Hello Mozillians,
We are happy to let you know that Friday, March 29th, we are organizing Firefox 67 Beta 6 Testday. We’ll be focusing our testing on: Anti-tracking (Fingerprinting and Cryptominers) and Media playback & support.
Check out the detailed instructions via this etherpad.
No previous testing experience is required, so feel free to join us on #qa IRC channel where our moderators will offer you guidance and answer your questions.
Join us and help us make Firefox better!
See you on Friday!
TL;DR: Yes, very much.
The issue
I’ve written a number of blog posts on LastPass security issues already. The latest one so far looked into the way the LastPass data is encrypted before it is transmitted to the server. The thing is: when your password manager uploads all data to its server backend, you normally want to be very certain that the data visible to the server is useless both to attackers who manage to compromise the server and company employees running that server. Early last year I reported a number of issues that allowed subverting LastPass encryption with comparably little effort. The most severe issues have been addressed, so all should be good now?
Sadly, no. It is absolutely possible for a password manager to use a server for some functionality while not trusting it. However, LastPass has been designed in a way that makes taking this route very difficult. In particular, the decision to fall back to server-provided pages for parts of the LastPass browser extension functionality is highly problematic. For example, whenever you access Account Settings you leave the trusted browser extension and access a web interface presented to you by the LastPass server, something that the extension tries to hide from you. Some other extension functionality is implemented similarly.
The glaring hole
So back in November I discovered an API meant to accommodate this context switch from the extension to a web application and make it transparent to the user. Not sure how I managed to overlook it on my previous strolls through the LastPass codebase but the getdata and keyplug2web API calls are quite something. The response to these calls contains your local encryption key, the one which could be used to decrypt all your server-side passwords.
There has been a number of reports in the past about that API being accessible by random websites. I particularly liked this security issue uncovered by Tavis Ormandy which exploited an undeclared variable to trick LastPass into loosening up its API restrictions. Luckily, all of these issues have been addressed and by now it seems that only lastpass.com and lastpass.eu domains can trigger these calls.
Oh, but the chances of some page within lastpass.com or lastpass.eu domain to be vulnerable aren’t exactly low! Somebody thought of that, so there is an additional security measure. The extension will normally ignore any getdata or keyplug2web calls, only producing a response once after this feature is unlocked. And it is unlocked on explicit user actions such as opening Account Preferences. This limits the danger considerably.
Except that the action isn’t always triggered by the user. There is a “breach notification” feature where the LastPass server will send notifications with arbitrary text and link to the user. If the user clicks the link here, the keyplug2web API will be unlocked and the page will get access to all of the user’s passwords.
The attack
LastPass is run by LogMeIn, Inc. which is based in United States. So let’s say the NSA knocks on their door: “Hey, we need your data on XYZ so we can check their terrorism connections!” As we know by now, NSA does these things and it happens to random people as well, despite not having any ties to terrorism. LastPass data on the server is worthless on its own, but NSA might be able to pressure the company into sending a breach notification to this user. It’s not hard to choose a message in such a way that the user will be compelled to click the link, e.g. “IMPORTANT: Your Google account might be compromised. Click to learn more.” Once they click it’s all over, my proof-of-concept successfully downloaded all the data and decrypted it with the key provided. The page can present the user with an “All good, we checked it and your account isn’t affected” message while the NSA walks away with the data.
The other scenario is of course a rogue company employee doing the same on their own. Here LastPass claims that there are internal processes to prevent employees from abusing their power in such a way. It’s striking however how their response mentions “a single person within development” — does it include server administrators or do we have to trust those? And what about two rogue employees? In the end, we have to take their word on their ability to prevent an inside job.
The fix
I reported this issue via Bugcrowd on November 22, 2018. As of
Or: The Best Way To Do Something Is To At Least Try
We all know the story: you can’t make money on open source. Is it really true?
I’m thinking about this now because Mozilla would like to diversify its revenue in the next few years, and one constraint we have is that everything we do is open source.
There are dozens (hundreds?) of successful open source projects that have tried to become even just modest commercial enterprises, some very seriously. Results aren’t great.
I myself am trying to pitch a commercial endeavor in Mozilla right now (if writing up plans and sending them into the ether can qualify as “pitching”), and this question often comes up in feedback: can we sell something that is open source?
