We’ve argued for many years that governments should implement transparent processes to review and disclose the software vulnerabilities that they learn about. Such processes are essential for the cybersecurity of citizens, businesses, and governments themselves. For that reason, we’re delighted to report that the EU has taken a crucial step forward in that endeavour, by giving its cybersecurity agency an explicit new mandate to help European governments establish and implement these processes where requested.
The just-adopted EU Cybersecurity Act is designed to increase the overall level of cybersecurity across the EU, and a key element of the approach focuses on empowering the EU’s cybersecurity agency (‘ENISA’) to play a more proactive role in supporting the Union’s Member States in cybersecurity policy and practices. Since the legislative proposal was launched in 2017, we’ve argued that ENISA should be given the power to support EU Member States in the area of government vulnerability disclosure (GVD) review processes.
Malicious actors can exploit vulnerabilities to cause significant harm to individuals and businesses, and can cripple critical infrastructure. At the same time, governments often learn about software vulnerabilities and face competing incentives as to whether to disclose the existence of the vulnerability to the affected company immediately, or delay disclosure so they can use the vulnerability as an offensive/intelligence-gathering tool. For those reasons, it’s essential that governments have processes in place for reviewing and coordinating the disclosure of the software vulnerabilities that they learn about, as a key pillar in their strategy to defend against the nearly daily barrage of cybersecurity attacks, hacks, and breaches.
For several years, we’ve been at the forefront of calls for governments to put in place these processes. In the United States, we spoke out strongly in favor of the Protecting Our Ability to Counter Hacking Act (PATCH Act) and participated in the Centre for European Policy Studies’ Task Force on Software Vulnerability Disclosure, a broad stakeholder taskforce that in 2018 recommended EU and national-level policymakers to implement GVD review processes. In that context, our work on the EU Cybersecurity Act is a necessary and important continuation of this commitment.
We’re excited to see continued progress on this important issue of cybersecurity policy. The adoption of the Cybersecurity Act by the European Parliament today ensures that, for the first time, the EU has given legal recognition to the importance of EU Member States putting in place processes to review and manage the disclosure of vulnerabilities that they learn about. In addition, by giving the EU Cybersecurity Agency the power to support Member States in developing and implementing these processes upon request, the EU will help ensure that Member States with weaker cybersecurity resilience are supported in implementing this ‘next generation’ of cybersecurity policy.
We applaud EU lawmakers for this forward-looking approach to cybersecurity, and are excited to continue working with policymakers within the 28 EU Member States to see this vision for government vulnerability disclosure review processes realised at national and EU level. This will help Europe and all Europeans to be more secure.
Further reading:
- A step forward for government vulnerability disclosure in Europe
- Mozilla publishes recommendations on government vulnerability disclosure in Europe
- Vulnerability disclosure should be part of new EU Cybersecurity Strategy
Recently, Mark Zuckerberg posted a lengthy note outlining Facebook’s vision to integrate its three messaging services – WhatsApp, Messenger, and Instagram (through its Direct messaging functionality) – into one privacy and security oriented platform. The post positioned Facebook’s future around individual and small group conversations, rather than the “public forum” style communications through Facebook’s newsfeed platform. Initial coverage of the move, largely critical, has focused on the privacy and security aspects of this integrated platform, the history of broken promises on privacy and the changes that would be needed for Facebook’s business model to realize the goal. However, there’s a yet darker side to the proposal, one mostly lost in the post and coverage so far: Facebook is taking one step further to make its family of services into the newest walled garden, at the expense of openness and the broader digital economy.
Here’s the part of the post that highlights the evolution in progress:

Sounds good on its face, right? Except, what Facebook is proposing isn’t interoperability as most use that term. It’s more like intraoperability – making sure the various messaging services in Facebook’s own walled garden all can communicate with each other, not with other businesses and services. In the context of this post, it seems clear that Facebook will intentionally box out other companies, apps, and networks in the course of this consolidation. Rather than creating the next digital platform to take the entire internet economy forward, encouraging downstream innovation, investment, and growth, Facebook is closing out its competitors and citing privacy and security considerations as its rationale.
This is not an isolated incident – it’s a trend. For example, on August 1, 2018, Facebook shut off the “publish_actions” feature in one of its core APIs. This change gutted the practical ability of independent companies and developers to interoperate with Facebook’s services. Some services were forced to disconnect Facebook profiles or stop interconnecting with Facebook entirely. Facebook subsequently changed a long-standing platform policy that had prohibited the use of their APIs to compete, but the damage was done, and the company’s restrictive practices continue.
