowed to run on. We’re working on our own design that puts users in control, including early work by our Outreachy intern Richa Sharma on a project to give users the ability to decide if extensions will run in different container tabs (bug 1683056). Stay tuned for more information about that project!
- Code execution: Dynamic code execution in privileged extension contexts will be restricted by default (bug 1687763). A content security policy for content scripts will be introduced (bug 1581608). The existing userScripts and contentScripts APIs will be reworked to support service worker-based extensions (
Are we targeting you? Yep. And we’ll tell you how.
When I joined Mozilla, the organization had made the decision to pause Facebook advertising in light of the Cambridge Analytica privacy controversy. This was a decision that I understand, but I’m changing course.
For Mozilla, it boils down to this: our mission requires that we empower everyone to protect themselves online, not just the folks that are plugged in to the recent techlash. And a lot of the people that may need our tools the most spend a lot of time on Facebook and Instagram.
So the question becomes, can we reach folks on these platforms with our ads, while staying true to Mozilla’s values? I believe we can, and it starts with being up front about what we’re doing.
Here’s the skinny:
Online, people are segmented into small groups in order to serve them up highly-targeted advertisements. This is called microtargeting. And it happens countless times a day on the platforms we use every day.
For many years the conventional wisdom was that this type of advertising was simply a better way to put more relevant ads in front of consumers. Relevant ads means better conversion for advertisers, which means more goods sold. And, hey, sometimes it works out well for people. Chances are you’ve found a new shampoo or pair of shoes or set of weights because of these targeted ads. You’ve also probably bought something you didn’t need (or even particularly want) because of these targeted ads. I know I have – my half-used collection of skincare products can attest to that.
The problem is not that these ads themselves exist, it is the complexity of the system that’s the issue. The same highly sophisticated targeting tools that allow advertisers to find you can also be used for harm. This can look like overly aggressive ad tactics, or even changing consumers’ self-perception after being targeted a certain way. In the most dangerous cases, advertisers can target groups with harmful messages, like targeting sick people with treatments that don’t actually work, ads that discriminate against different under-represented groups, and deceptive ads targeting stressed teenagers for army recruitment.
So what can we do? It starts with transparency. Ads and the targeting parameters used by companies should be public and available for anyone to see.
When Mozilla advertises on Instagram, we are going to tell you exactly what our ad says, who we are advertising to and why. Our ads themselves will do the same.
The full list of information for our Mozilla and Firefox ads can be found here.
Here’s an example:
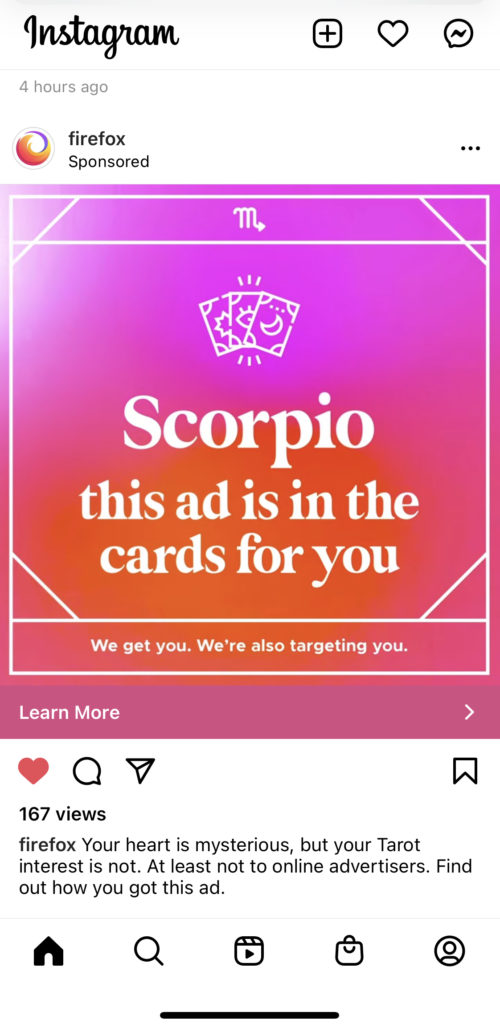
Target: Scorpio + Oct/Nov birthday + interest in tarot cards
Today the European Commission published its guidance for the upcoming revision of the EU Code of Practice on Disinformation. Mozilla was a founding signatory of the Code of Practice in 2018, and we’re happy to see plans materialise for its evolution.