I have no evidence that we can (or can’t), but I will make this assertion: it’s hard to sell something that wasn’t designed to be sold.
We treat open source like it’s a poison pill for a commercial product. And yes, with an open source license it’s harder to force someone to pay for a product, though many successful businesses exist without forcing anyone.
I see an implicit assumption that makes it harder to think about this: the idea that if something is useful, it should be profitable. It’s an unspoken and morally-infused expectation, a kind of Just World hypothesis: if something has utility, if it helps people, if it’s something the world needs, if it empowers other people, then there should be a revenue opportunity. It should be possible for the thing to be your day job, to make money, to see some remuneration for your successful effort in creating or doing this thing.
That’s what we think the world should be like, but we all know it isn’t. You can’t make a living making music. Or art. You can’t even make a living taking care of children. I think this underlies many of this moment’s critiques of capitalism: there’s too many things that are important, even needed, or that fulfill us more than any profitable item, and yet are economically unsustainable.
I won’t try to fix that in this blog post, only note: not all good things make money.
But we know there is money in software. Lots of money! Is the money in secrets? If OpenSSL was secret, could it make money? If it had a licensing paywall, could it make money? Seems unlikely. The license isn’t holding it back. It’s just not shaped like something that makes money. Solving important problems isn’t enough.
So what can you get paid to do?
- People will pay a little for apps; not a lot, but a bit. Scaling up requires marketing and capital, which open source projects almost never have (and I doubt many open source projects would know what to do with capital if they had it).
- There’s always money in ads. Sadly. This could potentially offend someone enough to actually repackage your open source software with ads removed. As a form of price discrimination (e.g., paid ad removal) I think you could avoid defection.
- Fully-hosted services: Automattic’s wordpress.com is a good example here. Is Ghost doing OK? These are complete solutions: you don’t just get software, you get a website.
- People will pay if you ensure they get a personalized solution. I.e., consulting. Applied to software you get consultingware. While often maligned, many real businesses are built on this. I think Drupal is in this category.
- People will pay you for your dedicated and ongoing attention. In other words: a day job as an employee. It feels unfair to put this option on the list, but it’s such a natural progression from consultingware, and such a dominant pattern in open source that I think it deserves acknowledgement.
- Anything paired with a physical device. People will judge the value based on the hardware and software experience together.
- I’m not sure if Firefox makes money (indirectly) from ads, or as compensation for maintaining monopoly positions.
I’m sure I’m missing some interesting ideas from that list.
But if you have a business concept, and you think it might work, what does open source even have to do with it? Don’t we learn: focus on your business! On your customer! Software licensing seems like a distraction, even software is a questionable thing to focus on, separate from the business. Maybe this is why you can’t make money with open source: it’s a distraction. The question isn’t open-source-vs-proprietary, but open-source-vs-business-focused.
Another lens might be: who are you selling to? Classical scratch-your-own-itch open source software is built by programmers
In the past week, we merged 50 PRs in the Servo organization’s repositories.
Planning and Status
Our roadmap is available online. Plans for 2019 will be published soon.
This week’s status updates are here.
Screenshots

A standalone demo of Pathfinder running on a Magic Leap device.
Exciting works in progress
- asajeffrey is building a Magic Leap demo of the Pathfinder project.
- peterjoel is replacing the preferences hashtable with a data structure generated at build time.
- ferjm is implementing parts of the Shadow DOM API in order to support UI for media controls and complex form controls.
Notable Additions
- waywardmonkeys updated harfbuzz to version 2.3.1.
- gterzian fixed an underflow error in the HTTP cache.
- waywardmonkeys improved the safety of the harfbuzz bindings.
- Manishearth removed a bunch of unnecessary duplication that occurred during XMLHttpRequest.
- georgeroman implemented a missing WebDriver API.
- jdm made ANGLE build a DLL on Windows.
- gterzian prevented tasks from running in non-active documents.
New Contributors
- Aron Zwaan
- Caio
- violet
Interested in helping build a web browser? Take a look at our curated list of issues that are good for new contributors!