We can see further evidence of the intent to create a silo under the guise of security in Zuckerberg’s note where he says: “Finally, it would create safety and spam vulnerabilities in an encrypted system to let people send messages from unknown apps where our safety and security systems couldn’t see the patterns of activity.” Security and spam are real problems, but interoperability doesn’t need to mean opening a system up to every incoming message from any service. APIs can be secured by tokens and protected by policies and legal systems.
Without doubt, Facebook needs to prioritize the privacy of its users. Shutting down overly permissive APIs, even at the cost of some amount of competition and interoperability, can be necessary for that purpose – as with the Cambridge Analytica incident. But there’s a difference between protecting users and building silos. And designing APIs that offer effective interoperability with strong privacy and security guarantees is a solvable problem.
The long-term challenge we need to be focused on with Facebook isn’t just whether we can trust the company with our privacy and security – it’s also whether they’re using privacy and security simply as a cover to get away with anticompetitive
Back in 2014 I blogged about several ideas about how to make Firefox updates smaller.
Since then, we have been able to implement some of these ideas, and we also landed a few unexpected changes!
tl;dr
It's hard to measure exactly what the impact of all these changes are over time. As Firefox continues to evolve, new code and dependencies are added, old code removed, while at the same time the build system and installer/updater continue to see improvements. Nevertheless I was interested in comparing what the impact of all these changes would be.
To attempt a comparison, I've taken the latest release of Firefox as of March 6, 2019, which is Firefox 65.0.2. Since most of our users are on Windows, I've downloaded the win64 installer.
Next, I tried to reverse some of the changes made below. I re-compressed omni.ja, used bz2 compression for the MAR files, re-added the deleted images and startup cache, and used the old version of mbsdiff to generate the partial updates.
| Format | Current Size | "Old" Size | Improvement (%) | ||
|---|---|---|---|---|---|
| Installer | 45,693,888 | 56,725,712 | 19% | ||
| Complete Update | 49,410,488 | 70,366,869 | 30% | ||
| Partial Update (from 64.0.2) | 14,935,692 | 28,080,719 | 47% |
Small updates FTW!
Ideally most of our users are getting partial updates from version to version, and a nearly 50% reduction in partial update size is quite significant! Smaller updates mean users can update more quickly and reliably!
One of the largest contributors to our partial update sizes right now are the binary diff size for compiled code. For example, the patch for xul.dll alone is 13.8MB of the 14.9MB partial update right now. Diffing algorithms like courgette could help here, as could investigations into making our PGO process more deterministic.
Here are some of the things we've done to reduce update sizes in Firefox.
Shipping uncompressed omni.ja files
This one is a bit counter-intuitive. omni.ja files are basically just zip files, and originally were shipped as regular compressed zips. The zip format compressed each file in the archive independently, in contrast to something like .tar.bz2 where the entire archive is compressed at once. Having the individual files in the archive compressed makes both types of updates inefficient: complete updates are larger because compressing (in the MAR file) already compressed data (in the ZIP file) doesn't yield good results, and partial updates are larger because calculating a binary diff between two compressed blobs also doesn't yield good results. Also, our Windows installers have been using LZMA compression for a long time, and after switching to LZMA for update compression, we can achieve much greater compression ratios with LZMA of the raw data versus LZMA of zip (deflate) compressed data.
The expected impact of this change was ~10% smaller complete updates, ~40% smaller partial updates, and ~15% smaller installers for Windows 64 en-US builds.
Using LZMA compression for updates
Pretty straightforward idea: LZMA does a better job of compression than bz2. We also looked at brotli and zstd for compression, but LZMA performs the best so far for updates, and we're willing to spend quite a bit of CPU time to compress updates for the benefit of faster downloads.
LZMA compressed updates were first shipped for Firefox 56.
The expected impact of this change was 20% reduction for Windows 64 en-US updates.
Disable startup cache generation
This came out of some investigation about why partial updates were so large. I remember digging into this in the Toronto office with Jeff Muizelaar, and we noticed that one of the largest contributors to partial update sizes were the startup cache files. The buildid was encoded into the header of startup cache files, which effectively changes the entire compressed file. It was unclear whether shipping these provided any benefit, and so we experimented with turning them off. Telemetry didn't show any impact to startup times, and so we
Firefox is an open-source project, created by a vibrant community of paid and volunteer contributors from all over the world. Did you know that some of those contributors are students, who are sponsored or given course credit to make improvements to Firefox?