Reacting to the guidance, Raegan MacDonald, Director of Global Policy, Mozilla Corporation said:
“We welcome the Commission’s guidance for the next iteration of the Code of Practice. We’re happy that the revised Code will provide a greater role for organisations with technical and research expertise, and we look forward to harnessing that opportunity to support the various stakeholders.
This guidance outlines a clear vision for how the fight against disinformation can sit within a future-focused and thoughtful policy framework for platform accountability. While we still need to ensure the DSA provides the fundamentals, we see the revised Code as playing an important role in giving practical meaning to transparency and accountability.”
The post Mozilla reacts to the European Commission’s guidance on the revision of the EU Code of Practice on Disinformation appeared first on Open Policy & Advocacy.
Welcome to the 200th curl release. We call it 200 OK. It coincides with us counting more than 900 commit authors and surpassing 2,400 credited contributors in the project. This is also the first release ever in which we thank more than 80 persons in the RELEASE-NOTES for having helped out making it and we’ve set two new record in the bug-bounty program: the largest single payout ever for a single bug (2,000 USD) and the largest total payout during a single release cycle: 3,800 USD.
This release cycle was 42 days only, two weeks shorter than normal due to the previous 7.76.1 patch release.
Release Presentation
Numbers
the 200th release
5 changes
42 days (total: 8,468)
133 bug-fixes (total: 6,966)
192 commits (total: 27,202)
0 new public libcurl function (total: 85)
2 new curl_easy_setopt() option (total: 290)
2 new curl command line option (total: 242)
82 contributors, 44 new (total: 2,410)
47 authors, 23 new (total: 901)
3 security fixes (total: 103)
3,800 USD paid in Bug Bounties (total: 9,000 USD)
Security
We set two new records in the curl bug-bounty program this time as mentioned above. These are the issues that made them happen.
CVE-2021-22901: TLS session caching disaster
This is a Use-After-Free in the OpenSSL backend code that in the absolutely worst case can lead to an RCE, a Remote Code Execution. The flaw is reasonably recently added and it’s very hard to exploit but you should upgrade or patch immediately.
The issue occurs when TLS session related info is sent from the TLS server when the transfer that previously used it is already done and gone.
The reporter was awarded 2,000 USD for this finding.
CVE-2021-22898: TELNET stack contents disclosure
When libcurl accepts custom TELNET options to send to the server, it the input parser was flawed which could be exploited to have libcurl instead send contents from the stack.
The reporter was awarded 1,000 USD for this finding.
CVE-2021-22897: schannel cipher selection surprise
In the Schannel backend code, the selected cipher for a transfer done with was stored in a static variable. This caused one transfer’s choice to weaken the choice for a single set transfer could unknowingly affect other connections to a lower security grade than intended.
The reporter was awarded 800 USD for this finding.
Changes
In this release we introduce 5 new changes that might be interesting to take a look at!
Make TLS flavor explicit
As explained separately, the curl configure script no longer defaults to selecting a particular TLS library. When you build curl with configure now, you need to select which library to use. No special treatment for any of them!
No more SSL
curl now has no more traces of support for SSLv2 or SSLv3. Those ancient and insecure SSL versions were already disabled by default by TLS libraries everywhere, but now it’s also impossible to activate them even in special build. Stripped out from both the curl tool and the library (thus counted as two changes).
HSTS in the build
We brought HSTS support a while ago, but now we finally remove the experimental label and ship it enabled in the build by default for everyone to use it more easily.
In-memory cert API
We introduce API options for libcurl that allow users to specify certificates in-memory instead of using files in the file system. See CURLOPT_CAINFO_BLOB.
Favorite bug-fixes
Again we manage to perform a large amount of fixes in this release, so I’m highlighting a few of the ones I find most interesting!
Version output
The first line of curl -V output got updated: libcurl now includes OpenLDAP and its version of that was used in the build, and then the curl tool can add libmetalink and its version of