TenFourFox Feature Parity Release 13 final is now available for testing (downloads, hashes, release notes). I added Olga's minimp3 patch for correctness; otherwise, there are no additional changes except for several security updates and to refresh the certificate and TLD stores. As usual it will go live Monday evening Pacific time assuming no difficulties.
I have three main updates in mind for TenFourFox FPR14: expanding FPR13's new AppleScript support to allow injecting JavaScript into pages (so that you can drive a web page by manipulating the DOM elements within it instead of having to rely on screen coordinates and sending UI events), adding Olga's ffmpeg framework to enable H.264 video support with a sidecar library (see the previous post for details on the scheme), and a possible solution to allow JavaScript async functions which actually might fix quite a number of presently non-working sites. I'm hopeful that combined with another parser hack this will be enough to restore Github functionality on TenFourFox, but no promises. Unfortunately, it doesn't address the infamous this is undefined problem that continues to plague a number of sites and I still have no good solution for that. These projects are decent-sized undertakings, so it's possible one or two might get pushed to FPR15. FPR14 is scheduled for May 14 with Firefox 67.
Meanwhile, I took a close look at the upcoming Raptor Blackbird at the So Cal Linux Expo 17. If the full big Talos II I'm typing this on is still more green than you can dream, the smaller Blackbird may be just your size to get a good-performing 64-bit Power system free of the lurking horrors in modern PCs at a better price. Check out some detailed board pics of the prototype and other shots of the expo on Talospace. If you're still not ready to jump, I'll be reviewing mine when it arrives hopefully later this spring.
http://tenfourfox.blogspot.com/2019/03/tenfourfox-fpr13-available.html
Like millions of people around the world, the Mozilla team has been deeply saddened by the news of the terrorist attack against the Muslim community in Christchurch, New Zealand.
The news of dozens of people killed and injured while praying in their place of worship is truly upsetting and absolutely abhorrent.
This is a call to all of us to look carefully at how hate spreads and is propagated and stand against it.
The post Mozilla statement on the Christchurch terror attack appeared first on Open Policy & Advocacy.
https://blog.mozilla.org/netpolicy/2019/03/15/mozilla-statement-on-the-christchurch-terror-attack/
A year ago, Mozilla Foundation started a search for a VP, Leadership Programs. The upshot of the job: work with people from around the world to build a movement to ensure our digital world stays open, healthy and humane. Over a year later, we’re in the second round of this search — finding the person to drive this work isn’t easy. However, we’re getting closer, so it’s time for an update.
At a nuts and bolts level, the person in this role will support teams at Mozilla that drive our thought leadership, fellowships and events programs. This is a great deal of work, but fairly straightforward. The tricky part is helping all the people we touch through these programs connect up with each other and work like a movement — driving to real outcomes that make digital life better.
While the position is global in scope, it will be based in Europe. This is in part because we want to work more globally, which means shifting our attention out of North America and towards African, European, Middle Eastern and South Asian time zones. Increasingly, it is also because we want to put a significant focus on Europe itself.
Europe is one of the places where a vision of an internet that balances public and private interests, and that respects people’s rights, has real traction. This vision spans everything from protecting our data to keeping digital markets open to competition to building a future where we use AI responsibly and ethically. If we want the internet to get better globally then learning from, and being more engaged with, Europe and Europeans has to be a central part of the plan.
The profile for this position is quite unique. We’re looking for someone who can think strategically and represent Mozilla publically, while also leading a distributed team within the organization; has a deep feel for both the political and technical aspects of digital life; and shares the values outlined in the Mozilla Manifesto. We’re also looking for someone who will add diversity to our senior leadership team.
In terms of an update: we retained the recruiting firm Perrett Laver in January to lead the current round of the search. We recently met with the recruiters to talk over 50 prospective candidates. There are some great people in there — people coming from the worlds of internet governance, open content, tech policy and the digital side of international development. We’re starting interviews with a handful of these people over the coming weeks — and still keeping our ear to the ground for a few more exceptional candidates as we do.
Getting this position filled soon is critical. We’re at a moment in history where the world really needs more people rolling up their sleeves to create a better digital world — this position is about gathering and supporting these people. The good news: I’m starting to feel optimistic that we can get this position filled by the middle of 2019.
PS. If you want to learn more about this role, here is the full recruiting package.