In this blog post, we want to talk about some student projects that have wrapped up recently, and also offer the students themselves an opportunity to reflect on their experience working on them.
If you or someone you know might be interested in developing Firefox as a student, there are some handy links at the bottom of this article to help get you started with some student programs. Not a student? No problem – come hack with us anyways!
Now let’s take a look at some interesting things that have happened in Firefox recently, thanks to some hard-working students.
Multi-select Tabs by Abdoulaye O. Ly
In the summer of 2018, Abdoulaye O. Ly worked on Firefox Desktop for Google Summer of Code. His project was to work on adding multi-select functionality to the tab bar in Firefox Desktop, and then adding context menu items to work on sets of tabs rather than individual ones. This meant Abdoulaye would be making changes in the heart of one of the most complicated and most important parts of Firefox’s user interface.
Abdoulaye’s project was a smash success! After a few months of baking and polish in Nightly, multi-select tabs shipped enabled by default to the general Firefox audience in Firefox 64. It was one of the top-line features for that release!
You can try it right now by holding down Ctrl/Cmd and clicking on individual tabs in the tab bar. You can also hold down Shift and select a range of tabs. Then, try right-clicking on the range to perform some operations. This way, you can bookmark a whole set of tabs, send them to another device, or close them all at once!
Here’s what Abdoulaye had to say about working on the project:
Being part of the multi-select project was one of my best experiences so far. Indeed, I had the opportunity to implement features that are being used by millions of Firefox users. In addition, it gave me the privilege of receiving a bunch of constructive reviews from my mentor and other Mozilla engineers, which has greatly boosted my software development skills. Now, I feel less intimidated when skimming through large code bases. Another aspect on which I have also made significant progress is on team collaboration, which was the most challenging part of my GSoC internship.
We want to thank Abdoulaye for collaborating with us on this long sought-after feature! He will continue his involvement at Mozilla with a summer internship in our Toronto office. Congratulations on shipping, and great work!
Better Certificate Error Pages by Trisha Gupta
University student Trisha Gupta contributed to Firefox as part of an Outreachy open source internship.
Her project was to make improvements to the certificate error pages that Firefox users see when a website presents a (seemingly) invalid security certificate. These sorts of errors can show up for a variety of reasons, only some of which are the fault of the websites themselves.
The Firefox user experience and security engineering teams collaborated on finding ways to convey these types of errors to users in a better, more understandable way. They produced a set of designs, fine-tuned them in user testing, and handed them off to Trisha so she could start implementing them in Firefox.