The post VP search update — and Europe appeared first on Mark Surman.
https://marksurman.commons.ca/2019/03/15/vp-search-update-and-europe/
I recently decided that the basic web hosting I was using wasn’t quite a configurable or powerful as I would like so I have started paying for a VPS and am slowly moving all my sites over to it. One of the things I decided was that I wanted the majority of services it ran to be running under Docker. Docker has its pros and cons but the thing I like about it is that I can define what services run, how they run and where they store all their data in a single place, separate from the rest of the server. So now I have a /srv/docker directory which contains everything I need to backup to ensure I can reinstall all the services easily, mostly regardless of the rest of the server.
As I was adding services I quickly realised I had a problem to solve. Some of the services were obviously external facing, nginx for example. But a lot should not be exposed to the public internet but needed to still be accessible, web management interfaces etc. So I wanted to figure out how to easily access them remotely.
I considered just setting up port forwarding or a socks proxy over ssh. But this would mean having to connect to ssh whenever needed and either defining all the ports and docker IPs (which I would then have to make static) in the ssh config or having to switch proxies in my browser whenever I needed to access a service and also would only really support web protocols.
Exposing them publicly anyway but requiring passwords was another option, I wasn’t a big fan of this either though. It would require configuring an nginx reverse proxy or something everytime I added a new service and I thought I could come up with something better.
At first I figured a VPN was going to be overkill, but eventually I decided that once set up it would give me the best experience. I also realised I could then set up a persistent VPN from my home network to the VPS so when at home, or when connected to my home network over VPN (already set up) I would have access to the containers without needing to do anything else.
Alright, so I have a home router that handles two networks, the LAN and its own VPN clients. Then I have a VPS with a few docker networks running on it. I want them all to be able to access each other and as a bonus I want to be able to just use names to connect to the docker containers, I don’t want to have to remember static IP addresses. This is essentially just using a VPN to bridge the networks, which is covered in many other places, except I had to visit so many places to put all the pieces together that I thought I’d explain it in my own words, if only so I have a single place to read when I need to do this again.
In my case the networks behind my router are 10.10.* for the local LAN and 10.11.* for its VPN clients. On the VPS I configured my docker networks to be under 10.12.*.
0. Configure IP forwarding.
The zeroth step is to make sure that IP forwarding is enabled and not firewalled any more than it needs to be on both router and VPS. How you do that will vary and it’s likely that the router will already have it enabled. At the least you need to use sysctl to set net.ipv4.ip_forward=1 and probably tinker with your firewall rules.
1. Set up a basic VPN connection.
First you need to set up a simple VPN connection between the router and the VPS. I ended up making the VPS the server since I can then connect directly to it from another machine either for testing or if my home network is down. I don’t think it really matters which is the “server” side of the VPN, either should work, you’ll just have to invert some of the description here if you choose the opposite.
There are many many tutorials on doing this so I’m not going to talk about it much. Just one thing to say is that you must be using certificate authentication (most tutorials cover setting this up), so the VPS can identify the router by its common name. Don’t add any “route” configuration yet. You could use redirect-gateway in the router config to make some of this easier, but that would then mean that all your internet traffic (from everything on the home LAN) goes through the VPN which I didn’t want. I set the VPN addresses to be in 10.12.10.* (this subnet is not used by any of the docker networks).
Once you’re done here the router and the VPS should be able to ping their IP addresses on the VPN tunnel. The VPS IP is 10.12.10.1, the router’s gets assigned on connection. They won’t be able to reach beyond that yet though.
2. Make the docker containers visible to the router.
Right now the router isn’t able to send packets to the docker containers because it doesn’t know how to get them there. It knows that anything for 10.12.10.* goes through the tunnel, but has no idea that other subnets are beyond that. This is pretty trivial to fix. Add this to the VPS’s VPN configuration:
push "route 10.12.0.0
I want to take this opportunity to thank Denelle Dixon for her partnership, leadership and significant contributions to Mozilla over the last six years.
Denelle joined Mozilla Corporation in September 2012 as an Associate General Counsel and rose through the ranks to lead our global business and operations as our Chief Operating Officer. Next month, after an incredible tour of duty at Mozilla, she will step down as a full-time Mozillian to join the Stellar Development Foundation as their Executive Director and CEO.
As a key part of our senior leadership team, Denelle helped to build a stronger more resilient Mozilla, including leading the acquisition of Pocket, orchestrating our major partnerships, and helping refocus us to unlock the growth opportunities ahead. Denelle has had a huge impact here — on our strategy, execution, technology, partners, brand, culture, people, the list goes on. Although I will miss her partnership deeply, I will be cheering her on in her new role as she embarks on the next chapter of her career.
As we conduct a search for our next COO, I will be working more closely with our business and operations leaders and teams as we execute on our strategy that will give people more control over their connected lives and help build an Internet that’s healthier for everyone.
Thank you, Denelle for everything, and all the best on your next adventure!
The post Thank you, Denelle Dixon appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2019/03/14/thank-you-denelle-dixon/
Dodrio is a virtual DOM library written in Rust and WebAssembly. It takes advantage of both Wasm’s linear memory and Rust’s low-level control by designing virtual DOM rendering around bump allocation. Preliminary benchmark results suggest it has best-in-class performance.
- Background
- Dodrio from a User’s Perspective
- Internal Design
- Preliminary Benchmarks
- Future Work
- Conclusion
Background
Virtual DOM Libraries
Virtual DOM libraries provide a declarative interface to the Web’s imperative DOM. Users describe the desired DOM state by generating a virtual DOM tree structure, and the library is responsible for making the Web page’s physical DOM reflect the user-generated virtual DOM tree. Libraries employ some diffing algorithm to decrease the number of expensive DOM mutation methods they invoke. Additionally, they tend to have facilities for caching to further avoid unnecessarily re-rendering components which have not changed and re-diffing identical subtrees.
Bump Allocation
Bump allocation is a fast, but limited approach to memory allocation. The allocator maintains a chunk of memory, and a pointer pointing within that chunk. To allocate an object, the allocator rounds the pointer up to the object’s alignment, adds the object’s size, and does a quick test that the pointer didn’t overflow and still points within the memory chunk. Allocation is only a small handful of instructions. Likewise, deallocating every object at once is fast: reset the pointer back to the start of the chunk.
The disadvantage of bump allocation is that there is no general way to deallocate individual objects and reclaim their memory regions while other objects are still in use.
These trade offs make bump allocation well-suited for phase-oriented allocations. That is, a group of objects that will all be allocated during the same program phase, used together, and finally deallocated together.
bump_allocate(size, align):
aligned_pointer = round_up_to(self.pointer, align)
new_pointer = aligned_pointer + size
if no overflow and new_pointer < self.end_of_chunk:
self.pointer = new_pointer
return aligned_pointer
else:
handle_allocation_failure()
Dodrio from a User’s Perspective
First off, we should be clear about what Dodrio is and is not. Dodrio is only a virtual DOM library. It is not a full framework. It does not provide state management, such as Redux stores and actions or two-way binding. It is not a complete solution for everything you encounter when building Web applications.
Using Dodrio should feel fairly familiar to anyone who has used Rust or virtual DOM libraries before. To define how a struct is rendered as HTML, users implement the dodrio::Render trait, which takes an immutable reference to self and returns a virtual DOM tree.
Dodrio uses the builder pattern to create virtual DOM nodes. We intend to support optional JSX-style, inline HTML templating syntax with compile-time procedural macros, but we’ve left it as future work.
The 'a and 'bump lifetimes in the dodrio::Render trait’s interface and the where 'a: 'bump clause enforce that the self reference outlives the bump allocation arena and the returned virtual DOM tree. This means that if self contains a string, for example, the returned virtual DOM can safely use that string by reference rather than copying it into the bump allocation arena. Rust’s lifetimes and borrowing enable us to be aggressive with cost-saving optimizations while simultaneously statically guaranteeing their safety.
struct Hello {
who: String,
}
impl Render for Hello {
fn render<'a, 'bump>(&'a self, bump: &'bump Bump) -> Please join us in congratulating Edoardo Viola, our Rep of the Month for February 2019!
Edoardo is a long-time Mozillian from Italy and has been a Rep for almost two years. He’s a Resource Rep and has been on the Reps Council until January. When he’s not busy with Reps work, Edoardo is a Mentor in the Open Leadership Training Program. In the past he has contributed to Campus Clubs as well as MozFest, where he was a Space Wrangler for the Web Literacy Track.