In some cases, this meant adding entirely new pages, such as the “clock skew” error page. That page tells users that the certificate error is caused by their system clocks being off by a few years, which happens a lot more often than one might think.
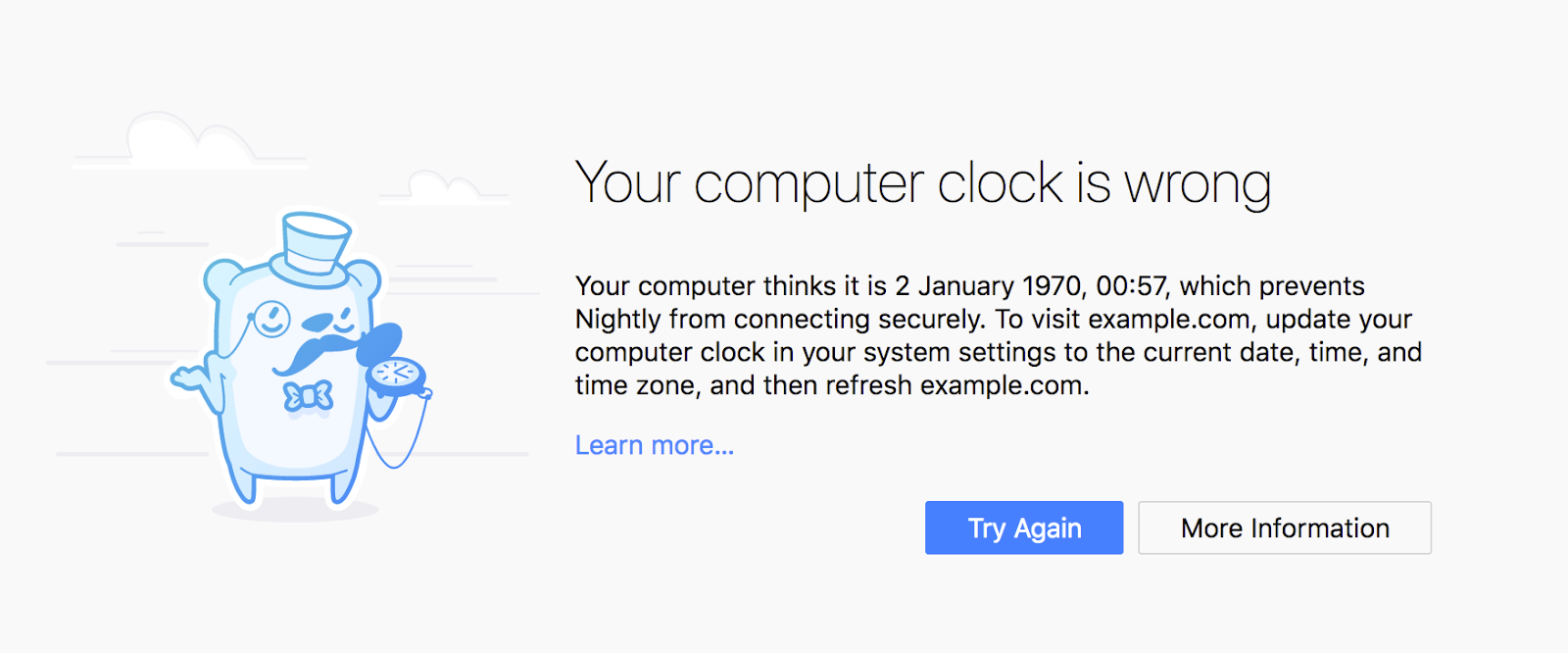
What year is it?
We are really grateful for Trisha’s fantastic work on this important project, and for the Outreachy program that enabled her to find this opportunity. Here is what Trisha says about her internship:
The whole experience working with the Mozillians was beyond fruitful. Everyone on my team, especially my mentor were very helpful and welcoming. It was my first time working with such a huge company and such an important team. Hence, the biggest
Flowers in bloom, birds singing, cluttered debris everywhere. It’s Spring cleaning season. We may not be able to help with that mystery odor in the garage, but here are some … Read more
The post Spring Cleaning with Browser Extensions appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/spring-cleaning-with-browser-extensions/
With the release of Firefox 66, we are pleased to welcome the 39 developers who contributed their first code change to Firefox in this release, 35 of whom were brand new volunteers! Please join us in thanking each of these diligent and enthusiastic individuals, and take a look at their contributions:
- 3DIndian: 1022039
- adam.kolodko: 1508990
- bitnotri: 1461737
- chengy12: 1518220
- danielleleb12: 1517756
- dhyey35: 1517505
- mathijs: 1514880, 1515354, 1519645
- matthewacha: 1517753
- nickcowles9575: 1517529
- quasicomputational: 1422235
- sharath.savasere: 1516221
- shivambalikondwar: 1468749
- thomasmo: 1474034, 1508225, 1522989
- tobias: 1513917
- sdaswani: 1517607
- Agboola Mukhtar : 1517442
- Akash Srivastava: 1516536, 1519920
- Akshay Kumar: 1508115, 1522145
- Alex Kong: 1508988
- Artem Polivanchuk: 1521715, 1521716, 1522424
- Garvit Khatri: 1519791
- Irvin Ives Lau: 1495189, 1509634
- Jeremy Lain'e: 1517731
- John Lin: 1516089
- Jonas Allmann: 1498238
- Julia McGeoghan: 1508991
- June Wilde: 1415743, 1508782
- Kaio Augusto de Camargo: 1513496
- Kristian Klausen: 1385706
- Muchtar: 1508984
- Ola Gasidlo: 1500353, 1518559,
Summary
Socorro is the crash ingestion pipeline for Mozilla's products like Firefox. When Firefox crashes, the crash reporter collects data about the crash, generates a crash report, and submits that report to Socorro. Socorro saves the crash report, processes it, and provides an interface for aggregating, searching, and looking at crash reports.
This blog post summarizes Socorro activities in February.
Read more… (6 mins to read)
https://bluesock.org/~willkg/blog/mozilla/socorro_2019_02.html
In the past month, we merged 176 PRs in the Servo organization’s repositories.
Planning and Status
Our roadmap is available online. Plans for 2019 will be published soon.
This week’s status updates are here.
Exciting works in progress
- peterjoel is replacing the preferences hashtable with a data structure generated at build time.
- ferjm is implementing parts of the Shadow DOM API in order to support UI for media controls and complex form controls.
- asajeffrey is implementing support for WebVR reftests
Notable Additions
- jdm improved the rendering of 2d canvas paths with transforms applied.
- sreeise implemented the DOM interfaces for audio, text, and video tracks.
- ceyusa added support for hardware accelerated rendering in the media backend.
- jdm prevented a panic when going back in history from a page using WebGL.
- paulrouget enabled support for sharing Gecko’s VR process on Oculus devices.
- asajeffrey made fullscreen content draw over top of any other page content.
- jdm fixed a regression in hit-testing certain kinds of content.
- paulrouget added automatic header file generation for the C embedding API.
- jdm converted the Magic Leap port to use the official embedding API.
- Manishearth added support for media track constraints to getUserMedia.
- asajeffrey made the VR embedding API more flexible.
- Manishearth implemented support for sending and receiving video streams over WebRTC.
- jdm redesigned the media dependency graph to reduce time spent compiling Servo when making changes.
- Manishearth added support for extended attributes on types in the WebIDL parser.
- asajeffrey avoided a deadlock in the VR thread.
- jdm fixed a severe performance problem when loading sites that use a lot of
innerHTMLmodification. - asajeffrey implemented a test VR display that works on desktop.
- Manishearth implemented several missing WebRTC callbacks.
- jdm corrected the behaviour of the
contentWindowAPI when navigating an iframe backwards in history.
New Contributors
 On June 30, 2010 I was:
On June 30, 2010 I was:
- Sleepy. My daughter had just been born a few months prior and was spending her time pooping, crying, and not sleeping (as babies do).
- Busy. I was working at Research in Motion (it would be three years before it would be renamed BlackBerry) on the BlackBerry Browser for BlackBerry 6.0. It was a big shift for us since that release was the first one using WebKit instead of the in-house “mango” rendering engine written in BlackBerry-mobile-dialect Java.
- Keen. Apparently I was filing a bug against Firefox 3.6.6?!
Yeah. I had completely forgotten about this. Apparently while reading my RSS feeds in Google Reader (that doesn’t make me old, does it?) taking in news from Dragonmount about the Wheel of Time (so I guess I’ve always been a nerd, then) the text would sometimes just fail to render. I even caught it happening on the old Bugzilla “possible duplicate finder” UI (see above).
The only reason I was reminded this exists was because I received bugmail on my personal email address when someone accidentally added and removed themselves from the Cc list.
Pretty sure this bug, being no longer reproducible, still in UNCONFIRMED state, and filed against a pre-rapid-release version Firefox is something I should close. Yeah, I’ll just go and do that.
:chutten
The other day I was doing some research on DOM methods and properties that Chrome implements, and has a usecounter for, but don't exist in Firefox.
defaultstatus caught my eye, because like, there's also a use counter for defaultStatus.
(The discerning reader will notice there's a lowercase and a lowerCamelCase version. The less-discerning reader should maybe slow down and start reading from the beginning.)
As far as I know, there's no real spec for these old BOM (Baroque Object Model) properties. It's supposed to allow you to set the default value for window.status, but it probably hasn't done anything in your browser for years.

Chrome inherited lowercase defaultstatus from Safari, but I would love to know why Safari (or KHTML pre-fork?) added it, and why Opera, Firefox or IE never bothered. Did a site break? Did someone complain about a missing status on a page load? Did this all stem from a typo?
DOMWindow.idl has the following similar-ish comments over the years and probably more, but nothing that points to a bug:
This attribute is an alias of defaultStatus and is necessary for legacy uses. For compatibility with legacy content.
It's hard to pin down exactly when it was added. It's in Safari 0.82's kjs_window.cpp. And in this "old" kde source tree as well. It is in current KHTML sources, so that suggests it was inherited by Safari after all.
Curious to see some code in the wild, I did some bigquerying with BigQuery on the HTTPArchive dataset and got a list of ~3000 sites that have a lowercase defaultstatus. Very exciting stuff.
There's at least 4 kinds of results:
1) False-positive results like var foo_defaultstatus. I could re-run the query, but global warming is real and making Google cloud servers compute more things will only hasten our own destruction.
2) User Agent sniffing, but without looking at navigator.userAgent. I guess you could call it User Agent inference, if you really cared to make a distinction.