Recently Edoardo helped out at FOSDEM in Brussels as part of the Mozilla volunteers organizing our presence. He helped out at the booth, as well as helping to moderate the Mozilla Dev Room. He also contributes to the Internet Health Report as part of the volunteer team to give input for the next edition of the report.
To congratulate him, please head over to Discourse!
https://blog.mozilla.org/mozillareps/2019/03/14/rep-of-the-month-february-2019/
Over the past year, the Fission MemShrink project has been working tirelessly to reduce the memory overhead of Firefox. The goal is to allow us to start spinning up more processes while still maintaining a reasonable memory footprint. I’m happy to announce that we’ve seen the fruits of this labor: as of version 66 we’re doubling the default number of content processes from 4 to 8.
Doubling the number of content processes is the logical extension of the e10s-multi project. Back when that project wrapped up we chose to limit the default number of processes to 4 in order to balance the benefits of multiple content processes — fewer crashes, better site isolation, improved performance when loading multiple pages — with the impact on memory usage for our users.
Our telemetry has looked really good: if we compare beta 59 (roughly when this project started) with beta 66, where we decided to let the increase be shipped to our regular users, we see a virtually unchanged total memory usage for our 25th, median, and 75th percentile and a modest 9% increase for the 95th percentile on Windows 64-bit.

Doubling the number of content processes and not seeing a huge jump is quite impressive. Even on our worst-case-scenario stress test — AWSY which loads 100 pages in 30 tabs, repeated 3 times — we only saw a 6% increase in memory usage when turning on 8 content processes when compared to when we started the project.

This is a huge accomplishment and I’m very proud of the loose-knit team of contributors who have done some phenomenal feats to get us to this point. There have been some big wins, but really it’s the myriad of minor improvements that compounded into a large impact. This has ranged from delay-loading browser JavaScript code until it’s needed (or not at all), to low-level changes to packing C++ data structures more efficiently, to large system-wide changes to how we generate bindings that glue together our JavaScript and C++ code. You can read more about the background of this project and many of the changes in our initial newsletter and the follow-up.
While I’m pleased with where we are now, we still have a way to go to get our overhead down even further. Fear not, for we have a quite a few changes in the pipeline including a fork server to help further reduce memory usage on Linux and macOS, work to share font data between processes, and work to share more CSS data between processes. In addition to reducing overhead we now have a tab unloading feature in Nightly 67 that will proactively unload tabs when it looks like you’re about to run out of memory. So far the results in reducing the number of out-of-memory crashes are looking really good and we’re hoping to get that released to a wider audience in the near future.
http://www.erahm.org/2019/03/13/doubling-the-number-of-content-processes-in-firefox/
We access the web on all sorts of devices from our laptop to our phone to our tablets. And we need our passwords everywhere to log into an account. This … Read more
The post Get better password management with Firefox Lockbox on iPad appeared first on The Firefox Frontier.
The other day someone filed a bug on curl that we don’t support redirects with the Refresh header. This took me down a rabbit hole of Refresh header research and I’ve returned to share with you what I learned down there.
tl;dr Refresh is not a standard HTTP header.
As you know, an HTTP redirect is specified to use a 3xx response code and a Location: header to point out the new URL (I use the term URL here but you know what I mean). This has been the case since RFC 1945 (HTTP/1.0). According to an old mail from Roy T Fielding (dated June 1996), Refresh “didn’t make it” into that spec. That was the first “real” HTTP specification. (And the HTTP we used before 1.0 didn’t even have headers!)
The little detail that it never made it into the 1.0 spec or any later one, doesn’t seem to have affected the browsers. Still today, browsers keep supporting the Refresh header as a sort of Location: replacement even though it seems to never have been present in a HTTP spec.
In good company
curl is not the only HTTP library that doesn’t support this non-standard header. The popular python library requests apparently doesn’t according to this bug from 2017, and another bug was filed about it already back in 2011 but it was just closed as “old” in 2014.
I’ve found no support in wget or wget2 either for this header.
I didn’t do any further extensive search for other toolkits’ support, but it seems that the browsers are fairly alone in supporting this header.
How common is the the Refresh header?
I decided to make an attempt to figure out, and for this venture I used the Rapid7 data trove. The method that data is collected with may not be the best – it scans the IPv4 address range and sends a HTTP request to each TCP port 80, setting the IP address in the Host: header. The result of that scan is 52+ million HTTP responses from different and current HTTP origins. (Exactly 52254873 responses in my 59GB data dump, dated end of February 2019).
Results from my scans
- Location is used in 18.49% of the responses
- Refresh is used in 0.01738% of the responses (exactly 9080 responses featured them)
- Location is thus used 1064 times more often than Refresh
- In 35% of the cases when Refresh is used, Location is also used
- curl thus handles 99.9939% of the redirects in this test
Additional notes
- When Refresh is the only redirect header, the response code is usually 200 (with 404 being the second most)
- When both headers are used, the response code is almost always 30x
- When both are used, it is common to redirect to the same target and it is also common for the Refresh header value to only contain a number (for the number of seconds until “refresh”).
Refresh from HTML content
Redirects can also be done by meta tags in HTML and sending the refresh that way, but I have not investigated how common as that isn’t strictly speaking HTTP so it is outside of my research (and interest) here.
In use, not documented, not in the spec
Just another undocumented corner of the web.
When I posted about these findings on the HTTPbis mailing list, it was pointed out that WHATWG mentions this header in their iana page. I say mention because calling that documenting would be a stretch…
It is not at all clear exactly what the header is supposed to do and it is not documented anywhere. It’s not exactly a redirect, but almost?
Will/should curl support it?
A decision hasn’t been made about it yet. With such a very low use frequency and since we’ve managed fine without support for it so long, maybe we can just maintain the situation and instead argue that we should just completely deprecate this header use from the web?
Updates
After this post first went live, I got some further feedback and data that are relevant and interesting.
A talk I did for the Automationeer’s Assemble series on how Mozilla handles complexity in their CI configuration.
In the last 10 years, there has been an explosion of interest in “scientific computing” and “data science”: that is, the application of computation to answer questions and analyze data in the natural and social sciences. To address these needs, we’ve seen a renaissance in programming languages, tools, and techniques that help scientists and researchers explore and understand data and scientific concepts, and to communicate their findings. But to date, very few tools have focused on helping scientists gain unfiltered access to the full communication potential of modern web browsers. So today we’re excited to introduce Iodide, an experimental tool meant to help scientists write beautiful interactive documents using web technologies, all within an iterative workflow that will be familiar to many scientists.

Iodide in action.
Beyond being just a programming environment for creating living documents in the browser, Iodide attempts to remove friction from communicative workflows by always bundling the editing tool with the clean readable document. This diverges from IDE-style environments that output presentational documents like .pdf files (which are then divorced from the original code) and cell-based notebooks which mix code and presentation elements. In Iodide, you can get both a document that looks however you want it to look, and easy access to the underlying code and editing environment.
Iodide is still very much in an alpha state, but following the internet aphorism “If you’re not embarrassed by the first version of your product, you’ve launched too late”, we’ve decided to do a very early soft launch in the hopes of getting feedback from a larger community. We have a demo that you can try out right now, but expect a lot of rough edges (and please don’t use this alpha release for critical work!). We’re hoping that, despite the rough edges, if you squint at this you’ll be able to see the value of the concept, and that the feedback you give us will help us figure out where to go next.
How we got to Iodide
Data science at Mozilla
At Mozilla, the vast majority of our data science work is focused on communication. Though we sometimes deploy models intended to directly improve a user’s experience, such as the recommendation engine that helps users discover browser extensions, most of the time our data scientists analyze our data in order to find and share insights that will inform the decisions of product managers, engineers and executives.
Data science work involves writing a lot of code, but unlike traditional software development, our objective is to answer questions, not to produce software. This typically results in some kind of report — a document, some plots, or perhaps an interactive data visualization. Like many data science organizations, at Mozilla we explore our data using fantastic tools like Jupyter and R-Studio. However, when it’s time to share our results, we cannot usually hand off a Jupyter notebook or an R script to a decision-maker, so we often end up doing things like copying key figures and summary statistics to a Google Doc.