Here's an example from some webmail script:
O.L3 = function(n) {
switch (n) {
case 'ie':
p = 'execScript';
break;
case 'ff':
p = 'Components';
break;
case 'op':
p = 'opera';
break;
case 'sf':
case 'gc':
case 'wk':
p = 'defaultstatus';
break;
}
return p && window[p] !== undefined;
}
And another from some kind of design firm's site:
browser = (function() {
return {
During the last month we attended two events: FOSDEM, Europe’s premier free software event, and a meetup with the folks behind DeltaChat. At both events we met great people, had interesting conversations, and talked through potential future collaboration with Thunderbird. This post details some of our conversations and insights gather from those events.
FOSDEM 2019
Magnus (Thunderbird Technical Manager), Kai (Thunderbird Security Engineer), and I (Ryan, Community Manager) arrived in Brussels for Europe’s premier free software event (free as in freedom, not beer): FOSDEM. I was excited to meet many of our contributors in-person who I’d only met online. It’s exhilarating to be looking someone in the eye and having a truly human interaction around something that you’re passionate about – this is what makes FOSDEM a blast.
There are too many conversations that we had to detail in their entirety in this blog post, but below are some highlights.
Chat over IMAP/Email
One thing we discussed at FOSDEM was Chat over IMAP with the people from Open-Xchange. Robert even gave a talk called “Break the Messaging Silos with COI”. They made a compelling case as to why email is a great medium for chat, and the idea of using a chat that lets you select the provider that stores your data – genius! We followed on FOSDEM with a meetup with the DeltaChat folks in Freiburg, Germany where we discussed encryption and Chat over Email.
Encryption, Encryption, Encryption
We discussed encryption a lot, primarily because we have been thinking about it a lot as a project. With the rising awareness of users about privacy concerns in tech, services like Protonmail getting a lot of attention, and in acknowledgement that many Thunderbird users rely on encrypted Email for their security – it was important that we use this opportunity to talk with our sister projects, contributors, and users about how we can do better.
Sequoia-PGP
We were very grateful that the Sequoia-PGP team took the time to sit down with us and listen to our ideas and concerns surrounding improving encrypted Email support in Thunderbird. Sequoia-PGP is an OpenPGP library, written in Rust that appears to be pretty solid. There is a potential barrier to incorporating their work into Thunderbird, in license compatibility (we use MPL and they use GPL). But we discussed a wide range of topics and have continued talking through what is possible following the event, it is my hope that we will find some way to collaborate going forward.
One thing that stood out to me about the Sequoia team was their true interest in seeing Thunderbird be the best that it can be, and they seemed to genuinely want to help us. I’m grateful to them for the time that they spent and look forward to getting another opportunity to sit with them and chat.
pEp
Following our discussion with the Sequoia team, we spoke to Volker of the pEp Foundation. Over dinner we discussed Volker’s vision of privacy by default and lowering the barrier of using encryption for all communication. We had spoken to Volker in the past, but it was great to sit around a table, enjoy a meal, and talk about the ways in which we could collaborate. pEp’s approach centers around key management and improved user experience to make encryption more understandable and easier to manage for all users (this is a simplified explanation, see pEp’s website for more information). I very much appreciated Volker taking the time to walk us through their approach, and sharing ideas as to how Thunderbird might move forward. Volker’s passion is infectious and I was happy to get to spend time with him discussing the pEp project.
EteSync
People close to me know that I have a strong desire to see encrypted calendar and contact sync become a standard (I’ve even grabbed the domains cryptdav.com and cryptdav.org). So when I heard that Tom of EteSync was at FOSDEM, I emailed him to set up a time to talk. EteSync is secure, end-to-end encrypted and privacy respecting sync for your contacts, calendars and tasks. That hit the mark!
In our conversation we discussed potential ways to work together, and I encouraged him to try and make this into a standard. He was quite interested and we talked through who we should pull into the conversation to move this forward. I’m happy to say that we’ve managed to get Thunderbird Council Chairman and Lightning Calendar author Philipp Kewisch in on the conversation – so I hope to see us move this along.
We’ve written a lot recently about the dangers that the EU Terrorist Content regulation poses to internet health and user rights, and efforts to combat violent extremism. One aspect that’s particularly concerning is the rule that all online hosts must remove ‘terrorist content’ within 60 minutes of notification. Here we unpack why that obligation is so problematic, and put forward a more nuanced approach to content takedowns for EU lawmakers.
Since the early days of the web, ‘notice & action’ has been the cornerstone of online content moderation. As there is so much user-generated content online, and because it is incredibly challenging for an internet intermediary to have oversight of each and every user activity, the best way to tackle illegal or harmful content is for online intermediaries to take ‘action’ (e.g. remove it) once they have been ‘notified’ of its existence by a user or another third party. Despite the fast-changing nature of internet technology and policy, this principle has shown remarkable resilience. While it often works imperfectly and there is much that could be done to make the process more effective, it remains a key tool for online content control.