We’ve found that making the round trip from exploring data in code to creating a digestible explanation and back again is not always easy. Research shows that many people share this experience. When one data scientist is reading through another’s final report and wants to look at the code behind it, there can be a lot of friction; sometimes tracking down the code is easy, sometimes not. If they want to attempt to experiment with and extend the code, things obviously get more difficult still. Another data scientist may have your code, but may not have an identical configuration on their machine, and setting that up takes time.
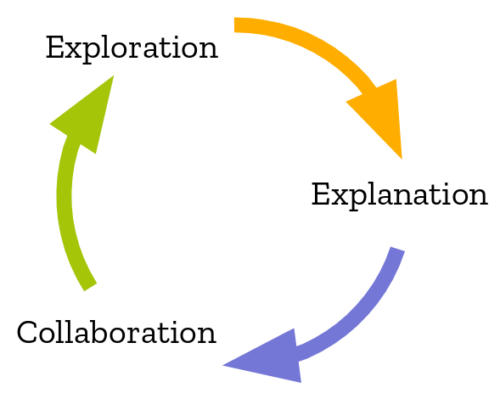
The virtuous circle of data science work.
Why is there so little web in science?
Against the background of these data science workflows at Mozilla, in late 2017 I undertook a project that called for
Moving files around the web can be complicated and expensive, but with Firefox Send it doesn’t have to be. There are plenty of services that let you send files for … Read more
The post Use Firefox Send to safely share files for free appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/use-firefox-send-to-safely-share-files-for-free/
We’re seeking technologists, activists, policy experts, and scientists devoted to a healthy internet. Apply to be a 2019-2020 Mozilla Fellow
Today, we’re opening applications for Mozilla Fellowships. Mozilla is seeking technologists, activists, policy experts, and scientists who are building a more humane digital world:
http://mozilla.fluxx.io/apply/fellowship
Mozilla Fellows work on the front lines of internet health, at a time when the internet is entwined with everything from elections and free expression to justice and personal safety. Fellows ensure the internet remains a force for good — empowerment, equality, access — and also combat online ills, like abuse, exclusion, and closed systems.
Mozilla is particularly interested in individuals whose expertise aligns with our 2019 impact goal: “better machine decision making,” or ensuring the artificial intelligence in our lives is designed with responsibility and ethics top of mind. For example: Fellows might research how disinformation spreads on Facebook. Or, build a tool that identifies the blind spots in algorithms that detect cancer. Or, advocate for a “digital bill of rights” that protects individuals from invasive facial recognition technology.
During a 10-month tenure, Mozilla Fellows may run campaigns, build products, and influence policy. Along the way, Fellows receive competitive funding and benefits; mentorship and trainings; access to the Mozilla network and megaphone; and more. Mozilla Fellows hail from a range of disciplines and geographies: They are scientists in the UK, human rights researchers in Germany, tech policy experts in Nigeria, and open-source advocates in New Zealand. The Mozilla Fellowship runs from October 2019 through July 2020.
Specifically, we’re seeking Fellows who identify with one of three profiles:
- Open web activists: Individuals addressing issues like privacy, security, and inclusion online. These Fellows will embed at leading human rights and civil society organizations from around the world, working alongside the organizations and also exchanging advocacy and technical insights among each other.
- Tech policy professionals: Individuals who examine the interplay of technology and public policy — and craft legal, academic, and governmental solutions.
- Scientists and researchers: Individuals who infuse open-source practices and principles into scientific research. These Fellows are based at the research institution with which they are currently affiliated.
Learn more about Mozilla Fellowships, and then apply. Part 1 of the applications closes on Monday April 8, 2019 at 5:00pm ET. Below, meet a handful of current Mozilla Fellows:
 Valentina Pavel
Valentina Pavel
Valentina is a digital rights advocate working on privacy, freedom of speech, and open culture. Valentina is currently investigating the implications of digital feudalism, and exploring different visions for shared data ownership. Read her latest writing.
 Selina Musuta
Selina Musuta
Selina is a web developer and infosec expert. Selina is currently embedded at Consumer Reports, and supporting the organization’s privacy and security work.
 Julia Lowndes | @juliesquid
Julia Lowndes | @juliesquid
Julia is a environmental scientist and open-source advocate. Julia is currently evangelizing openness in the scientific community, and training fellow researchers how to leverage open data and processes.