Unfortunately, the EU’s Terrorist Content regulation stretches this tool beyond its limit. Under the proposed rules, all hosting services, regardless of their size, nature, or exposure to ‘terrorist content’ would be obliged to put in place technical and operational infrastructure to remove content within 60 minutes of notification. There’s three key reasons why this is a major policy error:
- Regressive burden: Not all internet companies are the same, and it is reasonable to suggest that in terms of online content control, those who have more should do more. More concretely, it is intuitive that a social media service with billions in revenue and users should be able to remove notified content more quickly than a small family-run online service with a far narrower reach. Unfortunately however, this proposal forces all online services – regardless of their means – to implement the same ambitious 60-minute takedown timeframe. This places a disproportionate burden on those least able to comply, giving an additional competitive advantage to the handful of already dominant online platforms.
- Incentivises over-removal: A crucial aspect of the notice & action regime is the post-notification review and assessment. Regardless of whether a notification of suspected illegal content comes from a user, a law enforcement authority, or a government agency, it is essential that online services review the notification to assess its validity and conformity with basic evidentiary standards. This ‘quality assurance’ aspect is essential given how often notifications are either inaccurate, incomplete, or in some instances, bogus. However, a hard deadline of 60 minutes to remove notified content makes it almost impossible for most online services to do the kind of content moderation due diligence that would minimise this risk. What’s likely to result is the over-removal of lawful content. Worryingly, the risk is especially high for ‘terrorist content’ given its context-dependent nature and the thin line between intentionally terroristic and good-faith public interest reporting.
- Little proof that it actually works: Most troubling about the European Commission’s 60-minute takedown proposal is that there doesn’t seem to be any compelling reason why 60 minutes is an appropriate or necessary timeframe. To this date, the Commission has produced no research or evidence to justify this approach; a surprising state of affairs given how radically this obligation departs from existing policy norms. At the same time, a ‘hard’ 60 minute deadline strips the content moderation process of strategy and nuance, allowing for no distinction between type of terrorist content, it’s likely reach, or the likelihood that it will incite terrorist offences. With no distinction there can be no prioritisation.
For context, the decision by the German government to mandate a takedown deadline of 24 hours for ‘obviously illegal’ hate speech in its 2017 ‘NetzDG’ law sparked considerable
I had a brilliant idea! How do I get stakeholders to understand whether the market sees it in the same way?

People in startups have tried so hard to avoid spending time and money on building a product that doesn’t achieve the product/ market fit, so do tech companies. Resources are always limited. Making right decisions on where to put their resources are serious in organizations, and sometimes, it’s even harder to make one than in a startup.
ChecknShare, an experimental product idea from Mozilla Taipei for improving Taiwanese seniors’ online sharing experience, has learned a lot after doing several rounds of validations. In our retrospective meeting, we found the process can be polished to be more efficient when we both validate our ideas and communicate with our stakeholders at the same time.
Here are 3 steps that I suggest for validating your idea:
Step 1: Define hypotheses with stakeholders
Having hypotheses in the planning stage is essential, but never forget to include stakeholders when making your beautiful list of hypotheses. Share your product ideas with stakeholders, and ask them if they have any questions. Take their questions into consideration to plan for a method which can cover them all.
Your stakeholders might be too busy to participate in the process of defining the hypotheses. It’s understandable, you just need to be sure they all agree on the hypotheses before you start validating.
Step 2: Identify the purpose of validating your idea
Are you just trying to get some feedback for further iteration? Or do you need to show some results to your stakeholders in order to get some engagement/ resources from them? The purpose might influence how you select the validation methods.
There are two types of validation methods, qualitative and quantitative. Quantitative methods focus on finding “what the results look like”, while qualitative methods focus on “why/ how these results came about”. If you’re trying to get some insights for design iteration, knowing “why users have trouble falling in love with your idea” could be your first priority in the validation stage. Nevertheless, things might be different when you’re trying to get your stakeholders to agree.
From the path that ChecknShare has gone through, quantitative results were much easier to influence stakeholders as concrete numbers were interpreted as a representation of a real world situation. I’m not saying quantitative methods are “must-dos” during the validation stage, but be sure to select a method that speaks your stakeholders’ language.
Step 3: Select validation methods that validate the hypotheses precisely
With the hypotheses that were acknowledged by your stakeholders and the purpose behind the validation, you can select methods wisely without wasting time on inconsequential work.
In the following, I’m going to introduce the 5 validation methods that we conducted for ChecknShare and the lessons we’ve learned from each of them. I hope these shared lessons can help you find your perfect one. Starting with the qualitative methods:
Qualitative Validation Methods
1. Participatory Workshop
The participatory workshop was an approach for us to validate the initial ideas generated from the design sprint. During the co-design process, we had 6 participants who matched with our target user criteria. We prioritized the scenario, got first-hand feedback for the ideas, and did quick iterations with our participants. (For more details on how we hosted the workshop, please look at the blog I wrote previously.)
Although hosting a workshop externally can be challenging due to some logistic works like recruiting relevant participants and finding a large space for accommodating people, we see participatory workshop as a fast and effective approach for having early interactions with our target users.
2. Physical pitching survey

In order to see how our target market reacts to the idea in the early stage, we hosted a pitching session in a local learning center that offered free courses for seniors to learn how to use smartphones. During the pitching session, we handed out paper questionnaires to investigate their smartphone behaviors, interests of the idea, and their willingness to participate in our future user testings.
It was our first time experimenting with a physical survey instead of sitting in the office and deploying
Please join us in congratulating Viswaprasath KS, our Rep of the Month for November 2018!
Viswaprasath KS, also know as iamvp7, is a long time Mozillian from India who joined the Mozilla Rep program in June 2013. By profession he works as a software developer. He initially started contributing with designs and SUMO (Army of Awesome). He was also part of Firefox Student Ambassador E-Board and helped students to build exciting Firefox OS apps. In May 2014 he became one of the Firefox OS app reviewers.

Currently he is an active Mozilla TechSpeaker and loves to evangelise about WebExtensions and Progressive Web Apps. He has been an inspiration to many and loves to keep working towards a better web. He has worked extensively on Rust and WebExtensions, conducting many informative sessions on these topics recently. Together with other Mozillians he also wrote “Building Browser Extension”.
Thanks Viswaprasath, keep rocking the Open Web! 
To congratulate him, please head over to Discourse!
https://blog.mozilla.org/mozillareps/2019/03/06/rep-of-the-month-november-2018/
On Thursday, the Indian government approved an ordinance — an extraordinary procedure allowing the government to enact legislation without Parliamentary approval — that threatens to dilute the impact of the Supreme Court’s decision last September.
The Court had placed fundamental limits to the otherwise ubiquitous use of Aadhaar, India’s biometric ID system, including the requirement of an authorizing law for any private sector use. While the ordinance purports to provide this legal backing, its broad scope could dilute both the letter and intent of the judgment. As per the ordinance, companies will now be able to authenticate using Aadhaar as long as the Unique Identification Authority of India (UIDAI) is satisfied that “certain standards of privacy and security” are met. These standards remain undefined, and especially in the absence of a data protection law, this raises serious concerns.
The swift movement to foster expanded use of Aadhaar is in stark contrast to the lack of progress on advancing a data protection bill that would safeguard the rights of Indians whose data is implicated in this system. Aadhaar continues to be effectively mandatory for a vast majority of Indian residents, given its requirement for the payment of income tax and various government welfare schemes. Mozilla has repeatedly warned of the dangers of a centralized database of biometric information and authentication logs.
The implementation of these changes with no public consultation only exacerbates the lack of public accountability that has plagued the project. We urge the Indian government to consider the serious privacy and security risks from expanded private sector use of Aadhaar. The ordinance will need to gain Parliamentary approval in the upcoming session (and within six months) or else it will lapse. We urge the Parliament not to push through this law which clearly dilutes the Supreme Court’s diktat, and any subsequent proposals must be preceded by wide public consultation and debate.
The post Indian government allows expanded private sector use of Aadhaar through ordinance (but still no movement on data protection law) appeared first on Open Policy & Advocacy.
Hello Mozillians,
We are happy to let you know that Friday, March 8th, we are organizing DevEdition 66 Beta 14 Testday. We’ll be focusing our testing on: Firefox Screenshots, Search, Build installation & uninstallation.
Check out the detailed instructions via this etherpad.
No previous testing experience is required, so feel free to join us on #qa IRC channel where our moderators will offer you guidance and answer your questions.
Join us and help us make Firefox better!
See you on Friday!
https://quality.mozilla.org/2019/03/devedition-66-beta-14-friday-march-8th/